Internal Data Repetition Destroys Language Models
Pith reviewed 2026-06-26 00:11 UTC · model grok-4.3
The pith
Repeating documents in training data produces loss peaks at intermediate repeat counts that can waste a third of effective compute.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
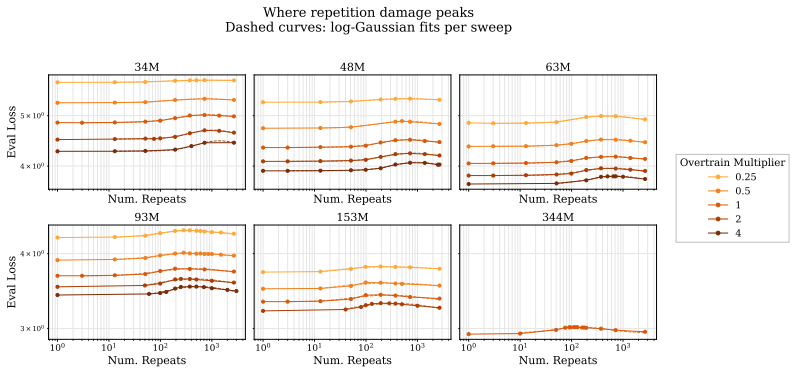
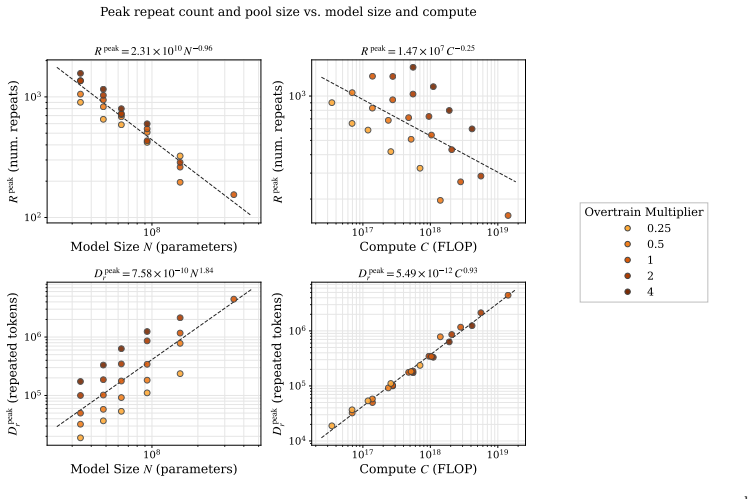
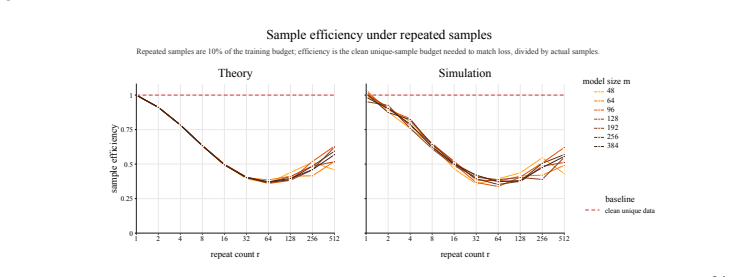
Holding compute allocated to repeated data constant, eval loss peaks at an intermediate repeat count Rep. The location of this peak is well-fit by a power law in model size. When repeated documents consume 10% of the FLOPs budget, the compute-equivalent loss can be large: on FineWeb-Edu-Dedup, the most damaging repeat count for a Qwen3-style 344M-parameter model at OT=1 matches the loss of a no-repetition run using 67% of the FLOPs. These phenomena appear in both language models and a misspecified linear regression with verbatim duplicates, which reproduces the loss peak from the statistical tradeoff between memorization and generalization.
What carries the argument
Compute-equivalent loss, obtained by comparing repeated-data performance to the prediction of a fitted no-repetition scaling law at matched total compute.
If this is right
- The most damaging repeat count grows more quickly than compute as model size increases.
- Repeating a moderately sized subset a moderate number of times damages performance more than repeating large subsets few times or small subsets many times.
- The same loss peak and scaling appear in a misspecified linear regression with duplicates, showing the effect is not language-model specific.
- The method allows direct quantification of compute wasted by the presence and repeat structure of duplicates in pretraining corpora.
Where Pith is reading between the lines
- Data pipelines could prioritize removal of moderate-repetition patterns to avoid the identified loss peak.
- Larger models will become increasingly sensitive to repeat structure because the damaging repeat count scales faster than compute.
- Similar repetition effects may occur in other supervised learning settings whenever duplicate examples are present.
- The statistical model suggests that correctly specifying the regression to account for duplicates would eliminate the loss peak.
Load-bearing premise
A scaling law fitted only on non-repeated data runs can accurately forecast the loss a non-repeated run would achieve at the same total compute level as a repeated-data experiment.
What would settle it
Train a model with no repetition at the exact compute level of a repeated run and verify whether its loss equals the value predicted by the no-repetition scaling law; a mismatch would show the compute-equivalent loss metric does not hold.
Figures






read the original abstract
Language models are running out of high-quality training data, and even aggressively deduplicated corpora retain some amount of repetition. Earlier controlled studies predated Chinchilla-style scaling laws and could only measure the cost of repetition indirectly. We revisit repetition in the Chinchilla era, using a fitted no-repetition scaling law to report Compute-Equivalent Gain and Compute-Equivalent Loss. We show that under this modernized paradigm, repetition damage is systematic in three ways. First, holding compute allocated to repeated data constant, eval loss peaks at an intermediate repeat count $\Rep$; repeating a moderately sized subset a moderate number of times damages performance more than repeating a large subset a few times or a small subset many times. Second, the location of this peak is well-fit by a power law in model size; this scaling law reveals that the most damaging number of repeated data grows more quickly than compute. Finally, when repeated documents consume 10\% of the FLOPs budget in a controlled exact-document repetition setting, the compute-equivalent loss can be large: on FineWeb-Edu-Dedup, the most damaging repeat count for a Qwen3-style 344M-parameter model at $\OT=1$ matches the loss of a no-repetition run using 67% of the FLOPs. We demonstrate that these phenomena are not language-model-specific, and can be analytically understood in a simple statistical model: a misspecified linear regression with verbatim duplicates reproduces the same qualitative loss peak, quantifying how such peaks can arise from a statistical tradeoff between memorization and generalization. Our findings add precision to the study of duplication in language models, allowing practitioners to quantify the wasted compute incurred by the presence and repeat structure of duplicates in pretraining corpora.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that internal repetition of documents in pretraining data systematically damages language model performance. Using a scaling law fitted exclusively to no-repetition runs, it defines compute-equivalent loss and shows that, for fixed compute allocated to repeats, eval loss peaks at an intermediate repeat count whose location scales as a power law in model size; at 10% FLOPs spent on repeats, the most damaging repeat count for a 344M model on FineWeb-Edu-Dedup produces loss equivalent to a no-repetition run at only 67% of the FLOPs. The same qualitative peak is reproduced in a misspecified linear-regression toy model with verbatim duplicates.
Significance. If the central quantitative claims hold, the work supplies a practical metric (compute-equivalent loss) for assessing the cost of duplicates that remain after aggressive deduplication, which is directly relevant to current data-scarcity constraints. The analytic reproduction of the loss peak inside a simple statistical model is a clear strength, as it isolates a memorization-generalization tradeoff without relying on language-model-specific mechanisms.
major comments (1)
- [Abstract and Compute-Equivalent Loss definition] Abstract (paragraph on Compute-Equivalent Loss) and the associated methods section: the reported compute-equivalent loss values (e.g., 67% FLOPs equivalence) are obtained by inverting a power-law scaling law whose parameters were fitted solely on separate no-repetition runs. No experiment is reported that checks whether the same fitted law correctly predicts the loss of an actual no-repetition run at the reduced compute budget when the training distribution contains verbatim duplicates; any systematic shift in the loss surface would therefore render the headline numbers non-independent of the assumed functional form.
minor comments (2)
- [Abstract] Notation for repeat count (\Rep) and OT=1 is introduced without an explicit equation or table reference in the abstract; a short definitional sentence or pointer to the methods section would improve readability.
- [Toy model section] The toy-model section states that the linear regression reproduces the "same qualitative loss peak"; a brief quantitative comparison (e.g., location of the peak as a function of model size) would strengthen the claim that the statistical model captures the essential tradeoff.
Simulated Author's Rebuttal
We thank the referee for the thoughtful comment on the compute-equivalent loss definition. We respond point-by-point below and outline the changes we will make.
read point-by-point responses
-
Referee: [Abstract and Compute-Equivalent Loss definition] Abstract (paragraph on Compute-Equivalent Loss) and the associated methods section: the reported compute-equivalent loss values (e.g., 67% FLOPs equivalence) are obtained by inverting a power-law scaling law whose parameters were fitted solely on separate no-repetition runs. No experiment is reported that checks whether the same fitted law correctly predicts the loss of an actual no-repetition run at the reduced compute budget when the training distribution contains verbatim duplicates; any systematic shift in the loss surface would therefore render the headline numbers non-independent of the assumed functional form.
Authors: The compute-equivalent loss is defined by design as the FLOPs budget at which a no-repetition run would reach the observed loss, obtained by inverting the scaling law fitted exclusively on no-repetition data. This yields a standardized, counterfactual measure of repetition damage relative to the optimal no-repetition regime; the paper does not claim or require that the same scaling law holds when duplicates are present. We agree that explicit validation of the fitted law strengthens the result. In the revision we will add (i) a direct comparison of predicted versus observed losses on the no-repetition runs used for fitting and (ii) new no-repetition training runs performed at the precise reduced compute budgets corresponding to the reported equivalence points (e.g., 67 % FLOPs), confirming that the inversion accurately recovers the measured loss. revision: yes
Circularity Check
No significant circularity; scaling law is independent benchmark
full rationale
The paper fits a no-repetition scaling law exclusively on separate no-repetition runs and applies it only as an external benchmark to translate observed losses from repetition experiments into equivalent-compute numbers. This does not reduce any reported result to its inputs by construction, nor does any central claim (peak location, 67% FLOPs equivalence) become a tautology. No self-citations, uniqueness theorems, or ansatzes are invoked as load-bearing steps. The derivation remains self-contained against the independent no-repetition data.
Axiom & Free-Parameter Ledger
free parameters (1)
- no-repetition scaling law parameters
axioms (1)
- domain assumption The functional form of the no-repetition scaling law remains valid when applied to repeated-data training runs.
Reference graph
Works this paper leans on
-
[1]
Position: Will we run out of data? limits of LLM scaling based on human- generated data
Pablo Villalobos, Anson Ho, Jaime Sevilla, Tamay Besiroglu, Lennart Heim, and Marius Hobbhahn. Position: Will we run out of data? limits of LLM scaling based on human- generated data. InForty-first International Conference on Machine Learning, 2024. URL https://openreview.net/forum?id=ViZcgDQjyG
2024
-
[2]
A pretrainer’s guide to training data: Measuring the effects of data age, domain coverage, quality, and toxicity
Shayne Longpre, Gregory Yauney, Emily Reif, Katherine Lee, Adam Roberts, Barret Zoph, Denny Zhou, Jason Wei, Kevin Robinson, David Mimno, and Daphne Ippolito. A pretrainer’s guide to training data: Measuring the effects of data age, domain coverage, quality, and toxicity. InProceedings of the 2024 Conference of NAACL: Human Language Technologies, pages 32...
2024
-
[3]
The fineweb datasets: Decanting the web for the finest text data at scale
Guilherme Penedo, Hynek Kydlí ˇcek, Loubna Ben Allal, Anton Lozhkov, Margaret Mitchell, Colin Raffel, Leandro V on Werra, and Thomas Wolf. The FineWeb datasets: Decanting the web for the finest text data at scale. InAdvances in Neural Infor- mation Processing Systems (NeurIPS), Datasets and Benchmarks Track, 2024. doi: 10.52202/079017-0970. URL https://pa...
-
[4]
and Carmon, Yair and Dave, Achal and Schmidt, Ludwig and Shankar, Vaishaal , booktitle =
Jeffrey Li, Alex Fang, Georgios Smyrnis, Maor Ivgi, Matt Jordan, Samir Gadre, Hritik Bansal, Etash Guha, Sedrick Keh, Kushal Arora, Saurabh Garg, Rui Xin, Niklas Muennighoff, Reinhard Heckel, Jean Mercat, Mayee Chen, Suchin Gururangan, Mitchell Wortsman, Alon Albalak, Yonatan Bitton, Marianna Nezhurina, Amro Abbas, Cheng-Yu Hsieh, Dhruba Ghosh, Josh Gardn...
-
[5]
Peters, Ab- hilasha Ravichander, Kyle Richardson, Zejiang Shen, Emma Strubell, Nishant Subramani, Oyvind Tafjord, Pete Walsh, Luke Zettlemoyer, Noah A
Luca Soldaini, Rodney Kinney, Akshita Bhagia, Dustin Schwenk, David Atkinson, Russell Authur, Ben Bogin, Khyathi Chandu, Jennifer Dumas, Yanai Elazar, Valentin Hofmann, Ananya Harsh Jha, Sachin Kumar, Li Lucy, Xinxi Lyu, Nathan Lambert, Ian Magnusson, Jacob Morrison, Niklas Muennighoff, Aakanksha Naik, Crystal Nam, Matthew E. Peters, Ab- hilasha Ravichand...
2024
-
[6]
Maurice Weber, Daniel Y . Fu, Quentin Anthony, Yonatan Oren, Shane Adams, Anton Alexan- drov, Xiaozhong Lyu, Huu Nguyen, Xiaozhe Yao, Virginia Adams, Ben Athiwaratkun, Rahul Chalamala, Kezhen Chen, Max Ryabinin, Tri Dao, Percy Liang, Christopher Ré, Irina Rish, and Ce Zhang. RedPajama: An open dataset for training large language models. InAdvances in Neur...
-
[7]
Deduplicating Training Data Makes Language Models Better , booktitle =
Katherine Lee, Daphne Ippolito, Andrew Nystrom, Chiyuan Zhang, Douglas Eck, Chris Callison-Burch, and Nicholas Carlini. Deduplicating training data makes language mod- els better. InProceedings of the 60th Annual Meeting of the Association for Computational Linguistics (ACL), 2022. doi: 10.18653/v1/2022.acl-long.577. URL https://aclanthology. org/2022.acl...
-
[8]
Amro Abbas, Kushal Tirumala, Dániel Simig, Surya Ganguli, and Ari S. Morcos. SemD- eDup: Data-efficient learning at web-scale through semantic deduplication.arXiv preprint arXiv:2303.09540, 2023. URLhttps://arxiv.org/abs/2303.09540
Pith/arXiv arXiv 2023
-
[9]
Kushal Tirumala, Daniel Simig, Armen Aghajanyan, and Ari S. Morcos. D4: Improving llm pretraining via document de-duplication and diversification. InAdvances in Neural Information Processing Systems (NeurIPS), 2023. URL https://papers.nips.cc/paper_files/ paper/2023/hash/a8f8cbd7f7a5fb2c837e578c75e5b615-Abstract-Datasets_and_ Benchmarks.html
2023
-
[10]
Scale dependent data duplication.arXiv preprint arXiv:2603.06603, 2026
Joshua Kazdan, Noam Levi, Rylan Schaeffer, Jessica Chudnovsky, Abhay Puri, Bo He, Mehmet Donmez, Sanmi Koyejo, and David Donoho. Scale dependent data duplication.arXiv preprint arXiv:2603.06603, 2026. URLhttps://arxiv.org/abs/2603.06603
arXiv 2026
-
[11]
Danny Hernandez, Tom Brown, Tom Conerly, Nova DasSarma, Dawn Drain, Sheer El-Showk, Nelson Elhage, Zac Hatfield-Dodds, Tom Henighan, Tristan Hume, Scott Johnston, Ben Mann, Chris Olah, Catherine Olsson, Dario Amodei, Nicholas Joseph, Jared Kaplan, and Sam Mc- Candlish. Scaling laws and interpretability of learning from repeated data.arXiv preprint arXiv:2...
Pith/arXiv arXiv 2022
-
[12]
Rae, Oriol Vinyals, and Laurent Sifre
Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, Diego de Las Casas, Lisa Anne Hendricks, Johannes Welbl, Aidan Clark, Tom Hennigan, Eric Noland, Katie Millican, George van den Driess- che, Bogdan Damoc, Aurelia Guy, Simon Osindero, Karen Simonyan, Erich Elsen, Jack W. Rae, Oriol Vinyals, and Laurent Sif...
-
[13]
URL https://proceedings.neurips.cc/paper_files/paper/2022/hash/ c1e2faff6f588870935f114ebe04a3e5-Abstract-Conference.html
2022
-
[14]
On the origin of algorithmic progress in ai, 2025
Hans Gundlach, Alex Fogelson, Jayson Lynch, Ana Trisovic, Jonathan Rosenfeld, Anmol Sandhu, and Neil Thompson. On the origin of algorithmic progress in ai, 2025. URL https: //arxiv.org/abs/2511.21622
arXiv 2025
-
[15]
AI capabilities can be significantly improved without expensive retraining, 2023
Tom Davidson, Jean-Stanislas Denain, Pablo Villalobos, and Guillem Bas. AI capabilities can be significantly improved without expensive retraining, 2023. URL https://arxiv.org/ abs/2312.07413
arXiv 2023
-
[16]
Introducing Muse Spark: Scaling towards personal superintelli- gence, April 2026
Meta Superintelligence Labs. Introducing Muse Spark: Scaling towards personal superintelli- gence, April 2026. URL https://ai.meta.com/blog/introducing-muse-spark-msl/ . Accessed: 2026-05-06
2026
-
[17]
Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jing Zhou, Jingren Zhou, Junyang Lin, Kai Dang, Keqin Bao, Kexin Yang, ...
Pith/arXiv arXiv 2025
-
[18]
Language models scale reliably with over-training and on downstream tasks
Samir Yitzhak Gadre, Georgios Smyrnis, Vaishaal Shankar, Suchin Gururangan, Mitchell Wortsman, Rulin Shao, Jean Mercat, Alex Fang, Jeffrey Li, Sedrick Keh, Rui Xin, Marianna Nezhurina, Igor Vasiljevic, Luca Soldaini, Jenia Jitsev, Alex Dimakis, Gabriel Ilharco, Pang Wei Koh, Shuran Song, Thomas Kollar, Yair Carmon, Achal Dave, Reinhard Heckel, Niklas Muen...
-
[19]
URLhttps://openreview.net/forum?id=iZeQBqJamf
-
[20]
Resolving discrepancies in compute-optimal scaling of language models
Tomer Porian, Mitchell Wortsman, Jenia Jitsev, Ludwig Schmidt, and Yair Carmon. Resolving discrepancies in compute-optimal scaling of language models. InThe Thirty-eighth Annual 11 Conference on Neural Information Processing Systems, 2024. URL https://openreview. net/forum?id=4fSSqpk1sM
2024
-
[21]
Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei
Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B. Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. Scaling laws for neural language models.arXiv preprint arXiv:2001.08361, 2020. URL https://arxiv.org/abs/ 2001.08361
Pith/arXiv arXiv 2001
-
[22]
Beyond chinchilla-optimal: Accounting for inference in language model scaling laws
Nikhil Sardana, Jacob Portes, Sasha Doubov, and Jonathan Frankle. Beyond chinchilla-optimal: Accounting for inference in language model scaling laws. InForty-first International Conference on Machine Learning, 2024. URLhttps://openreview.net/forum?id=0bmXrtTDUu
2024
-
[23]
Chinchilla scaling: A replication attempt.arXiv preprint arXiv:2404.10102, 2024
Tamay Besiroglu, Ege Erdil, Matthew Barnett, and Josh You. Chinchilla scaling: A replication attempt.arXiv preprint arXiv:2404.10102, 2024. URL https://arxiv.org/abs/2404. 10102
arXiv 2024
-
[24]
Deduplicating training data mitigates privacy risks in language models
Nikhil Kandpal, Eric Wallace, and Colin Raffel. Deduplicating training data mitigates privacy risks in language models. InProceedings of the 39th International Conference on Machine Learning, volume 162 ofProceedings of Machine Learning Research, pages 10697–10707,
-
[25]
URLhttps://proceedings.mlr.press/v162/kandpal22a.html
-
[26]
Quantifying memorization across neural language models
Nicholas Carlini, Daphne Ippolito, Matthew Jagielski, Katherine Lee, Florian Tramer, and Chiyuan Zhang. Quantifying memorization across neural language models. InThe Eleventh International Conference on Learning Representations, 2023. URL https://openreview. net/forum?id=TatRHT_1cK
2023
-
[27]
Unveiling the spectrum of data contamination in language models: A survey from detection to remediation
Chunyuan Deng, Yilun Zhao, Yuzhao Heng, Yitong Li, Jiannan Cao, Xiangru Tang, and Arman Cohan. Unveiling the spectrum of data contamination in language models: A survey from detection to remediation. InFindings of the Association for Computational Linguistics: ACL 2024, pages 16078–16092, 2024. URL https://aclanthology.org/2024.findings-acl. 951/
2024
-
[28]
Rylan Schaeffer, Joshua Kazdan, Baber Abbasi, Ken Ziyu Liu, Brando Miranda, Ahmed Ahmed, Fazl Berez, Abhay Puri, Stella Biderman, Niloofar Mireshghallah, and Sanmi Koyejo. Quantifying the effect of test set contamination on generative evaluations.arXiv preprint arXiv:2601.04301, 2026. URLhttps://arxiv.org/abs/2601.04301
arXiv 2026
-
[29]
Reconciling modern machine-learning practice and the classical bias–variance trade-off , volume=
Mikhail Belkin, Daniel Hsu, Siyuan Ma, and Soumik Mandal. Reconciling modern machine- learning practice and the classical bias–variance trade-off.Proceedings of the National Academy of Sciences, 116(32):15849–15854, 2019. doi: 10.1073/pnas.1903070116. URL https: //arxiv.org/abs/1812.11118
-
[30]
Trevor Hastie, Andrea Montanari, Saharon Rosset, and Ryan J. Tibshirani. Sur- prises in high-dimensional ridgeless least squares interpolation.The Annals of Statistics, 50(2):949–986, 2022. doi: 10.1214/21-AOS2133. URL https: //projecteuclid.org/journals/annals-of-statistics/volume-50/issue-2/ Surprises-in-high-dimensional-ridgeless-least-squares-interpol...
-
[31]
Bartlett, Philip M
Peter L. Bartlett, Philip M. Long, Gábor Lugosi, and Alexander Tsigler. Benign overfitting in linear regression.Proceedings of the National Academy of Sciences, 117(48):30063–30070,
-
[32]
doi: 10.1073/pnas.1907378117. URLhttps://arxiv.org/abs/1906.11300
-
[33]
Deep double descent: Where bigger models and more data hurt
Preetum Nakkiran, Gal Kaplun, Yamini Bansal, Tristan Yang, Boaz Barak, and Ilya Sutskever. Deep double descent: Where bigger models and more data hurt. InInternational Conference on Learning Representations (ICLR), 2020. URL https://openreview.net/forum?id= B1g5sA4twr
2020
-
[34]
Scaling data-constrained language models
Niklas Muennighoff, Alexander M Rush, Boaz Barak, Teven Le Scao, Nouamane Tazi, Aleksan- dra Piktus, Sampo Pyysalo, Thomas Wolf, and Colin Raffel. Scaling data-constrained language models. InThirty-seventh Conference on Neural Information Processing Systems, 2023. URL https://openreview.net/forum?id=j5BuTrEj35. 12
2023
-
[35]
To repeat or not to repeat: Insights from scaling llm under token-crisis
Fuzhao Xue, Yao Fu, Wangchunshu Zhou, Zangwei Zheng, and Yang You. To repeat or not to repeat: Insights from scaling llm under token-crisis. InAdvances in Neural Information Process- ing Systems (NeurIPS), 2023. URL https://proceedings.neurips.cc/paper_files/ paper/2023/hash/b9e472cd579c83e2f6aa3459f46aac28-Abstract-Conference. html
2023
-
[36]
Pratyush Maini, Skyler Seto, He Bai, David Grangier, Yizhe Zhang, and Navdeep Jaitly. Rephrasing the web: A recipe for compute and data-efficient language modeling.arXiv preprint arXiv:2401.16380, 2024. URLhttps://arxiv.org/abs/2401.16380
arXiv 2024
-
[37]
One epoch is all you need.arXiv preprint arXiv:1906.06669, 2019
Aran Komatsuzaki. One epoch is all you need.arXiv preprint arXiv:1906.06669, 2019. URL https://arxiv.org/abs/1906.06669
Pith/arXiv arXiv 1906
-
[39]
URLhttps://arxiv.org/abs/2605.01640
-
[40]
Gomez, Łukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. InAdvances in Neural Information Processing Systems (NeurIPS), pages 5998–6008, 2017. URL https: //arxiv.org/abs/1706.03762
Pith/arXiv arXiv 2017
-
[41]
Jianlin Su, Yu Lu, Shengfeng Pan, Ahmed Murtadha, Bo Wen, and Yunfeng Liu. RoFormer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063, 2024. doi: 10.1016/j.neucom.2023.127063. URL https://doi.org/10.1016/j.neucom.2023. 127063
-
[42]
Emergent and predictable memoriza- tion in large language models
Stella Biderman, USVSN Sai Prashanth, Lintang Sutawika, Hailey Schoelkopf, Quentin Anthony, Shivanshu Purohit, and Edward Raff. Emergent and predictable memoriza- tion in large language models. InAdvances in Neural Information Processing Systems (NeurIPS), 2023. URL https://papers.nips.cc/paper_files/paper/2023/hash/ 59404fb89d6194641c69ae99ecdf8f6d-Abstr...
2023
-
[43]
Physics of language models: Part 3.3, knowledge capacity scaling laws
Zeyuan Allen-Zhu and Yuanzhi Li. Physics of language models: Part 3.3, knowledge capacity scaling laws. InInternational Conference on Learning Representations (ICLR), 2025. URL https://openreview.net/forum?id=FxNNiUgtfa
2025
-
[44]
Markosyan, Luke Zettlemoyer, and Armen Aghajanyan
Kushal Tirumala, Aram H. Markosyan, Luke Zettlemoyer, and Armen Aghajanyan. Mem- orization without overfitting: Analyzing the training dynamics of large language mod- els. InAdvances in Neural Information Processing Systems (NeurIPS), pages 38274– 38290, 2022. URL https://proceedings.neurips.cc/paper_files/paper/2022/ hash/fa0509f4dab6807e2cb465715bf2d249...
2022
-
[45]
Causal estimation of memorisation profiles
Pietro Lesci, Clara Meister, Thomas Hofmann, Andreas Vlachos, and Tiago Pimentel. Causal estimation of memorisation profiles. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL), pages 15616–15635, 2024. URL https: //aclanthology.org/2024.acl-long.834/
2024
-
[46]
Broken neural scaling laws
Ethan Caballero, Kshitij Gupta, Irina Rish, and David Krueger. Broken neural scaling laws. InThe Eleventh International Conference on Learning Representations, 2023. URL https: //openreview.net/forum?id=sckjveqlCZ
2023
-
[47]
Explaining neural scaling laws.Proceedings of the National Academy of Sciences, 121(27):e2311878121,
Yasaman Bahri, Ethan Dyer, Jared Kaplan, Jaehoon Lee, and Utkarsh Sharma. Explaining neural scaling laws.Proceedings of the National Academy of Sciences, 121(27):e2311878121,
-
[48]
Explaining neural scaling laws.Proceedings of the National Academy of Sciences, 121(27), 2024
doi: 10.1073/pnas.2311878121. URLhttps://arxiv.org/abs/2102.06701
-
[49]
A dynamical model of neural scaling laws
Blake Bordelon, Alexander Atanasov, and Cengiz Pehlevan. A dynamical model of neural scaling laws. InProceedings of the 41st International Conference on Machine Learning, volume 235 ofProceedings of Machine Learning Research, pages 4345–4382, 2024. URL https://proceedings.mlr.press/v235/bordelon24a.html. 13
2024
-
[50]
Tom Henighan, Jared Kaplan, Mor Katz, Mark Chen, Christopher Hesse, Jacob Jackson, Heewoo Jun, Tom B. Brown, Prafulla Dhariwal, Scott Gray, Chris Hallacy, Benjamin Mann, Alec Radford, Aditya Ramesh, Nick Ryder, Daniel M. Ziegler, John Schulman, Dario Amodei, and Sam McCandlish. Scaling laws for autoregressive generative modeling.arXiv preprint arXiv:2010....
Pith/arXiv arXiv 2010
-
[52]
URLhttps://arxiv.org/abs/2207.10551
-
[53]
Extracting training data from large language models
Nicholas Carlini, Florian Tramer, Eric Wallace, Matthew Jagielski, Ariel Herbert-V oss, Kather- ine Lee, Adam Roberts, Tom Brown, Dawn Song, Ulfar Erlingsson, Alina Oprea, and Colin Raffel. Extracting training data from large language models. In30th USENIX Security Sym- posium (USENIX Security 21), pages 2633–2650, 2021. URL https://www.usenix.org/ confer...
2021
-
[54]
A survey on data selection for language models.Transactions on Machine Learning Research, 2024
Alon Albalak, Yanai Elazar, Sang Michael Xie, Shayne Longpre, Nathan Lambert, Xinyi Wang, Niklas Muennighoff, Bairu Hou, Liangming Pan, Haewon Jeong, Colin Raffel, Shiyu Chang, Tatsunori Hashimoto, and William Yang Wang. A survey on data selection for language models.Transactions on Machine Learning Research, 2024. ISSN 2835-8856. URL https: //openreview....
2024
-
[55]
Hashimoto
Yonatan Oren, Nicole Meister, Niladri Chatterji, Faisal Ladhak, and Tatsunori B. Hashimoto. Proving test set contamination in black-box language models. InThe Twelfth International Conference on Learning Representations (ICLR), 2024. URL https://openreview.net/ forum?id=KS8mIvetg2
2024
-
[56]
Data contamination: From memorization to exploitation
Inbal Magar and Roy Schwartz. Data contamination: From memorization to exploitation. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (ACL), Volume 2: Short Papers, pages 157–165, 2022. URL https://aclanthology.org/2022. acl-short.18/
2022
-
[57]
Stop uploading test data in plain text: Practical strategies for mitigating data contamination by evaluation benchmarks
Alon Jacovi, Avi Caciularu, Omer Goldman, and Yoav Goldberg. Stop uploading test data in plain text: Practical strategies for mitigating data contamination by evaluation benchmarks. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 5075–5084, 2023. URL https://aclanthology.org/2023.emnlp-main. 308/
2023
-
[58]
The RefinedWeb dataset for Falcon LLM: Outperforming curated corpora with web data only
Guilherme Penedo, Quentin Malartic, Daniel Hesslow, Ruxandra Cojocaru, Hamza Alobei- dli, Alessandro Cappelli, Baptiste Pannier, Ebtesam Almazrouei, and Julien Launay. The RefinedWeb dataset for Falcon LLM: Outperforming curated corpora with web data only. InAdvances in Neural Information Processing Systems (NeurIPS), Datasets and Benchmarks Track, 2023. ...
2023
-
[59]
Mor- cos
Ben Sorscher, Robert Geirhos, Shashank Shekhar, Surya Ganguli, and Ari S. Mor- cos. Beyond neural scaling laws: Beating power law scaling via data prun- ing. InAdvances in Neural Information Processing Systems (NeurIPS), 2022. URL https://proceedings.neurips.cc/paper_files/paper/2022/hash/ 7b75da9b61eda40fa35453ee5d077df6-Abstract-Conference.html
2022
-
[60]
Max Marion, Ahmet Üstün, Luiza Pozzobon, Alex Wang, Marzieh Fadaee, and Sara Hooker. When less is more: Investigating data pruning for pretraining llms at scale.arXiv preprint arXiv:2309.04564, 2023. URLhttps://arxiv.org/abs/2309.04564
arXiv 2023
-
[61]
Le, Tengyu Ma, and Adams Wei Yu
Sang Michael Xie, Hieu Pham, Xuanyi Dong, Nan Du, Hanxiao Liu, Yifeng Lu, Percy Liang, Quoc V . Le, Tengyu Ma, and Adams Wei Yu. DoReMi: Optimizing data mix- tures speeds up language model pretraining. InAdvances in Neural Information Processing Systems (NeurIPS), 2023. URL https://papers.nips.cc/paper_files/paper/2023/ hash/dcba6be91359358c2355cd920da3fc...
2023
-
[62]
Lipton, Aditi Raghunathan, and J
Sachin Goyal, Pratyush Maini, Zachary C. Lipton, Aditi Raghunathan, and J. Zico Kolter. Scaling laws for data filtering – data curation cannot be compute agnostic.arXiv preprint arXiv:2404.07177, 2024. URLhttps://arxiv.org/abs/2404.07177
arXiv 2024
-
[63]
Mikhail Belkin, Daniel Hsu, and Ji Xu. Two models of double descent for weak features.SIAM Journal on Mathematics of Data Science, 2(4):1167–1180, 2020. doi: 10.1137/20M1336072. URLhttps://arxiv.org/abs/1903.07571
-
[64]
High-dimensional dynamics of generalization error in neural networks
Madhu S. Advani, Andrew M. Saxe, and Haim Sompolinsky. High-dimensional dynamics of generalization error in neural networks.Neural Networks, 132:428–446, 2020. doi: 10.1016/j. neunet.2020.08.022. URLhttps://arxiv.org/abs/1710.03667
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1016/j 2020
-
[65]
Bartlett
Alexander Tsigler and Peter L. Bartlett. Benign overfitting in ridge regression.Journal of Machine Learning Research, 24(123):1–76, 2023. URL https://jmlr.org/papers/v24/ 22-1398.html
2023
-
[66]
Song Mei and Andrea Montanari. The generalization error of random features regression: Precise asymptotics and the double descent curve.Communications on Pure and Applied Mathematics, 75(4):667–766, 2022. doi: 10.1002/cpa.22008. URL https://arxiv.org/ abs/1908.05355
-
[67]
Qwen2 technical report.arXiv preprint arXiv:2407.10671, 2024
An Yang, Baosong Yang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Zhou, et al. Qwen2 technical report.arXiv preprint arXiv:2407.10671, 2024. URL https://arxiv.org/abs/ 2407.10671
Pith/arXiv arXiv 2024
-
[68]
Qwen2.5 technical report.arXiv preprint arXiv:2412.15115, 2025
An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, et al. Qwen2.5 technical report.arXiv preprint arXiv:2412.15115, 2025. URL https://arxiv.org/abs/ 2412.15115
Pith/arXiv arXiv 2025
-
[69]
Diederik P. Kingma and Jimmy Ba. Adam: A method for stochastic optimization, 2017. URL https://arxiv.org/abs/1412.6980. A Comprehensive related work We expand here the discussion sketched in §2, organized along five threads. Repeated data in language model pretraining.Our closest predecessor is Hernandez et al. [11], who train transformers with a small fr...
Pith/arXiv arXiv 2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.