FATHOMS-RAG: A Framework for the Assessment of Thinking and Observation in Multimodal Systems that use Retrieval Augmented Generation
Pith reviewed 2026-05-25 08:09 UTC · model grok-4.3
The pith
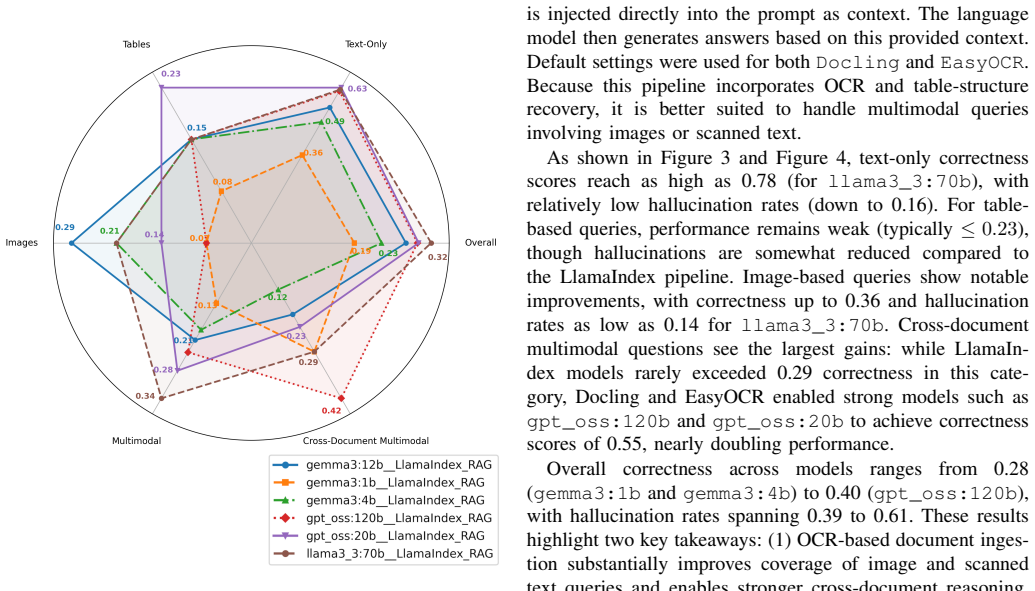
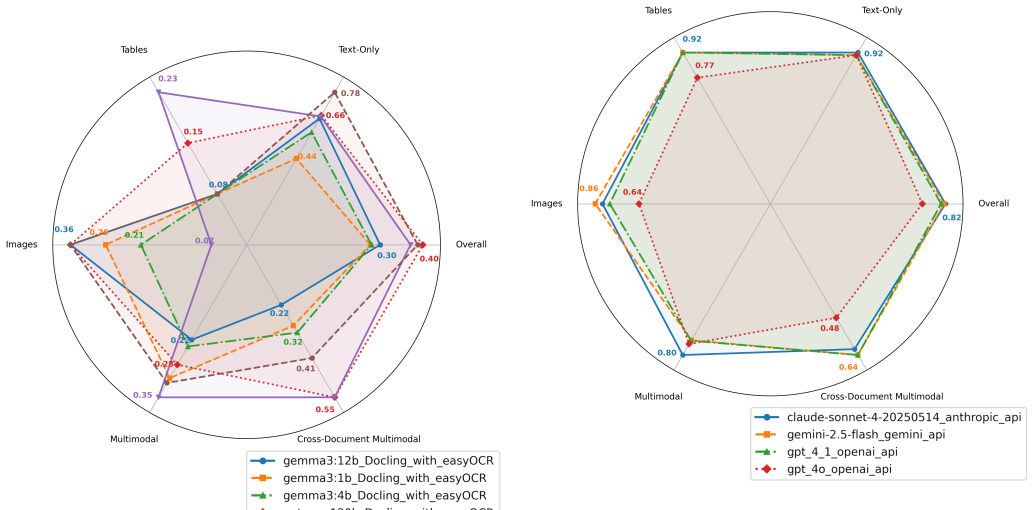
Closed-source RAG pipelines outperform open-source ones on multimodal and cross-document questions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
A benchmark consisting of 93 human-created questions, phrase-level recall, and nearest-neighbor embedding hallucination detection shows that closed-source RAG pipelines significantly outperform open-source pipelines in correctness and hallucination avoidance, with the performance gap widening on questions that depend on multimodal or cross-document information.
What carries the argument
The 93-question dataset spanning text, tables, images, and cross-document modalities, together with phrase-level recall for correctness and nearest-neighbor embedding classification for hallucination detection.
If this is right
- Closed-source pipelines maintain higher correctness and lower hallucination rates across all question types.
- The advantage of closed-source systems increases when questions require combining information from images, tables, or multiple documents.
- The phrase-level recall and embedding-based hallucination metrics align closely with third-party human judgments.
- Open-source retrieval mechanisms remain a limiting factor when pipelines must reason over non-text modalities or distributed sources.
Where Pith is reading between the lines
- Open-source RAG development may need targeted improvements in multimodal retrieval and cross-document linking to close the observed gap.
- Small human-curated test sets like this one could be used to guide iterative pipeline tuning before scaling to larger automated evaluations.
- The benchmark's separation of ingestion, retrieval, and reasoning stages offers a template for diagnosing where a given pipeline fails.
Load-bearing premise
The 93 questions and the two automated metrics together give a representative, unbiased picture of any RAG pipeline's ability to handle multimodal and cross-document information.
What would settle it
A larger or differently sampled question set that shows open-source pipelines matching or exceeding closed-source performance on the same metrics, or human raters showing low agreement with the automated scores.
Figures



read the original abstract
Retrieval-augmented generation (RAG) has emerged as a promising paradigm for improving factual accuracy in large language models (LLMs). We introduce a benchmark designed to evaluate RAG pipelines as a whole, evaluating a pipeline's ability to ingest, retrieve, and reason about several modalities of information, differentiating it from existing benchmarks that focus on particular aspects such as retrieval. We present (1) a small, human-created dataset of 93 questions designed to evaluate a pipeline's ability to ingest textual data, tables, images, and data spread across these modalities in one or more documents; (2) a phrase-level recall metric for correctness; (3) a nearest-neighbor embedding classifier to identify potential pipeline hallucinations; (4) a comparative evaluation of 2 pipelines built with open-source retrieval mechanisms and 4 closed-source foundation models; and (5) a third-party human evaluation of the alignment of our correctness and hallucination metrics. We find that closed-source pipelines significantly outperform open-source pipelines in both correctness and hallucination metrics, with wider performance gaps in questions relying on multimodal and cross-document information. Human evaluation of our metrics showed average agreement of 4.62 for correctness and 4.53 for hallucination detection on a 1-5 Likert scale (5 indicating "strongly agree").
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces FATHOMS-RAG, a benchmark framework for holistic evaluation of RAG pipelines on multimodal (text/tables/images) and cross-document reasoning. It contributes (1) a 93-question human-created dataset spanning these modalities and single/cross-document cases, (2) a phrase-level recall metric for correctness, (3) a nearest-neighbor embedding classifier for hallucination detection, (4) comparative results on 2 open-source retrieval pipelines and 4 closed-source foundation models, and (5) human validation of the metrics (avg. Likert agreement 4.62/4.53 on a 22-question subset). The central claim is that closed-source pipelines significantly outperform open-source ones on both metrics, with wider gaps on multimodal and cross-document questions.
Significance. If the performance differences and their modality dependence hold under proper validation, the work supplies a needed end-to-end benchmark that goes beyond isolated retrieval metrics and supplies human-validated automatic proxies for correctness and hallucination. The explicit construction of a multimodal/cross-document test set and the third-party human agreement study are concrete strengths that could support reproducible pipeline comparisons.
major comments (3)
- [Dataset construction] Dataset construction (abstract and § on data): the 93 questions are described only as “human-created” to cover modalities and single vs. cross-document cases, with no table or section reporting the actual counts per category, no stratification details, no inter-annotator agreement on question design, and no power or bootstrap analysis. This directly undermines the claim of “significantly wider performance gaps” on multimodal/cross-document items, as any imbalance in difficulty or distribution can produce the observed pattern with N=93.
- [Comparative evaluation] Evaluation results (comparative evaluation section): no statistical tests, error bars, confidence intervals, or variance analysis across modalities are reported for the correctness and hallucination differences between the 2 open-source and 4 closed-source pipelines. The central claim that closed-source pipelines “significantly outperform” and exhibit “wider gaps” therefore lacks the quantitative support required to distinguish genuine capability differences from sampling artifacts.
- [Human evaluation] Metric validation (human evaluation section): the phrase-level recall and nearest-neighbor embedding hallucination metrics are novel and are validated only against human ratings on a 22-question subset. Given that these metrics are load-bearing for all reported performance numbers, the small validation set size leaves open whether the high average Likert scores (4.62/4.53) generalize to the full 93-question set or to the multimodal subset.
minor comments (2)
- [Abstract] The abstract states “2 pipelines built with open-source retrieval mechanisms and 4 closed-source foundation models” but does not name the exact model versions or retrieval implementations; this information should be added for reproducibility.
- [Metric definitions] Notation for the nearest-neighbor embedding classifier (e.g., how the decision threshold is chosen and whether it is fixed or tuned) is not fully specified in the metric definition section.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below, indicating planned revisions where feasible while being transparent about limitations in the original work.
read point-by-point responses
-
Referee: [Dataset construction] Dataset construction (abstract and § on data): the 93 questions are described only as “human-created” to cover modalities and single vs. cross-document cases, with no table or section reporting the actual counts per category, no stratification details, no inter-annotator agreement on question design, and no power or bootstrap analysis. This directly undermines the claim of “significantly wider performance gaps” on multimodal/cross-document items, as any imbalance in difficulty or distribution can produce the observed pattern with N=93.
Authors: We agree that a detailed breakdown of dataset composition is needed for transparency. In the revised manuscript we will add a table reporting question counts by modality (text/tables/images) and by single- versus cross-document setting. The questions were designed by one primary author with team review; no formal inter-annotator agreement was collected. We will also add an explicit limitations paragraph noting the small fixed N=93 and the absence of power or bootstrap analysis. We maintain that the patterns are directionally informative but accept that stronger claims about modality-specific gaps require these details. revision: partial
-
Referee: [Comparative evaluation] Evaluation results (comparative evaluation section): no statistical tests, error bars, confidence intervals, or variance analysis across modalities are reported for the correctness and hallucination differences between the 2 open-source and 4 closed-source pipelines. The central claim that closed-source pipelines “significantly outperform” and exhibit “wider gaps” therefore lacks the quantitative support required to distinguish genuine capability differences from sampling artifacts.
Authors: We accept that the lack of statistical support weakens the central claims. In revision we will add confidence intervals for all reported metrics, perform paired statistical tests (e.g., Wilcoxon signed-rank or McNemar) on pipeline differences, and include modality-stratified variance where sample sizes permit. We will also discuss the limited statistical power given the modest total N and smaller subcategory sizes. revision: yes
-
Referee: [Human evaluation] Metric validation (human evaluation section): the phrase-level recall and nearest-neighbor embedding hallucination metrics are novel and are validated only against human ratings on a 22-question subset. Given that these metrics are load-bearing for all reported performance numbers, the small validation set size leaves open whether the high average Likert scores (4.62/4.53) generalize to the full 93-question set or to the multimodal subset.
Authors: The 22-question subset was selected to cover all modalities and question types, but we acknowledge its small size limits generalizability. In revision we will document the selection criteria, report any available per-category agreement, and add a limitations statement that the high Likert scores provide only preliminary evidence and do not guarantee performance on the full set or multimodal questions. Expanding validation to all 93 questions would require substantial additional human effort that was not feasible in the original study. revision: partial
Circularity Check
No significant circularity; metrics and claims are independently defined
full rationale
The paper introduces a fixed human-created dataset of 93 questions and two metrics (phrase-level recall for correctness; nearest-neighbor embedding classifier for hallucinations) that are defined prior to and independently of any pipeline evaluation results. These are then applied to compare open- and closed-source pipelines, with a separate human validation study (average Likert agreement 4.62/4.53) providing external alignment check. No equations, fitted parameters renamed as predictions, self-definitional constructs, or load-bearing self-citations appear in the derivation; the performance-gap claims remain empirical observations on fixed inputs rather than reductions to the inputs themselves.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The 93 questions are representative of real-world multimodal and cross-document RAG challenges
Reference graph
Works this paper leans on
-
[1]
Mmlu-pro: A more robust and challenging multi-task language understanding benchmark,
Y . Wang, X. Ma, G. Zhang, Y . Ni, A. Chandra, S. Guo, W. Ren, A. Arulraj, X. He, Z. Jiang, T. Li, M. Ku, K. Wang, A. Zhuang, R. Fan, X. Yue, and W. Chen, “Mmlu-pro: A more robust and challenging multi-task language understanding benchmark,” in Advances in Neural Information Processing Systems, A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. T...
work page 2024
-
[2]
Mmmu: A massive multi-discipline multimodal understanding and reasoning benchmark for expert agi,
X. Yue, Y . Ni, T. Zheng, K. Zhang, R. Liu, G. Zhang, S. Stevens, D. Jiang, W. Ren, Y . Sunet al., “Mmmu: A massive multi-discipline multimodal understanding and reasoning benchmark for expert agi,” in 2024 IEEE/CVF Conference on Computer Vision and Pattern Recogni- tion (CVPR). IEEE, 2024, pp. 9556–9567
work page 2024
-
[3]
Nphardeval4v: A dynamic reasoning benchmark of multimodal large language models,
L. Fan, W. Hua, X. Li, K. Zhu, M. Jin, L. Li, H. Ling, J. Chi, J. Wang, X. Ma, and Y . Zhang, “Nphardeval4v: A dynamic reasoning benchmark of multimodal large language models,” 2024. [Online]. Available: https://arxiv.org/abs/2403.01777
-
[4]
Mllm-compbench: A comparative reason- ing benchmark for multimodal llms,
J. Kil, Z. Mai, J. Lee, A. Chowdhury, Z. Wang, K. Cheng, L. Wang, Y . Liu, and W.-L. H. Chao, “Mllm-compbench: A comparative reason- ing benchmark for multimodal llms,”Advances in Neural Information Processing Systems, vol. 37, pp. 28 798–28 827, 2024
work page 2024
-
[5]
Rbench: Graduate-level multi- disciplinary benchmarks for llm & mllm complex reasoning evaluation,
M.-H. Guo, J. Xu, Y . Zhang, J. Song, H. Peng, Y .-X. Deng, X. Dong, K. Nakayama, Z. Geng, C. Wanget al., “Rbench: Graduate-level multi- disciplinary benchmarks for llm & mllm complex reasoning evaluation,” inF orty-second International Conference on Machine Learning, 2025
work page 2025
-
[6]
Can mllms reason in multimodality? emma: An enhanced multimodal reasoning benchmark,
Y . Hao, J. Gu, H. W. Wang, L. Li, Z. Yang, L. Wang, and Y . Cheng, “Can mllms reason in multimodality? emma: An enhanced multimodal reasoning benchmark,” inF orty-second International Conference on Machine Learning, 2025
work page 2025
-
[7]
Crag - comprehensive rag benchmark,
X. Yang, K. Sun, H. Xin, Y . Sun, N. Bhalla, X. Chen, S. Choudhary, R. D. Gui, Z. W. Jiang, Z. Jiang, L. Kong, B. Moran, J. Wang, Y . E. Xu, A. Yan, C. Yang, E. Yuan, H. Zha, N. Tang, L. Chen, N. Scheffer, Y . Liu, N. Shah, R. Wanga, A. Kumar, W.-t. Yih, and X. L. Dong, “Crag - comprehensive rag benchmark,” inAdvances in Neural Information Processing Syst...
work page 2024
-
[8]
Ragas: Automated Evaluation of Retrieval Augmented Generation
S. Es, J. James, L. Espinosa-Anke, and S. Schockaert, “Ragas: Au- tomated evaluation of retrieval augmented generation,”arXiv preprint arXiv:2309.15217, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[9]
Detecting hallucinations in large language models using semantic entropy,
S. Farquhar, J. Kossen, L. Kuhn, and Y . Gal, “Detecting hallucinations in large language models using semantic entropy,”Nature, vol. 630, no. 8017, pp. 625–630, 2024
work page 2024
-
[10]
W. Su, C. Wang, Q. Ai, Y . Hu, Z. Wu, Y . Zhou, and Y . Liu, “Unsu- pervised real-time hallucination detection based on the internal states of large language models,”Findings of the Association for Computational Linguistics, 2024
work page 2024
-
[11]
Docllm: A layout-aware generative language model for multimodal document understanding,
D. Wang, N. Raman, M. Sibue, Z. Ma, P. Babkin, S. Kaur, Y . Pei, A. Nourbakhsh, and X. Liu, “Docllm: A layout-aware generative language model for multimodal document understanding,” 2023. [Online]. Available: https://arxiv.org/abs/2401.00908
-
[12]
Physics-constrained flow matching: Sampling generative models with hard constraints,
U. Utkarsh, P. Cai, A. Edelman, R. Gomez-Bombarelli, and C. V . Rackauckas, “Physics-constrained flow matching: Sampling generative models with hard constraints,” 2025. [Online]. Available: https://arxiv.org/abs/2506.04171
-
[13]
The path to autonomous cyber defense,
S. Oesch, P. Austria, A. Chaulagain, B. Weber, C. Watson, M. Dixson, and A. Sadovnik, “The path to autonomous cyber defense,” 2024. [Online]. Available: https://arxiv.org/abs/2404.10788
-
[14]
Chartmimic: Evaluating lmm’s cross-modal reasoning capability via chart-to-code generation,
C. Yang, C. Shi, Y . Liu, B. Shui, J. Wang, M. Jing, L. Xu, X. Zhu, S. Li, Y . Zhang, G. Liu, X. Nie, D. Cai, and Y . Yang, “Chartmimic: Evaluating lmm’s cross-modal reasoning capability via chart-to-code generation,” 2025. [Online]. Available: https://arxiv.org/abs/2406.09961 TABLE II FULLLIST OFCORRECTNESS ANDHALLUCINATIONSCORES ACROSS ALLEVALUATIONS Pi...
-
[15]
Enigmaeval: A benchmark of long multimodal reasoning challenges,
C. J. Wang, D. Lee, C. Menghini, J. Mols, J. Doughty, A. Khoja, J. Lynch, S. Hendryx, S. Yue, and D. Hendrycks, “Enigmaeval: A benchmark of long multimodal reasoning challenges,” 2025. [Online]. Available: https://arxiv.org/abs/2502.08859
-
[16]
Hypertransformer: Model generation for supervised and semi-supervised few-shot learning,
A. Zhmoginov, M. Sandler, and M. Vladymyrov, “Hypertransformer: Model generation for supervised and semi-supervised few-shot learning,” 2022. [Online]. Available: https://arxiv.org/abs/2201.04182
-
[17]
Multimodal Chain-of-Thought Reasoning in Language Models
Z. Zhang, A. Zhang, M. Li, H. Zhao, G. Karypis, and A. Smola, “Multimodal chain-of-thought reasoning in language models,” 2024. [Online]. Available: https://arxiv.org/abs/2302.00923 APPENDIXA FULLTABLE OFEVALUATIONRESULTS All gathered correctness and hallucination scores are in- cluded in Table A. All of the code and raw result JSON files containing pipel...
work page internal anchor Pith review Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.