RT-Counter: Real-Time Text-Guided Open-Vocabulary Object Counting
Pith reviewed 2026-06-27 01:27 UTC · model grok-4.3
The pith
RT-Counter projects visual features into text space and weaves local-global attention to count text-described objects at real-time speeds with competitive accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
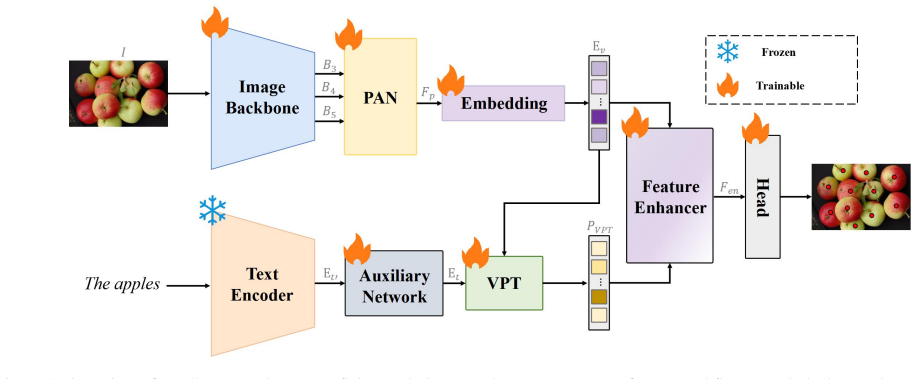
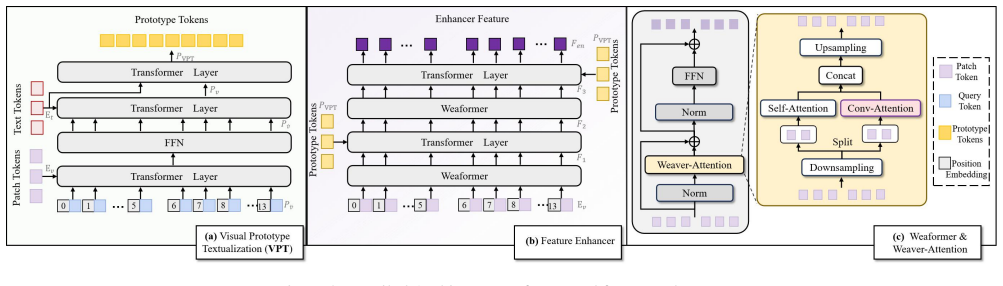
The paper claims that the Visual Prototype Textualization module, which projects learned visual features into text feature space to produce features containing both abstract information hard to capture with visual prototypes and detailed prototype information difficult to describe in text, combined with Weaving Transformer layers that use a novel hybrid attention mechanism to weave local and global visual features, enables accurate text-guided open-vocabulary object counting at real-time speeds, as shown by achieving a competitive MAE of 13.30 on FSC147 while operating at 112.48 FPS and using over 4 times fewer parameters than leading prior methods.
What carries the argument
Visual Prototype Textualization (VPT) module that projects visual features into text space and Weaving Transformer (Weaformer) layers with hybrid attention that efficiently combine local and global features.
If this is right
- Text-specified counting becomes feasible in live video streams without requiring category-specific retraining.
- The reduced parameter count allows deployment on devices with limited memory while retaining open-vocabulary flexibility.
- Hybrid attention layers of this form can replace heavier transformer blocks in other vision-language counting pipelines.
- Results across three public datasets indicate the design generalizes beyond the primary FSC147 benchmark.
- Real-time performance removes the previous need to trade accuracy for speed in text-guided counting scenarios.
Where Pith is reading between the lines
- The same visual-to-text projection step could be tested in related tasks such as open-vocabulary detection or segmentation to see whether the accuracy-speed balance transfers.
- If the hybrid attention proves stable, it offers a template for lowering compute in other vision transformers that mix local and global cues.
- Evaluating the method on text descriptions that contain negation or spatial relations not present in current benchmarks would expose any untested limits of the textualization step.
- Combining the framework with larger frozen vision-language backbones might increase accuracy further while preserving the reported speed advantage.
Load-bearing premise
The projection of visual features into text space by the VPT module actually succeeds in enhancing object-level counting by supplying both abstract and detailed information.
What would settle it
Measuring the model on the FSC147 test set and obtaining a mean absolute error above 13.30 or a frame rate below 100 FPS on comparable hardware would falsify the performance claims.
Figures


read the original abstract
Text-guided open-vocabulary object counting (TOOC) aims to count objects belonging to the categories specified by natural language descriptions. Although vision-language pre-trained models have been successful applied to TOOC tasks, they still struggle with fine-grained spatial understanding and real-time inference requirements in counting scenarios. To address these limitations, this paper proposes a real-time TOOC framework, called the Real-Time Counter (RT-Counter), that achieves not only good counting accuracy but also high computational efficiency. RT-Counter designs a novel Visual Prototype Textualization (VPT) module that can project learned visual features into a text feature space and then generate features containing the abstract information that is hard to capture with visual prototypes and the detailed prototype information that is difficult to describe in text, enhancing the object-level visual-language model's counting capabilities. Additionally, RT-Counter incorporates our Weaving Transformer (Weaformer) layers, maintaining high descriptive power at a fraction of the computational cost. The Weaformer layer adopts a novel hybrid attention mechanism that can efficiently weave together local and global visual features. Extensive experiments on three public datasets show that RT-Counter successfully breaks the accuracy-speed trade-off in TOOC. While achieving a competitive MAE of 13.30 on FSC147, RT-Counter operates at 112.48 FPS, making it 7.4x faster and over 4$\times$ more parameter-efficient than the existing leading methods in TOOC. Our work aims at balancing high accuracy and real-time performance in TOOC. Code is available at: https://github.com/Jason-Mar1/RT-Counter.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes RT-Counter, a real-time framework for text-guided open-vocabulary object counting (TOOC). It introduces a Visual Prototype Textualization (VPT) module that projects visual features into text space to capture abstract and detailed prototype information, and Weaving Transformer (Weaformer) layers using a hybrid attention mechanism to weave local and global features efficiently. The central empirical claim is that RT-Counter achieves a competitive MAE of 13.30 on FSC147 while running at 112.48 FPS, making it 7.4x faster and over 4x more parameter-efficient than leading TOOC methods, with public code released.
Significance. If the reported trade-off holds under verification, the work would be significant for practical TOOC applications by demonstrating that real-time inference is achievable without major accuracy loss. The public code repository strengthens reproducibility and allows direct testing of the VPT and Weaformer components.
major comments (3)
- [Abstract / §3 (method)] Abstract and method description: The VPT module is asserted to 'project learned visual features into a text feature space' and generate features with abstract/detailed information, but no equations, pseudocode, or feature-dimension details are supplied; this is load-bearing for the claim that it enhances the object-level visual-language model's counting capabilities beyond standard VLMs.
- [Abstract / §4 (Weaformer)] Abstract and experiments: The Weaformer is claimed to maintain 'high descriptive power at a fraction of the computational cost' via hybrid attention, yet the abstract provides neither complexity analysis (FLOPs, parameters) nor ablation results comparing it to standard attention or prior TOOC backbones; without these, the 7.4x FPS and 4x parameter-efficiency gains cannot be independently assessed.
- [Experiments] Experiments section: Only a single MAE point (13.30) and FPS value (112.48) are stated for FSC147 with no error bars, multiple runs, or dataset-split details; this weakens the cross-method comparison and the assertion that the accuracy-speed trade-off is broken.
minor comments (2)
- [Abstract] The abstract mentions 'three public datasets' but reports quantitative results only for FSC147; the other two should be summarized with at least MAE/FPS numbers in the abstract or a table to support the general claim.
- [Method] Notation for VPT and Weaformer components should be introduced with consistent symbols once the full equations appear, to avoid ambiguity when comparing to prior VLMs.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the clarity of our method and experimental reporting. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract / §3 (method)] Abstract and method description: The VPT module is asserted to 'project learned visual features into a text feature space' and generate features with abstract/detailed information, but no equations, pseudocode, or feature-dimension details are supplied; this is load-bearing for the claim that it enhances the object-level visual-language model's counting capabilities beyond standard VLMs.
Authors: We agree that the VPT description would be strengthened by explicit mathematical details. In the revised manuscript we will add the projection equations, feature dimensions, and pseudocode for the VPT module in Section 3. revision: yes
-
Referee: [Abstract / §4 (Weaformer)] Abstract and experiments: The Weaformer is claimed to maintain 'high descriptive power at a fraction of the computational cost' via hybrid attention, yet the abstract provides neither complexity analysis (FLOPs, parameters) nor ablation results comparing it to standard attention or prior TOOC backbones; without these, the 7.4x FPS and 4x parameter-efficiency gains cannot be independently assessed.
Authors: We will add FLOPs and parameter counts for Weaformer versus baselines, plus ablation results on the hybrid attention mechanism, to the experiments section of the revision. revision: yes
-
Referee: [Experiments] Experiments section: Only a single MAE point (13.30) and FPS value (112.48) are stated for FSC147 with no error bars, multiple runs, or dataset-split details; this weakens the cross-method comparison and the assertion that the accuracy-speed trade-off is broken.
Authors: The reported values use the standard FSC147 test split. We will include error bars from multiple runs, state the splits explicitly, and expand the comparison table in the revised experiments section. revision: yes
Circularity Check
No significant circularity
full rationale
The paper is an empirical contribution that introduces architectural modules (VPT and Weaformer) and validates them via training and evaluation on standard public benchmarks (FSC147 and two others). Reported figures (MAE 13.30, 112.48 FPS) are measured outcomes, not quantities derived from equations or parameters that are themselves fitted to the same target metrics. No derivation chain, uniqueness theorem, or self-citation is invoked to justify the central performance claim; the work is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Amini-Naieni, K
N. Amini-Naieni, K. Amini-Naieni, T. Han, and A. Zisser- man. Open-world text-specified object counting. InBritish Machine Vision Conference (BMCV), 2023. 2, 6, 7, 8
2023
-
[2]
Amini-Naieni, T
N. Amini-Naieni, T. Han, and A. Zisserman. Countgd: Multi-modal open-world counting. InAdvances in Neural Information Processing Systems (NeurIPS), 2024. 2, 6, 7
2024
-
[3]
Referring ex- pression counting
Siyang Dai, Jun Liu, and Ngai-Man Cheung. Referring ex- pression counting. InProceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition (CVPR),
-
[4]
A low-shot object counting network with iterative prototype adaptation
Nikola Djukic, Alan Lukezic, Vitjan Zavrtanik, and Matej Kristan. A low-shot object counting network with iterative prototype adaptation. InProceedings of the IEEE/CVF In- ternational Conference on Computer Vision (CVPR), pages 18872–18881, 2023. 1, 2, 6
2023
-
[5]
YOLOX: Exceeding YOLO series in 2021
Zheng Ge, Songtao Liu, Feng02 Wang, Zeming Li, and Jian Sun. YOLOX: Exceeding YOLO series in 2021. 2021. 1
2021
-
[6]
Michael Hobley and Victor Prisacariu. Learning to count anything: Reference-less class-agnostic counting with weak supervision.arXiv preprint arXiv:2205.10203, 2022. 6
arXiv 2022
-
[7]
Drone- based object counting by spatially regularized regional pro- posal network
Meng-Ru Hsieh, Yen-Liang Lin, and Winston H Hsu. Drone- based object counting by spatially regularized regional pro- posal network. InProceedings of the IEEE international conference on computer vision (ICCV), 2017. 5
2017
-
[8]
Clip- count: Towards text-guided zero-shot object counting.arXiv preprint arXiv:2305.07304, 2023
Ruixiang Jiang, Lingbo Liu, and Changwen Chen. Clip- count: Towards text-guided zero-shot object counting.arXiv preprint arXiv:2305.07304, 2023. 1, 2, 6, 7
arXiv 2023
-
[9]
Vlcounter: Text-aware visual representation for zero- shot object counting
Seunggu Kang, WonJun Moon, Euiyeon Kim, and Jae-Pil Heo. Vlcounter: Text-aware visual representation for zero- shot object counting. InProceedings of the AAAI Conference on Artificial Intelligence (AAAI), 2024. 2, 6, 7
2024
-
[10]
Countr: Transformer-based generalised visual count- ing.arXiv preprint arXiv:2208.13721, 2022
Chang Liu, Yujie Zhong, Andrew Zisserman, and Weidi Xie. Countr: Transformer-based generalised visual count- ing.arXiv preprint arXiv:2208.13721, 2022. 1, 2, 6
arXiv 2022
-
[11]
Path aggregation network for instance segmentation
Shu Liu, Lu Qi, Haifang Qin, Jianping Shi, and Jiaya Jia. Path aggregation network for instance segmentation. InPro- ceedings of IEEE Conference on Computer Vision and Pat- tern Recognition (CVPR), 2018. 3
2018
-
[12]
Grounding dino: Marrying dino with grounded pre-training for open-set object detection.European confer- ence on computer vision (ECCV), 2024
Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Chunyuan Li, Jianwei Yang, Hang Su, Jun Zhu, et al. Grounding dino: Marrying dino with grounded pre-training for open-set object detection.European confer- ence on computer vision (ECCV), 2024. 2, 6, 7
2024
-
[13]
Class-agnostic counting
Erika Lu, Weidi Xie, and Andrew Zisserman. Class-agnostic counting. InAsian Conference on Computer Vision (ACCV), pages 669–684, 2019. 6
2019
-
[14]
Fgenet: Fine- grained extraction network for congested crowd counting
Hao-Yuan Ma, Li Zhang, and Xiang-Yi Wei. Fgenet: Fine- grained extraction network for congested crowd counting. In Proceedings of the 30th International Conference on Multi- media Modeling (MMM), 2024. 1
2024
-
[15]
A novel unified architecture for low-shot counting by detection and segmentation.Advances in Neural Informa- tion Processing Systems (NeurIPS), 2024
Jer Pelhan, Alan Lukezic, Vitjan Zavrtanik, and Matej Kris- tan. A novel unified architecture for low-shot counting by detection and segmentation.Advances in Neural Informa- tion Processing Systems (NeurIPS), 2024. 1, 2, 6, 7
2024
-
[16]
Learn- ing transferable visual models from natural language super- vision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learn- ing transferable visual models from natural language super- vision. InInternational conference on machine learning (ICME), pages 8748–8763, 2021. 2
2021
-
[17]
Learning to count everything
Viresh Ranjan, Udbhav Sharma, Thu Nguyen, and Minh Hoai. Learning to count everything. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 3394–3403, 2021. 1, 2, 5, 6
2021
-
[18]
LAION-5b: An open large-scale dataset for training next generation image-text models
Christoph Schuhmann, Romain Beaumont, Richard Vencu, Cade W Gordon, Ross Wightman, Mehdi Cherti, Theo Coombes, Aarush Katta, Clayton Mullis, Mitchell Worts- man, Patrick Schramowski, Srivatsa R Kundurthy, Kather- ine Crowson, Ludwig Schmidt, Robert Kaczmarczyk, and Jenia Jitsev. LAION-5b: An open large-scale dataset for training next generation image-text...
2022
-
[19]
Rethinking Counting and Localization in Crowds:A Purely Point-Based Framework
Qingyu Song, Changan Wang, Zhengkai Jiang, Yabiao Wang, Ying Tai, Chengjie Wang, Jilin Li, Feiyue Huang, and Yang Wu. Rethinking Counting and Localization in Crowds:A Purely Point-Based Framework. InProceedings of the IEEE/CVF International Conference on Computer Vi- sion (ICCV), pages 3365–3374, 2021. 1
2021
-
[20]
Exploring contextual at- tribute density in referring expression counting, 2025
Zhicheng Wang, Zhiyu Pan, Zhan Peng, Jian Cheng, Liwen Xiao, Wei Jiang, and Zhiguo Cao. Exploring contextual at- tribute density in referring expression counting, 2025. 6, 7
2025
-
[21]
Zero-shot object counting
Jingyi Xu, Hieu Le, Vu Nguyen, Viresh Ranjan, and Dim- itris Samaras. Zero-shot object counting. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 15548–15557, 2023. 3, 6, 7
2023
-
[22]
Yolo-facev2: A scale and occlusion aware face detector
Ziping Yu, Hongbo Huang, Weijun Chen, Yongxin Su, Yahui Liu, and Xiuying Wang. Yolo-facev2: A scale and occlusion aware face detector. https://arxiv.org/abs/2208.02019, 2022. 5
arXiv 2022
-
[23]
Single-Image Crowd Counting via Multi- Column Convolutional Neural Network
Yingying Zhang, Desen Zhou, Siqin Chen, Shenghua Gao, and Yi Ma. Single-Image Crowd Counting via Multi- Column Convolutional Neural Network. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 589–597, 2016. 1
2016
-
[24]
Zero-shot object counting with good exemplars
Huilin Zhu, Jingling Yuan, Zhengwei Yang, Yu Guo, Zheng Wang, Xian Zhong, and Shengfeng He. Zero-shot object counting with good exemplars. InProceedings of the Euro- pean Conference on Computer Vision (ECCV), 2024. 3 9
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.