PySIFT: GPU-Resident Deterministic SIFT for Deep Learning Vision Pipelines
Pith reviewed 2026-05-20 11:56 UTC · model grok-4.3
The pith
Classical SIFT with DSP multi-scale pooling beats neural descriptor replacements on accuracy and runs 2-18 times faster across four benchmarks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
An eight-configuration ablation spanning four benchmarks demonstrates that classical SIFT paired with DSP multi-scale pooling outperforms neural descriptor and orientation replacements on every accuracy metric while executing 2-18 times faster; learned matchers such as LightGlue complement rather than replace the classical front end.
What carries the argument
DSP multi-scale pooling inside a fully GPU-resident SIFT pipeline that keeps all stages in VRAM and hands data to downstream networks via zero-copy DLPack.
If this is right
- Local feature pipelines can retain classical extraction for speed and determinism without accuracy penalty when paired with modern learned matchers.
- Reproducibility across GPU architectures becomes achievable for keypoint detection and description.
- Fully learned local feature stacks are not required for top performance on standard matching benchmarks.
- Modular GPU implementations allow direct head-to-head testing of classical versus learned stages inside the same memory-resident workflow.
Where Pith is reading between the lines
- The same modular GPU approach could be applied to other classical detectors to test whether multi-scale pooling yields similar gains.
- Deterministic classical features may simplify large-scale reproducibility studies where learned extractors currently vary by hardware.
- If the accuracy advantage persists on additional tasks such as structure-from-motion with very wide baselines, the composition strategy would gain further support.
Load-bearing premise
The ablation assumes DSP multi-scale pooling is a neutral, standard addition to classical SIFT rather than a tuned component whose benefit is isolated from the learned baselines.
What would settle it
Re-run the identical eight-configuration ablation after removing DSP multi-scale pooling from the classical arm and observe whether the accuracy edge over HardNet and OriNet vanishes on the same benchmarks.
Figures




read the original abstract
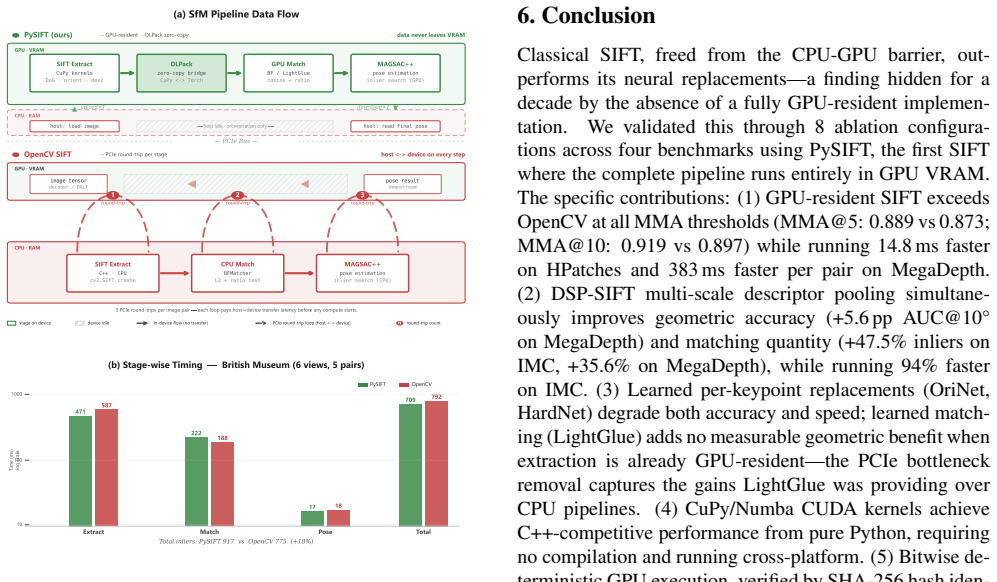
A widespread assumption in local feature research holds that classical handcrafted descriptors are accuracy-limited relics best replaced by learned alternatives. We show this is wrong. Through an 8-configuration ablation spanning four benchmarks (HPatches, ROxford5K, IMC Phototourism, MegaDepth), we demonstrate that classical SIFT with DSP multi-scale pooling outperforms neural descriptor and orientation replacements (HardNet, OriNet) on every accuracy metric--while running 2--18$\times$ faster--and that learned matchers (LightGlue) complement rather than supersede classical features. The conclusion reframes a decade of work: not "replace SIFT" but "compose with SIFT," classical extraction paired with learned matching only where geometric context demands it. This finding was invisible because no prior GPU SIFT kept the complete pipeline in VRAM or offered modularity for controlled classical-vs-learned ablations. We present PySIFT, the first fully GPU-resident SIFT, implemented in CuPy/Numba CUDA kernels with DLPack zero-copy handoff to downstream DL frameworks--submillisecond O(1) metadata swap regardless of keypoint count. On a laptop-grade NVIDIA RTX 3050 (4 GB VRAM), PySIFT achieves: (i) higher Mean Matching Accuracy (MMA) than OpenCV SIFT on HPatches, (ii) 383 ms faster per pair on high-resolution MegaDepth, (iii) higher geometric accuracy on cross-dataset benchmarks (+5.6 pp AUC@10${}^\circ$ on MegaDepth, more inliers on IMC Phototourism), and (iv) bitwise deterministic output--identical keypoints and descriptors across runs, with detection reproducing identically even across GPU architectures: a guarantee that learned extractors cannot match without significant performance sacrifice, and cannot achieve at all across GPU architectures due to cuDNN's architecture-dependent algorithm selection. PySIFT is open-source, requiring no C++ compilation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces PySIFT, the first fully GPU-resident deterministic SIFT implementation using CuPy/Numba CUDA kernels and DLPack for zero-copy integration with DL frameworks. It reports an 8-configuration ablation across HPatches, ROxford5K, IMC Phototourism, and MegaDepth showing that classical SIFT augmented with DSP multi-scale pooling outperforms neural descriptor/orientation replacements (HardNet, OriNet) on all accuracy metrics while running 2-18× faster; learned matchers (LightGlue) are shown to complement rather than replace classical features. The work emphasizes bitwise determinism across runs and GPU architectures, submillisecond metadata handling, and reframes local feature research as 'compose with SIFT' rather than replacement.
Significance. If the empirical claims hold after proper isolation of components, the result would be significant: it supplies a modular, reproducible, high-speed classical extractor suitable for end-to-end DL pipelines, directly challenges the decade-long replacement narrative with concrete cross-benchmark gains (+5.6 pp AUC@10° on MegaDepth), and provides an open-source artifact with stronger determinism guarantees than learned extractors. The GPU-resident design and DLPack handoff address practical integration barriers that prior CPU SIFT implementations could not.
major comments (2)
- [§4.2 and Table 2] §4.2 (Ablation study) and Table 2: the 8-configuration ablation includes DSP multi-scale pooling only in the classical-SIFT arm and provides no control row for otherwise-identical classical SIFT without DSP. Because the central claim attributes superiority to 'unmodified classical SIFT' rather than to the additional pooling choice, the absence of this isolation means the reported gains cannot be unambiguously credited to the classical baseline; this directly affects the reframing conclusion.
- [§3.1 and §5] §3.1 (Implementation) and §5 (Cross-GPU determinism): the bitwise-identical guarantee across GPU architectures is load-bearing for the reproducibility advantage over cuDNN-based methods, yet the manuscript does not specify which algorithmic choices (e.g., fixed-scale pyramid construction, exact floating-point reduction order) enforce this invariance; without that detail the determinism claim remains unverified.
minor comments (2)
- [Figure 3] Figure 3 caption: the legend does not explicitly map the eight ablation configurations to the plotted curves, forcing the reader to cross-reference Table 2.
- [Related Work] Related-work section: citation to the original Lowe SIFT paper is present but the discussion of prior GPU SIFT attempts (e.g., CUDA-SIFT) omits quantitative runtime comparisons on the same hardware.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major comment point by point below, with clear indications of planned revisions to improve the manuscript.
read point-by-point responses
-
Referee: [§4.2 and Table 2] §4.2 (Ablation study) and Table 2: the 8-configuration ablation includes DSP multi-scale pooling only in the classical-SIFT arm and provides no control row for otherwise-identical classical SIFT without DSP. Because the central claim attributes superiority to 'unmodified classical SIFT' rather than to the additional pooling choice, the absence of this isolation means the reported gains cannot be unambiguously credited to the classical baseline; this directly affects the reframing conclusion.
Authors: We agree that the current ablation lacks an explicit control for classical SIFT without DSP, which limits the ability to isolate the contribution of the base detector and descriptor. While the manuscript presents DSP multi-scale pooling as an enhancement within the classical arm (to enable fair comparison with learned components), adding this control will strengthen the evidence. In the revision we will insert a new configuration row in Table 2 and expand the discussion in §4.2 to report unmodified classical SIFT results. This will clarify the incremental effect of DSP while preserving the core comparison against neural replacements and supporting the reframing argument. revision: yes
-
Referee: [§3.1 and §5] §3.1 (Implementation) and §5 (Cross-GPU determinism): the bitwise-identical guarantee across GPU architectures is load-bearing for the reproducibility advantage over cuDNN-based methods, yet the manuscript does not specify which algorithmic choices (e.g., fixed-scale pyramid construction, exact floating-point reduction order) enforce this invariance; without that detail the determinism claim remains unverified.
Authors: We acknowledge that greater specificity on the mechanisms enforcing cross-GPU bitwise determinism is needed to make the claim fully verifiable. In the revised manuscript we will expand §3.1 to document the key implementation choices: fixed-scale Gaussian pyramid construction with deterministic bilinear interpolation, strict left-to-right reduction order in all CUDA kernels for keypoint localization and descriptor accumulation, and explicit avoidance of cuDNN or architecture-dependent primitives. We will also augment §5 with additional cross-architecture verification results (RTX 3050 vs. A100) demonstrating identical outputs. These additions will substantiate the reproducibility advantage without altering the empirical findings. revision: yes
Circularity Check
No circularity: empirical results on external benchmarks
full rationale
The paper reports direct empirical measurements of PySIFT against learned descriptors and matchers on independent external datasets (HPatches, ROxford5K, IMC Phototourism, MegaDepth). No equations, fitted parameters, or self-referential definitions are presented that would reduce the claimed superiority to an input by construction. The 8-configuration ablation and performance numbers are obtained from running the implementation on held-out benchmarks rather than from any internal derivation or renaming of prior results. Self-citations, if present in the full text, are not load-bearing for the central empirical claim.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption DSP multi-scale pooling is a standard, non-learned enhancement to classical SIFT
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
DSP multi-scale descriptor pooling... averages before normalization... first GPU implementation of DSP-SIFT
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
warp-private shared-memory regions and deterministic cross-warp reductions
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
David G. Lowe. Distinctive image features from scale- invariant keypoints.International Journal of Computer Vi- sion, 60(2):91–110, 2004. 1
work page 2004
-
[2]
Effect of parameter optimization on classical and learning-based im- age matching methods
Ufuk Efe, Kutalmis Gokalp Ince, and Aydin Alatan. Effect of parameter optimization on classical and learning-based im- age matching methods. InIEEE International Conference on Computer Vision Workshops (ICCVW), pages 2506–2513,
-
[3]
LightGlue: Local feature matching at light speed
Philipp Lindenberger, Paul-Erik Sarlin, and Marc Pollefeys. LightGlue: Local feature matching at light speed. InIEEE International Conference on Computer Vision (ICCV), pages 17627–17638, 2023. 1, 2, 4, 6
work page 2023
-
[4]
SuperGlue: Learning feature matching with graph neural networks
Paul-Erik Sarlin, Daniel DeTone, Tomasz Malisiewicz, and Andrew Rabinovich. SuperGlue: Learning feature matching with graph neural networks. InIEEE Conference on Com- puter Vision and Pattern Recognition (CVPR), pages 4938– 4947, 2020. 1
work page 2020
-
[5]
Working hard to know your neighbor’s mar- gins: Local descriptor learning loss
Anastasiya Mishchuk, Dmytro Mishkin, Filip Radenovi ´c, and Jiˇr´ı Matas. Working hard to know your neighbor’s mar- gins: Local descriptor learning loss. InAdvances in Neu- ral Information Processing Systems (NeurIPS), pages 4826– 4837, 2017. 1, 2
work page 2017
-
[6]
PopSift: A faithful SIFT implementation for real-time applications
Carsten Griwodz, Lilian Calvet, and P ˚al Halvorsen. PopSift: A faithful SIFT implementation for real-time applications. In ACM Multimedia Systems Conference (MMSys), pages 415– 420, 2018. 1, 2
work page 2018
-
[7]
Changchang Wu. SiftGPU: A GPU implementation of scale invariant feature transform.http://cs.unc.edu/ ˜ccwu/siftgpu, 2007. University of North Carolina at Chapel Hill. 1, 2
work page 2007
-
[8]
PyTorch Contributors. Reproducibility — PyTorch docu- mentation.https://pytorch.org/docs/stable/ notes/randomness.html, 2024. Documents opera- tions without deterministic GPU implementations. 1, 2, 7
work page 2024
-
[9]
Ryosuke Okuta, Yuya Unno, Daisuke Nishino, Shohei Hido, and Crissman Loomis. CuPy: A NumPy-compatible library for NVIDIA GPU calculations.NeurIPS Workshop on Ma- chine Learning Systems (LearningSys), 2017. 2
work page 2017
-
[10]
Numba: A LLVM-based Python JIT compiler
Siu Kwan Lam, Antoine Pitrou, and Stanley Seibert. Numba: A LLVM-based Python JIT compiler. InLLVM Compiler Infrastructure in HPC Workshop, pages 1–6, 2015. 2
work page 2015
-
[11]
Three things ev- eryone should know to improve object retrieval
Relja Arandjelovi ´c and Andrew Zisserman. Three things ev- eryone should know to improve object retrieval. InIEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 2911–2918, 2012. 2, 3, 5
work page 2012
-
[12]
Domain-size pooling in local descriptors: DSP-SIFT
Jingming Dong and Stefano Soatto. Domain-size pooling in local descriptors: DSP-SIFT. InIEEE Conference on Com- puter Vision and Pattern Recognition (CVPR), pages 5097– 5106, 2015. 2, 3, 5
work page 2015
-
[13]
SuperPoint: Self-supervised interest point detection and description
Daniel DeTone, Tomasz Malisiewicz, and Andrew Rabi- novich. SuperPoint: Self-supervised interest point detection and description. InIEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPR-W), pages 224– 236, 2018. 2, 5
work page 2018
-
[14]
HyNet: Learning lo- cal descriptor with hybrid similarity measure and triplet loss
Yurun Tian, Axel Barroso Laguna, Tony Ng, Vassileios Balntas, and Krystian Mikolajczyk. HyNet: Learning lo- cal descriptor with hybrid similarity measure and triplet loss. InAdvances in Neural Information Processing Systems (NeurIPS), volume 33, pages 7401–7412, 2020. 2
work page 2020
-
[15]
D. Bojani ´c, K. Bartol, T. Pribani ´c, T. Peharec, and J. Jeli ´c. On the comparison of classic and deep keypoint detector and descriptor methods. InIEEE International Symposium on Image and Signal Processing and Analysis (ISPA), pages 64– 69, 2020. 2, 7
work page 2020
-
[16]
DLPack: Open in memory ten- sor structure, 2021.https://github.com/dmlc/ dlpack
DLPack Contributors. DLPack: Open in memory ten- sor structure, 2021.https://github.com/dmlc/ dlpack. 4
work page 2021
-
[17]
MAGSAC++, a fast, reliable and accurate robust esti- mator
Daniel Barath, Jana Noskova, Maksym Ivashechkin, and Ji ˇr´ı Matas. MAGSAC++, a fast, reliable and accurate robust esti- mator. InIEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 1304–1312, 2020. 4
work page 2020
-
[18]
HPatches: A benchmark and evaluation of handcrafted and learned local descriptors
Vassileios Balntas, Karel Lenc, Andrea Vedaldi, and Krys- tian Mikolajczyk. HPatches: A benchmark and evaluation of handcrafted and learned local descriptors. InIEEE Confer- ence on Computer Vision and Pattern Recognition (CVPR), pages 3852–3861, 2017. 4
work page 2017
-
[19]
Revisiting Oxford and Paris: Large-scale image retrieval benchmarking
Filip Radenovi ´c, Ahmet Iscen, Giorgos Tolias, Yannis Avrithis, and Ond ˇrej Chum. Revisiting Oxford and Paris: Large-scale image retrieval benchmarking. InIEEE Confer- ence on Computer Vision and Pattern Recognition (CVPR), pages 5706–5715, 2018. 4, 5
work page 2018
-
[20]
Yuhe Jin, Dmytro Mishkin, Anastasiya Mishchuk, Ji ˇr´ı Matas, Pascal Fua, Kwang Moo Yi, and Eduard Trulls. Im- age matching across wide baselines: From paper to prac- tice.International Journal of Computer Vision, 129:517– 547, 2021. 4
work page 2021
-
[21]
MegaDepth: Learning single- view depth prediction from internet photos
Zhengqi Li and Noah Snavely. MegaDepth: Learning single- view depth prediction from internet photos. InIEEE Confer- ence on Computer Vision and Pattern Recognition (CVPR), pages 2041–2050, 2018. 4
work page 2041
-
[22]
Sch ¨onberger and Jan-Michael Frahm
Johannes L. Sch ¨onberger and Jan-Michael Frahm. Structure- from-motion revisited. InIEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 4104–4113,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.