Language Models Need Sleep: Learning to Self-Modify and Consolidate Memories
Pith reviewed 2026-06-28 10:53 UTC · model grok-4.3
The pith
Language models can consolidate short-term memories into long-term parameters and self-improve during a simulated sleep phase.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
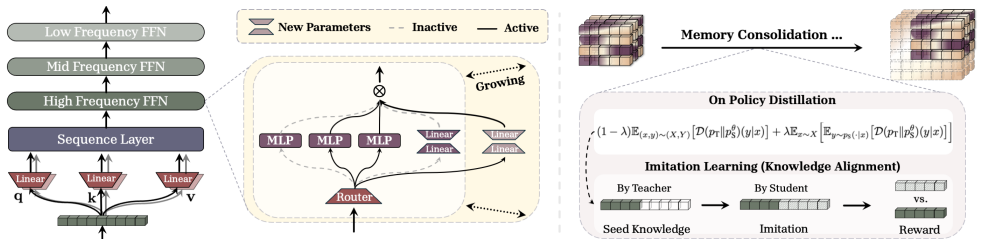
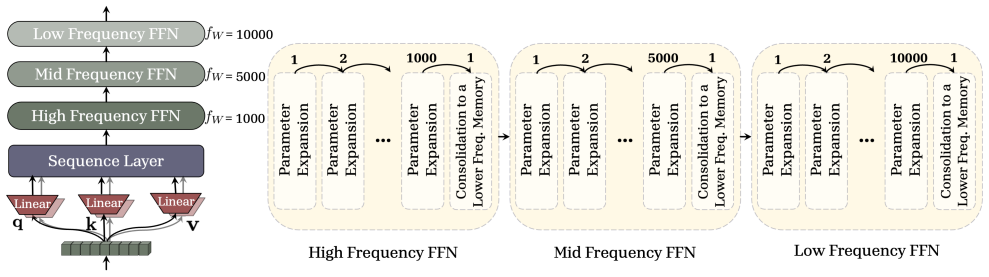
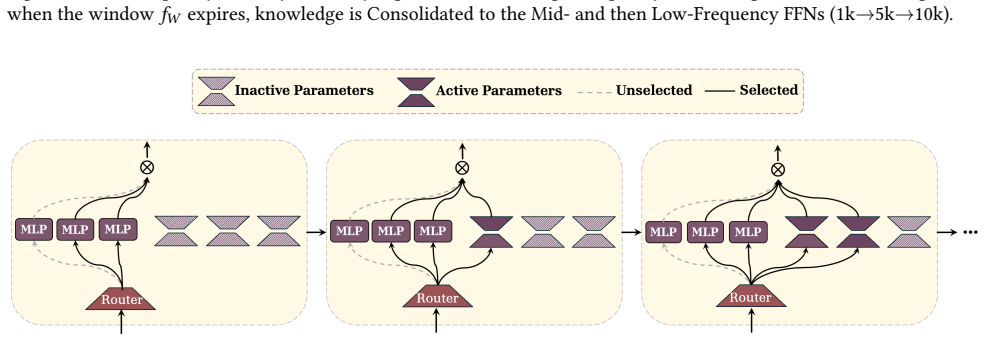
A sleep paradigm with two stages enables language models to continually learn: memory consolidation distills short-term memories from a smaller self into a larger network via generalized distillation (on-policy distillation combined with RL-based imitation), while a dreaming phase uses RL to create a curriculum of synthetic data for unsupervised rehearsal and capability refinement.
What carries the argument
The sleep paradigm, consisting of knowledge seeding via generalized distillation for upward memory consolidation and an RL-driven dreaming stage for self-generated curriculum improvement.
If this is right
- Models gain the ability to transfer temporal in-context knowledge into permanent parameter updates across extended sequences of tasks.
- Self-improvement occurs recursively as the dreaming stage generates new training signals without external labels.
- Knowledge incorporation tasks show reduced forgetting because short-term memories are stabilized through the consolidation stage.
- Few-shot generalization improves because the model rehearses capabilities on its own synthetic data.
- The process supports long-horizon continual learning by alternating between active use and sleep-based refinement.
Where Pith is reading between the lines
- Deployed models could periodically enter sleep phases to update themselves from ongoing interactions.
- The upward distillation step suggests a path for scaling model capacity while preserving prior knowledge.
- If the dreaming mechanism scales, it could reduce reliance on human-curated datasets for ongoing model development.
- The paradigm might extend to non-language domains where replay and self-generated curricula could stabilize learning.
Load-bearing premise
The described combination of on-policy distillation with RL imitation and RL-driven synthetic data generation will reliably consolidate memories and produce self-improvement in practice.
What would settle it
Running the proposed sleep stages on a continual learning benchmark and finding no measurable gain in long-term retention or task performance compared with standard fine-tuning or replay baselines.
Figures


read the original abstract
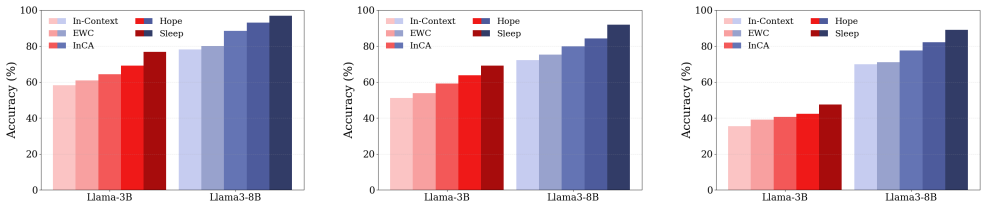
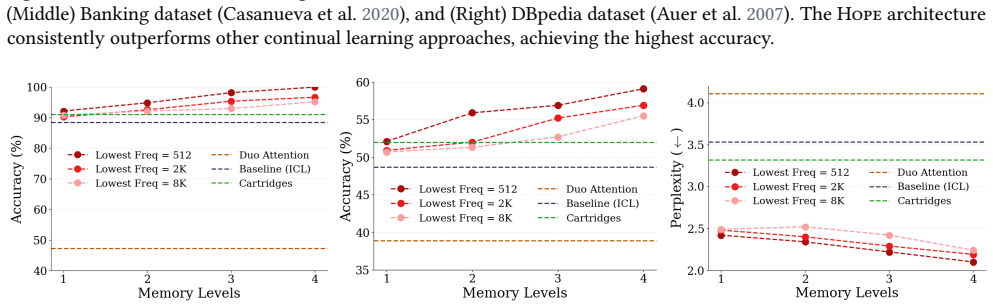
The past few decades have witnessed significant advances in the design of machine learning algorithms, from early studies on task-specific shallow models to more general deep Large Language Models (LLMs). Despite showing promising results in tasks that require instant prediction or in-context learning, existing models lack the ability to continually learn and effectively transfer their temporal in-context knowledge to their long-term parameters. Inspired by human learning process, we introduce a ''Sleep'' paradigm that allows the models to continually learn, distill their short-term fragile memories into stable long-term knowledge with replay, and recursively improve themselves with ''Dreaming'' process. In more detail, sleep consists of two stages: (1) Memory Consolidation: an upward distillation process, called Knowledge Seeding, where the memories of a smaller-self are distilled into a larger network to provide more capacity while preserving the knowledge. As a proof of concept, we present a new Generalized Distillation process for {Knowledge Seeding} (i.e., the combination of on-policy distillation with Reinforcement Learning (RL)-based imitation learning); (2) Dreaming: a self-improvement phase, where the model uses RL to generate a curriculum of synthetic data to rehearse new knowledge and refine existing capabilities without human supervision. Our experiments on long-horizon, continual learning, knowledge incorporation, and few-shot generalization tasks support the importance of the sleep stage.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a 'Sleep' paradigm for LLMs consisting of two stages: (1) Memory Consolidation via Knowledge Seeding, which uses a Generalized Distillation process (on-policy distillation combined with RL-based imitation learning) to distill short-term memories from a smaller model into a larger one; and (2) Dreaming, an RL-driven phase that generates a synthetic curriculum for rehearsal and self-improvement without human supervision. The approach is claimed to enable continual learning, knowledge consolidation, and recursive capability gains, with supporting experiments on long-horizon continual learning, knowledge incorporation, and few-shot generalization tasks.
Significance. If the central claims hold with concrete evidence, the work would address a key limitation of current LLMs (inability to consolidate in-context knowledge into parameters and achieve unsupervised self-improvement) by providing an explicit mechanism inspired by human sleep. The integration of distillation with RL for on-policy consolidation and synthetic data generation is a potentially useful direction, though the manuscript supplies no quantitative results, baselines, or reward details to assess whether the gains exceed standard continual-learning techniques.
major comments (2)
- [Abstract] Abstract: the claim that the Dreaming stage enables 'recursive self-improvement ... without human supervision' is load-bearing for the central contribution, yet the reward signal or objective used by the RL agent is never specified (no mention of intrinsic motivation, consistency loss, task metric, or other concrete formulation). Because RL outcomes are known to be highly sensitive to reward design, this omission prevents evaluation of whether the process is truly unsupervised or implicitly relies on external signals.
- [Abstract] Abstract: the manuscript states that 'our experiments ... support the importance of the sleep stage' but reports no quantitative results, error bars, baselines, or ablation studies. Without these, it is impossible to determine whether the observed gains on continual-learning tasks are attributable to the proposed stages or to standard fine-tuning effects.
minor comments (2)
- The term 'Generalized Distillation' is introduced without a clear positioning against prior distillation methods used in continual learning or knowledge distillation literature.
- Notation for the two stages (Knowledge Seeding, Dreaming) is introduced in the abstract but never formalized with equations or pseudocode, making the precise algorithmic flow difficult to reconstruct.
Simulated Author's Rebuttal
We thank the referee for their constructive comments. We agree that the current manuscript version requires additional detail on the RL reward formulation and quantitative experimental reporting. We will revise the paper to address both points.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that the Dreaming stage enables 'recursive self-improvement ... without human supervision' is load-bearing for the central contribution, yet the reward signal or objective used by the RL agent is never specified (no mention of intrinsic motivation, consistency loss, task metric, or other concrete formulation). Because RL outcomes are known to be highly sensitive to reward design, this omission prevents evaluation of whether the process is truly unsupervised or implicitly relies on external signals.
Authors: We agree the reward signal is not specified in the current manuscript. In the revised version we will add an explicit formulation of the RL objective in the Dreaming stage, including the precise reward function (a weighted combination of self-consistency with consolidated knowledge and an intrinsic novelty term), to allow readers to assess whether the process remains unsupervised. revision: yes
-
Referee: [Abstract] Abstract: the manuscript states that 'our experiments ... support the importance of the sleep stage' but reports no quantitative results, error bars, baselines, or ablation studies. Without these, it is impossible to determine whether the observed gains on continual-learning tasks are attributable to the proposed stages or to standard fine-tuning effects.
Authors: We agree that the manuscript currently contains no quantitative results, baselines, error bars, or ablations. The existing text presents the experimental tasks at a conceptual level only. We will revise the Experiments section to include quantitative metrics, standard continual-learning baselines, multiple-run error bars, and stage-specific ablations. revision: yes
Circularity Check
No derivation chain or equations present; conceptual proposal with experimental support
full rationale
The provided text (abstract and description) introduces a high-level 'Sleep' paradigm consisting of Knowledge Seeding via Generalized Distillation and an RL-based Dreaming stage for self-improvement. No mathematical derivations, equations, fitted parameters presented as predictions, or self-citations are visible. Claims rest on experimental results for continual learning tasks rather than any closed-form reduction to inputs. This is a standard case of a proposed framework without load-bearing circular steps.
Axiom & Free-Parameter Ledger
invented entities (3)
-
Sleep paradigm
no independent evidence
-
Knowledge Seeding
no independent evidence
-
Dreaming process
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Loss of recent memory after bilateral hippocampal lesions
William Beecher Scoville and Brenda Milner. “Loss of recent memory after bilateral hippocampal lesions”. In: Journal of neurology, neurosurgery, and psychiatry20.1 (1957), p. 11
1957
-
[2]
1987.url: https://people.idsia.ch/ ~juergen/diploma1987ocr.pdf
Jürgen Schmidhuber.Evolutionary Principles in Self-Referential Learning. 1987.url: https://people.idsia.ch/ ~juergen/diploma1987ocr.pdf
1987
-
[3]
Self-improving reactive agents based on reinforcement learning, planning and teaching
Long-Ji Lin. “Self-improving reactive agents based on reinforcement learning, planning and teaching”. In:Machine Learning8.3–4 (1992), pp. 293–321
1992
-
[4]
Learning to control fast-weight memories: An alternative to recurrent nets. Accepted for publication in
Juergen Schmidhuber. “Learning to control fast-weight memories: An alternative to recurrent nets. Accepted for publication in”. In:Neural Computation(1992)
1992
-
[5]
Why there are complementary learning systems in the hippocampus and neocortex: insights from the successes and failures of connectionist models of learning and memory
James L. McClelland, Bruce L. McNaughton, and Randall C. O’Reilly. “Why there are complementary learning systems in the hippocampus and neocortex: insights from the successes and failures of connectionist models of learning and memory”. In:Psychological Review102.3 (1995), pp. 419–457
1995
-
[6]
Retrograde amnesia and memory consolidation: a neurobiological perspective
Larry R Squire and Pablo Alvarez. “Retrograde amnesia and memory consolidation: a neurobiological perspective”. In:Current opinion in neurobiology5.2 (1995), pp. 169–177
1995
-
[7]
Synaptic tagging and long-term potentiation
Uwe Frey and Richard GM Morris. “Synaptic tagging and long-term potentiation”. In:Nature385.6616 (1997), pp. 533–536
1997
-
[8]
The plastic human brain cortex
Alvaro Pascual-Leone, Amir Amedi, Felipe Fregni, and Lotfi B Merabet. “The plastic human brain cortex”. In:Annu. Rev. Neurosci.28.1 (2005), pp. 377–401
2005
-
[9]
Sleep-dependent memory consolidation
Robert Stickgold. “Sleep-dependent memory consolidation”. In:Nature437.7063 (2005), pp. 1272–1278
2005
-
[10]
Reverse replay of behavioural sequences in hippocampal place cells during the awake state
David J Foster and Matthew A Wilson. “Reverse replay of behavioural sequences in hippocampal place cells during the awake state”. In:Nature440.7084 (2006), pp. 680–683
2006
-
[11]
Sleep function and synaptic homeostasis
Giulio Tononi and Chiara Cirelli. “Sleep function and synaptic homeostasis”. In:Sleep medicine reviews10.1 (2006), pp. 49–62
2006
-
[12]
Dbpedia: A nucleus for a web of open data
Sören Auer, Christian Bizer, Georgi Kobilarov, Jens Lehmann, Richard Cyganiak, and Zachary Ives. “Dbpedia: A nucleus for a web of open data”. In:international semantic web conference. Springer. 2007, pp. 722–735
2007
-
[13]
Coordinated memory replay in the visual cortex and hippocampus during sleep
Daoyun Ji and Matthew A Wilson. “Coordinated memory replay in the visual cortex and hippocampus during sleep”. In:Nature neuroscience10.1 (2007), pp. 100–107
2007
-
[14]
Plasticity in the developing brain: implications for rehabilitation
Michael V Johnston. “Plasticity in the developing brain: implications for rehabilitation”. In:Developmental disabilities research reviews15.2 (2009), pp. 94–101
2009
-
[15]
Replay of rule-learning related neural patterns in the prefrontal cortex during sleep
Adrien Peyrache, Mehdi Khamassi, Karim Benchenane, Sidney I Wiener, and Francesco P Battaglia. “Replay of rule-learning related neural patterns in the prefrontal cortex during sleep”. In:Nature neuroscience12.7 (2009), pp. 919–926
2009
-
[16]
Memory, sleep and dreaming: experiencing consolidation
Erin J Wamsley and Robert Stickgold. “Memory, sleep and dreaming: experiencing consolidation”. In:Sleep medicine clinics6.1 (2011), p. 97
2011
-
[17]
About sleep’s role in memory
Björn Rasch and Jan Born. “About sleep’s role in memory”. In:Physiological reviews(2013)
2013
-
[18]
The role of sleep in emotional brain function
Andrea N Goldstein and Matthew P Walker. “The role of sleep in emotional brain function”. In:Annual review of clinical psychology10.1 (2014), pp. 679–708
2014
-
[19]
Distilling the knowledge in a neural network
Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. “Distilling the knowledge in a neural network”. In:arXiv preprint arXiv:1503.02531(2015)
Pith/arXiv arXiv 2015
-
[20]
Human-level control through deep reinforcement learning
Volodymyr Mnih, Koray Kavukcuoglu, David Silver, Andrei A. Rusu, Joel Veness, Marc G. Bellemare, Alex Graves, Martin Riedmiller, Andreas K. Fidjeland, Georg Ostrovski, et al. “Human-level control through deep reinforcement learning”. In:Nature518.7540 (2015), pp. 529–533
2015
-
[21]
Memory consolidation
Larry R Squire, Lisa Genzel, John T Wixted, and Richard G Morris. “Memory consolidation”. In:Cold Spring Harbor perspectives in biology7.8 (2015), a021766
2015
-
[22]
Sequence-level knowledge distillation
Yoon Kim and Alexander M Rush. “Sequence-level knowledge distillation”. In:Proceedings of the 2016 conference on empirical methods in natural language processing. 2016, pp. 1317–1327
2016
-
[23]
What learning systems do intelligent agents need? Complementary learning systems theory updated
Dharshan Kumaran, Demis Hassabis, and James L. McClelland. “What learning systems do intelligent agents need? Complementary learning systems theory updated”. In:Trends in Cognitive Sciences20.7 (2016), pp. 512–534
2016
-
[24]
SQuAD: 100,000+ Questions for Machine Comprehension of Text
Pranav Rajpurkar, Jian Zhang, Konstantin Lopyrev, and Percy Liang. “SQuAD: 100,000+ Questions for Machine Comprehension of Text”. In:Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing. Ed. by Jian Su, Kevin Duh, and Xavier Carreras. Association for Computational Linguistics, 2016.url: https: //aclanthology.org/D16-1264/. 14
2016
-
[25]
Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks
Chelsea Finn, Pieter Abbeel, and Sergey Levine. “Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks”. In:Proceedings of the 34th International Conference on Machine Learning. Ed. by Doina Precup and Yee Whye Teh. Proceedings of Machine Learning Research. PMLR, 2017.url: https://proceedings.mlr.press/ v70/finn17a.html
2017
-
[26]
Neuroscience-inspired artificial intelligence
Demis Hassabis, Dharshan Kumaran, Christopher Summerfield, and Matthew Botvinick. “Neuroscience-inspired artificial intelligence”. In:Neuron95.2 (2017), pp. 245–258
2017
-
[27]
Overcoming catastrophic forgetting in neural networks
James Kirkpatrick, Razvan Pascanu, Neil Rabinowitz, Joel Veness, Guillaume Desjardins, Andrei A Rusu, Kieran Milan, John Quan, Tiago Ramalho, Agnieszka Grabska-Barwinska, et al. “Overcoming catastrophic forgetting in neural networks”. In:Proceedings of the national academy of sciences114.13 (2017), pp. 3521–3526
2017
-
[28]
REM sleep selectively prunes and maintains new synapses in development and learning
Wei Li, Lei Ma, Guang Yang, and Wen-Biao Gan. “REM sleep selectively prunes and maintains new synapses in development and learning”. In:Nature neuroscience20.3 (2017), pp. 427–437
2017
-
[29]
Attention is All you Need
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. “Attention is All you Need”. In:Advances in Neural Information Processing Systems. Ed. by I. Guyon, U. Von Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, and R. Garnett. Vol. 30. Cur- ran Associates, Inc., 2017.url: htt...
2017
-
[30]
Recurrent world models facilitate policy evolution
David Ha and Jürgen Schmidhuber. “Recurrent world models facilitate policy evolution”. In:Advances in Neural Information Processing Systems (NeurIPS). Vol. 31. 2018, pp. 2451–2463
2018
-
[31]
David Ha and Jürgen Schmidhuber. “World models”. In:arXiv preprint arXiv:1803.101222.3 (2018), p. 440
Pith/arXiv arXiv 2018
-
[32]
Measuring catastrophic forgetting in neural networks
Ronald Kemker, Marc McClure, Angelina Abitino, Tyler Hayes, and Christopher Kanan. “Measuring catastrophic forgetting in neural networks”. In:Proceedings of the AAAI conference on artificial intelligence. Vol. 32. 1. 2018
2018
-
[33]
An Evaluation Dataset for Intent Classification and Out-of-Scope Prediction
Stefan Larson, Anish Mahendran, Joseph J Peper, Christopher Clarke, Andrew Lee, Parker Hill, Jonathan K Kummerfeld, Kevin Leach, Michael A Laurenzano, Lingjia Tang, et al. “An Evaluation Dataset for Intent Classification and Out-of-Scope Prediction”. In:Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th Inte...
2019
-
[34]
Fast transformer decoding: One write-head is all you need
Noam Shazeer. “Fast transformer decoding: One write-head is all you need”. In:arXiv preprint arXiv:1911.02150 (2019)
Pith/arXiv arXiv 1911
-
[35]
Language models are few-shot learners
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. “Language models are few-shot learners”. In:Advances in neural information processing systems33 (2020), pp. 1877–1901
2020
-
[36]
Efficient Intent Detection with Dual Sentence Encoders
Inigo Casanueva, Tadas Temcinas, Daniela Gerz, Matthew Henderson, and Ivan Vulic. “Efficient Intent Detection with Dual Sentence Encoders”. In:ACL 2020(2020), p. 38
2020
-
[37]
Can sleep protect memories from catastrophic forgetting?
Oscar C. González, Yury Sokolov, Giri P. Krishnan, Jean Erik Delanois, and Maxim Bazhenov. “Can sleep protect memories from catastrophic forgetting?” In:eLife9 (2020), e51005
2020
-
[38]
Dream to control: Learning behaviors by latent imagination
Danijar Hafner, Timothy Lillicrap, Jimmy Ba, and Mohammad Norouzi. “Dream to control: Learning behaviors by latent imagination”. In:International Conference on Learning Representations (ICLR). 2020
2020
-
[39]
Transformers are rnns: Fast au- toregressive transformers with linear attention
Angelos Katharopoulos, Apoorv Vyas, Nikolaos Pappas, and François Fleuret. “Transformers are rnns: Fast au- toregressive transformers with linear attention”. In:International conference on machine learning. PMLR. 2020, pp. 5156–5165
2020
-
[40]
A dataset of information- seeking questions and answers anchored in research papers
Pradeep Dasigi, Kyle Lo, Iz Beltagy, Arman Cohan, Noah A Smith, and Matt Gardner. “A dataset of information- seeking questions and answers anchored in research papers”. In:arXiv preprint arXiv:2105.03011(2021)
arXiv 2021
-
[41]
Stepwise synaptic plasticity events drive the early phase of memory consolidation
Akihiro Goto, Ayaka Bota, Ken Miya, Jingbo Wang, Suzune Tsukamoto, Xinzhi Jiang, Daichi Hirai, Masanori Murayama, Tomoki Matsuda, Thomas J. McHugh, Takeharu Nagai, and Yasunori Hayashi. “Stepwise synaptic plasticity events drive the early phase of memory consolidation”. In:Science374.6569 (2021), pp. 857–863.doi: 10.1126/science.abj9195 . eprint: https://...
-
[42]
McGraw-Hill, 2021
Eric R Kandell, Jojhn D Koester, Sarah H Mack, and Steven Siegelbaum.Principles of neural science. McGraw-Hill, 2021
2021
-
[43]
The power of scale for parameter-efficient prompt tuning
Brian Lester, Rami Al-Rfou, and Noah Constant. “The power of scale for parameter-efficient prompt tuning”. In: arXiv preprint arXiv:2104.08691(2021)
Pith/arXiv arXiv 2021
-
[44]
Prefix-Tuning: Optimizing Continuous Prompts for Generation
Xiang Lisa Li and Percy Liang. “Prefix-Tuning: Optimizing Continuous Prompts for Generation”. In:Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). Ed. by Chengqing Zong, Fei Xia, Wenjie Li, and Roberto 15 Navigli. Onlin...
-
[45]
What learning algorithm is in-context learning? investigations with linear models
Ekin Akyürek, Dale Schuurmans, Jacob Andreas, Tengyu Ma, and Denny Zhou. “What learning algorithm is in-context learning? investigations with linear models”. In:arXiv preprint arXiv:2211.15661(2022)
Pith/arXiv arXiv 2022
-
[46]
Recurrent memory transformer
Aydar Bulatov, Yury Kuratov, and Mikhail Burtsev. “Recurrent memory transformer”. In:Advances in Neural Information Processing Systems35 (2022), pp. 11079–11091
2022
-
[47]
LoRA: Low-Rank Adaptation of Large Language Models
Edward J Hu, yelong shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. “LoRA: Low-Rank Adaptation of Large Language Models”. In:International Conference on Learning Representations. 2022.url:https://openreview.net/forum?id=nZeVKeeFYf9
2022
-
[48]
A modern self-referential weight matrix that learns to modify itself
Kazuki Irie, Imanol Schlag, Róbert Csordás, and Jürgen Schmidhuber. “A modern self-referential weight matrix that learns to modify itself”. In:International Conference on Machine Learning. PMLR. 2022.url: https://proceedings. mlr.press/v162/irie22b.html
2022
-
[49]
Sleep-like unsupervised replay reduces catastrophic forgetting in artificial neural networks
Timothy Tadros, Giri P. Krishnan, Ramyaa Ramyaa, and Maxim Bazhenov. “Sleep-like unsupervised replay reduces catastrophic forgetting in artificial neural networks”. In:Nature Communications13.1 (2022), p. 7742
2022
-
[50]
STaR: Bootstrapping Reasoning With Reasoning
Eric Zelikman, Yuhuai Wu, Jesse Mu, and Noah Goodman. “STaR: Bootstrapping Reasoning With Reasoning”. In: Advances in Neural Information Processing Systems. Ed. by S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho, and A. Oh. Curran Associates, Inc., 2022.url: https://proceedings.neurips.cc/paper_files/paper/2022/ file/639a9a172c044fbb64175b5fad42e9a...
2022
-
[51]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. “Gpt-4 technical report”. In:arXiv preprint arXiv:2303.08774(2023)
Pith/arXiv arXiv 2023
-
[52]
Gqa: Training generalized multi-query transformer models from multi-head checkpoints
Joshua Ainslie, James Lee-Thorp, Michiel De Jong, Yury Zemlyanskiy, Federico Lebrón, and Sumit Sanghai. “Gqa: Training generalized multi-query transformer models from multi-head checkpoints”. In:arXiv preprint arXiv:2305.13245(2023)
Pith/arXiv arXiv 2023
-
[53]
Adapting language models to compress contexts
Alexis Chevalier, Alexander Wettig, Anirudh Ajith, and Danqi Chen. “Adapting language models to compress contexts”. In:arXiv preprint arXiv:2305.14788(2023)
arXiv 2023
-
[54]
In-context autoencoder for context compression in a large language model
Tao Ge, Jing Hu, Lei Wang, Xun Wang, Si-Qing Chen, and Furu Wei. “In-context autoencoder for context compression in a large language model”. In:arXiv preprint arXiv:2307.06945(2023)
arXiv 2023
-
[55]
Mixture of cluster-conditional lora experts for vision-language instruction tuning
Yunhao Gou, Zhili Liu, Kai Chen, Lanqing Hong, Hang Xu, Aoxue Li, Dit-Yan Yeung, James T Kwok, and Yu Zhang. “Mixture of cluster-conditional lora experts for vision-language instruction tuning”. In:arXiv preprint arXiv:2312.12379(2023)
arXiv 2023
-
[56]
Mamba: Linear-time sequence modeling with selective state spaces
Albert Gu and Tri Dao. “Mamba: Linear-time sequence modeling with selective state spaces”. In:arXiv preprint arXiv:2312.00752(2023)
Pith/arXiv arXiv 2023
-
[57]
Lorahub: Efficient cross-task generalization via dynamic lora composition
Chengsong Huang, Qian Liu, Bill Yuchen Lin, Tianyu Pang, Chao Du, and Min Lin. “Lorahub: Efficient cross-task generalization via dynamic lora composition”. In:arXiv preprint arXiv:2307.13269(2023)
arXiv 2023
-
[58]
Llmlingua: Compressing prompts for accelerated inference of large language models
Huiqiang Jiang, Qianhui Wu, Chin-Yew Lin, Yuqing Yang, and Lili Qiu. “Llmlingua: Compressing prompts for accelerated inference of large language models”. In:arXiv preprint arXiv:2310.05736(2023)
arXiv 2023
-
[59]
Yucheng Li. “Unlocking context constraints of llms: Enhancing context efficiency of llms with self-information-based content filtering”. In:arXiv preprint arXiv:2304.12102(2023)
arXiv 2023
-
[60]
CodeGen: An Open Large Language Model for Code with Multi-Turn Program Synthesis
Erik Nijkamp, Bo Pang, Hiroaki Hayashi, Lifu Tu, Huan Wang, Yingbo Zhou, Silvio Savarese, and Caiming Xiong. “CodeGen: An Open Large Language Model for Code with Multi-Turn Program Synthesis”. In:The Eleventh Interna- tional Conference on Learning Representations. 2023.url:https://openreview.net/forum?id=iaYcJKpY2B_
2023
-
[61]
Memgpt: Towards llms as operating systems
Charles Packer, Sarah Wooders, Kevin Lin, Vivian Fang, Shishir G Patil, Ion Stoica, and Joseph E Gonzalez. “Memgpt: Towards llms as operating systems”. In:arXiv preprint arXiv:2310.08560(2023)
Pith/arXiv arXiv 2023
-
[62]
Are emergent abilities of large language models a mirage?
Rylan Schaeffer, Brando Miranda, and Sanmi Koyejo. “Are emergent abilities of large language models a mirage?” In:Advances in neural information processing systems36 (2023), pp. 55565–55581
2023
-
[63]
Visionllm: Large language model is also an open-ended decoder for vision-centric tasks
Wenhai Wang, Zhe Chen, Xiaokang Chen, Jiannan Wu, Xizhou Zhu, Gang Zeng, Ping Luo, Tong Lu, Jie Zhou, Yu Qiao, et al. “Visionllm: Large language model is also an open-ended decoder for vision-centric tasks”. In:Advances in Neural Information Processing Systems36 (2023), pp. 61501–61513
2023
-
[64]
H2o: Heavy-hitter oracle for efficient generative inference of large language models
Zhenyu Zhang, Ying Sheng, Tianyi Zhou, Tianlong Chen, Lianmin Zheng, Ruisi Cai, Zhao Song, Yuandong Tian, Christopher Ré, Clark Barrett, et al. “H2o: Heavy-hitter oracle for efficient generative inference of large language models”. In:Advances in Neural Information Processing Systems36 (2023), pp. 34661–34710. 16
2023
-
[65]
Marah Abdin, Jyoti Aneja, Harkirat Behl, Sébastien Bubeck, Ronen Eldan, Suriya Gunasekar, Michael Harrison, Rus- sell J Hewett, Mojan Javaheripi, Piero Kauffmann, et al. “Phi-4 technical report”. In:arXiv preprint arXiv:2412.08905 (2024)
Pith/arXiv arXiv 2024
-
[66]
On-Policy Distillation of Language Models: Learning from Self-Generated Mistakes
Rishabh Agarwal, Nino Vieillard, Yongchao Zhou, Piotr Stanczyk, Sabela Ramos Garea, Matthieu Geist, and Olivier Bachem. “On-Policy Distillation of Language Models: Learning from Self-Generated Mistakes”. In:The Twelfth International Conference on Learning Representations. 2024.url: https://openreview.net/forum?id= 3zKtaqxLhW
2024
-
[67]
The Surprising Effectiveness of Test-Time Training for Few-Shot Learning
Ekin Akyürek, Mehul Damani, Adam Zweiger, Linlu Qiu, Han Guo, Jyothish Pari, Yoon Kim, and Jacob Andreas. “The Surprising Effectiveness of Test-Time Training for Few-Shot Learning”. In:Forty-second International Conference on Machine Learning. 2024
2024
-
[68]
In-context language learning: Architectures and algorithms
Ekin Akyürek, Bailin Wang, Yoon Kim, and Jacob Andreas. “In-context language learning: Architectures and algorithms”. In:arXiv preprint arXiv:2401.12973(2024)
arXiv 2024
-
[69]
Simple linear attention language models balance the recall-throughput tradeoff
Simran Arora, Sabri Eyuboglu, Michael Zhang, Aman Timalsina, Silas Alberti, James Zou, Atri Rudra, and Christo- pher Re. “Simple linear attention language models balance the recall-throughput tradeoff”. In:Forty-first International Conference on Machine Learning. 2024.url:https://openreview.net/forum?id=e93ffDcpH3
2024
-
[70]
xLSTM: Extended Long Short-Term Memory
Maximilian Beck, Korbinian Pöppel, Markus Spanring, Andreas Auer, Oleksandra Prudnikova, Michael Kopp, Günter Klambauer, Johannes Brandstetter, and Sepp Hochreiter. “xLSTM: Extended Long Short-Term Memory”. In: arXiv preprint arXiv:2405.04517(2024)
arXiv 2024
-
[71]
Titans: Learning to memorize at test time
Ali Behrouz, Peilin Zhong, and Vahab Mirrokni. “Titans: Learning to memorize at test time”. In:arXiv preprint arXiv:2501.00663(2024)
Pith/arXiv arXiv 2024
-
[72]
Dated Data: Tracing Knowledge Cutoffs in Large Language Models
Jeffrey Cheng, Marc Marone, Orion Weller, Dawn Lawrie, Daniel Khashabi, and Benjamin Van Durme. “Dated Data: Tracing Knowledge Cutoffs in Large Language Models”. In:First Conference on Language Modeling. 2024.url: https://openreview.net/forum?id=wS7PxDjy6m
2024
-
[73]
Qingxiu Dong, Lei Li, Damai Dai, Ce Zheng, Jingyuan Ma, Rui Li, Heming Xia, Jingjing Xu, Zhiyong Wu, Baobao Chang, Xu Sun, Lei Li, and Zhifang Sui. “A Survey on In-context Learning”. In:Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. Ed. by Yaser Al-Onaizan, Mohit Bansal, and Yun-Nung Chen. Miami, Florida, USA: Asso...
-
[74]
The llama 3 herd of models
Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, Angela Fan, et al. “The llama 3 herd of models”. In:arXiv e-prints(2024), arXiv–2407
2024
-
[75]
RULER: What’s the Real Context Size of Your Long-Context Language Models?
Cheng-Ping Hsieh, Simeng Sun, Samuel Kriman, Shantanu Acharya, Dima Rekesh, Fei Jia, and Boris Ginsburg. “RULER: What’s the Real Context Size of Your Long-Context Language Models?” In:First Conference on Language Modeling. 2024.url:https://openreview.net/forum?id=kIoBbc76Sy
2024
-
[76]
Simple and Scalable Strategies to Continually Pre-train Large Language Models
Adam Ibrahim, Benjamin Thérien, Kshitij Gupta, Mats Leon Richter, Quentin Gregory Anthony, Eugene Belilovsky, Timothée Lesort, and Irina Rish. “Simple and Scalable Strategies to Continually Pre-train Large Language Models”. In:Transactions on Machine Learning Research(2024).issn: 2835-8856.url: https://openreview.net/forum?id= DimPeeCxKO
2024
-
[77]
Knowledge injection via prompt distillation
Kalle Kujanpää, Harri Valpola, and Alexander Ilin. “Knowledge injection via prompt distillation”. In:arXiv preprint arXiv:2412.14964(2024)
arXiv 2024
-
[78]
Babilong: Testing the limits of llms with long context reasoning-in-a-haystack
Yury Kuratov, Aydar Bulatov, Petr Anokhin, Ivan Rodkin, Dmitry Sorokin, Artyom Sorokin, and Mikhail Burtsev. “Babilong: Testing the limits of llms with long context reasoning-in-a-haystack”. In:Advances in Neural Information Processing Systems37 (2024), pp. 106519–106554
2024
-
[79]
Mixlora: Enhancing large language models fine-tuning with lora-based mixture of experts
Dengchun Li, Yingzi Ma, Naizheng Wang, Zhengmao Ye, Zhiyuan Cheng, Yinghao Tang, Yan Zhang, Lei Duan, Jie Zuo, Cal Yang, et al. “Mixlora: Enhancing large language models fine-tuning with lora-based mixture of experts”. In:arXiv preprint arXiv:2404.15159(2024)
arXiv 2024
-
[80]
Snapkv: Llm knows what you are looking for before generation
Yuhong Li, Yingbing Huang, Bowen Yang, Bharat Venkitesh, Acyr Locatelli, Hanchen Ye, Tianle Cai, Patrick Lewis, and Deming Chen. “Snapkv: Llm knows what you are looking for before generation”. In:Advances in Neural Information Processing Systems37 (2024), pp. 22947–22970
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.