ZeroDex: Zero-Shot Long-Horizon Dexterous Manipulation via Multi-View 3D-Grounded VLM Reasoning
Pith reviewed 2026-06-26 20:46 UTC · model grok-4.3
The pith
ZeroDex lifts VLM 2D keypoints to consistent 3D positions via multi-view triangulation and ray voting to support zero-shot long-horizon dexterous manipulation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
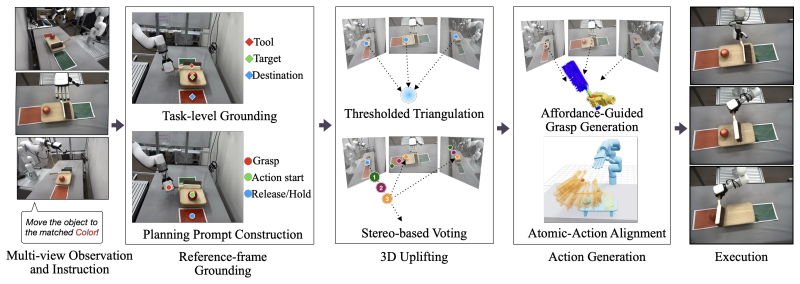
The paper claims that reference-frame task grounding and primitive-level 2D keypoints produced by a VLM from calibrated multi-view RGB images can be lifted into geometrically consistent 3D keypoints by triangulation combined with reference-view ray voting; these 3D points enable pick-and-place, retrieval of object-centric atomic actions with 6D tool-trajectory alignment for tool use, and expansion of grasp keypoints into affordance regions for dexterous execution, with closed-loop status verification and replanning supporting long-horizon performance on unseen objects in novel scenes.
What carries the argument
Multi-view 3D keypoint lifting that triangulates VLM-produced 2D groundings and supplements them with reference-view ray voting to locate geometrically consistent candidates.
If this is right
- Real-world tests report higher 3D grounding accuracy than single-view RGB-D methods.
- Execution reliability exceeds fine-tuned vision-language-action baselines on pick-and-place and tool-use.
- Long-horizon sequences succeed via repeated status verification and replanning.
- The pipeline executes zero-shot on unseen objects and novel tool-use tasks without task-specific training.
Where Pith is reading between the lines
- The separation of VLM reasoning from low-level motion generation could allow the same 3D-grounding step to pair with different robot arms or hands.
- Closed-loop replanning may extend naturally to settings where objects shift position between steps.
- If ray voting proves robust, similar fusion could be tested on other calibrated sensor combinations such as adding depth or event cameras.
Load-bearing premise
The vision-language model must output reliable reference-frame groundings and primitive 2D keypoints, and the triangulation-plus-ray-voting fusion must produce 3D points that match actual scene geometry well enough for physical execution.
What would settle it
An experiment measuring 3D grounding error and task success rate on a set of unseen tool-use tasks in novel scenes, where the multi-view method shows no improvement over single-view RGB-D grounding or fine-tuned baselines, would falsify the reliability claim.
Figures


read the original abstract
We present ZeroDex, a zero-shot framework for long-horizon dexterous manipulation that grounds language instructions into executable 3D task plans from calibrated multi-view RGB images. Rather than training an end-to-end policy, our system uses a vision-language model (VLM) to produce reference-frame task grounding and primitive-level 2D keypoints, then lifts them into 3D via multi-view fusion. This lifting combines triangulation of view-wise VLM groundings with reference-view ray voting, which searches along a semantic camera ray for geometrically consistent candidates across neighboring views. The resulting 3D keypoints support both pick-and-place and tool-use: for tool-use, we retrieve an object-centric atomic action corresponding to the inferred skill category and align its stored 6D tool trajectory to the scene; for dexterous execution, we expand the lifted grasp keypoint into a task-conditioned grasp affordance region and generate feasible grasp-motion pairs with an arm-hand motion generator. Real-world experiments show improved 3D grounding accuracy and execution reliability over single-view RGB-D grounding and fine-tuned VLA baselines. We further demonstrate long-horizon manipulation through closed-loop status verification and replan, enabling zero-shot execution on unseen objects and tool-use tasks in novel scenes.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents ZeroDex, a zero-shot framework for long-horizon dexterous manipulation that grounds language instructions into executable 3D task plans from calibrated multi-view RGB images. It uses a VLM to produce reference-frame task grounding and primitive-level 2D keypoints, lifts them to 3D via multi-view fusion (triangulation plus reference-view ray voting), retrieves stored 6D tool trajectories for tool-use tasks aligned to the keypoints, expands grasp keypoints into affordance regions for dexterous execution, and employs closed-loop status verification with replanning. Real-world experiments are claimed to show improved 3D grounding accuracy and execution reliability over single-view RGB-D and fine-tuned VLA baselines, enabling zero-shot performance on unseen objects and tool-use in novel scenes.
Significance. If the multi-view 3D lifting and closed-loop replanning deliver reliable results, the approach could be significant for scalable zero-shot dexterous manipulation by combining off-the-shelf VLMs with geometric operations, avoiding end-to-end policy training. The method's use of stored trajectories for tool-use and task-conditioned grasp generation addresses practical challenges in long-horizon tasks, potentially advancing applications in robotics where generalization to novel objects and scenes is required.
major comments (2)
- [Abstract] Abstract: The central zero-shot claim for tool-use tasks rests on retrieving a pre-stored object-centric atomic action and its 6D tool trajectory (aligned to the 3D keypoints) based on the VLM-inferred skill category. This is load-bearing for the claim of zero-shot execution on unseen objects and tool-use tasks in novel scenes, yet the description indicates the trajectories are stored rather than generated on the fly or derived parameter-free; clarification is needed on their generality and whether this limits true zero-shot capability for novel tools.
- [Abstract] Abstract: The assertion of 'improved 3D grounding accuracy and execution reliability' over baselines lacks any quantitative metrics, error bars, dataset details, or specific baseline descriptions. This is load-bearing for the empirical contribution and prevents verification of the real-world experiment claims.
minor comments (1)
- The multi-view fusion process (triangulation combined with reference-view ray voting) would benefit from an explicit equation or pseudocode in the methods to clarify how geometrically consistent 3D keypoints are selected across views.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment point-by-point below, agreeing that clarifications are warranted in the abstract to strengthen the presentation of our zero-shot claims and empirical results. We will incorporate revisions in the next version of the paper.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central zero-shot claim for tool-use tasks rests on retrieving a pre-stored object-centric atomic action and its 6D tool trajectory (aligned to the 3D keypoints) based on the VLM-inferred skill category. This is load-bearing for the claim of zero-shot execution on unseen objects and tool-use tasks in novel scenes, yet the description indicates the trajectories are stored rather than generated on the fly or derived parameter-free; clarification is needed on their generality and whether this limits true zero-shot capability for novel tools.
Authors: We agree that the tool-use tasks rely on retrieving pre-stored object-centric 6D tool trajectories aligned to the lifted 3D keypoints, rather than generating them on the fly. This is a deliberate design to enable zero-shot execution without end-to-end training or per-task trajectory synthesis: the VLM infers the skill category, retrieves the corresponding general primitive trajectory, and aligns it geometrically to the scene keypoints. The trajectories are intended as reusable, object-centric primitives for common tool-use actions, supporting generalization to unseen objects and novel scenes via the 3D grounding. However, the approach does assume availability of a stored trajectory for the inferred skill; entirely novel tools without a matching primitive would require extension of the library. We will revise the abstract and related sections to explicitly state this scope and clarify the zero-shot definition (no policy training or fine-tuning required). revision: yes
-
Referee: [Abstract] Abstract: The assertion of 'improved 3D grounding accuracy and execution reliability' over baselines lacks any quantitative metrics, error bars, dataset details, or specific baseline descriptions. This is load-bearing for the empirical contribution and prevents verification of the real-world experiment claims.
Authors: The current abstract provides a high-level summary of the results. Detailed quantitative metrics (e.g., 3D grounding accuracy percentages, execution success rates with standard deviations), dataset descriptions, and baseline comparisons (single-view RGB-D and fine-tuned VLA methods) are reported in the Experiments section, including tables and figures with error bars. To make the abstract self-contained and address the concern, we will revise it to incorporate key quantitative highlights from those experiments. revision: yes
Circularity Check
No circularity: pipeline uses external VLM and standard geometry
full rationale
The provided abstract and description present a modular pipeline that invokes an external VLM for 2D grounding and keypoints, applies standard multi-view operations (triangulation plus ray voting), and retrieves pre-stored 6D trajectories for tool-use categories. No equations, fitted parameters renamed as predictions, or self-citations appear in the text that would reduce any claimed result to its own inputs by construction. The zero-shot claim is scoped to VLM inference on novel scenes rather than a self-referential derivation, making the overall chain self-contained against external components.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Vision-language models can produce accurate 2D keypoint groundings aligned to language instructions and images
- domain assumption Multi-view triangulation combined with ray voting produces accurate 3D keypoints without task-specific training
Reference graph
Works this paper leans on
-
[1]
A. Brohan, N. Brown, J. Carbajal, Y . Chebotar, J. Dabis, C. Finn, K. Gopalakrishnan, K. Haus- man, A. Herzog, J. Hsu, et al. Rt-1: Robotics transformer for real-world control at scale.arXiv preprint arXiv:2212.06817, 2022
Pith/arXiv arXiv 2022
-
[2]
Zitkovich, T
B. Zitkovich, T. Yu, S. Xu, P. Xu, T. Xiao, F. Xia, J. Wu, P. Wohlhart, S. Welker, A. Wahid, et al. Rt-2: Vision-language-action models transfer web knowledge to robotic control. In CoRL, 2023
2023
-
[3]
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. Foster, G. Lam, P. Sanketi, et al. Openvla: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246, 2024
Pith/arXiv arXiv 2024
-
[4]
O. M. Team, D. Ghosh, H. Walke, K. Pertsch, K. Black, O. Mees, S. Dasari, J. Hejna, T. Kreiman, C. Xu, et al. Octo: An open-source generalist robot policy.arXiv preprint arXiv:2405.12213, 2024
Pith/arXiv arXiv 2024
-
[5]
K. Black, N. Brown, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, L. Groom, K. Hausman, B. Ichter, et al.π 0: A vision-language-action flow model for general robot control.arXiv preprint arXiv:2410.24164, 2024
Pith/arXiv arXiv 2024
-
[6]
Furukawa and C
Y . Furukawa and C. Hern´andez. Multi-view stereo: A tutorial.FnT CGV, 9(1-2):1–148, 2015
2015
-
[7]
L. Beyer, A. Steiner, A. S. Pinto, A. Kolesnikov, X. Wang, D. Salz, M. Neumann, I. Alabdul- mohsin, M. Tschannen, E. Bugliarello, et al. Paligemma: A versatile 3b vlm for transfer.arXiv preprint arXiv:2407.07726, 2024
Pith/arXiv arXiv 2024
-
[8]
Z. Chen, J. Wu, W. Wang, W. Su, G. Chen, S. Xing, M. Zhong, Q. Zhang, X. Zhu, L. Lu, et al. Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks. InCVPR, 2024
2024
-
[9]
S. Bai, Y . Cai, R. Chen, K. Chen, X. Chen, Z. Cheng, L. Deng, W. Ding, C. Gao, C. Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025
Pith/arXiv arXiv 2025
-
[10]
F. Ebert, Y . Yang, K. Schmeckpeper, B. Bucher, G. Georgakis, K. Daniilidis, C. Finn, and S. Levine. Bridge data: Boosting generalization of robotic skills with cross-domain datasets. arXiv preprint arXiv:2109.13396, 2021
Pith/arXiv arXiv 2021
-
[11]
H. R. Walke, K. Black, T. Z. Zhao, Q. Vuong, C. Zheng, P. Hansen-Estruch, A. W. He, V . My- ers, M. J. Kim, M. Du, et al. Bridgedata v2: A dataset for robot learning at scale. InCoRL, 2023
2023
-
[12]
O’Neill, A
A. O’Neill, A. Rehman, A. Maddukuri, A. Gupta, A. Padalkar, A. Lee, A. Pooley, A. Gupta, A. Mandlekar, A. Jain, et al. Open x-embodiment: Robotic learning datasets and rt-x models: Open x-embodiment collaboration 0. InICRA, 2024
2024
-
[13]
A. Khazatsky, K. Pertsch, S. Nair, A. Balakrishna, S. Dasari, S. Karamcheti, S. Nasiriany, M. K. Srirama, L. Y . Chen, K. Ellis, et al. Droid: A large-scale in-the-wild robot manipulation dataset.arXiv preprint arXiv:2403.12945, 2024
Pith/arXiv arXiv 2024
-
[14]
Q. Bu, J. Cai, L. Chen, X. Cui, Y . Ding, S. Feng, S. Gao, X. He, X. Hu, X. Huang, et al. Agibot world colosseo: A large-scale manipulation platform for scalable and intelligent embodied systems.arXiv preprint arXiv:2503.06669, 2025
Pith/arXiv arXiv 2025
-
[15]
J. Wen, Y . Zhu, J. Li, Z. Tang, C. Shen, and F. Feng. Dexvla: Vision-language model with plug-in diffusion expert for general robot control.arXiv preprint arXiv:2502.05855, 2025
Pith/arXiv arXiv 2025
-
[16]
M. J. Kim, C. Finn, and P. Liang. Fine-tuning vision-language-action models: Optimizing speed and success.arXiv preprint arXiv:2502.19645, 2025. 10
Pith/arXiv arXiv 2025
-
[17]
D. Qu, H. Song, Q. Chen, Y . Yao, X. Ye, Y . Ding, Z. Wang, J. Gu, B. Zhao, D. Wang, et al. Spatialvla: Exploring spatial representations for visual-language-action model.arXiv preprint arXiv:2501.15830, 2025
Pith/arXiv arXiv 2025
-
[18]
Q. Li, Y . Liang, Z. Wang, L. Luo, X. Chen, M. Liao, F. Wei, Y . Deng, S. Xu, Y . Zhang, et al. Cogact: A foundational vision-language-action model for synergizing cognition and action in robotic manipulation.arXiv preprint arXiv:2411.19650, 2024
Pith/arXiv arXiv 2024
-
[19]
G. R. Team, A. Abdolmaleki, S. Abeyruwan, J. Ainslie, J.-B. Alayrac, M. G. Arenas, A. Bal- akrishna, N. Batchelor, A. Bewley, J. Bingham, et al. Gemini robotics 1.5: Pushing the frontier of generalist robots with advanced embodied reasoning, thinking, and motion transfer.arXiv preprint arXiv:2510.03342, 2025
Pith/arXiv arXiv 2025
-
[20]
J. Bjorck, F. Casta ˜neda, N. Cherniadev, X. Da, R. Ding, L. Fan, Y . Fang, D. Fox, F. Hu, S. Huang, et al. Gr00t n1: An open foundation model for generalist humanoid robots.arXiv preprint arXiv:2503.14734, 2025
Pith/arXiv arXiv 2025
-
[21]
Zhong, X
Y . Zhong, X. Huang, R. Li, C. Zhang, Z. Chen, T. Guan, F. Zeng, K. N. Lui, Y . Ye, Y . Liang, et al. Dexgraspvla: A vision-language-action framework towards general dexterous grasping. InAAAI, 2026
2026
-
[22]
H. Luo, Y . Feng, W. Zhang, S. Zheng, Y . Wang, H. Yuan, J. Liu, C. Xu, Q. Jin, and Z. Lu. Being-h0: vision-language-action pretraining from large-scale human videos.arXiv preprint arXiv:2507.15597, 2025
arXiv 2025
-
[23]
D. Kim, H. Jang, M. Koo, S. Jang, T. Kim, B. Kim, B. Yoon, C. Jang, D. Choi, D. Han, et al. Rldx-1 technical report.arXiv preprint arXiv:2605.03269, 2026
Pith/arXiv arXiv 2026
-
[24]
Qin, Y .-H
Y . Qin, Y .-H. Wu, S. Liu, H. Jiang, R. Yang, Y . Fu, and X. Wang. Dexmv: Imitation learning for dexterous manipulation from human videos. InECCV, 2022
2022
-
[25]
A. Sivakumar, K. Shaw, and D. Pathak. Robotic telekinesis: Learning a robotic hand imitator by watching humans on youtube.arXiv preprint arXiv:2202.10448, 2022
arXiv 2022
-
[26]
C. Wang, H. Shi, W. Wang, R. Zhang, L. Fei-Fei, and C. K. Liu. Dexcap: Scalable and portable mocap data collection system for dexterous manipulation.arXiv preprint arXiv:2403.07788, 2024
arXiv 2024
-
[27]
Liang, W
J. Liang, W. Huang, F. Xia, P. Xu, K. Hausman, B. Ichter, P. Florence, and A. Zeng. Code as policies: Language model programs for embodied control. InICRA, 2023
2023
-
[28]
Singh, V
I. Singh, V . Blukis, A. Mousavian, A. Goyal, D. Xu, J. Tremblay, D. Fox, J. Thomason, and A. Garg. Progprompt: Program generation for situated robot task planning using large lan- guage models.AMR, 47(8):999–1012, 2023
2023
-
[29]
W. Huang, C. Wang, R. Zhang, Y . Li, J. Wu, and L. Fei-Fei. V oxposer: Composable 3d value maps for robotic manipulation with language models.arXiv preprint arXiv:2307.05973, 2023
Pith/arXiv arXiv 2023
-
[30]
F. Liu, K. Fang, P. Abbeel, and S. Levine. Moka: Open-world robotic manipulation through mark-based visual prompting.arXiv preprint arXiv:2403.03174, 2024
arXiv 2024
-
[31]
W. Huang, C. Wang, Y . Li, R. Zhang, and L. Fei-Fei. Rekep: Spatio-temporal reasoning of relational keypoint constraints for robotic manipulation.arXiv preprint arXiv:2409.01652, 2024
Pith/arXiv arXiv 2024
-
[32]
S. Nasiriany, F. Xia, W. Yu, T. Xiao, J. Liang, I. Dasgupta, A. Xie, D. Driess, A. Wahid, Z. Xu, et al. Pivot: Iterative visual prompting elicits actionable knowledge for vlms.arXiv preprint arXiv:2402.07872, 2024. 11
arXiv 2024
-
[33]
W. Yuan, J. Duan, V . Blukis, W. Pumacay, R. Krishna, A. Murali, A. Mousavian, and D. Fox. Robopoint: A vision-language model for spatial affordance prediction for robotics.arXiv preprint arXiv:2406.10721, 2024
arXiv 2024
-
[34]
Y . Du, S. Yang, B. Dai, H. Dai, O. Nachum, J. Tenenbaum, D. Schuurmans, and P. Abbeel. Learning universal policies via text-guided video generation.NeurIPS, 2023
2023
-
[35]
P.-C. Ko, J. Mao, Y . Du, S.-H. Sun, and J. B. Tenenbaum. Learning to act from actionless videos through dense correspondences. InICLR, 2024
2024
-
[36]
Black, M
K. Black, M. Nakamoto, P. Atreya, H. Walke, C. Finn, A. Kumar, and S. Levine. Zero-shot robotic manipulation with pre-trained image-editing diffusion models. InICLR, 2024
2024
- [37]
-
[38]
C. Yuan, C. Wen, T. Zhang, and Y . Gao. General flow as foundation affordance for scalable robot learning.arXiv preprint arXiv:2401.11439, 2024
arXiv 2024
-
[39]
B. Chen, Z. Xu, S. Kirmani, B. Ichter, D. Sadigh, L. Guibas, and F. Xia. Spatialvlm: Endowing vision-language models with spatial reasoning capabilities. InCVPR, 2024
2024
-
[40]
C. H. Song, V . Blukis, J. Tremblay, S. Tyree, Y . Su, and S. Birchfield. Robospatial: Teaching spatial understanding to 2d and 3d vision-language models for robotics. InCVPR, 2025
2025
-
[41]
R. Xu, Z. Huang, T. Wang, Y . Chen, J. Pang, and D. Lin. Vlm-grounder: A vlm agent for zero-shot 3d visual grounding.arXiv preprint arXiv:2410.13860, 2024
arXiv 2024
-
[42]
M. Pan, J. Zhang, T. Wu, Y . Zhao, W. Gao, and H. Dong. Omnimanip: Towards general robotic manipulation via object-centric interaction primitives as spatial constraints. InCVPR, 2025
2025
-
[43]
B. Wen, M. Trepte, J. Aribido, J. Kautz, O. Gallo, and S. Birchfield. Foundationstereo: Zero- shot stereo matching. InCVPR, 2025
2025
-
[44]
B. Wen, W. Yang, J. Kautz, and S. Birchfield. Foundationpose: Unified 6d pose estimation and tracking of novel objects. InCVPR, 2024
2024
-
[45]
S. Baik, G. Kim, M. Choi, and H. Joo. Text-guided 6d object pose rearrangement via closed- loop vlm agents.arXiv preprint arXiv:2604.09781, 2026
Pith/arXiv arXiv 2026
-
[46]
C. Tang, A. Xiao, Y . Deng, T. Hu, W. Dong, H. Zhang, D. Hsu, and H. Zhang. Mimicfunc: Imitating tool manipulation from a single human video via functional correspondence.arXiv preprint arXiv:2508.13534, 2025
arXiv 2025
-
[47]
R. Wang, J. Zhang, J. Chen, Y . Xu, P. Li, T. Liu, and H. Wang. Dexgraspnet: A large- scale robotic dexterous grasp dataset for general objects based on simulation.arXiv preprint arXiv:2210.02697, 2022
arXiv 2022
-
[48]
Y . Xu, W. Wan, J. Zhang, H. Liu, Z. Shan, H. Shen, R. Wang, H. Geng, Y . Weng, J. Chen, et al. Unidexgrasp: Universal robotic dexterous grasping via learning diverse proposal generation and goal-conditioned policy. InCVPR, 2023
2023
-
[49]
P. Li, T. Liu, Y . Li, Y . Geng, Y . Zhu, Y . Yang, and S. Huang. Gendexgrasp: Generalizable dexterous grasping. InICRA, 2023
2023
-
[50]
Zhong, Q
Y . Zhong, Q. Jiang, J. Yu, and Y . Ma. Dexgrasp anything: Towards universal robotic dexterous grasping with physics awareness. InCVPR, 2025
2025
-
[51]
J. Chen, Y . Ke, L. Peng, and H. Wang. Dexonomy: Synthesizing all dexterous grasp types in a grasp taxonomy.arXiv preprint arXiv:2504.18829, 2025. 12
arXiv 2025
-
[52]
Nasiriany, S
S. Nasiriany, S. Kirmani, T. Ding, L. Smith, Y . Zhu, D. Driess, D. Sadigh, and T. Xiao. Rt-affordance: Affordances are versatile intermediate representations for robot manipulation. 2025
2025
-
[53]
W. Huang, F. Xia, T. Xiao, H. Chan, J. Liang, P. Florence, A. Zeng, J. Tompson, I. Mordatch, Y . Chebotar, et al. Inner monologue: Embodied reasoning through planning with language models.arXiv preprint arXiv:2207.05608, 2022
Pith/arXiv arXiv 2022
-
[54]
B. Sundaralingam, A. Murali, and S. Birchfield. curobov2: Dynamics-aware motion generation with depth-fused distance fields for high-dof robots.arXiv preprint arXiv:2603.05493, 2026
Pith/arXiv arXiv 2026
-
[55]
M. A. Fischler and R. C. Bolles. Random sample consensus: a paradigm for model fitting with applications to image analysis and automated cartography.CACM, 24(6):381–395, 1981
1981
-
[56]
Pour water from the kettle
J. Chen, Y . Ke, and H. Wang. Bodex: Scalable and efficient robotic dexterous grasp synthesis using bilevel optimization. InICRA, 2025. 13 Supplementary Material A Additional Qualitative Examples A.1 Comparison of 3D Grounding Methods Figure S1: Comparison of grounding results produced by the single-view RGB-D baseline and our multi-view grounding method ...
2025
-
[57]
PICK + PLACE --- pick an object and put it on/in a destination
-
[58]
RELEASE --- drop the currently held object on/in a destination (after tool action case)
-
[59]
scene":
TOOL ACTION --- act on a target with a tool (sweep / wipe / cut / push / write / pour / press / ...). If not currently holding, the pick-up of the tool is part of this same task; if already holding the tool, just continue the action with it. Phrasing: - Plain string, natural language. No pixel coordinates. - Use object names / colors VISIBLE in the curren...
-
[60]
Judge whether that current position is actually ON ’{moving label}’ that this subtask must grasp
-
[61]
{scenario}
If it is off, decide WHICH DIRECTION (relative to ’{moving label}’ in this image) the correct region lies, then pick the candidate number(s) toward it. If already correct, keep it. [GRASP only] For GRASP the model writes the reasoning above first, then outputs the JSON array on a NEW FINAL line (reason-then-answer). You are given ONE image from camera ser...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.