DynaCF: Mitigating Shortcut Learning in Reward Models via Dynamic Counterfactual Sensitivity
Pith reviewed 2026-06-27 17:24 UTC · model grok-4.3
The pith
DynaCF mitigates shortcut learning in reward models by dynamically downweighting samples sensitive to counterfactual perturbations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
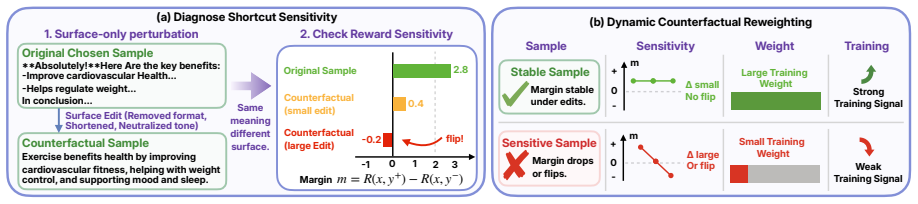
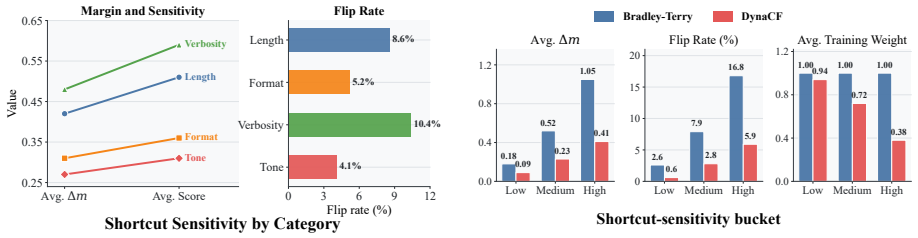
DynaCF measures shortcut sensitivity online during optimization by applying semantics-preserving counterfactual perturbations and tracking the resulting margin shifts and preference flips under the current model. Samples with higher shortcut sensitivity are dynamically downweighted in the Bradley-Terry objective, encouraging the model to rely less on superficial patterns and more on task-relevant preference signals.
What carries the argument
DynaCF, a dynamic reweighting framework that measures shortcut sensitivity via online counterfactual perturbations and downweights high-sensitivity samples in the Bradley-Terry loss.
If this is right
- Reward models exhibit reduced reliance on superficial patterns in pairwise preferences.
- Training produces models that focus more on task-relevant preference signals.
- The method yields consistent robustness improvements in preference modeling experiments.
Where Pith is reading between the lines
- The same online sensitivity tracking could apply to other supervised learning settings where shortcuts appear, such as classification tasks.
- It raises the possibility of using perturbation-based monitoring as a general tool for detecting and correcting other forms of spurious correlation during training.
- Automatic or learned generation of stronger counterfactuals might further strengthen the downweighting signal.
Load-bearing premise
Semantics-preserving counterfactual perturbations can be reliably constructed and that observed margin shifts and preference flips specifically indicate reliance on shortcut cues rather than noise or legitimate variation.
What would settle it
A controlled test set with known shortcut cues where DynaCF fails to reduce model reliance on those cues or shows no robustness gain over a standard Bradley-Terry baseline would falsify the claim.
Figures
read the original abstract
Reward models trained from pairwise preferences often exploit superficial shortcut cues rather than learning true response quality. We propose DynaCF, a dynamic reweighting framework for mitigating shortcut learning in reward model training. Unlike static shortcut heuristics, DynaCF measures shortcut sensitivity online during optimization by applying semantics-preserving counterfactual perturbations and tracking the resulting margin shifts and preference flips under the current model. Samples with higher shortcut sensitivity are dynamically downweighted in the Bradley-Terry objective, encouraging the model to rely less on superficial patterns and more on task-relevant preference signals. Extensive experiments show that DynaCF consistently improves robustness in preference modeling.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes DynaCF, a dynamic reweighting framework for reward model training that measures shortcut sensitivity online by applying semantics-preserving counterfactual perturbations, tracking margin shifts and preference flips under the current model, and downweighting high-sensitivity samples in the Bradley-Terry objective to encourage reliance on task-relevant signals rather than superficial cues. It claims that extensive experiments demonstrate consistent improvements in robustness for preference modeling.
Significance. If the core assumption that perturbation-induced flips isolate shortcut reliance holds, the approach offers a principled online alternative to static heuristics for improving reward model reliability in RLHF pipelines; the dynamic, model-dependent sensitivity tracking is a conceptual strength relative to fixed reweighting schemes.
major comments (3)
- [§3] §3 (method description): the central claim that observed margin shifts and preference flips under counterfactual perturbations specifically indicate shortcut reliance (rather than residual semantic variation or noise) lacks any formal invariance criterion, human validation protocol, or oracle consistency check; without this, the dynamic downweighting step in the modified Bradley-Terry loss is not justified and risks penalizing correct preference signals.
- [§4] §4 (experiments): the abstract asserts 'extensive experiments show consistent improvement' yet supplies no datasets, baselines, quantitative metrics, error bars, ablation results on the perturbation generator, or tables reporting robustness gains; this absence makes the empirical support for the robustness claim unevaluable and load-bearing for the paper's contribution.
- [§3.2] §3.2 (reweighting formulation): the sensitivity score used for sample weighting is defined solely in terms of margin shift and flip rate under the current model, but no analysis shows that this quantity is invariant to legitimate semantic changes; if the perturbations are not guaranteed semantics-preserving, the reweighting can degrade rather than improve preference modeling.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and detailed comments. We address each major point below, providing clarifications where the manuscript's approach can be defended on its stated terms and committing to revisions where additional justification or reporting is warranted.
read point-by-point responses
-
Referee: [§3] §3 (method description): the central claim that observed margin shifts and preference flips under counterfactual perturbations specifically indicate shortcut reliance (rather than residual semantic variation or noise) lacks any formal invariance criterion, human validation protocol, or oracle consistency check; without this, the dynamic downweighting step in the modified Bradley-Terry loss is not justified and risks penalizing correct preference signals.
Authors: The manuscript presents DynaCF as an empirical, online method that identifies sensitivity via margin shifts under perturbations explicitly constructed to be semantics-preserving (see perturbation generator in §3.1). We do not claim a formal invariance proof or oracle check; the justification rests on the dynamic, model-dependent measurement during training rather than static heuristics. We agree a dedicated discussion of assumptions would strengthen the presentation and will add a limitations subsection addressing potential residual semantic variation and the risk of penalizing valid signals. revision: partial
-
Referee: [§4] §4 (experiments): the abstract asserts 'extensive experiments show consistent improvement' yet supplies no datasets, baselines, quantitative metrics, error bars, ablation results on the perturbation generator, or tables reporting robustness gains; this absence makes the empirical support for the robustness claim unevaluable and load-bearing for the paper's contribution.
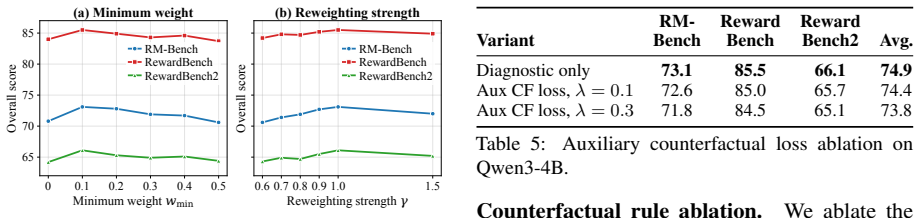
Authors: The initial submission omitted the full experimental details. The complete manuscript reports results on standard preference datasets (e.g., HH-RLHF, UltraFeedback) against baselines including vanilla Bradley-Terry and static reweighting methods, with metrics such as accuracy, robustness to shortcuts, and ablations on the perturbation module, including error bars. We will expand §4 with the requested tables, quantitative results, and ablation studies in the revision to make the empirical claims fully evaluable. revision: yes
-
Referee: [§3.2] §3.2 (reweighting formulation): the sensitivity score used for sample weighting is defined solely in terms of margin shift and flip rate under the current model, but no analysis shows that this quantity is invariant to legitimate semantic changes; if the perturbations are not guaranteed semantics-preserving, the reweighting can degrade rather than improve preference modeling.
Authors: The sensitivity score is deliberately computed under the current model to reflect its specific shortcut reliance at each training step. The perturbation generator is designed to produce semantics-preserving edits (detailed in §3.1), so that observed flips primarily capture superficial cue dependence rather than true semantic shifts. We acknowledge the absence of an explicit invariance analysis and will add a short theoretical motivation plus pseudocode clarifying the perturbation constraints, along with a note on failure modes if semantics are not fully preserved. revision: partial
Circularity Check
No significant circularity in derivation or claims
full rationale
The paper presents DynaCF as a heuristic reweighting procedure that applies external semantics-preserving perturbations to measure sensitivity via margin shifts and flips, then downweights samples in the Bradley-Terry loss. No equations, fitted parameters, or derivations are described that reduce by construction to the inputs themselves. No self-citations are invoked as load-bearing uniqueness theorems, and the method does not rename known results or smuggle ansatzes. The approach is self-contained as an online training heuristic without circular reduction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Semantics-preserving counterfactual perturbations can be generated that isolate superficial cues while leaving task-relevant meaning unchanged.
Reference graph
Works this paper leans on
-
[1]
Bradley, Ralph Allan and Terry, Milton E. , journal =. Rank Analysis of Incomplete Block Designs:. 1952 , publisher =. doi:10.2307/2334029 , url =
-
[2]
Advances in Neural Information Processing Systems , volume =
Deep Reinforcement Learning from Human Preferences , author =. Advances in Neural Information Processing Systems , volume =. 2017 , url =
2017
-
[3]
Advances in Neural Information Processing Systems , volume =
Training Language Models to Follow Instructions with Human Feedback , author =. Advances in Neural Information Processing Systems , volume =. 2022 , url =
2022
-
[4]
Thirty-seventh Conference on Neural Information Processing Systems , year=
Direct Preference Optimization: Your Language Model is Secretly a Reward Model , author =. Thirty-seventh Conference on Neural Information Processing Systems , year=
-
[5]
Nature Machine Intelligence , volume =
Shortcut Learning in Deep Neural Networks , author =. Nature Machine Intelligence , volume =. 2020 , doi =
2020
-
[6]
arXiv preprint arXiv:2505.09388 , year =. doi:10.48550/arXiv.2505.09388 , url =. 2505.09388 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2505.09388
-
[7]
2025 , url=
Wang, Zhilin and Zeng, Jiaqi and Delalleau, Olivier and Shin, Hoo-Chang and Soares, Felipe and Bukharin, Alexander and Evans, Ellie and Dong, Yi and Kuchaiev, Oleksii , booktitle=. 2025 , url=
2025
-
[8]
2025 , url=
Liu, Yantao and Yao, Zijun and Min, Rui and Cao, Yixin and Hou, Lei and Li, Juanzi , booktitle=. 2025 , url=
2025
-
[9]
Smith, and Hannaneh Hajishirzi
Lambert, Nathan and Pyatkin, Valentina and Morrison, Jacob and Miranda, LJ and Lin, Bill Yuchen and Chandu, Khyathi and Dziri, Nouha and Kumar, Sachin and Zick, Tom and Choi, Yejin and Smith, Noah A. and Hajishirzi, Hannaneh. Findings of the Association for Computational Linguistics: NAACL 2025. 2025. doi:10.18653/v1/2025.findings-naacl.96
-
[10]
and Hajishirzi, Hannaneh and Lambert, Nathan , booktitle=
Malik, Saumya and Pyatkin, Valentina and Land, Sander and Morrison, Jacob and Smith, Noah A. and Hajishirzi, Hannaneh and Lambert, Nathan , booktitle=. 2026 , url=
2026
-
[11]
LoRA: Low-Rank Adaptation of Large Language Models
Hu, Edward J. and Shen, Yelong and Wallis, Phillip and Allen-Zhu, Zeyuan and Li, Yuanzhi and Wang, Shean and Wang, Lu and Chen, Weizhu , booktitle =. 2022 , eprint =. doi:10.48550/arXiv.2106.09685 , url =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2106.09685 2022
-
[12]
Skywork-Reward: Bag of Tricks for Reward Modeling in LLMs
Liu, Chris Yuhao and Zeng, Liang and Liu, Jiacai and Yan, Rui and He, Jujie and Wang, Chaojie and Yan, Shuicheng and Liu, Yang and Zhou, Yahui , journal =. 2024 , eprint =. doi:10.48550/arXiv.2410.18451 , url =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2410.18451 2024
-
[13]
2026 , url=
Liu, Chris Yuhao and Zeng, Liang and Xiao, Yuzhen and He, Jujie and Liu, Jiacai and Wang, Chaojie and Yan, Rui and Shen, Wei and Zhang, Fuxiang and Xu, Jiacheng and Liu, Yang and Zhou, Yahui , booktitle=. 2026 , url=
2026
-
[14]
Regularizing Hidden States Enables Learning Generalizable Reward Model for
Yang, Rui and Ding, Ruomeng and Lin, Yong and Zhang, Huan and Zhang, Tong , booktitle =. Regularizing Hidden States Enables Learning Generalizable Reward Model for. 2024 , eprint =. doi:10.48550/arXiv.2406.10216 , url =
-
[15]
Uncertainty-aware Reward Model: Teaching Reward Models to Know What is Unknown , author =. arXiv preprint arXiv:2410.00847 , year =. doi:10.48550/arXiv.2410.00847 , url =. 2410.00847 , archivePrefix =
-
[16]
arXiv preprint arXiv:1707.06347 , year =
Proximal Policy Optimization Algorithms , author =. arXiv preprint arXiv:1707.06347 , year =. 1707.06347 , archivePrefix =
-
[17]
International Conference on Machine Learning , pages =
Scaling Laws for Reward Model Overoptimization , author =. International Conference on Machine Learning , pages =. 2023 , eprint =
2023
-
[18]
A Long Way to Go: Investigating Length Correlations in
Singhal, Prasann and Goyal, Tanya and Xu, Jiacheng and Durrett, Greg , booktitle=. A Long Way to Go: Investigating Length Correlations in. 2024 , url=
2024
-
[19]
arXiv preprint arXiv:1909.08593 , year =
Fine-Tuning Language Models from Human Preferences , author =. arXiv preprint arXiv:1909.08593 , year =. 1909.08593 , archivePrefix =
Pith/arXiv arXiv 1909
-
[20]
First Conference on Language Modeling , year=
Helping or Herding? Reward Model Ensembles Mitigate but do not Eliminate Reward Hacking , author=. First Conference on Language Modeling , year=
-
[21]
The Twelfth International Conference on Learning Representations , year=
Reward Model Ensembles Help Mitigate Overoptimization , author =. The Twelfth International Conference on Learning Representations , year=
-
[22]
International Conference on Machine Learning , year =
Ram. International Conference on Machine Learning , year =. doi:10.48550/arXiv.2401.12187 , url =. 2401.12187 , archivePrefix =
-
[23]
2024 , url=
Chen, Lichang and Zhu, Chen and Soselia, Davit and Chen, Jiuhai and Zhou, Tianyi and Goldstein, Tom and Huang, Heng and Shoeybi, Mohammad and Catanzaro, Bryan , booktitle=. 2024 , url=
2024
-
[24]
arXiv preprint arXiv:2510.19050 , year =
Rectifying Shortcut Behaviors in Preference-based Reward Learning , author =. arXiv preprint arXiv:2510.19050 , year =. doi:10.48550/arXiv.2510.19050 , url =. 2510.19050 , archivePrefix =
-
[25]
The Fourteenth International Conference on Learning Representations , year=
Robust Reward Modeling via Causal Rubrics , author =. The Fourteenth International Conference on Learning Representations , year=
-
[26]
Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback
Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback , author =. arXiv preprint arXiv:2204.05862 , year =. doi:10.48550/arXiv.2204.05862 , url =. 2204.05862 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2204.05862
-
[27]
Learning to summarize from human feedback
Learning to Summarize with Human Feedback , author =. Advances in Neural Information Processing Systems , volume =. 2020 , eprint =. doi:10.48550/arXiv.2009.01325 , url =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2009.01325 2020
-
[28]
Disentangling length from quality in direct preference optimization
Park, Ryan and Rafailov, Rafael and Ermon, Stefano and Finn, Chelsea. Disentangling Length from Quality in Direct Preference Optimization , author =. Findings of the Association for Computational Linguistics: ACL 2024. 2024. doi:10.18653/v1/2024.findings-acl.297
-
[29]
Findings of the Association for Computational Linguistics: EMNLP , pages =
Loose Lips Sink Ships: Mitigating Length Bias in Reinforcement Learning from Human Feedback , author =. Findings of the Association for Computational Linguistics: EMNLP , pages =. 2023 , eprint =. doi:10.48550/arXiv.2310.05199 , url =
-
[30]
and He, He and Feng, Shi , booktitle =
Wen, Jiaxin and Zhong, Ruiqi and Khan, Akbir and Perez, Ethan and Steinhardt, Jacob and Huang, Minlie and Bowman, Samuel R. and He, He and Feng, Shi , booktitle =. Language Models Learn to Mislead Humans via. 2025 , eprint =. doi:10.48550/arXiv.2409.12822 , url =
-
[31]
Length-Controlled
Dubois, Yann and Galambosi, Bal. Length-Controlled. First Conference on Language Modeling , year=
-
[32]
Defining and characterizing reward hacking.arXiv preprint arXiv:2209.13085, 2022
Defining and Characterizing Reward Gaming , author =. Advances in Neural Information Processing Systems , year =. doi:10.48550/arXiv.2209.13085 , url =. 2209.13085 , archivePrefix =
-
[33]
The Twelfth International Conference on Learning Representations , year=
Let's Verify Step by Step , author =. The Twelfth International Conference on Learning Representations , year=
-
[34]
Math-shepherd: Verify and reinforce LLMs step-by-step without human annotations
Wang, Peiyi and Li, Lei and Shao, Zhihong and Xu, Runxin and Dai, Damai and Li, Yifei and Chen, Deli and Wu, Yu and Sui, Zhifang. Math-Shepherd: Verify and Reinforce LLM s Step-by-step without Human Annotations. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024. doi:10.18653/v1/2024.acl-long.510
-
[35]
Secrets of RLHF in Large Language Models Part I: PPO
Zheng, Rui and Dou, Shihan and Gao, Songyang and Hua, Yuan and Shen, Wei and Wang, Binghai and Liu, Yan and Jin, Senjie and Liu, Qin and Zhou, Yuhao and Xiong, Limao and Chen, Lu and Xi, Zhiheng and Xu, Nuo and Lai, Wenbin and Zhu, Minghao and Chang, Cheng and Yin, Zhangyue and Weng, Rongxiang and Cheng, Wensen and Huang, Haoran and Sun, Tianxiang and Yan...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2307.04964 2023
-
[36]
2025 , eprint=
Beyond Reward Hacking: Causal Rewards for Large Language Model Alignment , author=. 2025 , eprint=
2025
-
[37]
2024 , eprint=
Generative Reward Models , author=. 2024 , eprint=
2024
-
[38]
and Strouse, DJ and Sandholm, Tuomas and Salakhutdinov, Ruslan and Dragan, Anca D
Moskovitz, Ted and Singh, Aaditya K. and Strouse, DJ and Sandholm, Tuomas and Salakhutdinov, Ruslan and Dragan, Anca D. and McAleer, Stephen , booktitle=. Confronting Reward Model Overoptimization with Constrained. 2024 , url=
2024
-
[39]
RLHF Workflow: From Reward Modeling to Online RLHF
Dong, Hanze and Xiong, Wei and Pang, Bo and Wang, Haoxiang and Zhao, Han and Zhou, Yingbo and Jiang, Nan and Sahoo, Doyen and Xiong, Caiming and Zhang, Tong , booktitle =. 2024 , eprint =. doi:10.48550/arXiv.2405.07863 , url =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2405.07863 2024
-
[40]
doi:10.48550/ARXIV.2401.06080 , url =
Wang, Binghai and Zheng, Rui and Chen, Lu and Liu, Yan and Dou, Shihan and Huang, Caishuang and Shen, Wei and Jin, Senjie and Zhou, Enyu and Shi, Chenyu and Gao, Songyang and Xu, Nuo and Zhou, Yuhao and Fan, Xiaoran and Xi, Zhiheng and Zhao, Jun and Wang, Xiao and Ji, Tao and Yan, Hang and Shen, Lixing and Chen, Zhan and Gui, Tao and Zhang, Qi and Qiu, Xi...
-
[41]
2025 , url=
Tianqi Liu and Wei Xiong and Jie Ren and Lichang Chen and Junru Wu and Rishabh Joshi and Yang Gao and Jiaming Shen and Zhen Qin and Tianhe Yu and Daniel Sohn and Anastasia Makarova and Jeremiah Zhe Liu and Yuan Liu and Bilal Piot and Abe Ittycheriah and Aviral Kumar and Mohammad Saleh , booktitle=. 2025 , url=
2025
-
[42]
2025 , eprint=
Unified Reward Model for Multimodal Understanding and Generation , author=. 2025 , eprint=
2025
-
[43]
2026 , eprint=
AdaJudge: Adaptive Multi-Perspective Judging for Reward Modeling , author=. 2026 , eprint=
2026
-
[44]
12 Haoxiang Wang, Wei Xiong, Tengyang Xie, Han Zhao, and Tong Zhang
Wang, Haoxiang and Xiong, Wei and Xie, Tengyang and Zhao, Han and Zhang, Tong. Findings of the Association for Computational Linguistics: EMNLP 2024. 2024. doi:10.18653/v1/2024.findings-emnlp.620
-
[45]
2026 , eprint=
Auto-Rubric as Reward: From Implicit Preferences to Explicit Multimodal Generative Criteria , author=. 2026 , eprint=
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.