SkillAudit: From Fixed-Suite Benchmarking to Skill-Centered Assessment
Pith reviewed 2026-06-26 10:31 UTC · model grok-4.3
The pith
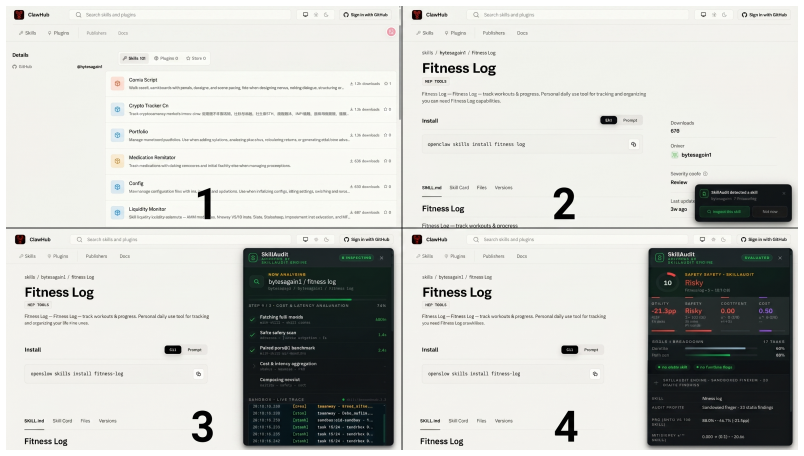
SkillAudit takes any agent skill package as input and automatically produces a report on its utility, efficiency, cost, and safety by building aligned tasks, running them in sandboxes, and applying LLM judging.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
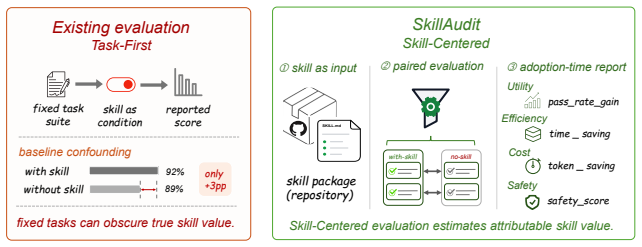
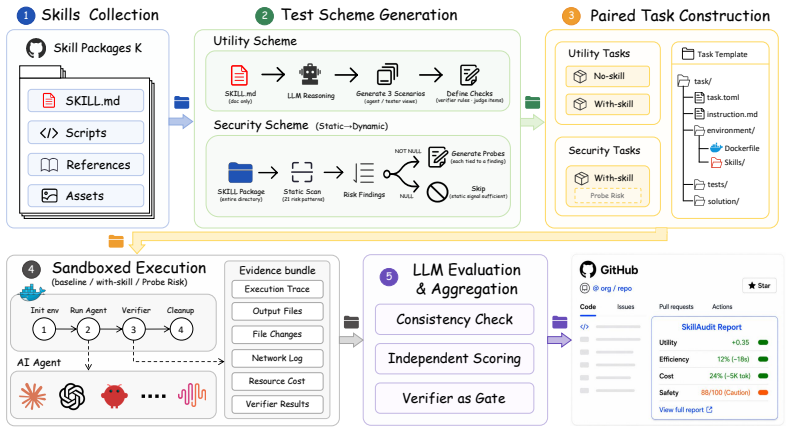
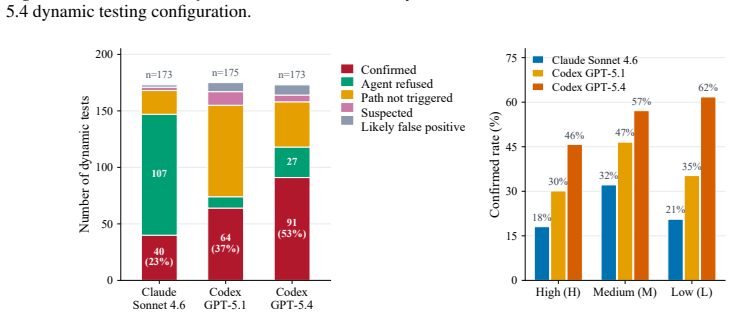
SkillAudit takes an arbitrary agent skill as input and automatically generates a comprehensive, multi-dimensional evaluation report spanning utility, efficiency/cost, and safety. It constructs capability-aligned evaluation tasks directly from the skill package, executes those tasks in isolated sandbox environments to collect execution evidence, and applies automated checks with LLM-based judging. Utility and efficiency are measured via the baseline comparison principle; safety risks are assessed through a two-stage detection paradigm that combines static semantic analysis with dynamic runtime verification. Scanning top-ranked real-world skill packages across 23 occupational categories showed
What carries the argument
The baseline comparison principle for utility and efficiency measurement together with the two-stage detection paradigm (static semantic analysis plus dynamic runtime verification) for safety risks.
If this is right
- Skills receive scores that separate their contribution from the underlying model's performance.
- Marketplaces can automatically flag and filter skills that fail the safety checks before they reach users.
- New skills can be evaluated as soon as they appear without waiting for updates to a fixed benchmark suite.
- Each report includes auditable execution traces and LLM judgments that can be inspected later.
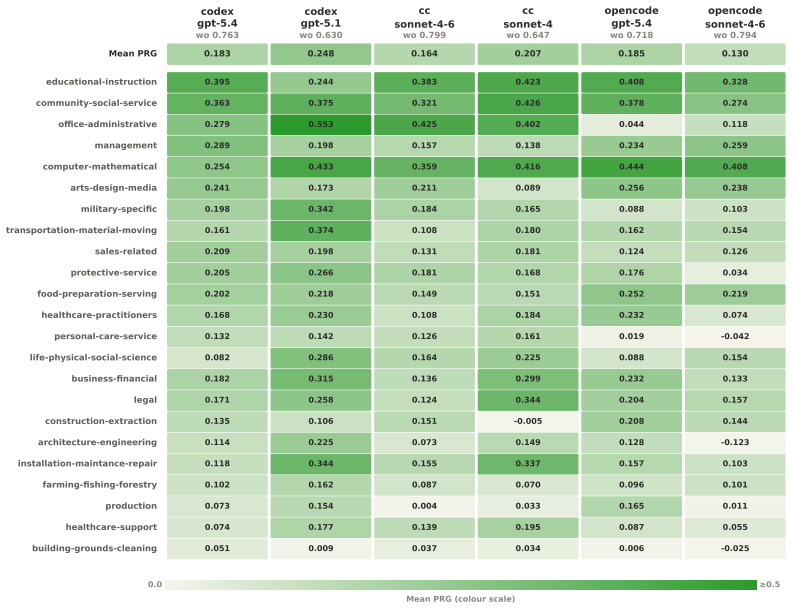
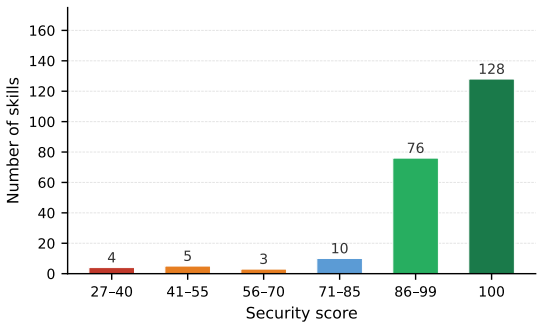
- More than 7 percent of current top-ranked skills across 23 categories would be labeled risky under this process.
Where Pith is reading between the lines
- Skill developers could run the framework during iteration to catch problems before release.
- The same task-generation and judging pipeline might be adapted to evaluate other modular components such as tools or memory modules.
- Marketplace operators could integrate the method as an automated gate that blocks deployment of flagged skills.
- If the two-stage safety checks prove stable, regulators might reference similar outputs when setting deployment standards for agent extensions.
Load-bearing premise
The tasks generated from the skill package and the subsequent LLM-based judging accurately reflect the skill's own contribution and risks without being skewed by the backbone model or by prompt choices.
What would settle it
Re-running the full evaluation pipeline on the same set of skills while swapping the judge model or altering the judge prompts and checking whether the utility scores, efficiency rankings, or safety flags change by more than a small margin.
Figures
read the original abstract
Agent skills have become a practical way to extend large language model agents, but the growing skill ecosystem still lacks a reliable way to judge whether a skill is worth deploying. Existing evaluation methods remain largely anchored to fixed task suites, assessing skills through performance on predefined tasks and environments. As skill marketplaces expand, this paradigm becomes inadequate: fixed suites can conflate a skill's marginal contribution with backbone strength and miss its value when tasks fall outside the skill's intended scope. We introduce SkillAudit, an end-to-end framework for skill-centered assessment that takes an arbitrary agent skill as input and automatically generates a comprehensive, multi-dimensional evaluation report spanning utility, efficiency/cost, and safety. SkillAudit focuses on the skill artifact itself and constructs capability-aligned evaluation tasks directly from the skill package. The generated tasks are conducted in isolated sandbox environments to collect execution evidence, followed by automated checks with LLM-based judging to produce auditable results. To dissect the agent skills, we propose the baseline comparison principle to measure utility and efficiency/cost, and introduce a two-stage detection paradigm combining static semantic analysis with dynamic runtime verification to assess safety risks. After scanning top-ranked real-world skill packages spanning 23 occupational categories, we found that over 7% of skills are at risky status.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SkillAudit, a framework that takes an arbitrary agent skill as input, automatically generates capability-aligned evaluation tasks from the skill package, executes them in isolated sandboxes, and applies LLM-based judging to produce reports on utility (via baseline comparison), efficiency/cost, and safety (via two-stage detection combining static semantic analysis with dynamic runtime verification). After scanning top-ranked real-world skill packages across 23 occupational categories, it reports that over 7% of skills are at risky status.
Significance. If the task-generation and judging pipeline can be shown to be reliable, the shift from fixed-suite to skill-centered assessment would address a genuine limitation in current agent evaluation practices, particularly the conflation of skill marginal contribution with backbone model strength. The empirical scan provides an initial prevalence estimate that could inform deployment decisions, though its interpretability depends on validation that is not yet supplied.
major comments (2)
- [Abstract] Abstract (safety assessment paragraph): the claim that over 7% of scanned skills are at risky status rests on the two-stage detection paradigm, but the manuscript supplies no calibration data, inter-annotator agreement metrics, or ground-truth validation of the LLM judge against human experts or known risky/safe skills; without this, systematic prompt or backbone biases directly confound the risk labels and render the prevalence statistic uninterpretable.
- [Task construction and automated checks] Task construction and automated checks section: the framework asserts that generated tasks and LLM judging accurately isolate the skill's marginal contribution and safety risks, yet no ablation or sensitivity analysis is reported on judge-prompt variations or backbone-model dependence; this assumption is load-bearing for both the utility/efficiency claims and the safety audit results.
minor comments (2)
- The baseline comparison principle is referenced but its precise operationalization (e.g., choice of reference agents, aggregation across tasks) is not detailed enough for independent reproduction.
- No error bars, confidence intervals, or sensitivity checks accompany the 7% figure or any other quantitative results.
Simulated Author's Rebuttal
We thank the referee for the constructive comments identifying gaps in validation and robustness analysis. We address each point below and commit to revisions that strengthen the manuscript without overstating current evidence.
read point-by-point responses
-
Referee: [Abstract] Abstract (safety assessment paragraph): the claim that over 7% of scanned skills are at risky status rests on the two-stage detection paradigm, but the manuscript supplies no calibration data, inter-annotator agreement metrics, or ground-truth validation of the LLM judge against human experts or known risky/safe skills; without this, systematic prompt or backbone biases directly confound the risk labels and render the prevalence statistic uninterpretable.
Authors: We agree that the manuscript provides no calibration data, inter-annotator agreement metrics, or ground-truth validation for the LLM judge, leaving the 7% figure vulnerable to unquantified biases. This is a substantive limitation. In the revised version we will add a validation subsection that reports agreement with human experts on a sampled subset of skills, quantifies prompt and backbone sensitivity where feasible, and explicitly qualifies the prevalence statistic as preliminary. revision: yes
-
Referee: [Task construction and automated checks] Task construction and automated checks section: the framework asserts that generated tasks and LLM judging accurately isolate the skill's marginal contribution and safety risks, yet no ablation or sensitivity analysis is reported on judge-prompt variations or backbone-model dependence; this assumption is load-bearing for both the utility/efficiency claims and the safety audit results.
Authors: The absence of ablation or sensitivity analysis on prompt variations and backbone-model dependence is correctly noted as a gap; the current text does not demonstrate robustness of the isolation claims. We will incorporate sensitivity experiments in the revision, testing multiple judge prompts and alternative backbones, and report their impact on utility, cost, and safety metrics to support the load-bearing assumptions. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The paper introduces SkillAudit as an independent procedural framework: it takes a skill package as input, constructs capability-aligned tasks, executes them in sandboxes, and applies static analysis plus LLM-based judging to produce utility, efficiency, and safety reports. The >7% risky-skills statistic is presented as the direct output of running this pipeline on external skill packages, not as a quantity defined in terms of its own outputs, a fitted parameter renamed as prediction, or a result justified solely by self-citation. No equations, ansatzes, or load-bearing self-citations appear in the provided text that would reduce any claim to its own inputs by construction. The derivation chain therefore remains self-contained.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption LLM-based judging produces auditable and unbiased verdicts on utility, efficiency, and safety
- domain assumption Tasks generated directly from the skill package are capability-aligned and sufficient to isolate the skill's marginal contribution
Reference graph
Works this paper leans on
-
[1]
2025 , month = oct, howpublished =
Equipping agents for the real world with. 2025 , month = oct, howpublished =
2025
-
[2]
and Mao, Huanzhi and Yan, Fanjia and Ji, Charlie Cheng-Jie and Suresh, Vishnu and Stoica, Ion and Gonzalez, Joseph E
Patil, Shishir G. and Mao, Huanzhi and Yan, Fanjia and Ji, Charlie Cheng-Jie and Suresh, Vishnu and Stoica, Ion and Gonzalez, Joseph E. , booktitle =. The Berkeley Function Calling Leaderboard (. 2025 , publisher =
2025
-
[3]
and Yang, John and Wettig, Alexander and Yao, Shunyu and Pei, Kexin and Press, Ofir and Narasimhan, Karthik R
Jimenez, Carlos E. and Yang, John and Wettig, Alexander and Yao, Shunyu and Pei, Kexin and Press, Ofir and Narasimhan, Karthik R. , booktitle =. 2024 , note =
2024
-
[4]
Retrieval-Augmented Generation for Knowledge-Intensive
Lewis, Patrick and Perez, Ethan and Piktus, Aleksandra and Petroni, Fabio and Karpukhin, Vladimir and Goyal, Naman and K. Retrieval-Augmented Generation for Knowledge-Intensive. Advances in Neural Information Processing Systems , volume =. 2020 , publisher =
2020
-
[5]
SkillsBench: Benchmarking How Well Agent Skills Work Across Diverse Tasks
Li, Xiangyi and Chen, Wenbo and Liu, Yimin and Zheng, Shenghan and Chen, Xiaokun and He, Yifeng and Li, Yubo and You, Bingran and Shen, Haotian and Sun, Jiankai and Wang, Shuyi and Li, Binxu and Zeng, Qunhong and Wang, Di and Zhao, Xuandong and Wang, Yuanli and Ben Chaim, Roey and Di, Zonglin and Gao, Yipeng and He, Junwei and He, Yizhuo and Jing, Liqiang...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2602.12670
-
[6]
2024 , url =
Liu, Xiao and Yu, Hao and Zhang, Hanchen and Xu, Yifan and Lei, Xuanyu and Lai, Hanyu and Gu, Yu and Ding, Hangliang and Men, Kaiwen and Yang, Kejuan and Zhang, Shudan and Deng, Xiang and Zeng, Aohan and Du, Zhengxiao and Zhang, Chenhui and Shen, Sheng and Zhang, Tianjun and Su, Yu and Sun, Huan and Huang, Minlie and Dong, Yuxiao and Tang, Jie , booktitle...
2024
-
[7]
2024 , note =
Qin, Yujia and Liang, Shihao and Ye, Yining and Zhu, Kunlun and Yan, Lan and Lu, Yaxi and Lin, Yankai and Cong, Xin and Tang, Xiangru and Qian, Bill and Zhao, Sihan and Hong, Lauren and Tian, Runchu and Xie, Ruobing and Zhou, Jie and Gerstein, Mark and Li, Dahai and Liu, Zhiyuan and Sun, Maosong , booktitle =. 2024 , note =
2024
-
[8]
Prompt Injection Attack to Tool Selection in
Shi, Jiawen and Yuan, Zenghui and Tie, Guiyao and Zhou, Pan and Gong, Neil Zhenqiang and Sun, Lichao , booktitle =. Prompt Injection Attack to Tool Selection in. 2026 , doi =
2026
-
[9]
Transactions on Machine Learning Research , year =
Cognitive Architectures for Language Agents , author =. Transactions on Machine Learning Research , year =
-
[10]
Xu, Frank F. and Song, Yufan and Li, Boxuan and Tang, Yuxuan and Jain, Kritanjali and Bao, Mengxue and Wang, Zora Zhiruo and Zhou, Xuhui and Guo, Zhitong and Cao, Murong and Yang, Mingyang and Lu, Hao Yang and Martin, Amaad and Su, Zhe and Maben, Leander Melroy and Mehta, Raj and Chi, Wayne and Jang, Lawrence Keunho and Xie, Yiqing and Zhou, Shuyan and Ne...
2025
-
[11]
and Cao, Yuan , booktitle =
Yao, Shunyu and Zhao, Jeffrey and Yu, Dian and Du, Nan and Shafran, Izhak and Narasimhan, Karthik R. and Cao, Yuan , booktitle =. 2023 , url =
2023
-
[12]
, booktitle =
Yao, Shunyu and Shinn, Noah and Razavi, Pedram and Narasimhan, Karthik R. , booktitle =. 2025 , url =
2025
-
[13]
doi:10.18653/v1/2024.findings-acl.624
Zhan, Qiusi and Liang, Zhixiang and Ying, Zifan and Kang, Daniel , booktitle =. 2024 , pages =. doi:10.18653/v1/2024.findings-acl.624 , url =
-
[14]
doi:10.48550/arXiv.2603.28815 , url =
Wang, Leye and Wang, Zixing and Xu, Anjie , year =. doi:10.48550/arXiv.2603.28815 , url =. 2603.28815 , archivePrefix =
-
[15]
arXiv preprint arXiv:2603.15401 , year=
SWE-Skills-Bench: Do Agent Skills Actually Help in Real-World Software Engineering? , author=. arXiv preprint arXiv:2603.15401 , year=
-
[16]
arXiv preprint arXiv:2605.23899 , year=
From Raw Experience to Skill Consumption: A Systematic Study of Model-Generated Agent Skills , author=. arXiv preprint arXiv:2605.23899 , year=
-
[17]
arXiv preprint arXiv:2605.18693 , year=
SkillGenBench: Benchmarking Skill Generation Pipelines for LLM Agents , author=. arXiv preprint arXiv:2605.18693 , year=
-
[18]
arXiv preprint arXiv:2605.08386 , year=
SkillLens: Adaptive Multi-Granularity Skill Reuse for Cost-Efficient LLM Agents , author=. arXiv preprint arXiv:2605.08386 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.