Where, What, Why, and Importance: Structured Defect Grounding for Text-to-Image Feedback
Pith reviewed 2026-06-28 01:49 UTC · model grok-4.3
The pith
Text-to-image diagnosis shifts from heatmap regression to structured prediction of defect tuples that each carry location, type, reason and importance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
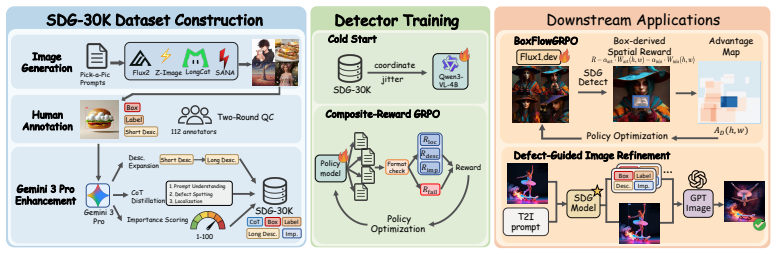
Structured Defect Grounding casts T2I diagnosis as structured set prediction in which each defect is represented by a (location, type, reason, importance) tuple; a VLM trained on the SDG-30K dataset performs this prediction, and BoxFlow-GRPO converts the predicted sets into importance-weighted box rewards that align diffusion models more effectively than prior dense-feedback approaches.
What carries the argument
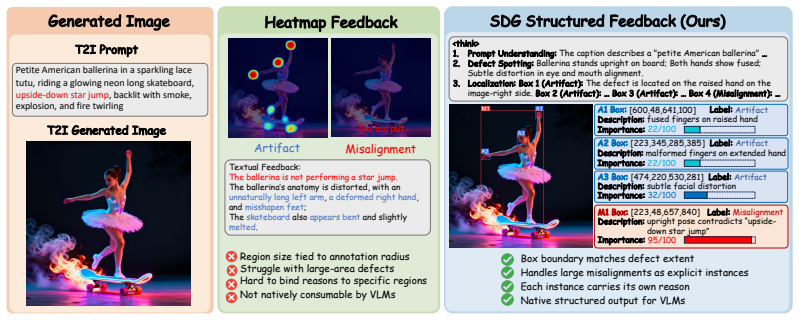
Structured Defect Grounding (SDG) as structured set prediction of (location, type, reason, importance) tuples, which replaces pixel-field regression and supplies the input for box-derived rewards.
If this is right
- The SDG detector outperforms leading proprietary VLMs on structured defect grounding tasks.
- SDG-guided rewards improve text-to-image alignment metrics.
- The same predicted defect sets support localized refinement of individual image regions.
- SDG supplies a single instance-level interface usable for diagnosis, evaluation and model enhancement.
Where Pith is reading between the lines
- The tuple representation could be applied to other generative domains such as video or 3D synthesis where defects also vary in count and require semantic explanation.
- Importance-weighted box rewards might reduce the need for global scalar signals when training alignment objectives.
- Once detectors exist, iterative refinement loops that feed detected defects back into the generator become feasible without manual intervention.
Load-bearing premise
Human annotations that assign consistent location, type, reason and importance labels to defects in generated images can serve as reliable training and evaluation targets.
What would settle it
An experiment in which the SDG detector does not exceed leading proprietary VLMs on the SDG-Eval protocol, or in which the BoxFlow-GRPO rewards derived from its outputs produce no measurable gain in alignment metrics on held-out prompts.
Figures





read the original abstract
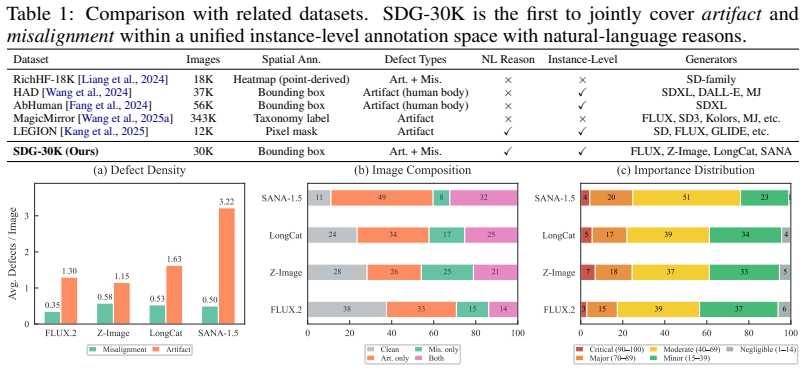
Despite generating increasingly photorealistic images, text-to-image (T2I) models still exhibit localized, subtle, and structurally complex failures. Diagnosing these failures requires instance-level feedback that answers where a defect occurs, what type it is, why it is defective, and its importance to overall image quality. While recent dense-feedback methods move beyond scalar supervision, their heatmap-centric representations still formulate diagnosis as pixel-field regression, making it difficult to localize variable-cardinality defects and bind semantic reasons to individual failures. To address this representation bottleneck, we propose Structured Defect Grounding (SDG), which casts T2I diagnosis as structured set prediction by modeling each defect as a (location, type, reason, importance) tuple. To make this formulation trainable and measurable, we introduce SDG-30K, a 30K-image dataset with box-grounded annotations across four modern T2I generators, together with a dedicated evaluation protocol, SDG-Eval. Building on this structured representation, we further present a diagnosis-to-alignment framework in which a Vision-Language Model (VLM) serves as the SDG detector, and BoxFlow-GRPO converts predicted defect sets into box-derived, importance-weighted spatial rewards for diffusion model alignment. Extensive experiments show that our SDG detector outperforms leading proprietary VLMs on structured defect grounding, while SDG-guided rewards consistently improve T2I alignment and support localized image refinement. These results establish SDG as a unified, instance-level interface for diagnosing, evaluating, and enhancing modern generative models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Structured Defect Grounding (SDG) to diagnose failures in text-to-image (T2I) models by modeling defects as (location, type, reason, importance) tuples via structured set prediction. It releases the SDG-30K dataset of 30K box-annotated images from four T2I generators along with the SDG-Eval protocol, trains a VLM-based SDG detector, and proposes BoxFlow-GRPO to derive importance-weighted spatial rewards from predicted defect sets for diffusion-model alignment. Experiments claim that the SDG detector outperforms leading proprietary VLMs on structured grounding and that the resulting rewards improve T2I alignment and enable localized refinement.
Significance. If the central claims hold after verification of label quality, the work would supply an instance-level, semantically rich interface that moves beyond scalar scores or heatmaps, enabling more precise diagnosis, evaluation, and reward-based alignment of generative models. The combination of a new dataset, evaluation protocol, and reward formulation could serve as a reusable benchmark and training signal for future T2I research.
major comments (2)
- [Dataset construction / SDG-30K] Dataset construction (implied §3 / SDG-30K description): the manuscript provides no inter-annotator agreement statistics (e.g., Fleiss’ kappa) or adjudication protocol for the subjective fields “reason” and “importance.” Because these attributes are load-bearing for both the VLM detector training and the importance-weighted rewards in BoxFlow-GRPO, the reported outperformance and alignment gains cannot yet be isolated from potential annotation noise.
- [Experiments / SDG-Eval] Experimental results (abstract and §5): baseline comparisons, statistical significance tests, and details of the annotation protocol are absent, so the claim that the SDG detector “outperforms leading proprietary VLMs” rests on unshown controls.
minor comments (1)
- [Method] Notation for the four-tuple components and the BoxFlow-GRPO reward formulation should be introduced with explicit equations rather than prose only.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our work. We address each major comment below and commit to revisions that strengthen the manuscript without altering its core claims.
read point-by-point responses
-
Referee: [Dataset construction / SDG-30K] Dataset construction (implied §3 / SDG-30K description): the manuscript provides no inter-annotator agreement statistics (e.g., Fleiss’ kappa) or adjudication protocol for the subjective fields “reason” and “importance.” Because these attributes are load-bearing for both the VLM detector training and the importance-weighted rewards in BoxFlow-GRPO, the reported outperformance and alignment gains cannot yet be isolated from potential annotation noise.
Authors: We agree that inter-annotator agreement metrics and a clear adjudication protocol are necessary to substantiate the reliability of the subjective fields. The original manuscript described the annotation guidelines and scale but did not report agreement statistics. In the revision we will add Fleiss’ kappa values computed over a held-out multi-annotator subset for both “reason” and “importance,” together with a description of the adjudication process used to resolve disagreements. These additions will be placed in §3 and will allow readers to assess label quality directly. revision: yes
-
Referee: [Experiments / SDG-Eval] Experimental results (abstract and §5): baseline comparisons, statistical significance tests, and details of the annotation protocol are absent, so the claim that the SDG detector “outperforms leading proprietary VLMs” rests on unshown controls.
Authors: We acknowledge that the main text does not include statistical significance tests or an expanded annotation-protocol subsection. The baseline comparisons appear in §5, yet p-values and confidence intervals were omitted. We will revise §5 to report paired statistical tests (e.g., McNemar or bootstrap) for all key metrics against the proprietary VLMs, and we will add a new subsection detailing the full annotation protocol, including annotator instructions, quality-control steps, and any filtering criteria. These changes will be incorporated in the revised version. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper introduces a new structured set-prediction formulation (SDG), a new annotated dataset (SDG-30K), and an empirical diagnosis-to-alignment pipeline using a VLM detector plus BoxFlow-GRPO rewards. No equations, fitted parameters, or self-citation chains are described that reduce claimed outputs (detector performance, alignment gains) to quantities defined by construction from the same inputs. All central claims rest on external VLM comparisons and the new dataset rather than tautological reductions, satisfying the self-contained criterion.
Axiom & Free-Parameter Ledger
invented entities (3)
-
Structured Defect Grounding (SDG)
no independent evidence
-
SDG-30K
no independent evidence
-
BoxFlow-GRPO
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Visual prominence— how easily a typical viewer can spot the defect at normal viewing distance
-
[2]
3.Area coverage— larger defects affecting more of the image score higher
Semantic impact— whether the defect changes the meaning, identity, or key content relative to the prompt. 3.Area coverage— larger defects affecting more of the image score higher
-
[3]
You are a helpful assistant
Location— defects on the main subject or focal area score higher than those in the background. Scores are grouped into five tiers: Critical (90–100), Major (70–89), Moderate (40–69), Minor (15–39), and Negligible (1–14). Importance annotations are obtained by prompting Gemini with the image, the original prompt, and the human-annotated defect set, and are...
-
[4]
<think> - Your detailed analysis
-
[5]
### Step 2: Visual Analysis & Defect Spotting (Issue Summary) - Describe the quality issues you observe in the image
<answer> - JSON list of bounding boxes ### Think Format (STRICT) <think> ### Step 1: Caption Understanding - Briefly summarize what the caption requires (subject, key attributes, actions, setting, style/composition if mentioned). ### Step 2: Visual Analysis & Defect Spotting (Issue Summary) - Describe the quality issues you observe in the image. - You MAY...
-
[6]
Anchor: the exact object/part involved
-
[7]
Position: image-based cues (image-left/right, upper/lower, center, near the border)
-
[8]
Interaction cue (when applicable): holding/touching/overlapping/merging/etc
-
[9]
Scale description: tiny localized detail, part-sized area, large area, or whole image
-
[10]
box_2d”: [x0, y0, x1, y1], “label
Shape/orientation: compact, elongated, runs along a boundary, wraps around an object - Do NOT invent new defects; each line must correspond to exactly one defect instance. </think> ### Answer Format (for <answer>) [{“box_2d”: [x0, y0, x1, y1], “label”: “misalignment”|“artifact”, “description”: “brief description of the issue”, “importance”: N}] Bounding b...
-
[11]
NEVER mention annotations, boxes, ground truth, translation, or any external hints
-
[12]
The final JSON must contain exactly the same set of boxes/labels as provided
Do NOT invent extra defects or remove any defect. The final JSON must contain exactly the same set of boxes/labels as provided
-
[13]
- Format: [x_min, y_min, x_max, y_max] (xyxy) - You MUST output these coordinates exactly as given in the final JSON
IMPORTANT: box_2d uses RELATIVE coordinates on a 0–1000 scale. - Format: [x_min, y_min, x_max, y_max] (xyxy) - You MUST output these coordinates exactly as given in the final JSON
-
[14]
Do NOT write numeric coordinates in the <think> block
-
[15]
</think> (2) <answer>
Output MUST contain exactly TWO blocks in this order: (1) <think> ... </think> (2) <answer> ... </answer>
-
[16]
box_2d”:[x0,y0,x1,y1],“label
<answer> MUST be a JSON list in xyxy format: [{“box_2d”:[x0,y0,x1,y1],“label”:“artifact”|“misalignment”, “description”:“...”,“importance”:N}, ...] ====== IMPORTANCE SCORING (FIELD: “importance”) ====== For EACH box, assign an integer importance score from 1 to 100: - 90–100: Critical –- immediately obvious, ruins the image. - 70–89: Major –- clearly visib...
1955
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.