NeuDW-CIM: a 65-nm 0.8-pJ/Sop Reconfigurable Neuromorphic Compute-in-Memory Macro with Nonlinear Dendrites and K-Winners
Pith reviewed 2026-06-27 14:58 UTC · model grok-4.3
The pith
A 65nm compute-in-memory macro uses nonlinear dendrite emulation and K-winner early stopping to reach 0.8 pJ per synaptic operation in spiking networks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
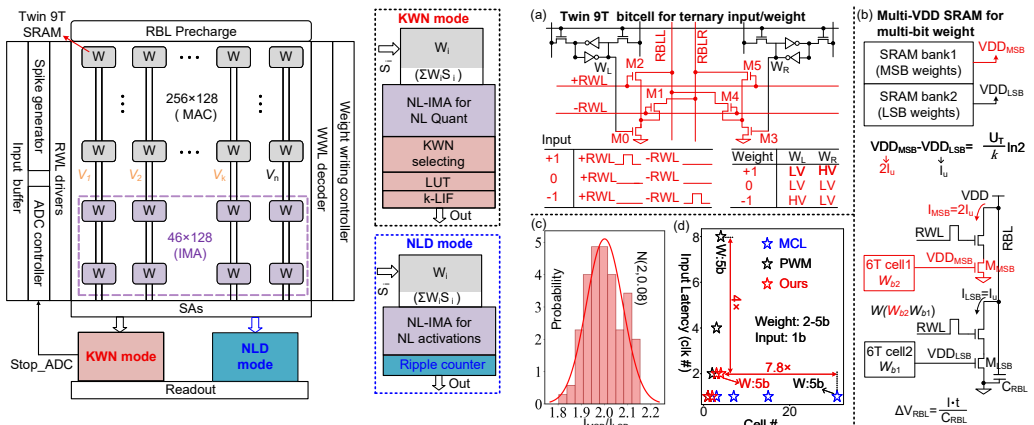
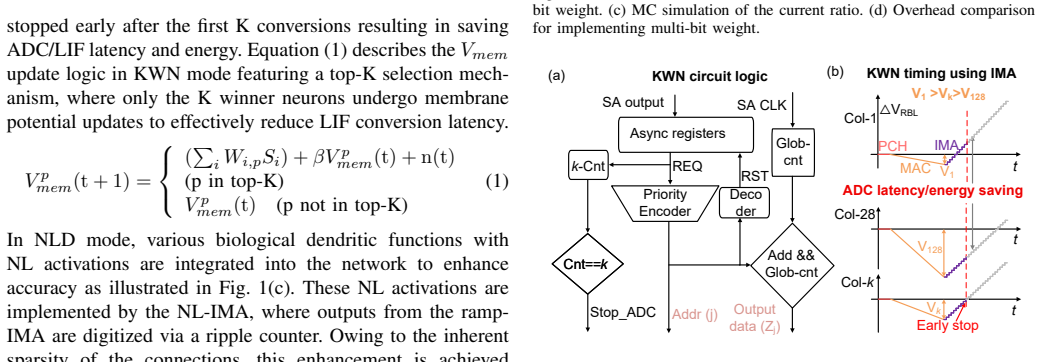
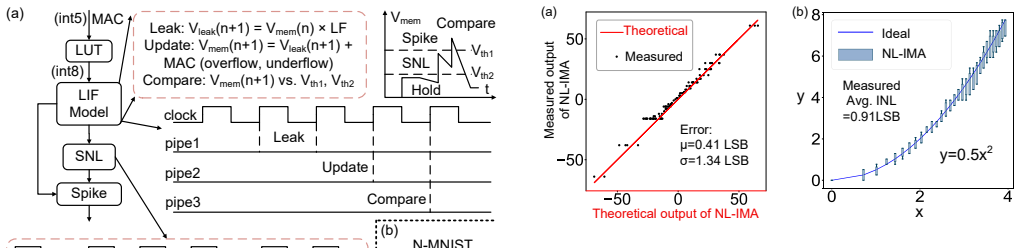
NeuDW-CIM is a 65-nm CMOS neuromorphic compute-in-memory macro that introduces a twin 9T bit-cell for ternary inputs and weights together with a reconfigurable non-linear in-memory ADC; the macro operates in nonlinear dendrite mode to emulate biological dendritic functions or in top-K winner mode with early stopping, producing measured accuracies of 97.2 percent on N-MNIST and 95.5 percent on DVS Gesture while reaching 0.8 pJ per SOP energy efficiency.
What carries the argument
Reconfigurable non-linear in-memory ADC that switches between dendritic nonlinearity emulation and early-stopping K-winner selection while the twin 9T bit-cell supplies ternary weights.
If this is right
- Nonlinear dendrite mode produces 97.2 percent accuracy on N-MNIST and 95.5 percent accuracy on DVS Gesture.
- K-winner mode reduces IMA conversion latency by 30 percent and digital LIF neuron latency by a factor of 10.
- Sparse updates in K-winner mode contribute directly to the measured 0.8 pJ per SOP efficiency.
- The same macro supports both modes through simple reconfiguration of the in-memory ADC.
- The design maintains ternary weight precision via the custom 9T bit-cell throughout both operating modes.
Where Pith is reading between the lines
- The reconfigurability could allow a single chip to switch between high-accuracy and low-power regimes for different edge-sensing tasks without retraining.
- Early stopping in the winner mode may scale favorably to deeper networks where only a small fraction of neurons fire per timestep.
- The dendritic nonlinearity emulation might be combined with existing SNN training algorithms to close the remaining accuracy gap to non-spiking networks on the same datasets.
- Because the efficiency gain comes from both analog and digital latency reductions, the approach could be ported to other process nodes that also support ternary bit-cells.
Load-bearing premise
The reported accuracy and energy numbers were measured on silicon that behaves like typical fabricated chips without unaccounted test-setup artifacts or process variation.
What would settle it
Re-measuring energy per SOP and classification accuracy on a second set of fabricated dies or at a different supply voltage and temperature would show whether the 0.8 pJ/SOP and 97 percent accuracy figures hold beyond the single reported test condition.
Figures




read the original abstract
This work presents NeuDW-CIM, a highly efficient neuromorphic Compute-in-Memory (CIM) macro for Spiking Neural Networks (SNNs) implemented in 65 nm CMOS. The design introduces a custom twin 9T bit-cell for ternary in-puts/weights and a reconfigurable non-linear In-Memory ADC (IMA). The macro supports two specialized modes: 1) Nonlinear Dendrite (NLD) mode, which utilizes reconfigurable IMA to emulate biological dendritic functions, achieving measured accuracies of 97.2% on N-MNIST and 95.5% on DVS Gesture; and 2) Top-K Winner (KWN) mode, featuring an early-stopping mechanism that reduces IMA conversion latency by 30% and digital LIF latency by 10x. Benefiting from the sparse update in KWN mode, NeuDW-CIM achieves a measured energy efficiency (EE) of 0.8 pJ/SOP (1.6x improvement).
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents NeuDW-CIM, a 65-nm CMOS neuromorphic compute-in-memory macro for spiking neural networks. It introduces a twin 9T bit-cell supporting ternary inputs/weights and a reconfigurable nonlinear in-memory ADC (IMA). The design operates in two modes: Nonlinear Dendrite (NLD) mode that emulates biological dendritic functions, and Top-K Winner (KWN) mode with early-stopping to reduce IMA conversion latency by 30% and digital LIF latency by 10x. Measured results on fabricated silicon report 97.2% accuracy on N-MNIST and 95.5% accuracy on DVS Gesture in NLD mode, together with 0.8 pJ/SOP energy efficiency in KWN mode (claimed 1.6x improvement).
Significance. If the silicon measurements are shown to be representative of typical fabricated performance, the work demonstrates a reconfigurable CIM macro that integrates nonlinear dendritic emulation and sparsity-driven early stopping within a single 65-nm design. The dual-mode operation and concrete energy figure constitute a tangible contribution to energy-efficient neuromorphic hardware for edge SNN inference.
major comments (1)
- [Abstract and experimental results section] Abstract and experimental results section: the headline claims rest entirely on measured accuracies (97.2% N-MNIST, 95.5% DVS Gesture) and 0.8 pJ/SOP efficiency. The manuscript must supply a complete measurement protocol that (a) confirms end-to-end on-chip inference without external post-processing, (b) reports the number of dies and dies-to-die variation statistics, and (c) itemizes all power components (array, IMA, digital LIF, leakage) under the exact conditions used for the accuracy runs. Absence of these details leaves the quoted figures unverifiable as representative silicon performance.
minor comments (1)
- [Abstract] Abstract: the statement of '1.6x improvement' does not identify the reference design or prior result against which the factor is computed.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the major comment on the measurement protocol below and will revise the manuscript to strengthen verifiability of the reported results.
read point-by-point responses
-
Referee: [Abstract and experimental results section] Abstract and experimental results section: the headline claims rest entirely on measured accuracies (97.2% N-MNIST, 95.5% DVS Gesture) and 0.8 pJ/SOP efficiency. The manuscript must supply a complete measurement protocol that (a) confirms end-to-end on-chip inference without external post-processing, (b) reports the number of dies and dies-to-die variation statistics, and (c) itemizes all power components (array, IMA, digital LIF, leakage) under the exact conditions used for the accuracy runs. Absence of these details leaves the quoted figures unverifiable as representative silicon performance.
Authors: We agree that the current version lacks sufficient detail on the measurement protocol, which is required to establish that the headline figures are representative of fabricated silicon performance. In the revised manuscript we will add a dedicated subsection 'Silicon Measurement Protocol' immediately preceding the accuracy results. This subsection will: (a) describe the end-to-end on-chip inference flow, confirming that spike inputs are applied directly to the macro and classification outputs are read from the on-chip digital LIF without any external post-processing; (b) state the number of dies measured and report dies-to-die variation (mean and standard deviation) for both accuracy and energy-efficiency metrics; and (c) provide a table that itemizes power consumption of the array, IMA, digital LIF, and leakage components measured under the exact voltage, frequency, and activity conditions used for the N-MNIST and DVS Gesture accuracy runs. These additions will be placed in the experimental results section and referenced from the abstract. revision: yes
Circularity Check
No circularity: claims rest on direct silicon measurements, not derived quantities or self-referential equations
full rationale
This is a hardware implementation and measurement paper. The central results (97.2% N-MNIST accuracy, 95.5% DVS Gesture accuracy, 0.8 pJ/SOP efficiency) are reported as measured values from fabricated 65 nm silicon under the two operating modes. No mathematical derivation chain, fitted parameters renamed as predictions, or self-citation load-bearing steps appear in the abstract or described content. The design choices (twin 9T cell, reconfigurable IMA, NLD and KWN modes) are presented as engineering decisions whose performance is validated by direct measurement rather than by reduction to prior equations within the paper. This matches the default expectation of a non-circular engineering report.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
2021 , publisher=
Jhang, Chuan-Jia and Xue, Cheng-Xin and Hung, Je-Min and Chang, Fu-Chun and Chang, Meng-Fan , journal=. 2021 , publisher=
2021
-
[2]
2022 , organization=
Jiang, Hongwu and Li, Wantong and Huang, Shanshi and Yu, Shimeng , booktitle=. 2022 , organization=
2022
-
[3]
2023 , organization=
Zhang, Jilin and others , booktitle=. 2023 , organization=
2023
-
[4]
2023 , organization=
Kim, Sangyeob and others , booktitle=. 2023 , organization=
2023
-
[5]
2023 , organization=
Niwa, Atsumi and others , booktitle=. 2023 , organization=
2023
-
[6]
2024 , organization=
Liu, Ying and others , booktitle=. 2024 , organization=
2024
-
[7]
2024 , organization=
Yang, Jiyue and others , booktitle=. 2024 , organization=
2024
-
[8]
2023 , publisher=
Kim, Sangyeob and others , journal=. 2023 , publisher=
2023
-
[9]
2025 , publisher=
Dong, Shuai and others , journal=. 2025 , publisher=
2025
-
[10]
2022 , publisher=
Yu, Chengshuo and others , journal=. 2022 , publisher=
2022
-
[11]
2022 , organization=
Frenkel, Charlotte and others , booktitle=. 2022 , organization=
2022
-
[12]
2025 , organization=
Fu, Haotian and others , booktitle=. 2025 , organization=
2025
-
[13]
2025 , publisher=
Akhoundi, Arash and others , journal=. 2025 , publisher=
2025
-
[14]
2025 , organization=
Sharma, Deepika and others , booktitle=. 2025 , organization=
2025
-
[15]
2024 , organization=
Choi, Byeongseon and others , booktitle=. 2024 , organization=
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.