DECK: A Consistency x Confidence Taxonomy of LLM Hallucinations
Pith reviewed 2026-06-28 14:54 UTC · model grok-4.3
The pith
The DECK taxonomy partitions LLM hallucinations into four regimes along consistency and confidence axes, each tied to specific uncertainty scorers, while exposing a universal blind spot for confident repeatable fabrications.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
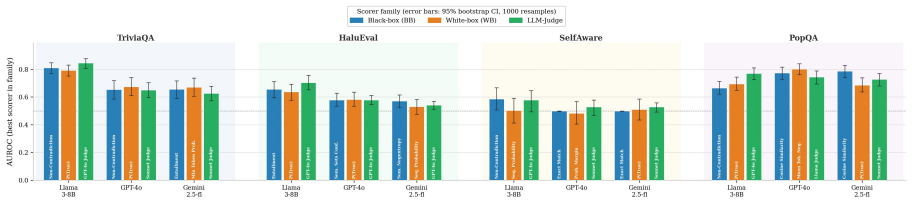
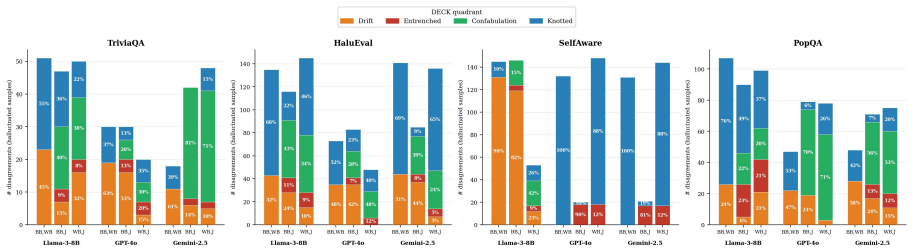
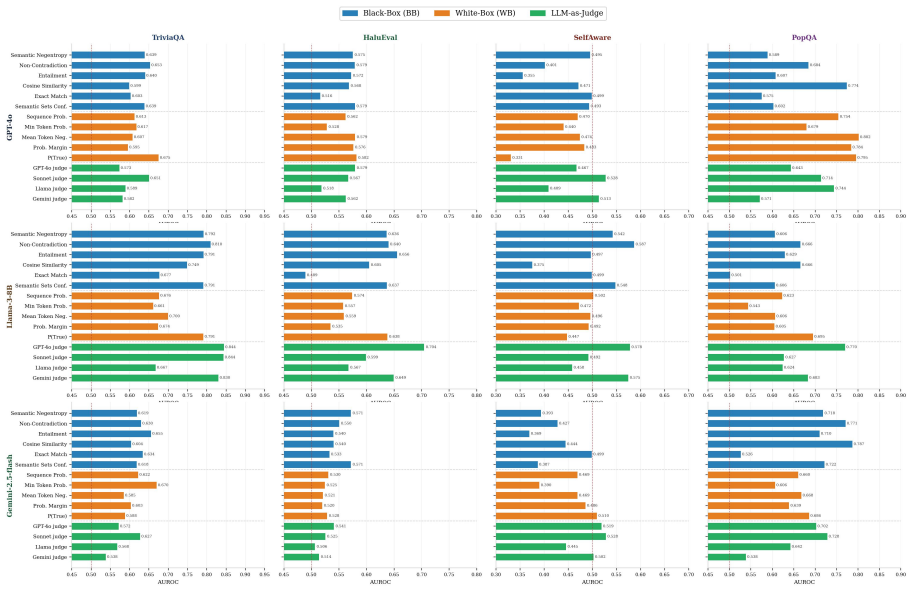
The DECK taxonomy is a 2x2 partition along inter-sample consistency and token-level confidence into four behavioural regimes (Drift, Entrenched, Confabulation, Knotted), each mapping to a specific scorer family that can detect it, with black-box consistency scorers having signal in Drift and Confabulation, white-box token-probability scorers having signal in Knotted and Confabulation, and only an LLM-as-a-Judge with independent pretraining able to detect Entrenched; cell membership is operationalised by a Youden's J optimal split on each scorer axis, external labels align with predicted cells, and all output-level UQ families collapse on knowledge-gap inputs that produce confident repeatable
What carries the argument
The DECK 2x2 taxonomy that classifies hallucinations by their detectability signature using inter-sample consistency and token-level confidence.
If this is right
- Black-box consistency scorers detect errors in the Drift and Confabulation regimes.
- White-box token-probability scorers detect errors in the Knotted and Confabulation regimes.
- Only an independent LLM-as-Judge reaches the Entrenched regime.
- All output-level uncertainty quantification methods fail on knowledge-gap inputs that elicit confident repeatable fabrications.
- A linear probe on hidden states also collapses to chance on those same inputs.
Where Pith is reading between the lines
- The blind spot may require methods that look beyond output-level signals or single-model activations.
- Hybrid scorers that combine consistency and token-probability signals could cover three of the four regimes.
- The taxonomy could guide selection of detection methods for specific application domains where one regime dominates.
Load-bearing premise
That the four cells defined by optimal splits on consistency and confidence axes capture genuinely distinct detectability regimes rather than merely reflecting the scorers chosen to draw the splits.
What would settle it
External labels from SelfAware, HaluEval, or PopQA fail to land preferentially in the predicted DECK cells when measured across multiple models, or scorer-pair disagreements show no alignment with the taxonomy partition.
Figures
read the original abstract
Existing hallucination taxonomies classify LLM errors by what is wrong with the output -- memorised misconceptions, reasoning failures, fluent fabrications. These taxonomies are useful for diagnosis but cannot answer a different question: which uncertainty scorer would have caught this error? We propose a complementary taxonomy that classifies errors by their detectability signature -- the signal a scorer family would read. The DECK taxonomy is a 2x2 partition along inter-sample consistency and token-level confidence into four behavioural regimes (Drift, Entrenched, Confabulation, Knotted), each mapping to a specific scorer family (or families) that can detect it: black-box consistency scorers have signal in D and C, white-box token-probability scorers have signal in K and C, and only an LLM-as-a-Judge with independent pretraining can detect E. Cell membership is operationalised by a Youden's J optimal split on each scorer axis. Across three models and four datasets we validate the taxonomy two ways: by analysing scorer-pair disagreement, and by checking that external labels (SelfAware unanswerable, HaluEval adversarial, PopQA entity popularity) land in the predicted DECK cells, with model-scale and content-specific secondary-cell refinements. We further identify a universal blind spot of output-level UQ: on knowledge-gap inputs where the generator emits confident, repeatable fabrications, every output-level family collapses by construction. A linear probe on Llama-3-8B's hidden states also collapses to chance, giving preliminary evidence that the failure may persist at the activation level; richer internal-state methods (UQ heads, information-theoretic estimators) remain to be tested.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes the DECK taxonomy, a 2x2 partition of LLM hallucinations along axes of inter-sample consistency and token-level confidence, yielding four regimes (Drift, Entrenched, Confabulation, Knotted) each associated with specific uncertainty scorer families. It operationalizes cell membership via Youden's J optimal splits, validates the taxonomy on three models and four datasets via scorer-pair disagreement patterns and placement of external labels (SelfAware unanswerable, HaluEval adversarial, PopQA popularity), and reports a universal blind spot for output-level UQ on knowledge-gap inputs producing confident repeatable fabrications, with preliminary evidence from a linear probe on Llama-3-8B hidden states.
Significance. If the 2x2 structure supplies signal beyond the underlying continuous scores, the taxonomy offers a useful organizing framework for matching hallucination types to detection methods and highlights a concrete limitation of current output-level UQ approaches. The identification of the blind spot and the attempt to ground the taxonomy in external labels are constructive contributions.
major comments (3)
- [Abstract] Abstract and validation description: Cell membership is defined by Youden's J splits on the same consistency and confidence axes used to assign regimes to scorer families, after which external labels are checked for placement in the predicted cells. This setup risks circularity; any label that correlates with consistency or confidence will appear to validate the taxonomy by construction, and the manuscript does not demonstrate that the discrete 2x2 partition adds explanatory power over the two continuous scores alone.
- [Abstract] Abstract: The scorer-pair disagreement analysis is presented as validation, yet disagreement is the expected statistical consequence of correlation between the two axes; this does not independently establish that the taxonomy supplies new signal.
- [Abstract] Abstract: The universal blind-spot claim (every output-level family collapses on knowledge-gap inputs emitting confident, repeatable fabrications) is load-bearing for the paper's contribution; the reported linear-probe result collapsing to chance requires the precise experimental setup, dataset construction, and baseline comparisons to be assessed for whether it supports the stronger claim that the failure may persist at the activation level.
minor comments (1)
- The mapping of regimes to scorer families (black-box consistency in D and C, white-box in K and C, LLM-as-Judge in E) should be stated with explicit citations to the relevant prior work on each family.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the DECK taxonomy. We address each major comment below, acknowledging valid concerns about validation design and evidence strength while providing the strongest honest defense of the manuscript's contributions.
read point-by-point responses
-
Referee: [Abstract] Abstract and validation description: Cell membership is defined by Youden's J optimal splits on the same consistency and confidence axes used to assign regimes to scorer families, after which external labels are checked for placement in the predicted cells. This setup risks circularity; any label that correlates with consistency or confidence will appear to validate the taxonomy by construction, and the manuscript does not demonstrate that the discrete 2x2 partition adds explanatory power over the two continuous scores alone.
Authors: The Youden's J splits operationalize the continuous axes into regimes to test alignment with scorer-family predictions, rather than to claim the taxonomy is independent of the underlying scores. External labels serve as an out-of-sample check on whether known hallucination types fall into the expected detectability regimes. We agree the current presentation does not explicitly quantify incremental value of the discrete partition. In revision we will add a direct comparison (e.g., logistic regression or mutual information) showing whether quadrant membership improves label prediction beyond the raw consistency and confidence scores. revision: partial
-
Referee: [Abstract] Abstract: The scorer-pair disagreement analysis is presented as validation, yet disagreement is the expected statistical consequence of correlation between the two axes; this does not independently establish that the taxonomy supplies new signal.
Authors: Disagreement is indeed expected under imperfect correlation; the analysis is not offered as proof of statistical independence. Its purpose is to demonstrate that the observed disagreement patterns are consistent with the taxonomy's mapping of regimes to specific scorer families (black-box consistency vs. white-box token probability). We will revise the text to clarify this interpretive goal and supplement with quantitative measures of regime-specific signal. revision: partial
-
Referee: [Abstract] Abstract: The universal blind-spot claim (every output-level family collapses on knowledge-gap inputs emitting confident, repeatable fabrications) is load-bearing for the paper's contribution; the reported linear-probe result collapsing to chance requires the precise experimental setup, dataset construction, and baseline comparisons to be assessed for whether it supports the stronger claim that the failure may persist at the activation level.
Authors: The linear-probe result is presented as preliminary evidence only. We agree that full experimental details are necessary for readers to evaluate the strength of the claim. In the revised manuscript we will expand the methods and add an appendix containing the exact dataset construction, probe architecture, training procedure, baseline comparisons, and statistical results. revision: yes
Circularity Check
No significant circularity; taxonomy is a definitional classification with external validation
full rationale
The DECK taxonomy is explicitly constructed as a 2x2 partition on the two input axes (consistency, confidence) with cell membership set via Youden's J splits and regimes mapped to scorer families by the scorers' known detection mechanisms; the blind spot is stated as holding 'by construction' without being presented as a derived result. Validation proceeds by checking alignment of independent external labels (SelfAware, HaluEval, PopQA) and scorer-pair disagreement patterns against the pre-defined cells. No equation or claim reduces a 'prediction' to a fitted parameter on the same data, no self-citation chain bears the central premise, and the external labels supply grounding outside the scorer definitions themselves. The derivation therefore remains self-contained as an organizational framework rather than a tautological fit.
Axiom & Free-Parameter Ledger
free parameters (1)
- Youden's J optimal split thresholds
axioms (1)
- domain assumption Youden's J statistic yields appropriate classification thresholds for the consistency and confidence axes
invented entities (1)
-
DECK regimes (Drift, Entrenched, Confabulation, Knotted)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Transactions on Machine Learning Research , year=
Uncertainty Quantification for Language Models: A Suite of Black-Box, White-Box, LLM Judge, and Ensemble Scorers , author=. Transactions on Machine Learning Research , year=
-
[2]
Journal of Machine Learning Research , volume=
Uqlm: A python package for uncertainty quantification in large language models , author=. Journal of Machine Learning Research , volume=. 2026 , url =
2026
-
[3]
Can Large Language Models Be an Alternative to Human Evaluations?
Chiang, Cheng-Han and Lee, Hung-yi. Can Large Language Models Be an Alternative to Human Evaluations?. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2023. doi:10.18653/v1/2023.acl-long.870
-
[4]
Nature , volume=
Detecting hallucinations in large language models using semantic entropy , author=. Nature , volume=. 2024 , url=
2024
-
[5]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
Factuality of large language models: A survey , author=. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=. 2024 , url=
2024
-
[6]
ACM Computing Surveys , volume=
Survey of Hallucination in Natural Language Generation , author=. ACM Computing Surveys , volume=. 2023 , publisher=
2023
-
[8]
International Conference on Learning Representations , year=
Semantic Uncertainty: Linguistic Invariances for Uncertainty Estimation in Natural Language Generation , author=. International Conference on Learning Representations , year=
-
[9]
International Conference on Learning Representations , year=
Uncertainty Estimation in Autoregressive Structured Prediction , author=. International Conference on Learning Representations , year=
-
[10]
Manakul, Potsawee and Liusie, Adian and Gales, Mark J. F. , booktitle=. 2023 , url=
2023
-
[11]
Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics , pages=
On Faithfulness and Factuality in Abstractive Summarization , author=. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics , pages=
-
[12]
2023 , url=
Min, Sewon and Krishna, Kalpesh and Lyu, Xinxi and Lewis, Mike and Yih, Wen-tau and Koh, Pang Wei and Iyyer, Mohit and Zettlemoyer, Luke and Hajishirzi, Hannaneh , booktitle=. 2023 , url=
2023
-
[13]
arXiv preprint arXiv:2405.13845 , year=
Semantic Density: Uncertainty Quantification for Large Language Models through Confidence Measurement in Semantic Space , author=. arXiv preprint arXiv:2405.13845 , year=
-
[14]
Advances in neural information processing systems , volume=
Semantic density: Uncertainty quantification for large language models through confidence measurement in semantic space , author=. Advances in neural information processing systems , volume=. 2024 , url=
2024
-
[15]
Xiong, Miao and Hu, Zhiyuan and Lu, Xinyang and Li, Yifei and Fu, Jie and He, Junxian and Hooi, Bryan , booktitle=. Can
-
[16]
International Conference on Learning Representations , volume=
Can llms express their uncertainty? an empirical evaluation of confidence elicitation in llms , author=. International Conference on Learning Representations , volume=. 2024 , url=
2024
-
[17]
Findings of the association for Computational Linguistics: ACL 2023 , pages=
Do large language models know what they don’t know? , author=. Findings of the association for Computational Linguistics: ACL 2023 , pages=. 2023 , url=
2023
-
[18]
Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics , pages =
On faithfulness and factuality in abstractive summarization , author =. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics , pages =
-
[19]
ACM Transactions on Information Systems , volume=
A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions , author=. ACM Transactions on Information Systems , volume=. 2025 , publisher=
2025
-
[20]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages =
Factuality of large language models: A survey , author =. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages =
2024
-
[21]
Transactions on Machine Learning Research , issn=
Generating with Confidence: Uncertainty Quantification for Black-box Large Language Models , author=. Transactions on Machine Learning Research , issn=. 2024 , url=
2024
-
[22]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Shifting attention to relevance: Towards the predictive uncertainty quantification of free-form large language models , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=. 2024 , url=
2024
-
[23]
arXiv preprint arXiv:2207.05221 , year =
Language models (mostly) know what they know , author =. arXiv preprint arXiv:2207.05221 , year =
-
[24]
Transactions of the Association for Computational Linguistics , volume=
How can we know when language models know? on the calibration of language models for question answering , author=. Transactions of the Association for Computational Linguistics , volume=. 2021 , publisher=
2021
-
[25]
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
Just ask for calibration: Strategies for eliciting calibrated confidence scores from language models fine-tuned with human feedback , author=. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=. 2023 , url=
2023
-
[26]
Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena , url =
Zheng, Lianmin and Chiang, Wei-Lin and Sheng, Ying and Zhuang, Siyuan and Wu, Zhanghao and Zhuang, Yonghao and Lin, Zi and Li, Zhuohan and Li, Dacheng and Xing, Eric and Zhang, Hao and Gonzalez, Joseph and Stoica, Ion , booktitle =. Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena , url =
-
[27]
Liu, Yang and Iter, Dan and Xu, Yichong and Wang, Shuohang and Xu, Ruochen and Zhu, Chenguang , booktitle =
-
[28]
Proceedings of the 2023 conference on empirical methods in natural language processing , pages=
G-eval: NLG evaluation using gpt-4 with better human alignment , author=. Proceedings of the 2023 conference on empirical methods in natural language processing , pages=. 2023 , url=
2023
-
[29]
Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages =
Can large language models be an alternative to human evaluations? , author =. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages =
-
[30]
Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Triviaqa: A large scale distantly supervised challenge dataset for reading comprehension , author=. Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=. 2017 , url=
2017
-
[31]
Proceedings of the 2023 conference on empirical methods in natural language processing , pages=
Halueval: A large-scale hallucination evaluation benchmark for large language models , author=. Proceedings of the 2023 conference on empirical methods in natural language processing , pages=. 2023 , url=
2023
-
[32]
Do large language models know what they don
Yin, Zhangyue and Sun, Qiushi and Guo, Qipeng and Wu, Jiawen and Qiu, Xipeng and Huang, Xuanjing , booktitle =. Do large language models know what they don
-
[33]
Lin, Stephanie and Hilton, Jacob and Evans, Owain , booktitle =
-
[34]
Proceedings of the 61st annual meeting of the association for computational linguistics (volume 1: Long papers) , pages=
When not to trust language models: Investigating effectiveness of parametric and non-parametric memories , author=. Proceedings of the 61st annual meeting of the association for computational linguistics (volume 1: Long papers) , pages=. 2023 , url=
2023
-
[35]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Don’t hallucinate, abstain: Identifying llm knowledge gaps via multi-llm collaboration , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=. 2024 , url=
2024
-
[36]
International Conference on Learning Representations , year =
Out-of-distribution detection and selective generation for conditional language models , author =. International Conference on Learning Representations , year =
-
[37]
arXiv preprint arXiv:2509.04664 , year=
Why language models hallucinate , author=. arXiv preprint arXiv:2509.04664 , year=
-
[38]
Machine learning , volume=
Aleatoric and epistemic uncertainty in machine learning: An introduction to concepts and methods , author=. Machine learning , volume=. 2021 , publisher=
2021
-
[39]
arXiv preprint arXiv:2510.12040 , year =
Uncertainty quantification for hallucination detection in large language models: Foundations, methodology, and future directions , author =. arXiv preprint arXiv:2510.12040 , year =
-
[40]
IEEE BITS the Information Theory Magazine , year=
Uncertainty quantification for hallucination detection in large language models: Foundations, methodology, and future directions , author=. IEEE BITS the Information Theory Magazine , year=
-
[41]
arXiv preprint arXiv:2412.05563 , year =
A survey on uncertainty quantification of large language models: Taxonomy, open research challenges, and future directions , author =. arXiv preprint arXiv:2412.05563 , year =
-
[42]
To believe or not to believe your
Abbasi Yadkori, Yasin and Kuzborskij, Ilja and Gy. To believe or not to believe your. arXiv preprint arXiv:2406.02543 , year =
-
[43]
To Believe or Not to Believe Your LLM: Iterative Prompting for Estimating Epistemic Uncertainty , url =
Yadkori, Yasin Abbasi and Kuzborskij, Ilja and Gy\". To Believe or Not to Believe Your LLM: Iterative Prompting for Estimating Epistemic Uncertainty , url =. Advances in Neural Information Processing Systems , doi =
-
[44]
Shelmanov, Artem and Fadeeva, Ekaterina and Tsvigun, Akim and Tsvigun, Ivan and Xie, Zhuohan and Kiselev, Igor and Daheim, Nico and Zhang, Caiqi and Vazhentsev, Artem and Sachan, Mrinmaya and Nakov, Preslav and Baldwin, Timothy. A Head to Predict and a Head to Question: Pre-trained Uncertainty Quantification Heads for Hallucination Detection in LLM Output...
-
[45]
Multicalibration for confidence scoring in
Detommaso, Gianluca and Bertran, Martin and Fogliato, Riccardo and Roth, Aaron , booktitle =. Multicalibration for confidence scoring in
-
[46]
International Conference on Machine Learning , year =
Linguistic calibration of long-form generations , author =. International Conference on Machine Learning , year =
-
[47]
Reducing conversational agents
Mielke, Sabrina J and Szlam, Arthur and Dinan, Emily and Boureau, Y-Lan , booktitle =. Reducing conversational agents
-
[48]
arXiv preprint arXiv:2110.06674 , year=
Truthful AI: Developing and governing AI that does not lie , author=. arXiv preprint arXiv:2110.06674 , year=
-
[49]
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
The curious case of hallucinatory (un) answerability: Finding truths in the hidden states of over-confident large language models , author=. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=. 2023 , url=
2023
-
[50]
Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics , year =
When not to trust language models: Investigating effectiveness of parametric and non-parametric memories , author =. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics , year =
-
[51]
ACM Computing Surveys , volume=
A survey on uncertainty quantification of large language models: Taxonomy, open research challenges, and future directions , author=. ACM Computing Surveys , volume=. 2025 , publisher=
2025
-
[52]
LUQ : Long-text Uncertainty Quantification for LLM s
Zhang, Caiqi and Liu, Fangyu and Basaldella, Marco and Collier, Nigel. LUQ : Long-text Uncertainty Quantification for LLM s. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 2024. doi:10.18653/v1/2024.emnlp-main.299
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.