Boundary-Protection W8A8 HiFloat8 Quantization for Large-Scale Text-to-Video Diffusion Transformers
Pith reviewed 2026-06-28 17:46 UTC · model grok-4.3
The pith
Protecting boundary blocks in full precision while quantizing the middle ones enables W8A8 HiFloat8 inference on a 14B text-to-video diffusion transformer with no measurable accuracy loss.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
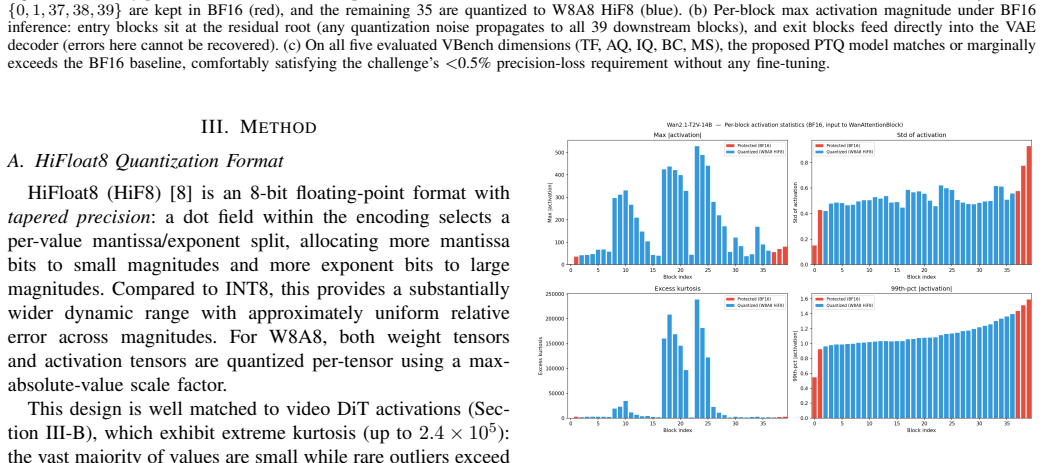
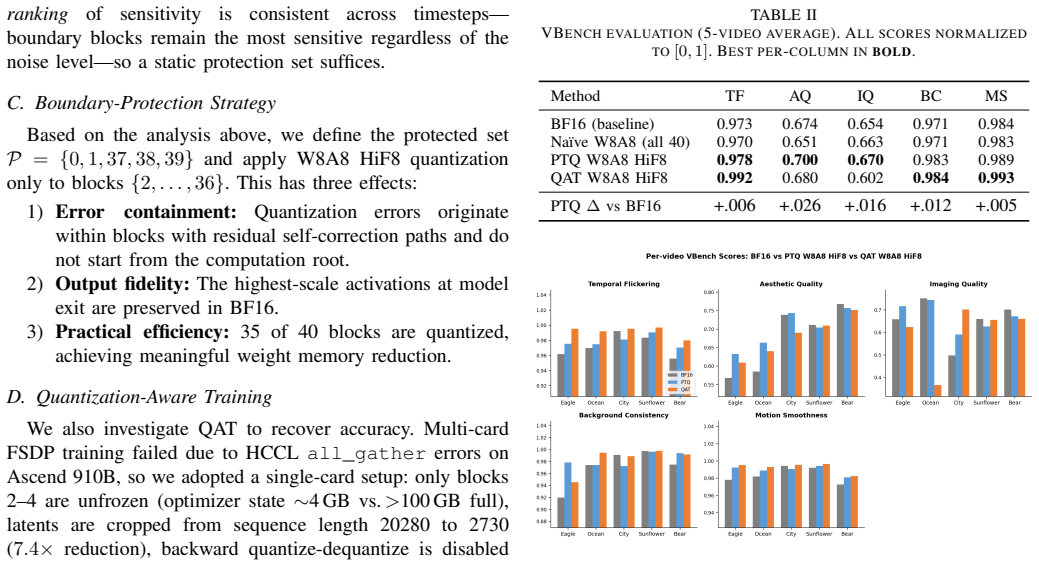
A boundary-protection post-training quantization strategy retains the first two and last three WanAttentionBlocks in BF16 while quantizing the remaining 35 blocks to W8A8 HiFloat8; this configuration matches or marginally exceeds the BF16 baseline across all VBench dimensions on the 14B Wan2.1-T2V-14B model within the 5-prompt test set, and an ablation verifies that this exact protection choice outperforms the other three configurations examined.
What carries the argument
Boundary-protection strategy that uses per-block activation analysis to select which transformer blocks remain in BF16.
If this is right
- Quantizing 35 of 40 blocks reduces memory footprint and inference cost on NPUs while preserving output quality.
- The same per-block analysis can be repeated on other large DiT models to identify their own boundary blocks.
- QAT provides no consistent gain over this PTQ recipe on single-card hardware.
- Full boundary protection is the configuration that maximizes average VBench score among the four tested options.
Where Pith is reading between the lines
- The heterogeneous block statistics may appear in other diffusion transformer families, suggesting the protection pattern could transfer after similar analysis.
- Extending the evaluation to hundreds of prompts would test whether the no-loss result holds outside the current small set.
- The approach could be combined with other compression techniques such as pruning or distillation for further efficiency gains.
Load-bearing premise
The activation statistics measured on the 40 blocks remain stable enough that protecting exactly the first two and last three blocks will continue to work for other prompts and model configurations.
What would settle it
Running the same W8A8 model on a larger prompt set or different video tasks and measuring a clear drop below the BF16 VBench scores would show the protection choice does not generalize.
Figures



read the original abstract
We present a post-training quantization (PTQ) approach for Wan2.1-T2V-14B, a 14-billion-parameter text-to-video diffusion transformer, targeting the W8A8 HiFloat8 (HiF8) format on Ascend 910B NPUs. A central challenge in quantizing video DiT models is the heterogeneous activation distribution across transformer blocks: boundary blocks (the first and last few blocks) exhibit fundamentally different statistical properties from middle blocks, making uniform quantization ineffective. We conduct a systematic per-block activation analysis across all 40 WanAttentionBlocks and use the findings to motivate a boundary-protection strategy that retains the first two and last three blocks in BF16 while quantizing the remaining 35 blocks with W8A8 HiF8. The proposed PTQ method matches or marginally exceeds the BF16 baseline on all five VBench dimensions evaluated, indicating no measurable accuracy loss within the 5-prompt evaluation set. An ablation study over four protection configurations confirms that full boundary protection yields the highest average VBench score, validating the data-driven block selection. We additionally investigate quantization-aware training (QAT) as a complementary fine-tuning stage and analyze the conditions under which it fails to outperform plain PTQ on single-card hardware.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a post-training quantization (PTQ) technique for the 14B-parameter Wan2.1-T2V text-to-video diffusion transformer targeting W8A8 HiFloat8 on Ascend NPUs. Through per-block activation analysis on the 40 WanAttentionBlocks, it identifies that boundary blocks have distinct statistics and proposes protecting the first two and last three blocks in BF16 while quantizing the middle 35 blocks. The method is shown to match or exceed BF16 performance on all five VBench dimensions using five prompts, supported by an ablation study on protection configurations and analysis of QAT.
Significance. Should the boundary-protection strategy prove robust across diverse prompts and models, this work would be significant for efficient deployment of large-scale video generation models on specialized hardware. It provides an empirical solution to the heterogeneous activation issue in DiTs without full model retraining. The systematic analysis and ablation offer practical insights, though the small evaluation scale limits broader claims.
major comments (2)
- [Abstract and Evaluation] Abstract and Evaluation: The central claim of matching BF16 performance 'indicating no measurable accuracy loss' rests on results from only five prompts (Abstract). Since the per-block activation analysis used to select exactly the first two and last three blocks for protection was performed on the same prompt set, the evaluation does not test generalization; prompt-dependent shifts in activation ranges could render the fixed protection mask suboptimal.
- [Per-block analysis section] Per-block analysis section: The manuscript does not clarify if the activation statistics for block selection were computed on a held-out calibration set distinct from the five evaluation prompts. This detail is load-bearing for assessing whether the observed parity is due to the method or to the data-driven choice being tuned to the test prompts.
minor comments (2)
- [Notation] The term 'HiFloat8 (HiF8)' should be defined more explicitly with its format details upon first use to aid readers unfamiliar with the Ascend-specific format.
- [Figures] The per-block activation range plots (presumably in the analysis section) would benefit from error bars across multiple runs or prompts to show variability.
Simulated Author's Rebuttal
We thank the referee for the constructive comments highlighting the evaluation scale and calibration details. We address each point below and will revise the manuscript for greater clarity on these aspects.
read point-by-point responses
-
Referee: [Abstract and Evaluation] Abstract and Evaluation: The central claim of matching BF16 performance 'indicating no measurable accuracy loss' rests on results from only five prompts (Abstract). Since the per-block activation analysis used to select exactly the first two and last three blocks for protection was performed on the same prompt set, the evaluation does not test generalization; prompt-dependent shifts in activation ranges could render the fixed protection mask suboptimal.
Authors: We agree the evaluation uses only five prompts and that block selection derives from analysis on this same set. The abstract already qualifies results as holding 'within the 5-prompt evaluation set.' This reflects standard PTQ practice where calibration data matches the target distribution. The ablation over protection configurations shows the selected boundaries yield the highest score on these prompts. We will revise to explicitly discuss the limited scope and lack of generalization testing, without claiming broader robustness. revision: partial
-
Referee: [Per-block analysis section] Per-block analysis section: The manuscript does not clarify if the activation statistics for block selection were computed on a held-out calibration set distinct from the five evaluation prompts. This detail is load-bearing for assessing whether the observed parity is due to the method or to the data-driven choice being tuned to the test prompts.
Authors: The activation statistics were computed on the same five evaluation prompts; the manuscript does not describe a distinct held-out calibration set. We will revise the per-block analysis section to state this explicitly. The data-driven selection is thus tuned to the evaluated prompts, which is a limitation. However, the systematic per-block analysis and ablation still provide evidence that boundary blocks exhibit distinct statistics warranting protection. The revision will clarify this without overstating generalization. revision: yes
Circularity Check
No significant circularity; empirical PTQ selection is data-driven but not self-referential by construction
full rationale
The paper performs per-block activation analysis on the 5-prompt set to select the boundary-protection mask (first two and last three of 40 blocks kept in BF16), then directly measures VBench scores on the identical set and runs an ablation over four masks. No derivation chain, equation, or first-principles claim reduces to its own inputs; the reported parity with BF16 is a measured outcome rather than a fitted or self-defined prediction. No self-citations, uniqueness theorems, or ansatzes appear in the abstract or described method. The approach is self-contained empirical engineering whose generalization risk is a separate validity question, not circularity.
Axiom & Free-Parameter Ledger
free parameters (1)
- number of boundary blocks to protect
Forward citations
Cited by 1 Pith paper
-
Holding the FP8 Quality Ceiling at 8-Bit Weights and Activations: INT8 and GGUF Post-Training Quantization of Ideogram 4.0 for Consumer GPUs
INT8 W8A8 post-training quantization of Ideogram 4.0 preserves FP8 quality on a 200-prompt benchmark while outperforming NF4 on CLIP score and offering a favorable quality-memory trade-off via GGUF Q4_K.
Reference graph
Works this paper leans on
-
[1]
Scalable diffusion models with transformers,
W. Peebles and S. Xie, “Scalable diffusion models with transformers,” inProc. ICCV, 2023, pp. 4195–4205
2023
-
[2]
Wan: Open and advanced large-scale video generative models,
Wan Team, “Wan: Open and advanced large-scale video generative models,”arXiv:2503.20314, 2025
Pith/arXiv arXiv 2025
-
[3]
GPTQ: Accurate post-training quantization for gen- erative pre-trained transformers,
E. Frantaret al., “GPTQ: Accurate post-training quantization for gen- erative pre-trained transformers,” inProc. ICLR, 2023
2023
-
[4]
SmoothQuant: Accurate and efficient post-training quantization for large language models,
G. Xiaoet al., “SmoothQuant: Accurate and efficient post-training quantization for large language models,” inProc. ICML, 2023
2023
-
[5]
Q-Diffusion: Quantizing diffusion models,
X. Liet al., “Q-Diffusion: Quantizing diffusion models,” inProc. ICCV, 2023
2023
-
[6]
Q-DiT: Accurate post-training quantization for diffusion transformers,
Y . Chenet al., “Q-DiT: Accurate post-training quantization for diffusion transformers,”arXiv:2406.17343, 2024
arXiv 2024
-
[7]
LLM.int8(): 8-bit matrix multiplication for trans- formers at scale,
T. Dettmerset al., “LLM.int8(): 8-bit matrix multiplication for trans- formers at scale,” inProc. NeurIPS, 2022
2022
-
[8]
HiFloat8: An 8-bit floating point format with tapered precision encoding,
L. Luoet al., “HiFloat8: An 8-bit floating point format with tapered precision encoding,”arXiv:2409.16626, 2024
arXiv 2024
-
[9]
VBench: Comprehensive benchmark suite for video generative models,
Z. Huanget al., “VBench: Comprehensive benchmark suite for video generative models,” inProc. CVPR, 2024. Fig. 5. Ablation qualitative comparison (frame 24). Columns: four protection configurations. Full boundary protection (rightmost) produces the sharpest details and most vivid colors
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.