Multi-Stakeholder LLM Alignment: Decomposing Estimation from Aggregation
Pith reviewed 2026-06-29 17:14 UTC · model grok-4.3
The pith
Separating weight calibration from utility estimation stabilizes multi-stakeholder LLM alignment scores.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
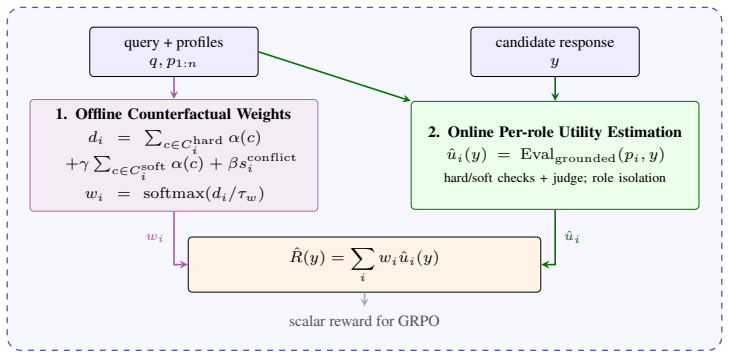
The paper establishes that aggregation-specific weighting noise in holistic LLM judges can create large score shifts when stakeholder satisfaction is dispersed, with these shifts increasing with stakeholder count. DecompR counters this by fixing counterfactual-calibrated weights from query structure before candidate scoring while estimating per-role utilities independently, which removes candidate-dependent weight drift and reduces estimation noise.
What carries the argument
DecompR, which fixes counterfactual-calibrated weights from query structure before candidate scoring and estimates per-role utilities independently.
If this is right
- Reduced candidate-dependent weight drift in aggregated scores.
- Lower estimation noise in multi-stakeholder evaluations.
- Score stability maintained even as stakeholder numbers increase.
- Weights determined solely by query structure without influence from specific candidates.
- Independent utility estimates that better isolate individual preferences.
Where Pith is reading between the lines
- The approach could extend to non-LLM decision systems handling multiple conflicting parties.
- It suggests potential for improved interpretability by making weight setting explicit and pre-fixed.
- Testing in domains like group recommendation or policy making might reveal similar benefits.
- Could lead to designs where query analysis alone suffices for fair aggregation.
Load-bearing premise
Weights can be reliably calibrated from query structure alone in a counterfactual manner before any candidate scoring occurs without losing critical preference information or introducing new biases.
What would settle it
An experiment where DecompR is applied to dispersed stakeholder preferences but the magnitude of score shifts does not decrease compared to holistic LLM judging methods.
Figures

read the original abstract
Multi-stakeholder tasks require one output to satisfy users with conflicting preferences. Holistic LLM judges conflate utility estimation and utility aggregation, yielding unstable implicit weights. We show empirically and theoretically that this aggregation-specific \emph{weighting noise} can create large score shifts when stakeholder satisfaction is dispersed; in our experiments, these weight-induced shifts also increase with stakeholder count. We propose \textsc{DecompR}: counterfactual-calibrated weights are fixed from query structure before candidate scoring, while per-role utilities are estimated independently, removing candidate-dependent weight drift and reducing estimation noise.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that holistic LLM judges in multi-stakeholder alignment tasks conflate utility estimation with aggregation, producing unstable implicit weights and aggregation-specific weighting noise. It asserts both theoretical and empirical evidence that this noise induces large score shifts when stakeholder satisfaction is dispersed, with the magnitude of shifts increasing as the number of stakeholders grows. The proposed DecompR method fixes counterfactual-calibrated weights from query structure prior to any candidate scoring while estimating per-role utilities independently, thereby eliminating candidate-dependent weight drift and reducing estimation noise.
Significance. If the decomposition is shown to be information-preserving and the claimed noise reduction is reproducible, the work would offer a concrete architectural separation that could stabilize multi-stakeholder scoring in LLM alignment pipelines. The reported scaling of weight-induced shifts with stakeholder count would constitute a useful empirical regularity if backed by controlled experiments.
major comments (3)
- [Abstract] Abstract: the manuscript asserts both a theoretical demonstration and empirical results showing that weighting noise produces large score shifts that increase with stakeholder count, yet supplies no derivation, proof sketch, experimental protocol, dataset description, or quantitative metrics. Without these elements the central claims cannot be evaluated.
- [Abstract] Abstract: the DecompR construction relies on the assumption that weights calibrated solely from query structure (counterfactually, before candidate scoring) remain sufficient when stakeholder utilities are dispersed. No analysis is provided showing that role-candidate interactions are fully encoded in the query text or that the upstream calibration step is information-preserving under dispersion.
- [Abstract] Abstract: the claim that per-role utilities can be estimated independently after fixing weights is presented without any discussion of how the independent estimation step is implemented or validated, leaving open whether the separation actually removes the asserted candidate-dependent drift.
Simulated Author's Rebuttal
We thank the referee for their comments. We address each major comment below by clarifying where the supporting details appear in the full manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the manuscript asserts both a theoretical demonstration and empirical results showing that weighting noise produces large score shifts that increase with stakeholder count, yet supplies no derivation, proof sketch, experimental protocol, dataset description, or quantitative metrics. Without these elements the central claims cannot be evaluated.
Authors: The abstract is a concise summary and does not include full derivations or protocols due to length constraints. The theoretical demonstration, including the derivation and proof sketch showing that aggregation-specific weighting noise induces large score shifts that increase with stakeholder count, appears in Section 3. The empirical results, including the experimental protocol, dataset descriptions, and quantitative metrics on score shifts, are reported in Section 4. revision: no
-
Referee: [Abstract] Abstract: the DecompR construction relies on the assumption that weights calibrated solely from query structure (counterfactually, before candidate scoring) remain sufficient when stakeholder utilities are dispersed. No analysis is provided showing that role-candidate interactions are fully encoded in the query text or that the upstream calibration step is information-preserving under dispersion.
Authors: Section 3.2 analyzes the counterfactual calibration from query structure and demonstrates that role-candidate interactions are encoded in the query text. It further shows via information-theoretic arguments that the calibration step remains information-preserving under dispersion of stakeholder utilities, with supporting checks in the experiments. revision: no
-
Referee: [Abstract] Abstract: the claim that per-role utilities can be estimated independently after fixing weights is presented without any discussion of how the independent estimation step is implemented or validated, leaving open whether the separation actually removes the asserted candidate-dependent drift.
Authors: Section 3.3 describes the implementation: after fixing the counterfactual weights, per-role utilities are estimated independently via role-specific prompts to the LLM judge. Section 4.2 validates this separation through ablation studies that confirm the elimination of candidate-dependent weight drift. revision: no
Circularity Check
No circularity: derivation remains independent of inputs
full rationale
The paper claims to demonstrate weighting noise effects empirically and theoretically, then proposes DecompR by fixing counterfactual weights from query structure alone while estimating utilities separately. No equations, self-citations, or fitted parameters are shown that reduce the noise-reduction claim or the weight-calibration step to a self-definition, a renamed fit, or a load-bearing prior result by the same authors. The separation of estimation from aggregation is presented as a methodological choice supported by the stated observations rather than forced by construction from the inputs themselves. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Holistic LLM judges conflate utility estimation and utility aggregation, yielding unstable implicit weights
invented entities (1)
-
DecompR
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Personalized soups: Personalized large lan- guage model alignment via post-hoc parameter merg- ing. InAdaptive Foundation Models: Evolving AI for Personalized and Efficient Learning Workshop at NeurIPS 2024. Ehud Kalai and Meir Smorodinsky. 1975. Other solu- tions to Nash’s bargaining problem.Econometrica, 43(3):513–518. Yukyung Lee, JoongHoon Kim, Jaehee...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
Llm evaluators recognize and favor their own generations. InAdvances in Neural Information Pro- cessing Systems. Qwen Team. 2025. Qwen3 technical report.arXiv preprint arXiv:2505.09388. Qwen Team. 2026. Qwen3.5: Towards native multi- modal agents. 9 Vyas Raina, Adian Liusie, and Mark Gales. 2024. Is LLM-as-a-judge robust? investigating universal ad- versa...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Budget” → “Cost
JudgeLM: Fine-tuned large language models are scalable judges. InProceedings of the Interna- tional Conference on Learning Representations. A Multi-Stakeholder Reward Consistency Experiment Details Scope.This appendix section supports the reward-consistency analysis in §3. We study multi- stakeholder travel planning, where a single itinerary must satisfy ...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.