One-Shot Data Selection for Medical Image Classification via Graph Coverage
Pith reviewed 2026-06-26 12:47 UTC · model grok-4.3
The pith
A two-term coverage kernel on k-NN graphs from frozen embeddings selects subsets that maximize manifold coverage and raise balanced accuracy on medical image tasks without any training during selection.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
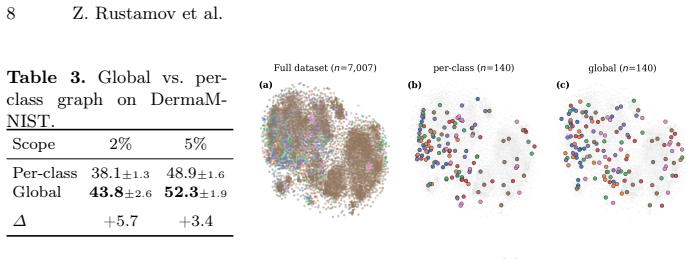
Given embeddings from a pretrained encoder, the method constructs a k-nearest neighbor graph over all training samples, derives a two-term coverage kernel from the heat diffusion kernel that approximates full spectral behavior through sparse matrix operations, and uses greedy facility location on this kernel to choose class-balanced subsets that maximize coverage of the data manifold; the resulting subsets produce the highest balanced accuracy on nine of ten dataset-ratio conditions across five MedMNIST datasets, with the largest gains on class-imbalanced collections.
What carries the argument
The two-term coverage kernel on the k-NN graph, which encodes direct and two-hop neighborhood relationships for facility-location selection.
If this is right
- The method requires no model training or oracle access during the selection step itself.
- Global graph construction yields larger gains on class-imbalanced datasets than methods that operate per class.
- The two-term kernel reproduces the selection behavior of the full heat kernel while remaining computationally cheap.
- Performance is measured on five MedMNIST collections covering histopathology, radiology, and microscopy.
Where Pith is reading between the lines
- If the same kernel construction were applied to embeddings from a domain-specific fine-tuned model, the coverage quality might increase further.
- The approach could serve as an initialization step for subsequent active-learning rounds rather than a standalone one-shot solution.
- Failure on a new dataset would most likely trace back to the pretrained embeddings failing to reflect the target manifold rather than to the kernel or selection algorithm.
Load-bearing premise
Embeddings from a generic pretrained foundation model preserve enough local manifold structure of the specific medical datasets that selections based on the k-NN graph and two-term kernel will improve downstream classifier performance.
What would settle it
On a held-out medical imaging dataset, the subsets chosen by the graph-coverage method produce classifiers whose balanced accuracy falls below that of random selection or the strongest baseline under the same annotation budget.
Figures

read the original abstract
Training medical image classifiers on entire datasets is wasteful when annotation budgets are limited: not all samples contribute equally, yet acquiring expert labels is expensive. Active learning reduces annotation cost through iterative querying, but assumes repeated access to an oracle and requires multiple rounds of model training. One-shot geometry-based methods such as facility location avoid retraining but operate on pairwise distances that ignore the local structure of the data manifold. We propose a graph-based one-shot selection method that operates entirely on frozen foundation model embeddings. Given embeddings from a pretrained encoder, we construct a k-nearest neighbor graph over all training samples and derive a two-term coverage kernel from the heat diffusion kernel, capturing both direct and two-hop neighborhood relationships. Greedy facility location on this kernel selects class-balanced subsets that maximize coverage of the data manifold. The two-term kernel matches the full spectral heat kernel in selection behavior while reducing computation to sparse matrix operations with a single hyperparameter. We evaluate on five MedMNIST datasets spanning histopathology, radiology, and microscopy, comparing against both training-dynamics and geometry-based baselines. Our method achieves the highest balanced accuracy on nine of ten dataset-ratio conditions, with the largest gains on class-imbalanced datasets where global graph construction captures cross-class structure that per-class methods miss, all without any model training during selection. Code is available at https://github.com/zahiriddin-rustamov/graph-coverage-selection.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a one-shot data selection method for medical image classification that constructs a k-NN graph on frozen pretrained foundation-model embeddings, derives a two-term coverage kernel from the heat diffusion kernel to capture direct and two-hop neighborhoods, and applies greedy facility location to select class-balanced subsets maximizing manifold coverage. Evaluated on five MedMNIST datasets (histopathology, radiology, microscopy), the method reports the highest balanced accuracy on nine of ten dataset-ratio conditions versus training-dynamics and geometry-based baselines, with largest gains on imbalanced data, and releases code at the provided GitHub link.
Significance. If the central empirical claim holds after addressing the embedding assumption, the work offers a training-free, one-shot alternative to active learning that efficiently handles annotation budgets in medical imaging, particularly for imbalanced classes via global graph structure. Credit is due for the code release (reducing circularity risk), the reduction to sparse operations with only k and one kernel hyperparameter, and the focus on cross-class manifold coverage that per-class methods miss.
major comments (2)
- [Evaluation / Experimental Setup] Evaluation section: no validation is provided of whether the generic pretrained embeddings preserve local manifold structure on the MedMNIST datasets (e.g., neighborhood preservation metrics such as trustworthiness or continuity, or ablation against domain-specific encoders). This assumption is load-bearing for the central claim, because the k-NN graph and two-term kernel selections are only useful downstream if the embedding geometry aligns with the data manifold; distortion would render the reported balanced-accuracy gains un-attributable to the coverage kernel.
- [Results] Results (and abstract): the superiority claim (highest balanced accuracy on 9/10 conditions) provides no statistical significance tests, run-to-run variance, or exact baseline implementation details (e.g., hyperparameter choices or training protocols for the dynamics-based comparators). This is load-bearing for verifying the performance edge, especially on imbalanced subsets where small differences could arise from implementation variance rather than the proposed kernel.
minor comments (2)
- [Methods] The single kernel hyperparameter is mentioned but its value, selection procedure, and sensitivity analysis are not detailed; adding this (with ablation) would improve reproducibility without altering the core contribution.
- [Method] Notation for the two-term coverage kernel (direct vs. two-hop terms) could be clarified with an explicit equation reference to distinguish it from the full spectral heat kernel.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the major comments point by point below.
read point-by-point responses
-
Referee: [Evaluation / Experimental Setup] Evaluation section: no validation is provided of whether the generic pretrained embeddings preserve local manifold structure on the MedMNIST datasets (e.g., neighborhood preservation metrics such as trustworthiness or continuity, or ablation against domain-specific encoders). This assumption is load-bearing for the central claim, because the k-NN graph and two-term kernel selections are only useful downstream if the embedding geometry aligns with the data manifold; distortion would render the reported balanced-accuracy gains un-attributable to the coverage kernel.
Authors: We agree that the manuscript does not include explicit validation of manifold preservation in the embeddings. This is a valid observation. We will revise the evaluation section to add neighborhood preservation metrics (trustworthiness and continuity) on the MedMNIST embeddings and include an ablation against available domain-specific encoders to support the assumption. revision: yes
-
Referee: [Results] Results (and abstract): the superiority claim (highest balanced accuracy on 9/10 conditions) provides no statistical significance tests, run-to-run variance, or exact baseline implementation details (e.g., hyperparameter choices or training protocols for the dynamics-based comparators). This is load-bearing for verifying the performance edge, especially on imbalanced subsets where small differences could arise from implementation variance rather than the proposed kernel.
Authors: We agree that statistical tests, variance reporting, and detailed baseline protocols are necessary for robust claims. We will revise the results section and supplementary material to report means and standard deviations over multiple random seeds, add statistical significance tests (e.g., paired tests), and provide exact hyperparameter settings and training protocols for all baselines. revision: yes
Circularity Check
No significant circularity; derivation is self-contained.
full rationale
The paper defines a one-shot selection procedure directly from k-NN graph construction on frozen embeddings followed by a two-term kernel and greedy facility location. No step reduces a claimed prediction or result to a fitted parameter or self-citation by construction; the method is algorithmic and evaluated empirically on external datasets without internal fitting loops that would force equivalence between inputs and outputs. The central claim rests on the empirical performance of this explicit construction rather than any definitional or self-referential reduction.
Axiom & Free-Parameter Ledger
free parameters (2)
- k (nearest neighbors)
- single kernel hyperparameter
axioms (1)
- domain assumption Embeddings from a pretrained foundation model preserve the local structure of the target medical image data manifold.
invented entities (1)
-
two-term coverage kernel
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Medical Image Analysis71, 102062 (2021) Graph Coverage Selection 9
Budd, S., Robinson, E.C., Kainz, B.: A survey on active learning and human-in- the-loop deep learning for medical image analysis. Medical Image Analysis71, 102062 (2021) Graph Coverage Selection 9
2021
-
[2]
Nature Medicine30(3), 850–862 (2024)
Chen, R.J., Ding, T., Lu, M.Y., Williamson, D.F.K., Jaume, G., Song, A.H., Chen, B.,Zhang,A.,Shao,D.,Shaban,M.,Williams,M.,Oldenburg,L.,Weishaupt,L.L., Wang,J.J.,Vaidya,A.,Le,L.P.,Gerber,G.,Sahai,S.,Williams,W.,Mahmood,F.: Towards a general-purpose foundation model for computational pathology. Nature Medicine30(3), 850–862 (2024)
2024
-
[3]
In: Medical Image Computing and Computer Assisted Intervention – MICCAI 2021
Chen, R.J., Lu, M.Y., Shaban, M., Chen, C., Chen, T.Y., Williamson, D.F.K., Mahmood, F.: Whole slide images are 2d point clouds: Context-aware survival prediction using patch-based graph convolutional networks. In: Medical Image Computing and Computer Assisted Intervention – MICCAI 2021. pp. 339–349. Springer (2021)
2021
-
[4]
Journal of the American Medi- cal Informatics Association30(6), 1079–1090 (2023).https://doi.org/10.1093/ jamia/ocad055
Chinn, E., Arora, R., Arnaout, R., Arnaout, R.: Enriching medical imaging train- ing sets enables more efficient machine learning. Journal of the American Medi- cal Informatics Association30(6), 1079–1090 (2023).https://doi.org/10.1093/ jamia/ocad055
2023
-
[5]
In: Balinski, M.L., Hoffman, A.J
Fisher, M.L., Nemhauser, G.L., Wolsey, L.A.: An analysis of approximations for maximizing submodular set functions—II. In: Balinski, M.L., Hoffman, A.J. (eds.) Polyhedral Combinatorics, pp. 73–87. Springer, Berlin, Heidelberg (1978)
1978
-
[6]
In: DEXA
Guo, C., Zhao, B., Bai, Y.: Deepcore: A comprehensive library for coreset selection in deep learning. In: DEXA. LNCS, vol. 13108, pp. 181–195. Springer (2022)
2022
-
[7]
In: CVPR (2016)
He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: CVPR (2016)
2016
-
[8]
In: Proceedings of the 32nd ACM International Conference on Multimedia
Hong, Y., Zhang, X., Zhang, X., Zhou, J.T.: Evolution-aware variance (eva) core- set selection for medical image classification. In: Proceedings of the 32nd ACM International Conference on Multimedia. pp. 301–310. MM ’24, Association for Computing Machinery, New York, NY, USA (2024).https://doi.org/10.1145/ 3664647.3681592
arXiv 2024
-
[9]
In: 2025 IEEE 22nd Inter- national Symposium on Biomedical Imaging (ISBI) (2025).https://doi.org/10
Ji, A., Kang, Q., Xu, W., Wang, C., Li, K., Lao, Q.: Confounder-aware medical data selection for fine-tuning pretrained vision models. In: 2025 IEEE 22nd Inter- national Symposium on Biomedical Imaging (ISBI) (2025).https://doi.org/10. 1109/ISBI60581.2025.10980785
arXiv 2025
-
[10]
In: ICML (2002)
Kondor, R.I., Lafferty, J.: Diffusion kernels on graphs and other discrete input spaces. In: ICML (2002)
2002
-
[11]
In: Medical Image Computing and Computer Assisted Intervention – MICCAI 2023
Liu, H., Li, H., Yao, X., Fan, Y., Hu, D., Dawant, B.M., Nath, V., Xu, Z., Oguz, I.: Colossal: A benchmark for cold-start active learning for 3d medical image seg- mentation. In: Medical Image Computing and Computer Assisted Intervention – MICCAI 2023. pp. 25–34. Springer (2023)
2023
-
[12]
Mathematical Programming14, 265–294 (1978)
Nemhauser, G.L., Wolsey, L.A., Fisher, M.L.: An analysis of approximations for maximizing submodular set functions—I. Mathematical Programming14, 265–294 (1978)
1978
-
[13]
Medical Image Analysis75, 102264 (2022)
Pati, P., Jaume, G., Foncubierta-Rodríguez, A., Feroce, F., Anniciello, A.M., Scog- namiglio, G., Brancati, N., Fiche, M., Dubruc, E., Riccio, D., Di Bonito, M., De Pietro, G., Botti, G., Thiran, J.P., Frucci, M., Goksel, O., Gabrani, M.: Hierarchi- cal graph representations in digital pathology. Medical Image Analysis75, 102264 (2022)
2022
-
[14]
In: Advances in Neural Information Processing Systems
Paul, M., Ganguli, S., Dziugaite, G.K.: Deep learning on a data diet: Finding im- portant examples early in training. In: Advances in Neural Information Processing Systems. vol. 34, pp. 20596–20607 (2021)
2021
-
[15]
Settles, B.: Active learning literature survey. Tech. rep., University of Wisconsin– Madison (2009) 10 Z. Rustamov et al
2009
-
[16]
In: Advances in Neural Information Processing Systems
Sorscher, B., Geirhos, R., Shekhar, S., Ganguli, S., Morcos, A.: Beyond neural scaling laws: Beating power law scaling via data pruning. In: Advances in Neural Information Processing Systems. vol. 35, pp. 19523–19536. Curran Associates, Inc. (2022)
2022
-
[17]
In: ICLR (2019)
Toneva, M., Sordoni, A., Combes, R.T.d., Trischler, A., Bengio, Y., Gordon, G.J.: An empirical study of example forgetting during deep neural network learning. In: ICLR (2019)
2019
-
[18]
Medical Image Analysis95, 103201 (2024)
Wang, H., Jin, Q., Li, S., Liu, S., Wang, M., Song, Z.: A comprehensive survey on deep active learning in medical image analysis. Medical Image Analysis95, 103201 (2024)
2024
-
[19]
In: ICML
Wei, K., Iyer, R., Bilmes, J.: Submodularity in data subset selection and active learning. In: ICML. vol. 37, pp. 1954–1963. PMLR (2015)
1954
-
[20]
In: ICML (2009)
Welling, M.: Herding dynamical weights to learn. In: ICML (2009)
2009
-
[21]
Scientific Data10(1), 41 (2023)
Yang, J., Shi, R., Wei, D., Liu, Z., Zhao, L., Ke, B., Pfister, H., Ni, B.: Medmnist v2–a large-scale lightweight benchmark for 2d and 3d biomedical image classifica- tion. Scientific Data10(1), 41 (2023)
2023
-
[22]
In: ICCV Workshops (2019)
Zhou,Y.,Graham,S.,AlemiKoohbanani,N.,Shaban,M.,Heng,P.A.,Rajpoot,N.: Cgc-net: Cell graph convolutional network for grading of colorectal cancer histology images. In: ICCV Workshops (2019)
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.