PyMETA: A Benchmark Dataset for Hierarchical Student Code Error Classification with Python-Interpreter-Based Labels
Pith reviewed 2026-06-30 04:47 UTC · model grok-4.3
The pith
PyMETA supplies 48,646 Python student submissions with interpreter-derived single-error labels and a 97-sample multi-error subset under a three-level taxonomy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
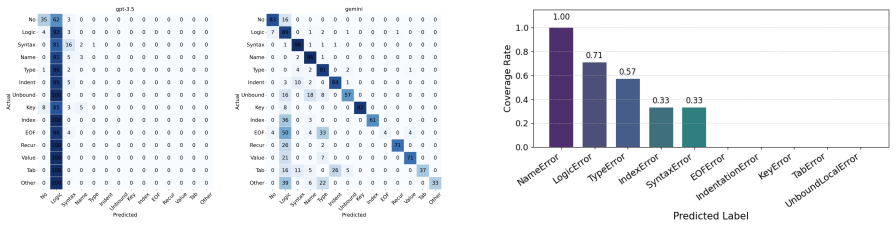
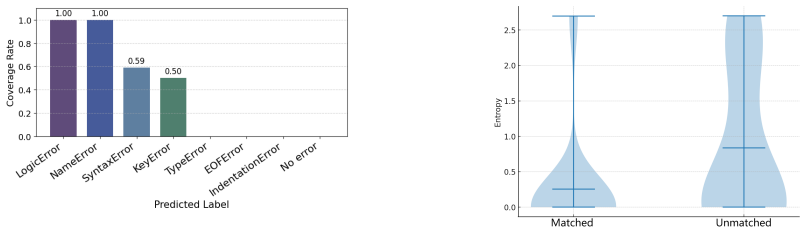
The paper establishes PyMETA as a benchmark containing 48,646 single-error labeled student submissions plus 97 multi-error expert samples, organized by a three-level hierarchy grounded in Python's official exception structure, and shows through direct model comparisons that finetuned smaller models outperform prompted LLMs while most LLMs over-predict Logic Error.
What carries the argument
Python-interpreter-based labeling that executes each student submission and records the first exception raised to assign a single-error label.
If this is right
- Finetuned models achieve higher macro F1 scores than prompted LLMs on the same hierarchical tasks.
- LLMs exhibit systematic over-classification of submissions as Logic Error, with measurable differences across model families.
- The same taxonomy supports both single-error and multi-error evaluation under a contains criterion.
- Performance gaps appear consistently across the 14 fine-grained error types.
Where Pith is reading between the lines
- The dataset could support development of feedback systems that point students to the most specific error category first.
- Observed LLM biases suggest targeted fine-tuning on underrepresented error types might reduce over-prediction of Logic Error.
- The hierarchical structure makes it possible to train models that first detect presence of error before naming its type.
Load-bearing premise
Running the code in the interpreter produces labels that match the actual primary error present in the student's submission even when other undetected errors exist.
What would settle it
Expert manual review of a random subset of the 48,646 samples that finds frequent mismatches between the interpreter label and the dominant error type visible in the code.
Figures








read the original abstract
With the advancement of Large Language Models (LLMs), code error detection has extended beyond traditional IDE diagnostics to context-sensitive debugging in educational scenarios. However, existing approaches lack large-scale datasets, multi-error analysis, and unified error taxonomies. To address this, we introduce PyMETA, a large-scale Python code error classification dataset of 48,646 student submissions, with single-error labels for all samples and a diagnostic subset of 97 expert-annotated multi-error samples. The dataset uses a three-level hierarchical taxonomy, from a binary error/no-error split down to 14 fine-grained error types grounded in Python's official exception hierarchy. We evaluate multi-level classification tasks on two finetuned models and four LLMs with prompting, comparing their classification performance and runtime cost. For multi-error prompting, the best model, Gemini 2.5 Pro, achieves 81.8% macro F1 under the "contains" criterion. We observe that: 1) prompted LLMs still underperform finetuned smaller models; 2) models exhibit significant disparities across error types; 3) most LLMs over-classify code as Logic Error, with GPT-3.5 showing the highest Logic Error Overprediction Rate and Gemini 2.5 Pro the lowest. Our work establishes a data foundation and provides insights for LLM-based code error research.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces PyMETA, a dataset of 48,646 Python student submissions with single-error labels generated via Python interpreter execution and a three-level hierarchical taxonomy (binary error/no-error down to 14 fine-grained types based on Python's official exception hierarchy). It includes a 97-sample expert-annotated multi-error diagnostic subset and reports evaluations of two finetuned models plus four LLMs on multi-level classification tasks, including observations on performance disparities and Logic Error overprediction.
Significance. If the interpreter-derived labels prove reliable at scale, the dataset would supply a substantial, reproducible resource for code error classification benchmarks in educational settings, with its hierarchical structure and partial multi-error coverage addressing gaps in prior work. The interpreter-based approach and reported model comparisons (e.g., Gemini 2.5 Pro at 81.8% macro F1 under 'contains' criterion) provide concrete starting points for future LLM-based debugging research.
major comments (2)
- [Dataset Construction] Dataset Construction section: The central claim that the 48,646 samples supply reliably labeled single-error data rests on Python interpreter output identifying the dominant error. No large-scale expert validation, agreement metrics, or systematic analysis of multi-error mislabeling is reported for this set (only the 97-sample subset receives expert annotation), leaving the label quality assumption untested at the scale that defines the dataset's utility as a benchmark.
- [Experiments] Experiments section (multi-error evaluation): The 97-sample multi-error subset is used to support claims about 'contains' criterion performance, but its small size limits statistical power and generalizability of conclusions about model handling of multiple errors relative to the 48k single-error scale.
minor comments (2)
- [Abstract] Abstract: The description of label generation could explicitly state the single-error assumption and its potential failure modes to better frame the contribution.
- The paper would benefit from a table summarizing the 14 fine-grained error types with their Python exception mappings for quick reference.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address the two major comments point by point below, acknowledging the limitations raised while clarifying the design choices in our labeling and evaluation approach.
read point-by-point responses
-
Referee: [Dataset Construction] Dataset Construction section: The central claim that the 48,646 samples supply reliably labeled single-error data rests on Python interpreter output identifying the dominant error. No large-scale expert validation, agreement metrics, or systematic analysis of multi-error mislabeling is reported for this set (only the 97-sample subset receives expert annotation), leaving the label quality assumption untested at the scale that defines the dataset's utility as a benchmark.
Authors: The 48,646 labels are produced by executing each submission in the Python interpreter and recording the first exception raised, which supplies a deterministic, reproducible signal for the error that actually occurs. This method was chosen precisely to scale labeling without relying on subjective human judgment for the full set. We agree that the absence of large-scale expert validation leaves open the possibility that some samples contain multiple errors where only the dominant one is recorded. The 97-sample expert-annotated subset was created specifically to examine multi-error cases separately. In the revision we will add an explicit limitations paragraph discussing the interpreter-based labeling assumptions and the trade-off between scale and expert verification. revision: partial
-
Referee: [Experiments] Experiments section (multi-error evaluation): The 97-sample multi-error subset is used to support claims about 'contains' criterion performance, but its small size limits statistical power and generalizability of conclusions about model handling of multiple errors relative to the 48k single-error scale.
Authors: The 97-sample subset is intentionally small because expert multi-error annotation is resource-intensive; it functions as a diagnostic probe rather than a statistically powered test set. We already qualify the multi-error results with this scale in mind and do not claim they generalize to the full 48k distribution. In the revision we will strengthen the caveats around statistical power and explicitly frame the multi-error results as preliminary, while noting expansion of this subset as future work. revision: partial
Circularity Check
No circularity: dataset construction and evaluations are self-contained
full rationale
The paper introduces a new dataset (PyMETA) whose single-error labels are produced by direct execution against the external Python interpreter and official exception hierarchy; the 97-sample expert subset is used only for diagnostics, not to derive or fit the main labels. No equations, fitted parameters, predictions, or self-citations appear in the derivation chain. Model evaluations are standard benchmarking against external LLMs and finetuned baselines. All load-bearing steps (label generation, taxonomy definition, performance reporting) rest on independent external mechanisms rather than reducing to the paper's own inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Locate the specific programming problem on the online judge using the Question ID
-
[2]
Paste the student’s answer into the judge, ob- serve the first error, and increment the corre- sponding error-type count in the annotation spreadsheet
-
[3]
Fixonlythat single error (referring to the ex- pected answer as a reference), and verify that re-execution no longer produces the same er- ror at the same location
-
[4]
Repeat steps 2–3 until no explicit runtime or compile-time errors remain
-
[5]
A.6 Use of AI Assistants AI assistants were used solely for translation and grammar checking during the preparation of this manuscript
If the problem includes test cases, run them: failure to pass all test cases indicates a Logic Error; passing all test cases marks the sample as complete. A.6 Use of AI Assistants AI assistants were used solely for translation and grammar checking during the preparation of this manuscript. No AI-generated content was included in the scientific contributio...
2023
-
[6]
A.8 Model Performance Evaluation Metrics and Prompt Templates We evaluate model performance usingprecision, recall, andF1-scoreunder two modes:Contains andTop-1
are both Python-based works built on the AOJ ITP1 44 introductory problems. A.8 Model Performance Evaluation Metrics and Prompt Templates We evaluate model performance usingprecision, recall, andF1-scoreunder two modes:Contains andTop-1. Precision (Contains).For each class c that ap- pears in the gold labels: TPc =|{i|c∈y gold i andc∈y pred i }|,(4) FPc =...
-
[7]
First, see the student's code to check if the code has explicit errors (Syntax Error, Name Error, Type Error, Indentation Error, UnboundLocal Error, Key Error, Index Error, EOF Error, Value Error, Tab Error)
-
[8]
If there is no explicit errors, see the question description, the student's code, and compare with the expected answer to check the logic of code
-
[9]
0 No error
If the logic is wrong, there is an logic error; Else, there is no error. 16 17Your goal is to classify the error into a predefined taxonomy of Python error types. Please output only the label number and label name, separated by a space, e.g., "0 No error" or "3 NameError". 18 19## Definition of Error Type Categories (Label number and names) 200: No error ...
-
[10]
Examine the student's code for explicit errors (Syntax Error, Name Error, Type Error , Indentation Error, Unbound Local Error, Key Error, Index Error, EOF Error, Value Error, Tab Error)
-
[11]
If no explicit error is found, compare the student's code with the expected answer to check the logic
-
[12]
Write a function that returns the square of a number
If the logic is incorrect, classify as Logic Error. Otherwise, classify as No Error. 16Use this reasoning process internally to justify the final prediction. 17 18--- 19#Definition of Error Type Categories (Label numbers and names) 200: No Error: The code runs successfully with no explicit or Logic Error. 211: Logic Error: The code has no explicit error b...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.