Addressing Exacerbated Attention Sink for Source-Free Cross-Domain Few-Shot Learning
Pith reviewed 2026-06-29 22:26 UTC · model grok-4.3
The pith
Standard target-domain few-shot fine-tuning exacerbates attention sink in vision-language models for cross-domain few-shot learning, which dynamic token re-weighting corrects.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
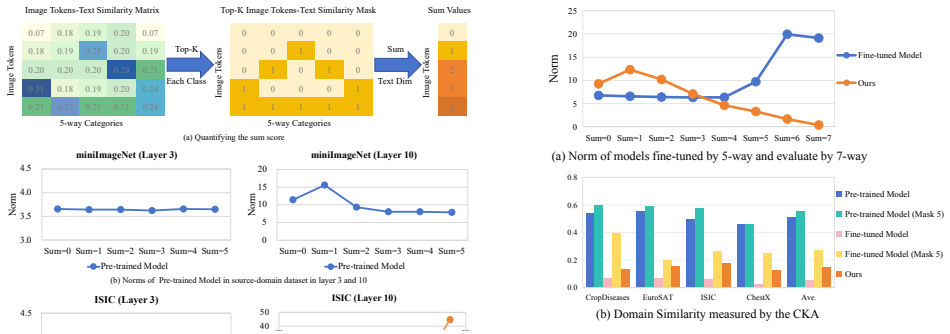
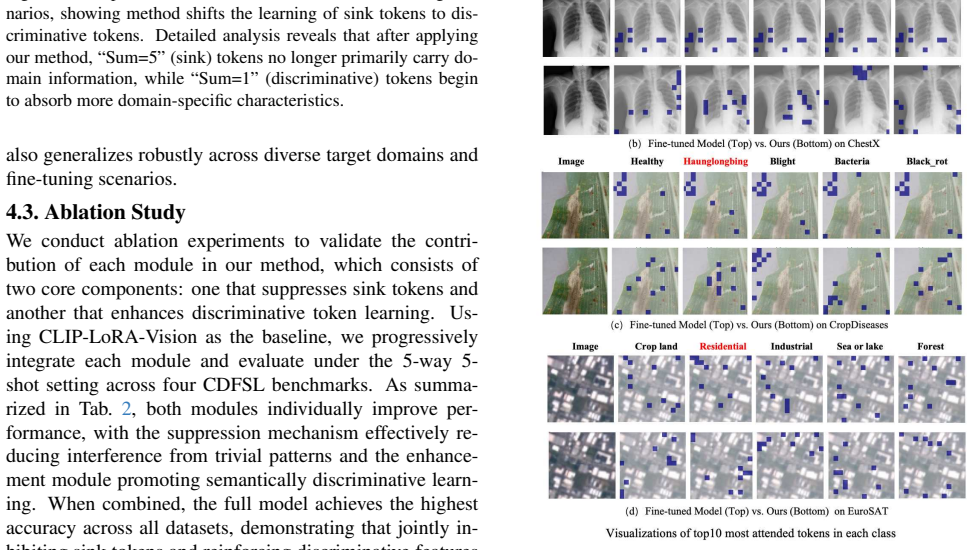
Standard target-domain few-shot fine-tuning in CDFSL significantly exacerbates the attention sink problem, leading to poor discriminability across classes. The model engages in shortcut learning by pushing initially closer tokens even closer to target-domain classes while wasting capacity on initially further but potentially useful tokens. Dynamic token re-weighting during fine-tuning suppresses reliance on these simple tokens and enhances learning of hard tokens, reducing sink tokens and enhancing discriminability.
What carries the argument
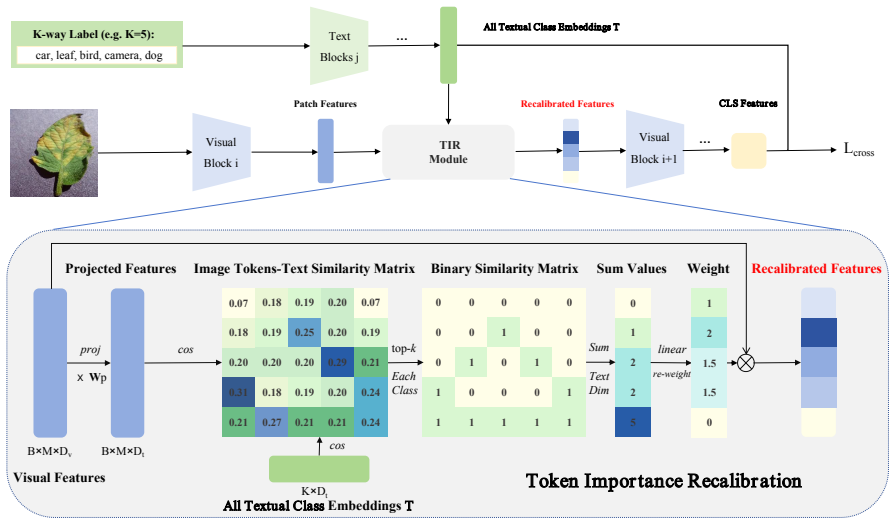
Dynamic token re-weighting according to relevance with target-domain classes during target-domain fine-tuning, which suppresses simple tokens and boosts hard tokens.
Load-bearing premise
The observed attention sink exacerbation is caused by shortcut learning through over-pushing of initially closer tokens, and relevance-based re-weighting will reliably improve hard-token learning without introducing new biases.
What would settle it
Running the proposed re-weighting on a target domain and observing no reduction in sink tokens or no gain in class discriminability would falsify the claim that the method addresses the root cause.
Figures







read the original abstract
Vision-language models (VLMs) like CLIP have shown impressive generalization capabilities, yet their potential for Cross-Domain Few-Shot Learning (CDFSL) remains underexplored, where the model needs to transfer source-domain information to target domains with scarce training data. While the attention sink phenomenon has been observed in VLMs for certain tasks, its role in CDFSL scenarios has not been studied. In this paper, we uncover a critical issue overlooked by prior works: standard target-domain few-shot fine-tuning in CDFSL significantly exacerbates the attention sink problem, leading to poor discriminability across classes. To understand this phenomenon, through extensive experiments, we interpret it as the model's shortcut learning for domain adaptation: to overcome the huge domain gap between the source and target domains, the model shows a high tendency to push tokens that are initially closer to target-domain classes (i.e., simple tokens) to be even closer to these classes, exacerbating the attention sink and wasting the capability of learning other discriminative but initially further tokens (i.e., hard tokens). To address this, we propose a novel approach to dynamically re-weight tokens according to their relevance with target-domain classes during the target-domain finetuning, which explicitly suppresses the model's reliance on these simple tokens and enhances the learning of hard tokens, reducing sink tokens and enhancing discriminability. Extensive experiments on four benchmark datasets validate the rationale of our method, demonstrating new state-of-the-art performance. Our codes are available at https://github.com/shuaiyi308/TIR.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript examines the attention sink phenomenon in vision-language models (e.g., CLIP) under source-free cross-domain few-shot learning (CDFSL). It claims that standard target-domain few-shot fine-tuning exacerbates attention sink via shortcut learning—over-pushing initially closer 'simple tokens' at the expense of 'hard tokens'—leading to reduced class discriminability. The authors propose dynamic relevance-based token re-weighting during fine-tuning to suppress simple tokens and promote hard-token learning, reporting new state-of-the-art results on four benchmark datasets with code released.
Significance. If the causal account and method hold, the work identifies an under-studied limitation of standard fine-tuning in domain-shifted few-shot settings and supplies a targeted mitigation. Reproducibility via public code is a positive factor. The result would be of interest to the CDFSL and VLM fine-tuning communities, though its scope is limited to the specific shortcut-learning interpretation of sink exacerbation.
major comments (2)
- [Abstract / experiments] Abstract and experiments section: the central mechanistic claim—that fine-tuning exacerbates sink specifically by over-pushing simple tokens, which in turn drives poor discriminability—is supported only by before/after attention visualizations and accuracy deltas. No controlled intervention (e.g., ablating the re-weighting while measuring sink growth independently of accuracy) is described to establish that sink growth is the driver rather than a correlated side-effect of domain-gap optimization.
- [Method] Method description: the dynamic re-weighting is presented as explicitly suppressing reliance on simple tokens and enhancing hard tokens, yet the manuscript provides no quantitative verification (e.g., per-token relevance scores or hard-token learning curves) that the re-weighting achieves this targeted effect rather than acting as generic attention regularization. This leaves the shortcut-learning rationale unverified.
minor comments (2)
- [Abstract] The abstract states 'extensive experiments' and 'four benchmark datasets' but supplies no quantitative details, ablation tables, or error bars; these should be summarized with specific metrics even in the abstract.
- [Introduction / Method] Notation for 'simple tokens' and 'hard tokens' is introduced informally; a precise definition (e.g., via initial similarity thresholds or ranking) would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments below and will revise the manuscript to incorporate additional quantitative analyses that strengthen the mechanistic claims.
read point-by-point responses
-
Referee: [Abstract / experiments] Abstract and experiments section: the central mechanistic claim—that fine-tuning exacerbates sink specifically by over-pushing simple tokens, which in turn drives poor discriminability—is supported only by before/after attention visualizations and accuracy deltas. No controlled intervention (e.g., ablating the re-weighting while measuring sink growth independently of accuracy) is described to establish that sink growth is the driver rather than a correlated side-effect of domain-gap optimization.
Authors: We agree that the current evidence is primarily correlational via visualizations and accuracy results. To better isolate causality, we will add a controlled ablation in the revised experiments section that tracks independent sink metrics (e.g., sink token attention mass and ratio) throughout fine-tuning both with and without the re-weighting module, while holding other optimization factors fixed. revision: yes
-
Referee: [Method] Method description: the dynamic re-weighting is presented as explicitly suppressing reliance on simple tokens and enhancing hard tokens, yet the manuscript provides no quantitative verification (e.g., per-token relevance scores or hard-token learning curves) that the re-weighting achieves this targeted effect rather than acting as generic attention regularization. This leaves the shortcut-learning rationale unverified.
Authors: We will augment the method and experimental sections with quantitative verification, including training curves of per-token relevance scores separated by simple vs. hard tokens and direct comparisons of token-type contributions with/without re-weighting. These additions will confirm the targeted suppression effect beyond generic regularization. revision: yes
Circularity Check
No circularity: empirical method with independent motivation
full rationale
The paper's central contribution is an empirical observation of attention sink exacerbation in CDFSL followed by a proposed dynamic token re-weighting heuristic. No equations, fitted parameters, or self-citation chains are present that would reduce the claimed improvement to a definitional or statistical tautology. The interpretation of shortcut learning is presented as post-hoc analysis of visualizations and accuracy deltas rather than a closed-form derivation. The method itself is a novel intervention motivated by external observations of the sink phenomenon, not by re-labeling its own inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Kazi Hasan Ibn Arif, Sajib Acharjee Dip, Khizar Hussain, Lang Zhang, and Chris Thomas. Paint: Paying attention to informed tokens to mitigate hallucination in large vision- language model.arXiv preprint arXiv:2501.12206, 2025. 8, 4
-
[2]
Perception Encoder: The best visual embeddings are not at the output of the network
Daniel Bolya, Po-Yao Huang, Peize Sun, Jang Hyun Cho, Andrea Madotto, Chen Wei, Tengyu Ma, Jiale Zhi, Jathushan Rajasegaran, Hanoona Rasheed, et al. Perception encoder: The best visual embeddings are not at the output of the net- work.arXiv preprint arXiv:2504.13181, 2025. 2
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Emre Celebi, Stephen Dusza, David Gutman, Brian Helba, Aadi Kalloo, Konstantinos Liopyris, Michael Marchetti, Harald Kittler, and Allan Halpern
Noel Codella, Veronica Rotemberg, Philipp Tschandl, M. Emre Celebi, Stephen Dusza, David Gutman, Brian Helba, Aadi Kalloo, Konstantinos Liopyris, Michael Marchetti, Harald Kittler, and Allan Halpern. Skin le- sion analysis toward melanoma detection 2018: A challenge hosted by the international skin imaging collaboration (isic),
2018
-
[4]
Vision transformers need registers
Timoth ´ee Darcet, Maxime Oquab, Julien Mairal, and Piotr Bojanowski. Vision transformers need registers. InThe Twelfth International Conference on Learning Representa- tions, 2024. 8, 4
2024
-
[5]
Reliability of cka as a similarity measure in deep learning, 2022
MohammadReza Davari, Stefan Horoi, Amine Natik, Guil- laume Lajoie, Guy Wolf, and Eugene Belilovsky. Reliability of cka as a similarity measure in deep learning, 2022. 2
2022
-
[6]
Imagenet: A large-scale hierarchical image database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 248–255. Ieee, 2009. 1
2009
-
[7]
Meta-fdmixup: Cross-domain few-shot learning guided by labeled target data
Yuqian Fu, Yanwei Fu, and Yu-Gang Jiang. Meta-fdmixup: Cross-domain few-shot learning guided by labeled target data. InProceedings of the 29th ACM international con- ference on multimedia, pages 5326–5334, 2021. 6
2021
-
[8]
Wave-san: Wavelet based style augmentation network for cross-domain few-shot learning, 2022
Yuqian Fu, Yu Xie, Yanwei Fu, Jingjing Chen, and Yu-Gang Jiang. Wave-san: Wavelet based style augmentation network for cross-domain few-shot learning, 2022. 8
2022
-
[9]
Styleadv: Meta style adversarial training for cross-domain few-shot learning, 2023
Yuqian Fu, Yu Xie, Yanwei Fu, and Yu-Gang Jiang. Styleadv: Meta style adversarial training for cross-domain few-shot learning, 2023. 6
2023
-
[10]
When Attention Sink Emerges in Language Models: An Empirical View
Xiangming Gu, Tianyu Pang, Chao Du, Qian Liu, Fengzhuo Zhang, Cunxiao Du, Ye Wang, and Min Lin. When attention sink emerges in language models: An empirical view.arXiv preprint arXiv:2410.10781, 2024. 1, 3, 8
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[11]
Eurosat: A novel dataset and deep learning benchmark for land use and land cover classification, 2019
Patrick Helber, Benjamin Bischke, Andreas Dengel, and Damian Borth. Eurosat: A novel dataset and deep learning benchmark for land use and land cover classification, 2019. 6, 1
2019
-
[12]
Lora: Low-rank adaptation of large language models.ICLR, 1(2):3, 2022
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen- Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models.ICLR, 1(2):3, 2022. 4
2022
-
[13]
Yanxu Hu and Andy J. Ma. Adversarial feature augmentation for cross-domain few-shot classification, 2022. 8
2022
-
[14]
Mingi Jung, Saehyung Lee, Eunji Kim, and Sungroh Yoon. Visual attention never fades: Selective progressive attention recalibration for detailed image captioning in multimodal large language models.arXiv preprint arXiv:2502.01419,
-
[15]
arXiv preprint arXiv:2503.03321 (2025)
Seil Kang, Jinyeong Kim, Junhyeok Kim, and Seong Jae Hwang. See what you are told: Visual attention sink in large multimodal models.arXiv preprint arXiv:2503.03321, 2025. 8
-
[16]
Maple: Multi-modal prompt learning
Muhammad Uzair Khattak, Hanoona Rasheed, Muham- mad Maaz, Salman Khan, and Fahad Shahbaz Khan. Maple: Multi-modal prompt learning. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 19113–19122, 2023. 4
2023
-
[17]
On the stability-plasticity dilemma of class-incremental learning
Dongwan Kim and Bohyung Han. On the stability-plasticity dilemma of class-incremental learning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 20196–20204, 2023. 2
2023
-
[18]
Similarity of neural network represen- tations revisited
Simon Kornblith, Mohammad Norouzi, Honglak Lee, and Geoffrey Hinton. Similarity of neural network represen- tations revisited. InInternational Conference on Machine Learning, pages 3519–3529. PMLR, 2019. 1
2019
-
[19]
Ran Ma, Yixiong Zou, Yuhua Li, and Ruixuan Li. Recon- struction target matters in masked image modeling for cross- domain few-shot learning.arXiv preprint arXiv:2412.19101,
-
[20]
Mohanty, David P
Sharada P. Mohanty, David P. Hughes, and Marcel Salath ´e. Using deep learning for image-based plant disease detection. Frontiers in Plant Science, 7(September), 2016. Publisher Copyright: © 2016 Mohanty, Hughes and Salath´e. 6, 1
2016
-
[21]
Understanding cross- domain few-shot learning based on domain similarity and few-shot difficulty, 2022
Jaehoon Oh, Sungnyun Kim, Namgyu Ho, Jin-Hwa Kim, Hwanjun Song, and Se-Young Yun. Understanding cross- domain few-shot learning based on domain similarity and few-shot difficulty, 2022. 1
2022
-
[22]
Explanation-guided training for cross-domain few-shot clas- sification
Jiamei Sun, Sebastian Lapuschkin, Wojciech Samek, Yun- qing Zhao, Ngai-Man Cheung, and Alexander Binder. Explanation-guided training for cross-domain few-shot clas- sification. In2020 25th international conference on pattern recognition (ICPR), pages 7609–7616. IEEE, 2021. 6
2021
-
[23]
Michael Tschannen, Alexey Gritsenko, Xiao Wang, Muham- mad Ferjad Naeem, Ibrahim Alabdulmohsin, Nikhil Parthasarathy, Talfan Evans, Lucas Beyer, Ye Xia, Basil Mustafa, et al. Siglip 2: Multilingual vision-language en- coders with improved semantic understanding, localization, and dense features.arXiv preprint arXiv:2502.14786, 2025. 2
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[24]
Matching networks for one shot learning
Oriol Vinyals, Charles Blundell, Timothy Lillicrap, Koray Kavukcuoglu, and Daan Wierstra. Matching networks for one shot learning. InProceedings of the International Con- ference on Neural Information Processing Systems, pages 3637–3645, 2016. 1
2016
-
[25]
Xiaosong Wang, Yifan Peng, Le Lu, Zhiyong Lu, Mo- hammadhadi Bagheri, and Ronald M. Summers. Chestx- ray8: Hospital-scale chest x-ray database and benchmarks on weakly-supervised classification and localization of com- mon thorax diseases. In2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, 2017. 3, 6, 1
2017
-
[26]
Yining Wang, Mi Zhang, Junjie Sun, Chenyue Wang, Min Yang, Hui Xue, Jialing Tao, Ranjie Duan, and Jiexi Liu. Mi- rage in the eyes: Hallucination attack on multi-modal large language models with only attention sink.arXiv preprint arXiv:2501.15269, 1, 2025. 1
-
[27]
On attention and norms: An opinionated review of recent work.Analysis, 84(1):173–201, 2024
Wayne Wu. On attention and norms: An opinionated review of recent work.Analysis, 84(1):173–201, 2024. 2
2024
-
[28]
Efficient Streaming Language Models with Attention Sinks
Guangxuan Xiao, Yuandong Tian, Beidi Chen, Song Han, and Mike Lewis. Efficient streaming language models with attention sinks.arXiv preprint arXiv:2309.17453, 2023. 1, 8
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[29]
Huali Xu, Shuaifeng Zhi, Shuzhou Sun, Vishal M Patel, and Li Liu. Deep learning for cross-domain few-shot visual recognition: A survey.arXiv preprint arXiv:2303.08557,
-
[30]
Huali Xu, Li Liu, Tianpeng Liu, Shuaifeng Zhi, Shuzhou Sun, and Ming-Ming Cheng. Step-wise distribution align- ment guided style prompt tuning for source-free cross- domain few-shot learning.arXiv preprint arXiv:2411.10070,
-
[31]
Huali Xu, Li Liu, Shuaifeng Zhi, Shaojing Fu, Zhuo Su, Ming-Ming Cheng, and Yongxiang Liu. Enhancing infor- mation maximization with distance-aware contrastive learn- ing for source-free cross-domain few-shot learning.IEEE Transactions on Image Processing, 33:2058–2073, 2024. 1, 6
2058
-
[32]
Cross-domain detection via graph-induced proto- type alignment
Minghao Xu, Hang Wang, Bingbing Ni, Qi Tian, and Wen- jun Zhang. Cross-domain detection via graph-induced proto- type alignment. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 12355– 12364, 2020. 4
2020
-
[33]
Visual domain bridge: A source-free domain adaptation for cross-domain few-shot learning
Moslem Yazdanpanah and Parham Moradi. Visual domain bridge: A source-free domain adaptation for cross-domain few-shot learning. InProceedings of the IEEE/CVF con- ference on computer vision and pattern recognition, pages 2868–2877, 2022. 6
2022
-
[34]
Random registers for cross-domain few-shot learning.arXiv preprint arXiv:2506.02843, 2025
Shuai Yi, Yixiong Zou, Yuhua Li, and Ruixuan Li. Random registers for cross-domain few-shot learning.arXiv preprint arXiv:2506.02843, 2025. 6, 8
-
[35]
Shuai Yi, Yixiong Zou, Yuhua Li, and Ruixuan Li. Revis- iting continuity of image tokens for cross-domain few-shot learning.arXiv preprint arXiv:2506.03110, 2025. 1, 6, 8
-
[36]
Low-rank few-shot adaptation of vision-language models
Maxime Zanella and Ismail Ben Ayed. Low-rank few-shot adaptation of vision-language models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1593–1603, 2024. 6
2024
-
[37]
Xiaofeng Zhang, Yihao Quan, Chaochen Gu, Chen Shen, Xiaosong Yuan, Shaotian Yan, Hao Cheng, Kaijie Wu, and Jieping Ye. Seeing clearly by layer two: Enhancing atten- tion heads to alleviate hallucination in lvlms.arXiv preprint arXiv:2411.09968, 2024. 1
-
[38]
Micm: Rethinking un- supervised pretraining for enhanced few-shot learning
Zhenyu Zhang, Guangyao Chen, Yixiong Zou, Zhimeng Huang, Yuhua Li, and Ruixuan Li. Micm: Rethinking un- supervised pretraining for enhanced few-shot learning. In Proceedings of the 32nd ACM International Conference on Multimedia, pages 7686–7695, 2024. 8
2024
-
[39]
Learning unknowns from unknowns: Di- versified negative prototypes generator for few-shot open-set recognition
Zhenyu Zhang, Guangyao Chen, Yixiong Zou, Yuhua Li, and Ruixuan Li. Learning unknowns from unknowns: Di- versified negative prototypes generator for few-shot open-set recognition. InProceedings of the 32nd ACM International Conference on Multimedia, pages 6053–6062, 2024. 8
2024
-
[40]
Decoupling template bias in clip: Harnessing empty prompts for enhanced few-shot learning
Zhenyu Zhang, Guangyao Chen, Yixiong Zou, Zhimeng Huang, and Yuhua Li. Decoupling template bias in clip: Harnessing empty prompts for enhanced few-shot learning. arXiv preprint arXiv:2512.08606, 2025. 2
-
[41]
Zhenyu Zhang, Guangyao Chen, Yixiong Zou, Yuhua Li, and Ruixuan Li. Reclaiming lost text layers for source-free cross- domain few-shot learning.arXiv preprint arXiv:2603.05235,
-
[42]
Zhenyu Zhang, Yixiong Zou, Yuhua Li, Ruixuan Li, and Guangyao Chen. Mind the discriminability trap in source-free cross-domain few-shot learning.arXiv preprint arXiv:2603.13341, 2026. 8
-
[43]
Clip in medical imaging: A comprehensive sur- vey.arXiv preprint arXiv:2312.07353, 2023
Zihao Zhao, Yuxiao Liu, Han Wu, Mei Wang, Yonghao Li, Sheng Wang, Lin Teng, Disheng Liu, Zhiming Cui, Qian Wang, et al. Clip in medical imaging: A comprehensive sur- vey.arXiv preprint arXiv:2312.07353, 2023. 1
-
[44]
Revisiting prototypical network for cross domain few-shot learning
Fei Zhou, Peng Wang, Lei Zhang, Wei Wei, and Yanning Zhang. Revisiting prototypical network for cross domain few-shot learning. InProceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition (CVPR), pages 20061–20070, 2023. 8
2023
-
[45]
Conditional prompt learning for vision-language mod- els
Kaiyang Zhou, Jingkang Yang, Chen Change Loy, and Ziwei Liu. Conditional prompt learning for vision-language mod- els. InProceedings of the IEEE/CVF conference on com- puter vision and pattern recognition, pages 16816–16825,
-
[46]
Atten- tion temperature matters in vit-based cross-domain few-shot learning
Yixiong Zou, Ran Ma, Yuhua Li, and Ruixuan Li. Atten- tion temperature matters in vit-based cross-domain few-shot learning. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems, . 6, 8
-
[47]
A closer look at the cls token for cross-domain few-shot learning
Yixiong Zou, Shuai Yi, Yuhua Li, and Ruixuan Li. A closer look at the cls token for cross-domain few-shot learning. In The Thirty-eighth Annual Conference on Neural Information Processing Systems, . 4, 6
-
[48]
Flatten long-range loss landscapes for cross-domain few- shot learning, 2024
Yixiong Zou, Yicong Liu, Yiman Hu, Yuhua Li, and Ruixuan Li. Flatten long-range loss landscapes for cross-domain few- shot learning, 2024. 1, 2, 6
2024
-
[49]
Compositional few-shot class-incremental learning.arXiv preprint arXiv:2405.17022, 2024
Yixiong Zou, Shanghang Zhang, Haichen Zhou, Yuhua Li, and Ruixuan Li. Compositional few-shot class-incremental learning.arXiv preprint arXiv:2405.17022, 2024. 4 Addressing Exacerbated Attention Sink for Source-Free Cross-Domain Few-Shot Learning Supplementary Material
-
[50]
Representative samples from the source-domain miniImageNet dataset
Detailed Dataset Description miniImageNet Source-domain Dataset Figure 9. Representative samples from the source-domain miniImageNet dataset. miniImageNet[24] is a widely adopted benchmark in meta-learning and few-shot learning, comprising a curated subset of the original ImageNet [6] dataset. The dataset contains 60,000 color images distributed across 10...
-
[51]
Detailed Descriptions of the CKA Following established practices in domain similarity mea- surement [18, 21], we employ Centered Kernel Alignment (CKA) to quantitatively assess the similarity between fea- ture representations across different domains. CKA is a robust statistical method specifically designed to compare high-dimensional representations lear...
-
[52]
More Experiments 9.1. Norm distribution of different sum numbers from layer 0 to layer 11 We provide comprehensive layer-wise analyses of token norm distributions across all transformer layers (0 to 11) in Fig.11. The complete visualization across all layers of- fers deeper insights into the evolution of semantic aware- ness and attention patterns through...
-
[53]
Sum=1”), while the target domain fine-tuned model shifts toward non-discriminative tokens (“Sum=5
Our approach consistently achieves improvements over the baselines in both the 1-shot and 5-shot settings, demon- Norms of Pre-trained Model in source-domain dataset (miniImageNet) and Norms of three models in target-domain datasets (CropDiseases, EuroSAT, ISIC, ChestX) in layer 0-11 4.5 5.0 5.5 Sum=0 Sum=1 Sum=2 Sum=3 Sum=4 Sum=5 miniImageNet (Layer 0) P...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.