DeadPool: Resilient LLM Training with Hot-Swapping via Zero-Overhead Checkpoint
Pith reviewed 2026-07-03 17:24 UTC · model grok-4.3
The pith
DeadPool lets LLM training jobs survive permanent node failures by hot-swapping spares using zero-overhead in-memory checkpoints.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
DeadPool restores LLM training via hot-swapping of failed nodes with spare nodes without terminating the job, enabled by an off-critical-path in-memory checkpointing mechanism that supplies spatial redundancy and a communicator reconstruction protocol that operates at runtime; the checkpointing overlaps fully with computation so that error-free execution incurs zero overhead, and upon permanent failure the system rebuilds memory states from the in-memory copies with only minimal recomputation.
What carries the argument
Off-critical-path in-memory checkpointing for spatial redundancy together with the runtime communicator reconstruction protocol that performs the hot-swap.
If this is right
- LLM training jobs continue after a node failure instead of requiring a full restart.
- Error-free runs incur no measurable slowdown from the added fault-tolerance machinery.
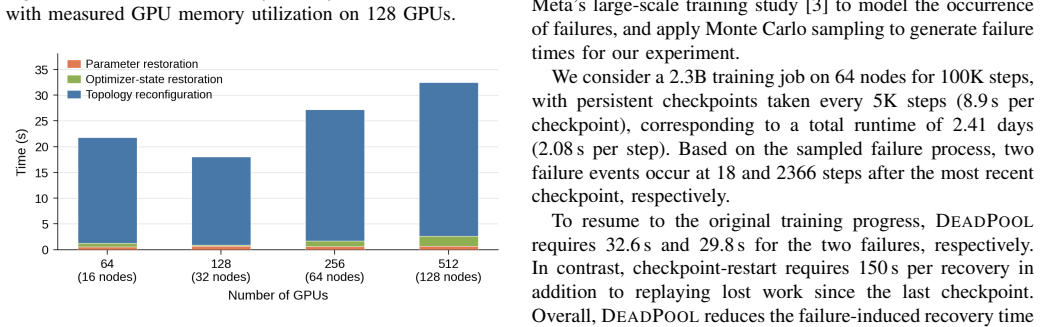
- Recovery from permanent node loss completes in under 40 seconds even at hundreds of GPUs.
- The same checkpoint data that enables fast recovery also avoids recomputing large portions of prior work.
Where Pith is reading between the lines
- The design could extend to other collective-communication workloads that already maintain spare capacity.
- If spare-node availability proves unreliable in practice, the recovery guarantee would need an alternative fallback path.
- The zero-overhead property could be verified by comparing iteration times with and without the checkpointing threads active on identical hardware.
Load-bearing premise
The checkpointing work can be placed completely off the critical path so that it truly adds zero cost to normal execution, and spare nodes plus the reconstruction protocol can be assumed available without creating new failure modes or added latency.
What would settle it
A measurement that shows the in-memory checkpointing step measurably slows the forward or backward pass on the same hardware, or a failure scenario where the hot-swap recovery exceeds 40 seconds at the 512-GPU scale.
Figures




read the original abstract
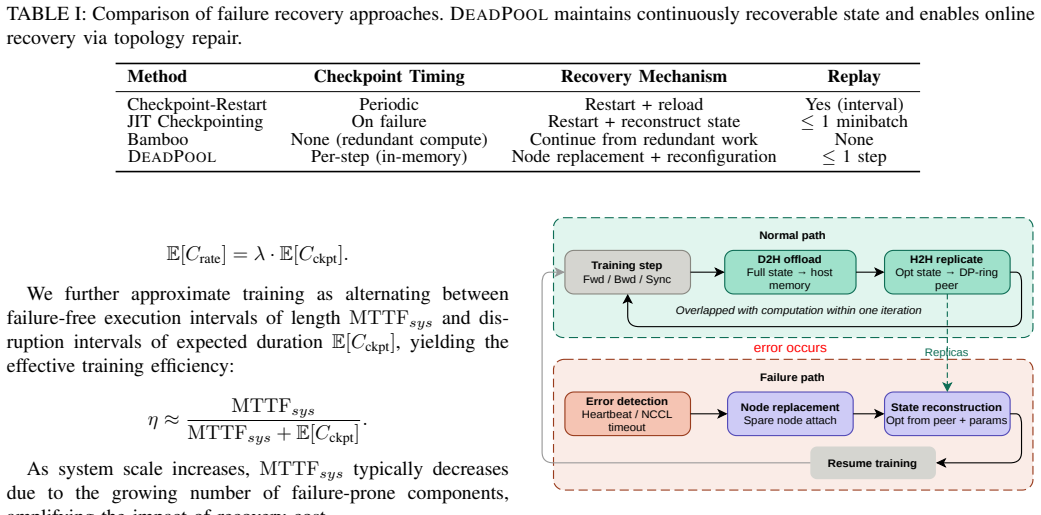
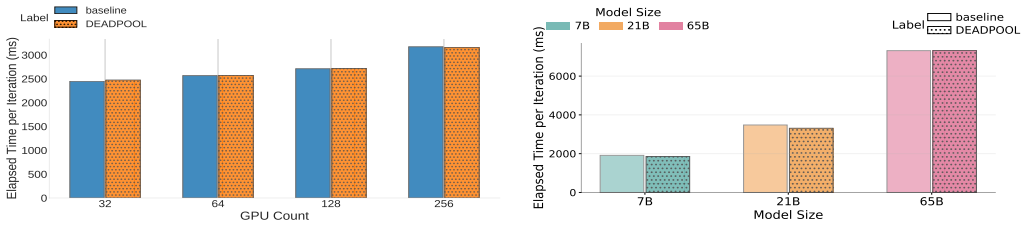
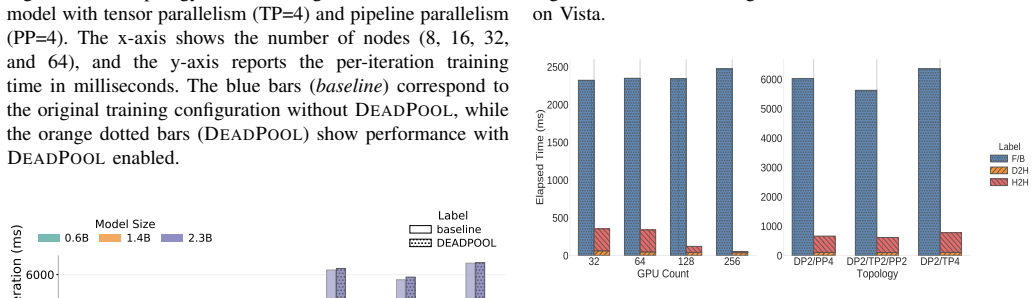
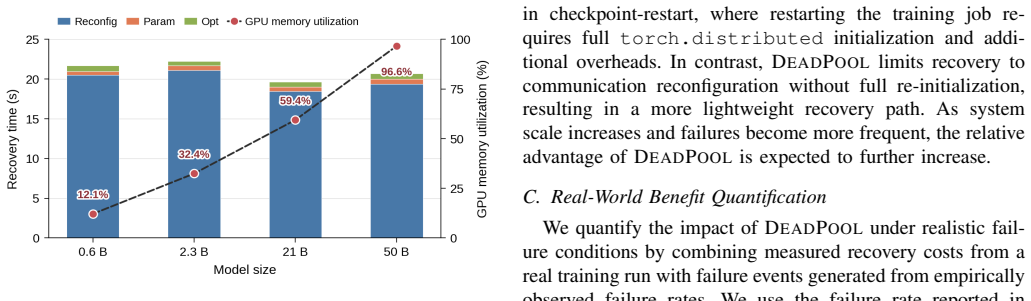
State-of-the-art large language model (LLM) training takes tens of thousands of graphics processing units (GPUs) for months and encounters failures across the software and hardware stack. Existing fault-tolerance mechanisms either impose non-trivial overhead during failure-free execution or suffer from prolonged recovery latency, particularly under scenarios where a small subset of compute nodes experience permanent failures. %The tradeoff between failure-free overhead and recovery latency forms a space forms a Pareto frontier We present DeadPool to simultaneously address both optimization objectives. DeadPool incorporates a fault-tolerance mechanism that restores LLM training via hot-swapping, namely by replacing failed nodes with spare nodes without terminating the complete job. The hot-swapping of DeadPool is enabled by two ideas: First, it exploits an off-critical-path in-memory checkpointing mechanism for spatial redundancy. Second, it introduces a communicator reconstruction protocol that replaces failed nodes with spare nodes at runtime. DeadPool efficiently overlaps the in-memory checkpointing with computation, thus introducing zero overhead during error-free execution. Upon permanent node failures, DeadPool can rebuild memory states with minimal recomputation by leveraging in-memory checkpoints. We evaluate DeadPool across scales (up to 512 NVIDIA A100 GPUs) and LLMs (up to 65B parameters), and observe zero checkpoint overhead with hot-swapping recovery completing in under 40 seconds. These results show that DeadPool simultaneously achieves both zero-overhead error-free execution and extremely low recovery cost.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents DeadPool, a fault-tolerance mechanism for large-scale LLM training. It achieves zero overhead during error-free execution via an off-critical-path in-memory checkpointing scheme that overlaps with computation, and enables hot-swapping recovery upon permanent node failures through a communicator reconstruction protocol that replaces failed nodes with spares while leveraging the checkpoints for minimal recomputation. The system is evaluated at scales up to 512 NVIDIA A100 GPUs and models up to 65B parameters, with reported results of zero checkpoint overhead and recovery completing in under 40 seconds.
Significance. If the reported measurements hold, the work is significant because it simultaneously eliminates the failure-free overhead that typically accompanies checkpointing and delivers extremely low recovery latency, addressing a central practical barrier to reliable long-running distributed training jobs. The direct empirical support at substantial scale (512 GPUs, 65B parameters) constitutes independent evidence for the overlap and reconstruction mechanisms.
minor comments (1)
- Abstract: the largest-scale configuration (exact model size, number of nodes, and failure injection details) could be stated more precisely to allow readers to immediately assess the scope of the zero-overhead and sub-40 s claims.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of DeadPool, the recognition of its significance for large-scale LLM training, and the recommendation for minor revision. No major comments were provided in the report.
Circularity Check
No significant circularity
full rationale
This is a systems paper presenting a fault-tolerance mechanism for LLM training. It contains no mathematical derivations, equations, fitted parameters, or predictions derived from models. All claims rest on described design choices (off-critical-path checkpointing, communicator reconstruction) and direct empirical measurements (zero overhead observed, <40s recovery on up to 512 GPUs). No self-citation chains, self-definitional steps, or renamings of known results appear. The evaluation constitutes independent evidence outside any internal reduction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Spare compute nodes are available and the network allows runtime communicator reconstruction without job termination
invented entities (1)
-
Communicator reconstruction protocol
no independent evidence
Reference graph
Works this paper leans on
-
[1]
A. Grattafiori, A. Dubey, A. Jauhri, A. Pandey, A. Kadian, A. Al-Dahle, A. Letman, A. Mathur, A. Schelten, A. Vaughanet al., “The llama 3 herd of models,”arXiv preprint arXiv:2407.21783, 2024. [Online]. Available: https://arxiv.org/abs/2407.21783
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
Opt-175b baselines logbook,
MetaSeq, “Opt-175b baselines logbook,” 2022, https://github. com/facebookresearch/metaseq/blob/main/projects/OPT/chronicles/ OPT175B Logbook.pdf
2022
-
[4]
D. Narayanan, M. Shoeybi, J. Casper, P. LeGresley, M. Patwary, and B. Catanzaro, “Efficient large-scale language model training on gpu clusters using megatron-lm,”arXiv preprint arXiv:2104.04473, 2021. [Online]. Available: https://arxiv.org/abs/2104.04473
-
[5]
Datastates-llm: Lazy asynchronous checkpointing for large language models,
A. Maurya, R. Underwood, M. M. Rafique, F. Cappello, and B. Nicolae, “Datastates-llm: Lazy asynchronous checkpointing for large language models,” inProceedings of the 33rd international symposium on high- performance parallel and distributed computing, 2024, pp. 227–239. doi: 10.1145/3625549.3658685
-
[6]
Bytecheckpoint: a unified checkpointing system for large foundation model development,
B. Wan, M. Han, Y . Sheng, Y . Peng, H. Lin, M. Zhang, Z. Lai, M. Yu, J. Zhang, Z. Song, X. Liu, and C. Wu, “Bytecheckpoint: a unified checkpointing system for large foundation model development,” inProceedings of the 22nd USENIX Symposium on Networked Systems Design and Implementation, ser. NSDI ’25. USA: USENIX Association, 2025. [Online]. Available: ht...
-
[7]
Transom: An Efficient Fault-Tolerant System for Training LLMs,
B. Wu, L. Xia, Q. Li, K. Li, X. Chen, Y . Guo, T. Xiang, Y . Chen, and S. Li, “Transom: An Efficient Fault-Tolerant System for Training LLMs,” 2023. doi: 10.48550/arXiv.2310.10046 . [Online]. Available: https://arxiv.org/abs/2310.10046
-
[8]
X. Lian, S. A. Jacobs, L. Kurilenko, M. Tanaka, S. Bekman, O. Ruwase, and M. Zhang, “Universal checkpointing: a flexible and efficient dis- tributed checkpointing system for large-scale dnn training with recon- figurable parallelism,” inProceedings of the 2025 USENIX Conference on Usenix Annual Technical Conference, ser. USENIX ATC ’25. USA: USENIX Associ...
-
[9]
CheckFreq: Frequent, Fine-Grained DNN checkpointing,
J. Mohan, A. Phanishayee, and V . Chidambaram, “CheckFreq: Frequent, Fine-Grained DNN checkpointing,” in19th USENIX Conference on File and Storage Technologies (FAST 21). USENIX Association, Feb. 2021, pp. 203–216. [Online]. Available: https: //www.usenix.org/conference/fast21/presentation/mohan
2021
-
[10]
Bamboo: Making preemptible instances resilient for affordable training of large DNNs,
J. Thorpe, P. Zhao, J. Eyolfson, Y . Qiao, Z. Jia, M. Zhang, R. Netravali, and G. H. Xu, “Bamboo: Making preemptible instances resilient for affordable training of large DNNs,” in20th USENIX Symposium on Networked Systems Design and Implementation (NSDI 23), 2023, pp. 497–513. [Online]. Available: https://arxiv.org/abs/2204.12013
-
[11]
PyTorch: An Imperative Style, High-Performance Deep Learning Library
A. Paszke, S. Gross, F. Massa, A. Lerer, J. Bradbury, G. Chanan, T. Killeen, Z. Lin, N. Gimelshein, and L. Antiga, “Pytorch: An imperative style, high-performance deep learning library,”Advances in neural information processing systems, vol. 32, pp. 8026–8037, 2019. [Online]. Available: https://arxiv.org/abs/1912.01703
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[12]
Fti: high performance fault tolerance interface for hybrid systems,
L. Bautista-Gomez, S. Tsuboi, D. Komatitsch, F. Cappello, N. Maruyama, and S. Matsuoka, “Fti: high performance fault tolerance interface for hybrid systems,” inProceedings of 2011 International Conference for High Performance Computing, Networking, Storage and Analysis, ser. SC ’11. New York, NY , USA: Association for Computing Machinery, 2011. doi: 10.11...
-
[13]
On the Opportunities and Risks of Foundation Models
R. Bommasani, D. A. Hudson, E. Adeli, R. Altmanet al., “On the opportunities and risks of foundation models,”Preprint arXiv:2108.07258, 2021. [Online]. Available: https://arxiv.org/abs/2108. 07258
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[14]
Training Compute-Optimal Large Language Models
J. Hoffmann, S. Borgeaud, A. Mensch, E. Buchatskaya, T. Cai, E. Rutherford, D. de Las Casas, L. A. Hendricks, J. Welbl, A. Clark, T. Hennigan, E. Noland, K. Millican, G. van den Driessche, B. Damoc, A. Guy, S. Osindero, K. Simonyan, E. Elsen, J. W. Rae, O. Vinyals, and L. Sifre, “Training compute-optimal large language models,”arXiv preprint arXiv:2203.15...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[15]
Demystifying parallel and distributed deep learning: An in-depth concurrency analysis,
T. Ben-Nun and T. Hoefler, “Demystifying parallel and distributed deep learning: An in-depth concurrency analysis,”ACM Computing Surveys, vol. 52, no. 4, pp. 1–43, 2019. doi: https://doi.org/10.1145/3320060
-
[16]
S. Li, F. Xue, C. Baranwal, Y . Li, and Y . You, “Sequence parallelism: Long sequence training from system perspective,” 2022. [Online]. Available: https://arxiv.org/abs/2105.13120
-
[17]
Blockwise parallel transformers for large context models,
H. Liu and P. Abbeel, “Blockwise parallel transformers for large context models,”Advances in Neural Information Processing Systems, vol. 36,
-
[18]
doi: 10.5555/3666122.3666508
-
[19]
Ring Attention with Blockwise Transformers for Near-Infinite Context
H. Liu, M. Zaharia, and P. Abbeel, “Ring attention with blockwise transformers for near-infinite context,” 2023. [Online]. Available: https://arxiv.org/abs/2310.01889
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[20]
A large-scale study of soft-errors on gpus in the field,
B. Nie, D. Tiwari, S. Gupta, E. Smirni, and J. H. Rogers, “A large-scale study of soft-errors on gpus in the field,” in2016 IEEE International Symposium on High Performance Computer Architecture, HPCA 2016, Barcelona, Spain, March 12-16, 2016. IEEE Computer Society, 2016, pp. 519–530. doi: 10.1109/HPCA.2016.7446091 . [Online]. Available: https://doi.org/1...
-
[21]
A systematic study of ddr4 dram faults in the field,
M. V . Beigi, Y . Cao, S. Gurumurthi, C. Recchia, A. Walton, and V . Sridharan, “A systematic study of ddr4 dram faults in the field,” in2023 IEEE International Symposium on High-Performance Com- puter Architecture (HPCA). IEEE, 2023, pp. 991–1002. doi: 10.1109/HPCA56546.2023.10071066
-
[22]
Code-dependent and architecture-dependent reliability be- haviors,
V . Fratin, D. Oliveira, C. Lunardi, F. Santos, G. Rodrigues, and P. Rech, “Code-dependent and architecture-dependent reliability be- haviors,” in2018 48th Annual IEEE/IFIP International Conference on Dependable Systems and Networks (DSN), 2018, pp. 13–26. doi: 10.1109/DSN.2018.00015
-
[23]
Killi: Runtime fault classification to deploy low voltage caches without MBIST,
S. Ganapathy, J. Kalamatianos, B. M. Beckmann, S. Raasch, and L. G. Szafaryn, “Killi: Runtime fault classification to deploy low voltage caches without MBIST,” in25th IEEE International Symposium on High Performance Computer Architecture, HPCA 2019, Washington, DC, USA, February 16-20, 2019. IEEE, 2019, pp. 304–316. doi: 10.1109/HPCA.2019.00046 . [Online]...
-
[24]
Addressing failures in exascale computing,
M. Snir, R. W. Wisniewski, J. A. Abraham, S. V . Adve, S. Bagchi, P. Balaji, J. Belak, P. Bose, F. Cappello, B. Carlson, A. A. Chien, P. Coteus, N. A. DeBardeleben, P. C. Diniz, C. Engelmann, M. Erez, S. Fazzari, A. Geist, R. Gupta, F. Johnson, S. Krishnamoorthy, S. Leyf- fer, D. Liberty, S. Mitra, T. Munson, R. Schreiber, J. Stearley, and E. V . Hensberg...
-
[25]
Radiation-induced error criticality in modern hpc parallel accelera- tors,
D. A. G. De Oliveira, L. L. Pilla, M. Hanzich, V . Fratin, F. Fernandes, C. Lunardi, J. M. Cela, P. O. A. Navaux, L. Carro, and P. Rech, “Radiation-induced error criticality in modern hpc parallel accelera- tors,” in2017 IEEE International Symposium on High Performance Computer Architecture (HPCA). IEEE, 2017, pp. 577–588. doi: 10.1109/HPCA.2017.41
-
[26]
Quantifying the impact of memory errors in deep learning,
Z. Zhang, L. Huang, R. Huang, W. Xu, and D. S. Katz, “Quantifying the impact of memory errors in deep learning,” in2019 IEEE International Conference on Cluster Computing (CLUSTER). IEEE, 2019, pp. 1–12. doi: 10.1109/CLUSTER.2019.8890989
-
[27]
Understanding and mitigating hardware failures in deep learning training systems,
Y . He, M. Hutton, S. Chan, R. De Gruijl, R. Govindaraju, N. Patil, and Y . Li, “Understanding and mitigating hardware failures in deep learning training systems,” inProceedings of the 50th Annual Inter- national Symposium on Computer Architecture, 2023, pp. 1–16. doi: 10.1145/3579371.3589105
-
[28]
Lifespan and failures of ssds and hdds: Similarities, differences, and prediction models,
R. Pinciroli, L. Yang, J. Alter, and E. Smirni, “Lifespan and failures of ssds and hdds: Similarities, differences, and prediction models,” IEEE Transactions on Dependable and Secure Computing, 2021. doi: 10.1109/TDSC.2021.3131571
-
[29]
Horovod: fast and easy distributed deep learning in TensorFlow
A. Sergeev and M. D. Balso, “Horovod: Fast and easy distributed deep learning in TensorFlow,”arXiv preprint arXiv:1802.05799, 2018. [Online]. Available: https://arxiv.org/abs/1802.05799
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[30]
Analysis of large-scale multi-tenant gpu clusters for dnn training workloads,
M. Jeon, S. Venkataraman, A. Phanishayee, J. Qian, W. Xiao, and F. Yang, “Analysis of large-scale multi-tenant gpu clusters for dnn training workloads,” 2019. [Online]. Available: https: //arxiv.org/abs/1901.05758
-
[31]
MLaaS in the wild: Workload analysis and scheduling in Large-Scale heterogeneous GPU clusters,
Q. Weng, W. Xiao, Y . Yu, W. Wang, C. Wang, J. He, Y . Li, L. Zhang, W. Lin, and Y . Ding, “MLaaS in the wild: Workload analysis and scheduling in Large-Scale heterogeneous GPU clusters,” in19th USENIX Symposium on Networked Systems Design and Implementation (NSDI 22), 2022, pp. 945–960. [Online]. Available: https://www.usenix.org/conference/nsdi22/presen...
2022
-
[32]
Easyscale: Elastic training with con- sistent accuracy and improved utilization on gpus,
M. Li, W. Xiao, H. Yang, B. Sun, H. Zhao, S. Ren, Z. Luan, X. Jia, Y . Liu, Y . Li, W. Lin, and D. Qian, “Easyscale: Elastic training with con- sistent accuracy and improved utilization on gpus,” inProceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, 2023, pp. 1–14. doi: 10.1145/3581784.3607054
-
[33]
Dlrover-rm: Resource optimization for deep recommendation models training in the cloud,
Q. Wang, T. Lan, Y . Tang, Z. Huang, Y . Du, H. Zhang, J. Sha, H. Lu, Y . Zhou, K. Zhang, and M. Tang, “Dlrover-rm: Resource optimization for deep recommendation models training in the cloud,” 2024. [Online]. Available: https://arxiv.org/abs/2304.01468
-
[34]
Varuna: scalable, low-cost training of massive deep learning models,
S. Athlur, N. Saran, M. Sivathanu, R. Ramjee, and N. Kwatra, “Varuna: scalable, low-cost training of massive deep learning models,” inProceedings of the Seventeenth European Conference on Computer Systems, 2022, pp. 472–487. [Online]. Available: https://api.semanticscholar.org/CorpusID:243847496
2022
-
[35]
Oobleck: Resilient distributed training of large models using pipeline templates,
I. Jang, Z. Yang, Z. Zhang, X. Jin, and M. Chowdhury, “Oobleck: Resilient distributed training of large models using pipeline templates,” inProceedings of the 29th Symposium on Operating Systems Principles, 2023, pp. 382–395. doi: 10.1145/3600006.3613152
-
[36]
Parcae: Proactive,Liveput-Optimized DNN Training on Preemptible Instances,
J. Duan, Z. Song, X. Miao, X. Xi, D. Lin, H. Xu, M. Zhang, and Z. Jia, “Parcae: Proactive,Liveput-Optimized DNN Training on Preemptible Instances,” in21st USENIX Symposium on Networked Systems Design and Implementation (NSDI 24), 2024, pp. 1121–1139. [Online]. Available: https://arxiv.org/abs/2403.14097
-
[37]
Slipstream: Adapting pipelines for distributed training of large dnns amid failures,
S. Gandhi, M. Zhao, A. Skiadopoulos, and C. Kozyrakis, “Slipstream: Adapting pipelines for distributed training of large dnns amid failures,”arXiv preprint arXiv:2405.14009, 2024. doi: 10.48550/arXiv.2405.14009
-
[38]
CheckFreq: Frequent,Fine-Grained DNN Checkpointing,
J. Mohan, A. Phanishayee, and V . Chidambaram, “CheckFreq: Frequent,Fine-Grained DNN Checkpointing,” in19th USENIX Conference on File and Storage Technologies (FAST 21), 2021, pp. 203–216. [Online]. Available: https://par.nsf.gov/biblio/10286595
-
[39]
Gemini: Fast failure recovery in distributed training with in-memory checkpoints,
Z. Wang, Z. Jia, S. Zheng, Z. Zhang, X. Fu, T. E. Ng, and Y . Wang, “Gemini: Fast failure recovery in distributed training with in-memory checkpoints,” inProceedings of the 29th Symposium on Operating Systems Principles, 2023, pp. 364–381. doi: 10.1145/3600006.3613145
-
[40]
FastPersist: Accelerating Model Checkpointing in Deep Learning,
G. Wang, O. Ruwase, B. Xie, and Y . He, “FastPersist: Accelerating Model Checkpointing in Deep Learning,”arXiv preprint arXiv:2406.13768, 2024. [Online]. Available: https: //arxiv.org/abs/2406.13768
-
[41]
Just-in-time checkpointing: Low cost error recovery from deep learning training failures,
T. Gupta, S. Krishnan, R. Kumar, A. Vijeev, B. Gulavani, N. Kwatra, R. Ramjee, and M. Sivathanu, “Just-in-time checkpointing: Low cost error recovery from deep learning training failures,” inProceedings of the Nineteenth European Conference on Computer Systems, 2024, pp. 1110–1125. doi: 10.1145/3627703.3650085
-
[42]
Efficient fault tolerance for recommendation model training via erasure coding,
T. Zhang, K. Liu, J. Kosaian, J. Yang, and R. Vinayak, “Efficient fault tolerance for recommendation model training via erasure coding,” Proceedings of the VLDB Endowment, vol. 16, no. 11, pp. 3137–3150,
-
[43]
doi: 10.14778/3611479.3611514
-
[44]
Check-N-Run: A checkpointing system for training deep learning recommendation models,
A. Eisenman, K. K. Matam, S. Ingram, D. Mudigere, R. Krishnamoorthi, K. Nair, M. Smelyanskiy, and M. Annavaram, “Check-N-Run: A checkpointing system for training deep learning recommendation models,” in19th USENIX Symposium on Networked Systems Design and Implementation (NSDI 22), 2022, pp. 929–943. [Online]. Available: https://www.usenix.org/conference/n...
2022
-
[45]
K. Maeng, S. Bharuka, I. Gao, M. C. Jeffrey, V . Saraph, B.-Y . Su, C. Trippel, J. Yang, M. Rabbat, B. Lucia, and C.-J. Wu, “Cpr: Understanding and improving failure tolerant training for deep learning recommendation with partial recovery,” 2020. [Online]. Available: https://arxiv.org/abs/2011.02999
-
[46]
Fine-grained policy-driven i/o sharing for burst buffers,
E. Karrels, L. Huang, Y . Kan, I. Arora, Y . Wang, D. S. Katz, W. Gropp, and Z. Zhang, “Fine-grained policy-driven i/o sharing for burst buffers,” inProceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, ser. SC ’23. New York, NY , USA: Association for Computing Machinery, 2023. doi: 10.1145/3581784.3...
-
[47]
Training llms with fault tolerant hsdp on 100,000 gpus,
O. Salpekar, R. Varma, K. Yu, V . Ivanov, Y . Wang, A. Sharif, M. Si, S. Xu, F. Tian, S. Zheng, T. Rice, A. Garg, S. Peng, S. Siravara, W. Fu, R. de Castro, A. Gangidi, A. Obraztsov, S. Narang, S. Edunov, M. Naumov, C. Tang, and M. Oldham, “Training llms with fault tolerant hsdp on 100,000 gpus,” 2026. [Online]. Available: https://arxiv.org/abs/2602.00277
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.