PortraitGen: Exemplar-Driven GRPO with Dual-Reward Guidance for Photorealistic Portrait Generation
Pith reviewed 2026-06-26 05:12 UTC · model grok-4.3
The pith
Inserting inverted real images into GRPO sampling groups plus dual rewards breaks the model's original distribution and removes fine-grained AI artifacts in portraits.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
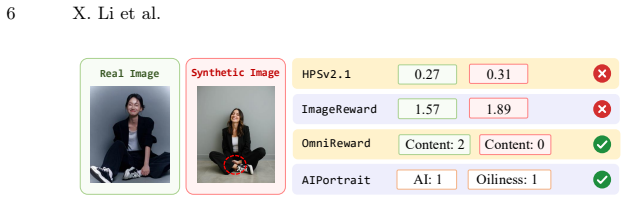
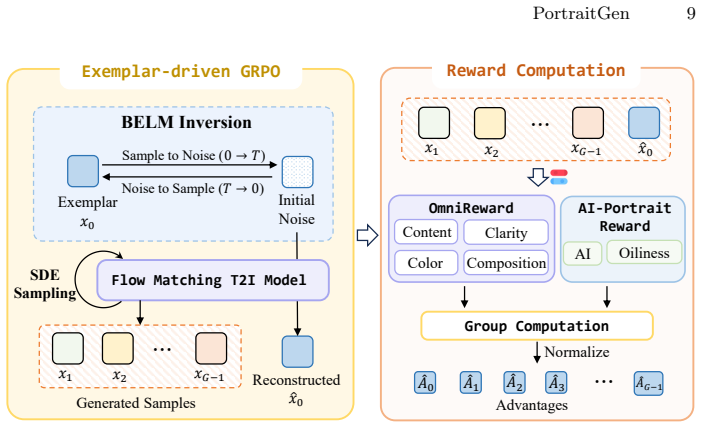
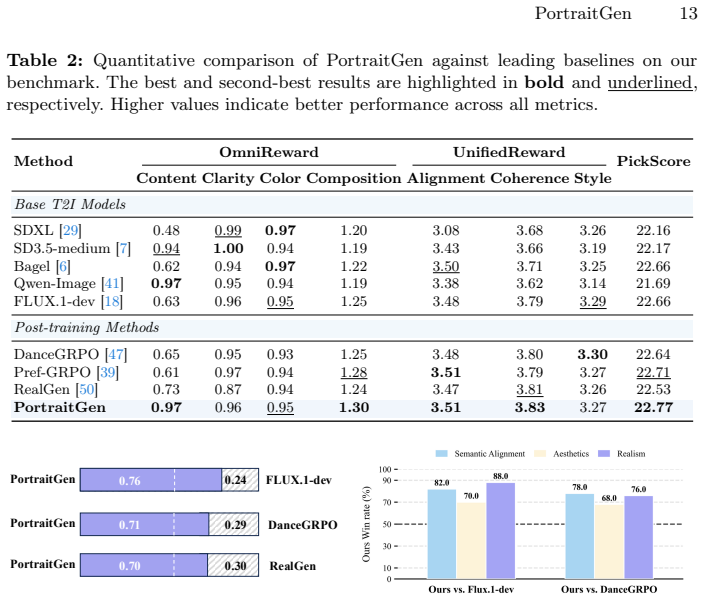
PortraitGen demonstrates that directly introducing real images into GRPO sampling groups via inversion, combined with an OmniReward for overall quality and an AI-Portrait reward for human-centric details, allows the policy to escape its original generative distribution and suppress AI artifacts that prior methods leave unresolved.
What carries the argument
Exemplar-driven GRPO that inserts inverted real images into sampling groups, guided by the dual-reward pair OmniReward and AI-Portrait.
If this is right
- Generated portraits exhibit measurably fewer AI artifacts than those from standard GRPO or other baselines.
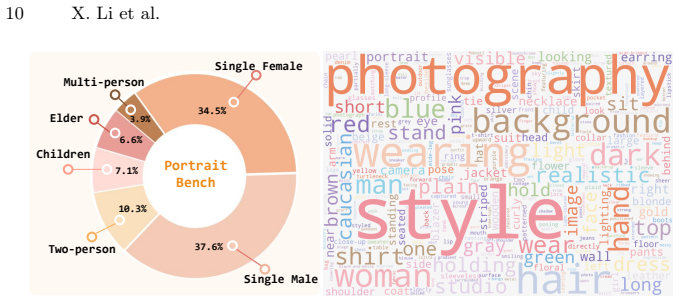
- The method produces higher human-centric fidelity scores on the new PortraitBench benchmark.
- Real-image exemplars can be reused across multiple GRPO iterations without retraining from scratch.
- The dual-reward structure can be applied to other fine-grained image domains beyond portraits.
Where Pith is reading between the lines
- The same inversion-plus-dual-reward pattern might extend to non-portrait domains such as landscapes or product photography if analogous real-image exemplars and domain-specific rewards are supplied.
- If the approach scales without extra hyperparameter search, it could shorten the iteration cycle between model release and production-quality output.
- Future work could test whether the benefit persists when the number of real exemplars per group is reduced below the value used in the reported experiments.
Load-bearing premise
Directly adding inverted real images to GRPO groups together with the two new rewards will reliably push the model outside its starting distribution and remove artifacts without creating fresh failure modes.
What would settle it
Run the same portrait prompts on PortraitGen and on the prior GRPO baseline; if the rate of oily skin, unnatural eyes, or other listed artifacts remains statistically unchanged, the central claim does not hold.
Figures


read the original abstract
Reinforcement Learning like Group Relative Policy Optimization (GRPO) has significantly advanced text-to-image post-training. However, current methods often favor superficial aesthetics, such as over-saturated colors, leaving critical flaws like AI artifacts and biological implausibilities unresolved. We attribute these limitations to two primary factors: (1) The absence of real images during post-training confines GRPO sampling to the original distribution, failing to break inherent generative boundaries; (2) the optimization process lacks specific rewards targeting fine-grained artifacts like overly oily skin and other AI artifacts. To address this, we propose PortraitGen, a novel framework tailored for photorealistic portrait generation. First, we break inherent generative boundaries by directly introducing real images into the GRPO sampling groups, where image inversion is employed to obtain their transition probabilities and latents. Second, to explicitly steer the model toward photorealism, we introduce a complementary dual-reward mechanism: OmniReward for general quality and AI-Portrait for human-centric fidelity. Furthermore, we curate PortraitBench, a comprehensive portrait-centric benchmark. Extensive experiments demonstrate that PortraitGen significantly outperforms existing baselines, effectively suppressing AI artifacts and achieving unprecedented photorealism.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces PortraitGen, a framework for photorealistic portrait generation that extends Group Relative Policy Optimization (GRPO) post-training. It identifies two limitations in prior work—sampling confined to the original model distribution and lack of rewards for fine-grained artifacts—and proposes to address them by (1) inserting real images into GRPO groups via image inversion to obtain latents and transition probabilities, and (2) adding a dual-reward mechanism (OmniReward for general quality and AI-Portrait for human-centric fidelity). The authors also curate PortraitBench and report that the method outperforms baselines in artifact suppression.
Significance. If the inversion step supplies statistics outside the pretrained support and the dual rewards demonstrably reduce specific artifacts without introducing new failure modes, the approach could provide a practical route to improving photorealism in RL-tuned generative models, especially for human portraits where biological implausibilities are costly.
major comments (1)
- [Abstract] Abstract: The claim that 'directly introducing real images into the GRPO sampling groups, where image inversion is employed to obtain their transition probabilities and latents' breaks inherent generative boundaries assumes these probabilities are not still conditioned on the pretrained distribution. Standard inversion (DDIM or equivalent) derives latents and transition probabilities by running the model's own forward process or noise predictor on the real image; if this holds, the GRPO updates remain inside the original support and cannot reliably eliminate fine-grained artifacts as asserted.
minor comments (1)
- The abstract would be strengthened by naming the exact inversion procedure and any modifications to the GRPO group construction.
Simulated Author's Rebuttal
We thank the referee for the careful analysis of our abstract claim. We address the single major comment below and will make corresponding revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that 'directly introducing real images into the GRPO sampling groups, where image inversion is employed to obtain their transition probabilities and latents' breaks inherent generative boundaries assumes these probabilities are not still conditioned on the pretrained distribution. Standard inversion (DDIM or equivalent) derives latents and transition probabilities by running the model's own forward process or noise predictor on the real image; if this holds, the GRPO updates remain inside the original support and cannot reliably eliminate fine-grained artifacts as asserted.
Authors: We agree that standard DDIM-style inversion computes latents and transition probabilities using the pretrained model's noise predictor, so the resulting latents remain within the original support. The manuscript's phrasing that this 'breaks inherent generative boundaries' is therefore imprecise. The intended mechanism is that real-image latents are mixed into each GRPO group; the dual rewards then produce relative rankings that include these real exemplars, allowing the policy gradient to shift generation toward photorealistic outputs even though each individual sample is still drawn from the model. We will revise the abstract (and the corresponding methods paragraph) to remove the 'breaks boundaries' claim, replace it with a clearer description of exemplar mixing and reward-driven ranking, and add a short discussion of the support limitation. revision: yes
Circularity Check
No circularity detected; claims rest on empirical assumptions rather than self-referential derivations
full rationale
The paper proposes PortraitGen by inserting inverted real images into GRPO groups and adding OmniReward plus AI-Portrait rewards to address AI artifacts. No equations appear that define a quantity in terms of itself or rename a fitted parameter as a prediction. The inversion step is presented as a methodological choice to supply external statistics, not as a derivation that reduces to the pretrained model by construction. No self-citation chains, uniqueness theorems, or ansatzes smuggled via prior work are invoked in the abstract or described claims. The central argument is therefore an independent proposal whose validity is left to experimental validation rather than tautological reduction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Bai, S., Cai, Y., Chen, R., Chen, K., Chen, X., Cheng, Z., Deng, L., Ding, W., Gao, C., Ge, C., et al.: Qwen3-vl technical report. arXiv preprint arXiv:2511.21631 (2025) 3, 5
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
IEEE transactions on pattern analysis and machine intelligence47(3), 2212–2231 (2024) 3
Bie, F., Yang, Y., Zhou, Z., Ghanem, A., Zhang, M., Yao, Z., Wu, X., Holmes, C., Golnari, P., Clifton, D.A., et al.: Renaissance: A survey into ai text-to-image generation in the era of large model. IEEE transactions on pattern analysis and machine intelligence47(3), 2212–2231 (2024) 3
2024
-
[3]
Training Diffusion Models with Reinforcement Learning
Black, K., Janner, M., Du, Y., Kostrikov, I., Levine, S.: Training diffusion models with reinforcement learning. arXiv preprint arXiv:2305.13301 (2023) 1
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
Z-Image: An Efficient Image Generation Foundation Model with Single-Stream Diffusion Transformer
Cai, H., Cao, S., Du, R., Gao, P., Hoi, S., Hou, Z., Huang, S., Jiang, D., Jin, X., Li, L., et al.: Z-image: An efficient image generation foundation model with single-stream diffusion transformer. arXiv preprint arXiv:2511.22699 (2025) 3, 6
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Directly Fine-Tuning Diffusion Models on Differentiable Rewards
Clark, K., Vicol, P., Swersky, K., Fleet, D.J.: Directly fine-tuning diffusion models on differentiable rewards. arXiv preprint arXiv:2309.17400 (2023) 1
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
Emerging Properties in Unified Multimodal Pretraining
Deng, C., Zhu, D., Li, K., Gou, C., Li, F., Wang, Z., Zhong, S., Yu, W., Nie, X., Song, Z., et al.: Emerging properties in unified multimodal pretraining. arXiv preprint arXiv:2505.14683 (2025) 3, 13
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
In: Forty-first international conference on machine learning (2024) 13
Esser, P., Kulal, S., Blattmann, A., Entezari, R., Müller, J., Saini, H., Levi, Y., Lorenz, D., Sauer, A., Boesel, F., et al.: Scaling rectified flow transformers for high-resolution image synthesis. In: Forty-first international conference on machine learning (2024) 13
2024
-
[8]
Advances in Neural Information Processing Sys- tems36, 79858–79885 (2023) 1
Fan, Y., Watkins, O., Du, Y., Liu, H., Ryu, M., Boutilier, C., Abbeel, P., Ghavamzadeh, M., Lee, K., Lee, K.: Dpok: Reinforcement learning for fine-tuning text-to-image diffusion models. Advances in Neural Information Processing Sys- tems36, 79858–79885 (2023) 1
2023
-
[9]
Grattafiori, A., Dubey, A., Jauhri, A., Pandey, A., Kadian, A., Al-Dahle, A., Let- man, A., Mathur, A., Schelten, A., Vaughan, A., et al.: The llama 3 herd of models. arXiv preprint arXiv:2407.21783 (2024) 3
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[10]
Hartwig, S., Engel, D., Sick, L., Kniesel, H., Payer, T., Poonam, P., Glöckler, M., Bäuerle, A., Ropinski, T.: A survey on quality metrics for text-to-image generation. IEEE Transactions on Visualization and Computer Graphics31(10), 9464–9483 (2025).https://doi.org/10.1109/TVCG.2025.35850773
- [11]
-
[12]
Advances in neural information processing systems30(2017) 3
Heusel,M.,Ramsauer,H.,Unterthiner,T.,Nessler,B.,Hochreiter,S.:Ganstrained by a two time-scale update rule converge to a local nash equilibrium. Advances in neural information processing systems30(2017) 3
2017
-
[13]
Advances in neural information processing systems33, 6840–6851 (2020) 3
Ho, J., Jain, A., Abbeel, P.: Denoising diffusion probabilistic models. Advances in neural information processing systems33, 6840–6851 (2020) 3
2020
-
[14]
arXiv preprint arXiv:2505.00703 (2025) 2, 4
Jiang, D., Guo, Z., Zhang, R., Zong, Z., Li, H., Zhuo, L., Yan, S., Heng, P.A., Li, H.: T2i-r1: Reinforcing image generation with collaborative semantic-level and token-level cot. arXiv preprint arXiv:2505.00703 (2025) 2, 4
- [15]
-
[16]
Advances in neural information processing systems36, 36652–36663 (2023) 1, 3, 11 16 X
Kirstain,Y.,Polyak,A.,Singer,U.,Matiana,S.,Penna,J.,Levy,O.:Pick-a-pic:An open dataset of user preferences for text-to-image generation. Advances in neural information processing systems36, 36652–36663 (2023) 1, 3, 11 16 X. Li et al
2023
-
[17]
In: Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)
Ku, M., Jiang, D., Wei, C., Yue, X., Chen, W.: Viescore: Towards explainable metrics for conditional image synthesis evaluation. In: Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). pp. 12268–12290 (2024) 3
2024
-
[18]
Labs, B.F.: Flux.https://github.com/black-forest-labs/flux(2024) 2, 3, 6, 13, 14
2024
-
[19]
Labs, B.F.: FLUX.2: Frontier Visual Intelligence.https://bfl.ai/blog/flux-2 (2025) 2, 3
2025
-
[20]
In: International conference on machine learning
Li, J., Li, D., Savarese, S., Hoi, S.: Blip-2: Bootstrapping language-image pre- training with frozen image encoders and large language models. In: International conference on machine learning. pp. 19730–19742. PMLR (2023) 3
2023
-
[21]
In: ProceedingsoftheIEEE/CVFConferenceonComputerVisionandPatternRecog- nition (CVPR)
Li, X., Liu, Y., Isobe, T., Jia, X., Cui, Q., Zhou, D., Li, D., He, Y., Lu, H., Wang, Z., Barsoum, E.: Reneg: Learning negative embedding with reward guidance. In: ProceedingsoftheIEEE/CVFConferenceonComputerVisionandPatternRecog- nition (CVPR). pp. 23636–23645 (June 2025) 4
2025
-
[22]
In: Pro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recogni- tion (CVPR)
Li, Y., Liu, X., Kag, A., Hu, J., Idelbayev, Y., Sagar, D., Wang, Y., Tulyakov, S., Ren, J.: Textcraftor: Your text encoder can be image quality controller. In: Pro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recogni- tion (CVPR). pp. 7985–7995 (June 2024) 4
2024
- [23]
-
[24]
arXiv preprint arXiv:2508.11433 (2025) 2, 4
Liang, Q., Wu, Y., Li, K., Wei, J., He, S., Guo, J., Xie, N.: Mm-r1: Unleashing the power of unified multimodal large language models for personalized image generation. arXiv preprint arXiv:2508.11433 (2025) 2, 4
-
[25]
arXiv preprint arXiv:2503.23907 (2025) 2
Liao, Z., Liu, X., Qin, W., Li, Q., Wang, Q., Wan, P., Zhang, D., Zeng, L., Feng, P.: Humanaesexpert: Advancing a multi-modality foundation model for human image aesthetic assessment. arXiv preprint arXiv:2503.23907 (2025) 2
-
[26]
Flow-GRPO: Training Flow Matching Models via Online RL
Liu, J., Liu, G., Liang, J., Li, Y., Liu, J., Wang, X., Wan, P., Zhang, D., Ouyang, W.: Flow-grpo: Training flow matching models via online rl. arXiv preprint arXiv:2505.05470 (2025) 1, 2, 4, 8
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[27]
Advances in neural information processing systems35, 5775–5787 (2022) 3
Lu, C., Zhou, Y., Bao, F., Chen, J., Li, C., Zhu, J.: Dpm-solver: A fast ode solver for diffusion probabilistic model sampling in around 10 steps. Advances in neural information processing systems35, 5775–5787 (2022) 3
2022
-
[28]
Ma, Y., Wu, X., Sun, K., Li, H.: Hpsv3: Towards wide-spectrum human preference score, 2025. URL https://arxiv. org/abs/2508.0378941, 3
-
[29]
SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis
Podell, D., English, Z., Lacey, K., Blattmann, A., Dockhorn, T., Müller, J., Penna, J., Rombach, R.: Sdxl: Improving latent diffusion models for high-resolution image synthesis. arXiv preprint arXiv:2307.01952 (2023) 3, 13
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[30]
In: International conference on machine learning
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al.: Learning transferable visual models from natural language supervision. In: International conference on machine learning. pp. 8748–8763. PmLR (2021) 2, 3, 13
2021
-
[31]
Advances in neural information processing systems35, 25278–25294 (2022) 3
Schuhmann, C., Beaumont, R., Vencu, R., Gordon, C., Wightman, R., Cherti, M., Coombes, T., Katta, A., Mullis, C., Wortsman, M., et al.: Laion-5b: An open large- scale dataset for training next generation image-text models. Advances in neural information processing systems35, 25278–25294 (2022) 3
2022
-
[32]
Seedream 4.0: Toward Next-generation Multimodal Image Generation
Seedream, T., Chen, Y., Gao, Y., Gong, L., Guo, M., Guo, Q., Guo, Z., Hou, X., Huang, W., Huang, Y., et al.: Seedream 4.0: Toward next-generation multimodal image generation. arXiv preprint arXiv:2509.20427 (2025) 3 PortraitGen 17
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[33]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Shao, Z., Wang, P., Zhu, Q., Xu, R., Song, J., Bi, X., Zhang, H., Zhang, M., Li, Y., Wu, Y., et al.: Deepseekmath: Pushing the limits of mathematical reasoning in open language models. arXiv preprint arXiv:2402.03300 (2024) 2
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[34]
Singh, A., Fry, A., Perelman, A., Tart, A., Ganesh, A., El-Kishky, A., McLaughlin, A., Low, A., Ostrow, A., Ananthram, A., et al.: Openai gpt-5 system card. arXiv preprint arXiv:2601.03267 (2025) 3
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[35]
Denoising Diffusion Implicit Models
Song, J., Meng, C., Ermon, S.: Denoising diffusion implicit models. arXiv preprint arXiv:2010.02502 (2020) 3, 8
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[36]
Team,C.:Chameleon:Mixed-modalearly-fusionfoundationmodels.arXivpreprint arXiv:2405.09818 (2024) 3
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[37]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Wallace, B., Dang, M., Rafailov, R., Zhou, L., Lou, A., Purushwalkam, S., Ermon, S., Xiong, C., Joty, S., Naik, N.: Diffusion model alignment using direct preference optimization. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 8228–8238 (2024) 1
2024
-
[38]
Advances in Neural Information Processing Systems37, 46118–46159 (2024) 8
Wang, F., Yin, H., Dong, Y.J., Zhu, H., Zhao, H., Qian, H., Li, C., et al.: Belm: Bidirectional explicit linear multi-step sampler for exact inversion in diffusion mod- els. Advances in Neural Information Processing Systems37, 46118–46159 (2024) 8
2024
-
[39]
Pref-GRPO: Pairwise Preference Reward-based GRPO for Stable Text-to-Image Reinforcement Learning
Wang, Y., Li, Z., Zang, Y., Zhou, Y., Bu, J., Wang, C., Lu, Q., Jin, C., Wang, J.: Pref-grpo: Pairwise preference reward-based grpo for stable text-to-image rein- forcement learning. arXiv preprint arXiv:2508.20751 (2025) 2, 4, 13
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[40]
Unified Reward Model for Multimodal Understanding and Generation
Wang, Y., Zang, Y., Li, H., Jin, C., Wang, J.: Unified reward model for multimodal understanding and generation. arXiv preprint arXiv:2503.05236 (2025) 3, 11
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[41]
Wu, C., Li, J., Zhou, J., Lin, J., Gao, K., Yan, K., ming Yin, S., Bai, S., Xu, X., Chen, Y., Chen, Y., Tang, Z., Zhang, Z., Wang, Z., Yang, A., Yu, B., Cheng, C., Liu, D., Li, D., Zhang, H., Meng, H., Wei, H., Ni, J., Chen, K., Cao, K., Peng, L., Qu, L., Wu, M., Wang, P., Yu, S., Wen, T., Feng, W., Xu, X., Wang, Y., Zhang, Y., Zhu, Y., Wu, Y., Cai, Y., L...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[42]
Wu, X., Hao, Y., Sun, K., Chen, Y., Zhu, F., Zhao, R., Li, H.: Human preference score v2: A solid benchmark for evaluating human preferences of text-to-image synthesis. arXiv preprint arXiv:2306.09341 (2023) 1, 2, 3, 13
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[43]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Xiao, S., Wang, Y., Zhou, J., Yuan, H., Xing, X., Yan, R., Li, C., Wang, S., Huang, T., Liu, Z.: Omnigen: Unified image generation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 13294–13304 (2025) 3
2025
-
[44]
Show-o: One Single Transformer to Unify Multimodal Understanding and Generation
Xie, J., Mao, W., Bai, Z., Zhang, D.J., Wang, W., Lin, K.Q., Gu, Y., Chen, Z., Yang, Z., Shou, M.Z.: Show-o: One single transformer to unify multimodal under- standing and generation. arXiv preprint arXiv:2408.12528 (2024) 3
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [45]
-
[46]
Advances in Neural Information Processing Systems36, 15903–15935 (2023) 1, 3, 4
Xu, J., Liu, X., Wu, Y., Tong, Y., Li, Q., Ding, M., Tang, J., Dong, Y.: Imagere- ward: Learning and evaluating human preferences for text-to-image generation. Advances in Neural Information Processing Systems36, 15903–15935 (2023) 1, 3, 4
2023
-
[47]
DanceGRPO: Unleashing GRPO on Visual Generation
Xue, Z., Wu, J., Gao, Y., Kong, F., Zhu, L., Chen, M., Liu, Z., Liu, W., Guo, Q., Huang, W., et al.: Dancegrpo: Unleashing grpo on visual generation. arXiv preprint arXiv:2505.07818 (2025) 1, 2, 4, 8, 13, 14 18 X. Li et al
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[48]
ACM computing surveys56(4), 1–39 (2023) 3
Yang,L.,Zhang,Z.,Song,Y.,Hong,S.,Xu,R.,Zhao,Y.,Zhang,W.,Cui,B.,Yang, M.H.: Diffusion models: A comprehensive survey of methods and applications. ACM computing surveys56(4), 1–39 (2023) 3
2023
-
[49]
arXiv preprint arXiv:2505.02527 (2025) 3
Yang, P., Cheung, N.M., Ma, X.: Text to image generation and editing: A survey. arXiv preprint arXiv:2505.02527 (2025) 3
-
[50]
arXiv preprint arXiv:2512.00473 (2025) 2, 4, 13
Ye, J., Zhu, L., Guo, Y., Jiang, D., Huang, Z., Zhang, Y., Yan, Z., Fu, H., He, C., Li, W.: Realgen: Photorealistic text-to-image generation via detector-guided rewards. arXiv preprint arXiv:2512.00473 (2025) 2, 4, 13
- [51]
-
[52]
arXiv preprint arXiv:2303.07909 (2023) 3
Zhang, C., Zhang, C., Zhang, M., Kweon, I.S., Kim, J.: Text-to-image diffusion models in generative ai: A survey. arXiv preprint arXiv:2303.07909 (2023) 3
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.