Shopping Reasoning Bench: An Expert-Authored Benchmark for Multi-Turn Conversational Shopping Assistants
Pith reviewed 2026-06-27 09:39 UTC · model grok-4.3
The pith
Shopping Reasoning Bench shows current models reach only 57-77% pass rates on expert multi-turn shopping tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
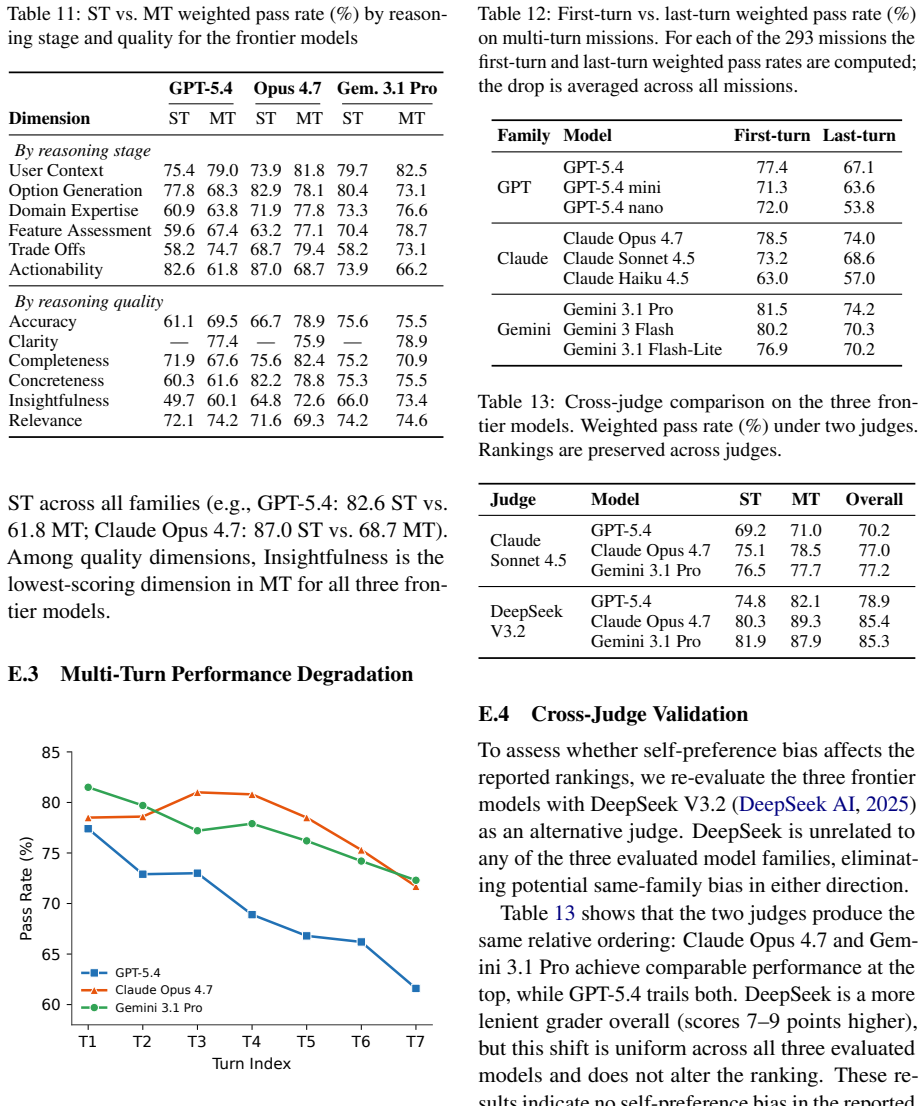
Shopping Reasoning Bench is an expert-authored benchmark of 525 missions with 10863 importance-weighted binary rubrics under a taxonomy of five reasoning categories. Evaluation across GPT, Claude, and Gemini models demonstrates pass rates between 57 and 77 percent, with multi-turn scores 13-29 points lower on optional criteria and 4-18 points degradation over conversation turns, showing that models provide basic assistance but fall short of expert-level performance.
What carries the argument
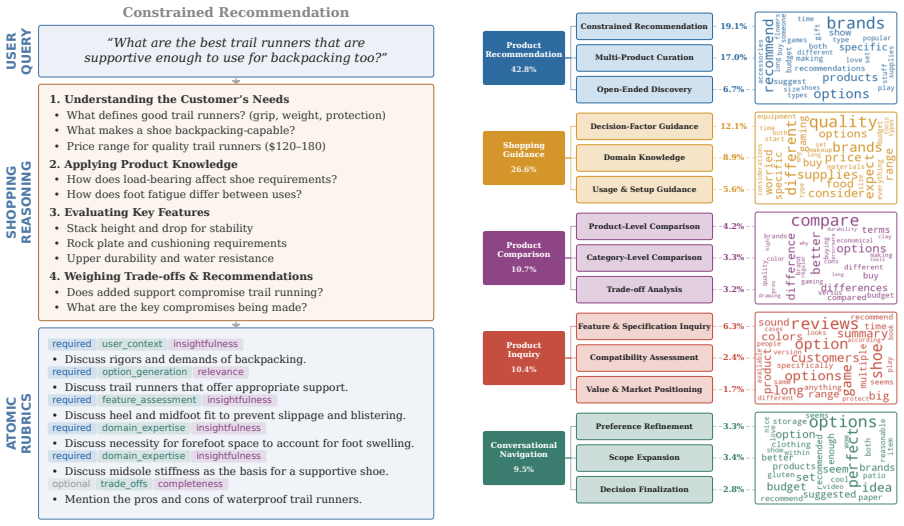
The Shopping Reasoning Bench, a collection of 525 missions and 10863 rubrics authored by retail experts and organized into five categories and fifteen subcategories for assessing shopping reasoning.
Load-bearing premise
The 10863 importance-weighted binary rubrics authored by retail domain experts accurately capture the open-ended multi-turn reasoning and domain expertise demanded by real shopping conversations.
What would settle it
Human raters scoring model responses on the same 525 missions using the same rubrics and comparing agreement rates to the reported model pass rates would test whether the expert criteria match real user judgments.
Figures


read the original abstract
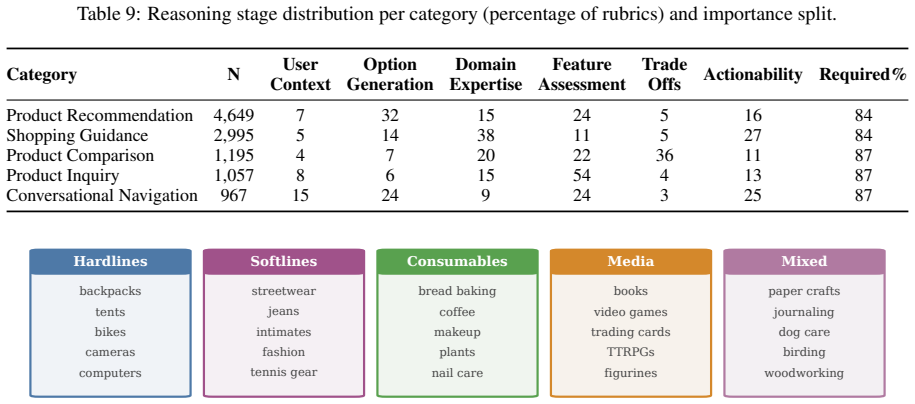
Conversational shopping assistants now serve hundreds of millions of customers, yet no existing benchmark jointly evaluates the open-ended multi-turn reasoning, domain expertise, and criterion-level quality that real shopping conversations demand. Shopping reasoning is unique among language model applications. Unlike factual question answering or verifiable code generation, it requires balancing subjective preferences, budget constraints, and cross-product trade-offs across multi-turn dialogue, capabilities absent from previous e-commerce and general-purpose benchmarks. We introduce the Shopping Reasoning Bench, an expert-authored benchmark of 525 missions (232 single-turn, 293 multi-turn) with 10863 importance-weighted binary rubrics authored by retail domain experts. These criteria are organized under a taxonomy of five reasoning categories and fifteen subcategories covering diverse demands such as preference refinement, trade-off analysis, and compatibility assessment. An evaluation of nine models across three families (GPT, Claude, Gemini) shows that pass rates reach only 57--77% overall. On multi-turn missions, all models score 13--29 points lower on optional above-and-beyond criteria than on required ones, and performance degrades 4--18 points as conversations progress. These gaps show that current models handle basic shopping assistance but fall short of expert-level advice, making Shopping Reasoning Bench a challenging testbed for future shopping assistant development.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Shopping Reasoning Bench, an expert-authored benchmark of 525 missions (232 single-turn, 293 multi-turn) with 10863 importance-weighted binary rubrics created by retail domain experts and organized under a five-category taxonomy with fifteen subcategories. It evaluates nine models across GPT, Claude, and Gemini families, reporting overall pass rates of 57-77%, 13-29 point drops on optional criteria for multi-turn missions, and 4-18 point degradation over conversation turns, concluding that current models manage basic shopping assistance but fall short of expert-level advice.
Significance. If the rubrics prove reliable, the benchmark would fill a gap by targeting open-ended multi-turn preference refinement, trade-off analysis, and compatibility assessment in shopping contexts, capabilities absent from prior e-commerce and general-purpose benchmarks. The expert authorship and scale are clear strengths that could make it a useful testbed for future model development.
major comments (2)
- [Abstract] Abstract: The central claim that 57-77% pass rates and the observed gaps (13-29 points on optional criteria; 4-18 point degradation) demonstrate models fall short of expert-level advice rests entirely on the 10863 rubrics accurately encoding required capabilities, yet the manuscript supplies no inter-expert agreement statistics, hold-out review of rubric coverage, or correlation with external signals such as purchase outcomes.
- [Abstract] Benchmark description (abstract and implied methods): The five-category taxonomy and rubric authoring process are presented without quantitative measures of consistency or sampling method for the 525 missions, leaving open whether systematic biases in rubric construction could produce the reported gaps even if models were closer to expert performance.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on rubric validation and potential biases in benchmark construction. We agree these points identify areas where the manuscript can be improved and will incorporate revisions to address them. Our point-by-point responses follow.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that 57-77% pass rates and the observed gaps (13-29 points on optional criteria; 4-18 point degradation) demonstrate models fall short of expert-level advice rests entirely on the 10863 rubrics accurately encoding required capabilities, yet the manuscript supplies no inter-expert agreement statistics, hold-out review of rubric coverage, or correlation with external signals such as purchase outcomes.
Authors: We agree that the strength of our claims depends on rubric quality and that the manuscript lacks formal inter-expert agreement statistics, hold-out coverage reviews, or external correlations such as purchase outcomes. The rubrics were created through iterative expert review by retail domain specialists, but no quantitative agreement metrics were computed during development. We will revise the abstract, methods, and limitations sections to describe the authoring process in greater detail, explicitly acknowledge the absence of these validation measures, and frame the performance gaps as indicative rather than conclusive evidence of shortfall pending further validation. We do not have access to purchase outcome data for correlation analysis. revision: yes
-
Referee: [Abstract] Benchmark description (abstract and implied methods): The five-category taxonomy and rubric authoring process are presented without quantitative measures of consistency or sampling method for the 525 missions, leaving open whether systematic biases in rubric construction could produce the reported gaps even if models were closer to expert performance.
Authors: We concur that the manuscript would benefit from more explicit details on taxonomy construction and mission sampling to allow assessment of potential biases. The taxonomy emerged from expert analysis of common shopping scenarios, and the 525 missions were curated by the same experts to span the five categories and fifteen subcategories with a mix of single- and multi-turn tasks. We will expand the methods section to include additional description of the taxonomy derivation, mission selection criteria, and any steps taken to ensure diversity. Quantitative consistency metrics were not collected, which we will note as a limitation. revision: yes
Circularity Check
No circularity: benchmark construction and model evaluation are independent of any self-referential derivation.
full rationale
The paper defines a new benchmark consisting of 525 missions and 10863 expert-authored rubrics, then reports direct empirical pass rates from evaluating nine external models on those fixed criteria. No equations, fitted parameters, predictions derived from the benchmark itself, or load-bearing self-citations appear in the derivation chain. The central claims rest on observable model outputs against the externally authored rubrics rather than reducing to quantities defined inside the paper by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Training Verifiers to Solve Math Word Problems
Training verifiers to solve math word prob- lems.arXiv preprint arXiv:2110.14168. Jacob Cohen. 1960. A coefficient of agreement for nominal scales.Educational and Psychological Mea- surement, 20(1):37–46. DeepSeek AI. 2025. DeepSeek-V3 technical report. arXiv preprint arXiv:2412.19437. 9 Google DeepMind. 2026. Gemini models documenta- tion. Accessed: 2026...
work page internal anchor Pith review Pith/arXiv arXiv 1960
-
[2]
SessionIntentBench: A multi-task inter- session intention-shift modeling benchmark for E- commerce customer behavior understanding.arXiv preprint arXiv:2507.20185. Shunyu Yao, Howard Chen, John Yang, and Karthik Narasimhan. 2022. WebShop: Towards scalable real- world web interaction with grounded language agents. InAdvances in Neural Information Processin...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[3]
good” or “appro- priate
Clear & Unambiguous.Each rubric uses precise language so that both human annota- tors and LLM judges reach the same pass/fail decision. Vague terms like “good” or “appro- priate” are replaced with specific, measurable criteria
-
[4]
A judge can determine pass/fail by examining the response text alone
Actionable.Rubrics describe observable re- sponse behaviors rather than internal model states. A judge can determine pass/fail by examining the response text alone
-
[5]
Comprehensive.The rubric set for a query covers the reasoning stages that the query’s reasoning category demands—for example, Product Comparison rubrics emphasize fea- ture assessment and trade-off reasoning, while Shopping Guidance rubrics emphasize do- main expertise and actionability
-
[6]
11 Table 7: Definitions of the six reasoning stages and six quality dimensions used to tag each rubric
Aligned with System Capabilities.Rubrics do not penalize responses for limitations out- side the model’s control (e.g., real-time inven- tory checks) and account for what a text-based assistant can reasonably provide. 11 Table 7: Definitions of the six reasoning stages and six quality dimensions used to tag each rubric. Percentages give the share of Shopp...
-
[7]
Balanced.Rubrics test both the presence of required information (recall) and the absence of harmful or irrelevant content (precision), avoiding over-emphasis on either direction
-
[8]
Rubrics avoid requir- ing a single “correct” phrasing or product or- dering unless specificity is essential
Fair.Multiple valid response strategies can satisfy the same rubric. Rubrics avoid requir- ing a single “correct” phrasing or product or- dering unless specificity is essential
-
[9]
Recommend a durable and affordable prod- uct
Atomic.Each rubric tests exactly one as- pect of the response. Compound criteria (e.g., “Recommend a durable and affordable prod- uct”) are split into separate rubrics. In addition, we enforce the following operational guidelines: • Rubrics are ordered by importance, with re- quired rubrics listed before optional ones. • Each rubric is written as a comple...
-
[10]
Query:A natural language shopping ques- tion or request that a customer might ask a conversational assistant
-
[11]
•importance : required (must be satis- fied) oroptional(bonus quality)
Rubric Dimensions:A list of atomic, binary criteria, each with: •rubric_text : A clear, verifiable state- ment of what the response should in- clude. •importance : required (must be satis- fied) oroptional(bonus quality). •scope : instance (specific to this query) orcluster(category-level). •reasoning_stage : The expert rea- soning phase the rubric tests ...
-
[12]
Mission Tags:Metadata including mission ID, name, type, objective, product family, and length
-
[13]
Re- sponse is helpful
Turn Sequence:An ordered list of customer utterances representing a realistic shopping conversation flow. 3.Per-Turn Annotations:For each turn: • Turn-level tags: reasoning_category, reasoning_subcategory, shopping_funnel_stage. • Rubric dimensions specific to the turn’s expected response, each carrying the four LLM-assigned tag dimensions: scope, importa...
1960
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.