Hybrid-IR: Dual-Path Hybrid Retrieval with Iterative Reasoning for Complex Medical Question Answering
Pith reviewed 2026-06-25 21:30 UTC · model grok-4.3
The pith
Dual-path retrieval with an iterative loop improves complex medical question answering.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
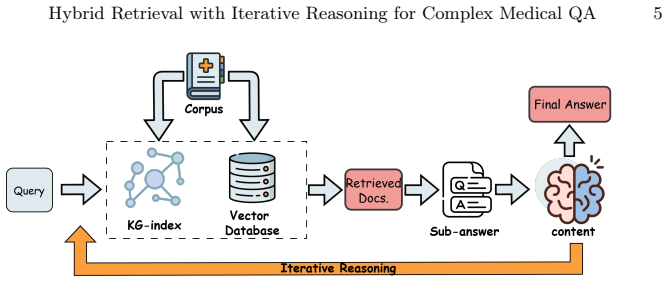
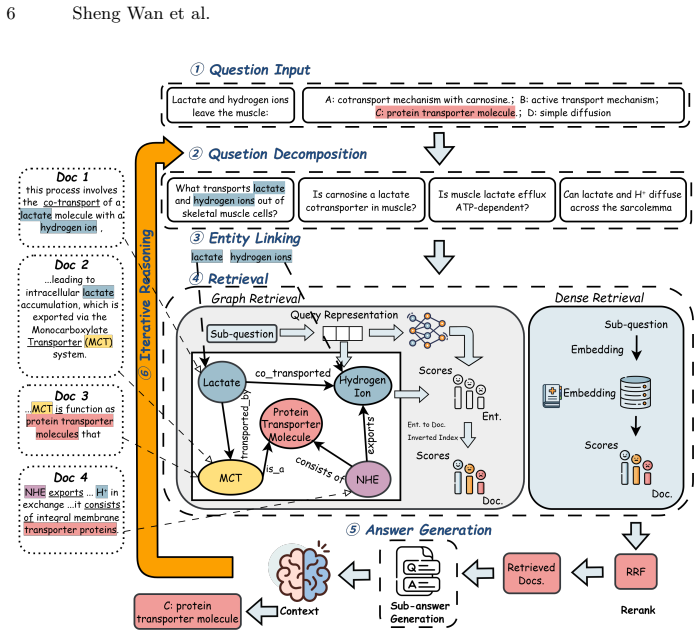
Hybrid-IR integrates graph-based retrieval for exploration of structured knowledge and dense retrieval for fine-grained semantic matching. The reasoning trajectory can be progressively refined through an iterative retrieve-reason loop. Experiments on three widely used medical QA benchmarks demonstrate the effectiveness of Hybrid-IR.
What carries the argument
Dual-path hybrid retrieval with iterative retrieve-reason loop that pairs graph-based structured exploration and dense semantic matching.
If this is right
- Joint preservation of fine-grained semantic information and structured global associations in fragmented medical documents.
- Progressive refinement of reasoning trajectories to support deep reasoning in complex medical QA.
- Reduced hallucinations and outdated knowledge in LLMs through more effective external document use.
- Demonstrated gains on three standard medical QA benchmarks.
Where Pith is reading between the lines
- The dual-path plus iteration pattern might transfer to other domains where knowledge is both detailed and interconnected, such as legal or technical QA.
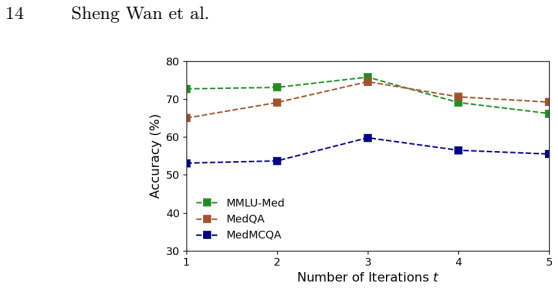
- Measuring how many loop iterations are typically needed could clarify the added compute cost versus accuracy benefit.
- The framework could be extended by weighting the two retrieval paths differently depending on question type.
Load-bearing premise
That running graph-based and dense retrieval together in an iterative loop will keep both fine details and overall structure while enabling deep reasoning without creating new failure modes on real medical data.
What would settle it
If Hybrid-IR shows no accuracy gain over single-path RAG baselines when tested on the same three medical QA benchmarks, or if the iterative steps increase incorrect reasoning chains.
Figures
read the original abstract
Large language models (LLMs) have shown promising performance across a wide range of biomedical applications, including medical question answering (QA), yet they remain prone to hallucinations and outdated knowledge. Although retrieval-augmented generation (RAG) can alleviate this issue by incorporating external documents, there still exist two fundamental limitations. First, medical knowledge is often fragmented across documents, while most RAG methods rely on a single retrieval path, which makes it challenging to jointly preserve fine-grained semantic information and structured global associations. Second, static retrieval strategies are typically insufficient to support deep reasoning that is important in complex medical QA. In this paper, we present a dual-path retrieval framework with an iterative retrieval-reasoning mechanism termed "Hybrid-IR" for complex medical QA. The proposed Hybrid-IR integrates graph-based retrieval for exploration of structured knowledge and dense retrieval for fine-grained semantic matching. Moreover, the reasoning trajectory can be progressively refined through an iterative retrieve-reason loop. Experiments on three widely used medical QA benchmarks demonstrate the effectiveness of our Hybrid-IR.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Hybrid-IR, a dual-path hybrid retrieval framework with an iterative retrieve-reason loop for complex medical question answering. It combines graph-based retrieval for structured knowledge exploration and dense retrieval for fine-grained semantic matching to address two limitations in standard RAG: fragmented medical knowledge across documents and insufficient support for deep reasoning with static retrieval. The reasoning trajectory is refined progressively via the iterative loop, with effectiveness shown on three medical QA benchmarks.
Significance. If the empirical gains hold and the iterative mechanism avoids error amplification, the work could meaningfully advance RAG methods for medical QA by jointly handling structured associations and semantic details while supporting multi-step reasoning. The dual-path design directly targets a recognized weakness in single-path retrieval for domains with fragmented knowledge.
major comments (2)
- [Abstract] Abstract: The central claim that the iterative retrieve-reason loop 'progressively refines' the reasoning trajectory without introducing new failure modes is load-bearing, yet the abstract provides no description of termination criteria, fusion of graph and dense outputs, conflict resolution for contradictory evidence, or verification of intermediate steps. This leaves the no-new-failure-modes assumption unanchored, especially given the known risk of error amplification on noisy medical retrievals.
- [Abstract] Abstract: The claim that experiments on three medical QA benchmarks 'demonstrate the effectiveness' cannot be evaluated because no implementation details, baselines, ablation studies, or error analysis are described, making it impossible to verify whether the dual-path plus iterative design actually preserves fine-grained semantics and structured associations jointly.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract. We agree that the abstract should better anchor its claims about the iterative mechanism and experimental results. We will revise the abstract accordingly while respecting length constraints, with details remaining in the body of the paper. Point-by-point responses follow.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that the iterative retrieve-reason loop 'progressively refines' the reasoning trajectory without introducing new failure modes is load-bearing, yet the abstract provides no description of termination criteria, fusion of graph and dense outputs, conflict resolution for contradictory evidence, or verification of intermediate steps. This leaves the no-new-failure-modes assumption unanchored, especially given the known risk of error amplification on noisy medical retrievals.
Authors: We acknowledge the abstract's conciseness leaves the iterative mechanism underspecified. Section 3 of the manuscript describes termination (fixed max iterations or convergence when no new evidence is added), fusion (score-weighted merging of graph paths and dense passages), conflict resolution (LLM consistency check against sources), and verification (cross-referencing intermediate steps with retrieved evidence). To directly address error amplification concerns, we will revise the abstract to include a brief clause noting that intermediate steps undergo evidence verification. This strengthens the claim without misrepresenting the work. revision: yes
-
Referee: [Abstract] Abstract: The claim that experiments on three medical QA benchmarks 'demonstrate the effectiveness' cannot be evaluated because no implementation details, baselines, ablation studies, or error analysis are described, making it impossible to verify whether the dual-path plus iterative design actually preserves fine-grained semantics and structured associations jointly.
Authors: We agree abstracts cannot contain full implementation details, baselines, ablations or error analysis due to space limits. These are provided in Sections 4 and 5, including comparisons to single-path RAG variants, component ablations, and analysis showing joint preservation of semantics and structure. We will revise the abstract to name the benchmarks and note that ablations confirm the design's benefits. Full verification remains in the paper body, as expanding the abstract to include all requested elements is not feasible. revision: partial
Circularity Check
No significant circularity; method proposal is self-contained
full rationale
The paper presents a descriptive framework for Hybrid-IR combining graph-based and dense retrieval with an iterative retrieve-reason loop. No equations, fitted parameters, predictions derived from inputs, or self-citations appear in the abstract or described content. The central claims rest on experimental results on external benchmarks rather than any derivation that reduces to its own definitions or prior self-references. This is the common case of a non-circular systems paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
AI@Meta: Llama 3 model card (2024),https://github.com/meta-llama/llama3/ blob/main/MODEL_CARD.md
2024
-
[2]
arXiv preprint arXiv:2503.10677 (2025)
Cheng, M., Luo, Y., Ouyang, J., Liu, Q., Liu, H., Li, L., Yu, S., Zhang, B., Cao, J., Ma, J., et al.: A survey on knowledge-oriented retrieval-augmented generation. arXiv preprint arXiv:2503.10677 (2025)
arXiv 2025
-
[3]
In: Proceedings of the 32nd in- ternational ACM SIGIR conference on Research and development in information retrieval
Cormack, G.V., Clarke, C.L., Buettcher, S.: Reciprocal rank fusion outperforms condorcet and individual rank learning methods. In: Proceedings of the 32nd in- ternational ACM SIGIR conference on Research and development in information retrieval. pp. 758–759 (2009)
2009
-
[4]
arXiv preprint arXiv:2404.16130 (2024)
Edge, D., Trinh, H., Cheng, N., Bradley, J., Chao, A., Mody, A., Truitt, S., Metropolitansky, D., Ness, R.O., Larson, J.: From local to global: A graph rag approach to query-focused summarization. arXiv preprint arXiv:2404.16130 (2024)
Pith/arXiv arXiv 2024
-
[5]
arXiv preprint arXiv:2502.14802 (2025)
Gutiérrez, B.J., Shu, Y., Qi, W., Zhou, S., Su, Y.: From rag to memory: Non-parametric continual learning for large language models. arXiv preprint arXiv:2502.14802 (2025)
Pith/arXiv arXiv 2025
-
[6]
Plos one19(7), e0307383 (2024)
Hadi, A., Tran, E., Nagarajan, B., Kirpalani, A.: Evaluation of ChatGPT as a diagnostic tool for medical learners and clinicians. Plos one19(7), e0307383 (2024)
2024
-
[7]
arXiv preprint arXiv:2009.03300 (2020)
Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Stein- hardt, J.: Measuring massive multitask language understanding. arXiv preprint arXiv:2009.03300 (2020)
Pith/arXiv arXiv 2009
-
[8]
arXiv preprint arXiv:2112.09118 (2021)
Izacard, G., Caron, M., Hosseini, L., Riedel, S., Bojanowski, P., Joulin, A., Grave, E.: Unsupervised dense information retrieval with contrastive learning. arXiv preprint arXiv:2112.09118 (2021)
Pith/arXiv arXiv 2021
-
[9]
Advances in Neural Information Processing Systems37, 59532–59569 (2024)
Jimenez Gutierrez, B., Shu, Y., Gu, Y., Yasunaga, M., Su, Y.: Hipporag: Neu- robiologically inspired long-term memory for large language models. Advances in Neural Information Processing Systems37, 59532–59569 (2024)
2024
-
[10]
Applied Sciences11(14), 6421 (2021)
Jin, D., Pan, E., Oufattole, N., Weng, W.H., Fang, H., Szolovits, P.: What disease does this patient have? a large-scale open domain question answering dataset from medical exams. Applied Sciences11(14), 6421 (2021)
2021
-
[11]
Bioinformatics39(11), btad651 (2023)
Jin, Q., Kim, W., Chen, Q., Comeau, D.C., Yeganova, L., Wilbur, W.J., Lu, Z.: Medcpt: Contrastive pre-trained transformers with large-scale pubmed search logs for zero-shot biomedical information retrieval. Bioinformatics39(11), btad651 (2023)
2023
-
[12]
In: Proceed- ings of the 2020 conference on empirical methods in natural language processing (EMNLP)
Karpukhin, V., Oguz, B., Min, S., Lewis, P., Wu, L., Edunov, S., Chen, D., Yih, W.t.: Dense passage retrieval for open-domain question answering. In: Proceed- ings of the 2020 conference on empirical methods in natural language processing (EMNLP). pp. 6769–6781 (2020) 16 Sheng Wan et al
2020
-
[13]
In: Proceedings of the 43rd International ACM SIGIR conference on research and development in Information Retrieval
Khattab, O., Zaharia, M.: Colbert: Efficient and effective passage search via con- textualized late interaction over bert. In: Proceedings of the 43rd International ACM SIGIR conference on research and development in Information Retrieval. pp. 39–48 (2020)
2020
-
[14]
Advances in neural information processing systems 33, 9459–9474 (2020)
Lewis, P., Perez, E., Piktus, A., Petroni, F., Karpukhin, V., Goyal, N., Küttler, H., Lewis, M., Yih, W.t., Rocktäschel, T., et al.: Retrieval-augmented generation for knowledge-intensive nlp tasks. Advances in neural information processing systems 33, 9459–9474 (2020)
2020
-
[15]
In: Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers)
Li, Z., Guo, Q., Shao, J., Song, L., Bian, J., Zhang, J., Wang, R.: Graph neu- ral network enhanced retrieval for question answering of large language models. In: Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). pp. 6612–6633 (2025)
2025
-
[16]
In: International Conference on Machine Learning
Luo, L., Zhao, Z., Haffari, G., Li, Y.F., Gong, C., Pan, S.: Graph-constrained reasoning: Faithful reasoning on knowledge graphs with large language models. In: International Conference on Machine Learning. pp. 41540–41565. PMLR (2025)
2025
-
[17]
Advances in Neural Information Processing Systems38, 36371–36405 (2026)
Luo, L., Zhao, Z., Haffari, R., Phung, D., Gong, C., Pan, S.: Gfm-rag: graph foun- dation model for retrieval augmented generation. Advances in Neural Information Processing Systems38, 36371–36405 (2026)
2026
-
[18]
arXiv preprint arXiv:2509.24276 (2025)
Luo, L., Zhao, Z., Liu, J., Qiu, Z., Dong, J., Panev, S., Gong, C., Vu, T.T., Haffari, G., Phung, D., et al.: G-reasoner: Foundation models for unified reasoning over graph-structured knowledge. arXiv preprint arXiv:2509.24276 (2025)
Pith/arXiv arXiv 2025
-
[19]
In: Findings of the Association for Computational Linguistics: ACL 2025
Mavromatis, C., Karypis, G.: Gnn-rag: Graph neural retrieval for efficient large language model reasoning on knowledge graphs. In: Findings of the Association for Computational Linguistics: ACL 2025. pp. 16682–16699 (2025)
2025
-
[20]
OpenAI: Hello GPT-4o (May 2024),https://openai.com/index/hello-gpt-4o/
2024
-
[21]
Findings of the association for computational linguistics: EMNLP 2024 pp
Pai, L., Gao, W., Dong, W., Ai, L., Gong, Z., Huang, S., Zongsheng, L., Hoque, E., Hirschberg, J., Zhang, Y.: A survey on open information extraction from rule- based model to large language model. Findings of the association for computational linguistics: EMNLP 2024 pp. 9586–9608 (2024)
2024
-
[22]
In: Conference on health, inference, and learning
Pal, A., Umapathi, L.K., Sankarasubbu, M.: Medmcqa: A large-scale multi-subject multi-choice dataset for medical domain question answering. In: Conference on health, inference, and learning. pp. 248–260. PMLR (2022)
2022
-
[23]
ACM Transactions on Information Sys- tems44(2), 1–52 (2025)
Peng, B., Zhu, Y., Liu, Y., Bo, X., Shi, H., Hong, C., Zhang, Y., Tang, S.: Graph retrieval-augmented generation: A survey. ACM Transactions on Information Sys- tems44(2), 1–52 (2025)
2025
-
[24]
In: The Twelfth International Conference on Learning Representations (2024)
Sarthi, P., Abdullah, S., Tuli, A., Khanna, S., Goldie, A., Manning, C.D.: Rap- tor: Recursive abstractive processing for tree-organized retrieval. In: The Twelfth International Conference on Learning Representations (2024)
2024
-
[25]
Nature medicine31(3), 943–950 (2025)
Singhal, K., Tu, T., Gottweis, J., Sayres, R., Wulczyn, E., Amin, M., Hou, L., Clark, K., Pfohl, S.R., Cole-Lewis, H., et al.: Toward expert-level medical question answering with large language models. Nature medicine31(3), 943–950 (2025)
2025
-
[26]
arXiv preprint arXiv:2411.00300 (2024)
Sohn, J., Park, Y., Yoon, C., Park, S., Hwang, H., Sung, M., Kim, H., Kang, J.: Rationale-guided retrieval augmented generation for medical question answering. arXiv preprint arXiv:2411.00300 (2024)
arXiv 2024
-
[27]
arXiv preprint arXiv:2504.08690 (2025)
Sun, Y., Zhang, Y., Zhao, Z., Wan, S., Tao, D., Gong, C.: Fast-slow-thinking: Complex task solving with large language models. arXiv preprint arXiv:2504.08690 (2025)
arXiv 2025
-
[28]
In: Findings of the Association for Computational Linguis- tics: ACL 2025
Sun, Y., Zhao, Z., Wan, S., Gong, C.: Cortexdebate: Debating sparsely and equally for multi-agent debate. In: Findings of the Association for Computational Linguis- tics: ACL 2025. pp. 9503–9523 (2025) Hybrid Retrieval with Iterative Reasoning for Complex Medical QA 17
2025
-
[29]
In: Proceedings of the 61st annual meeting of the association for computational lin- guistics (volume 1: long papers)
Trivedi, H., Balasubramanian, N., Khot, T., Sabharwal, A.: Interleaving retrieval with chain-of-thought reasoning for knowledge-intensive multi-step questions. In: Proceedings of the 61st annual meeting of the association for computational lin- guistics (volume 1: long papers). pp. 10014–10037 (2023)
2023
-
[30]
USMLE Committee: United states medical licensing examination (usmle).https: //www.usmle.org/(2026)
2026
-
[31]
Pattern Recognition179, 113714 (2026)
Wan, S., Ren, S., Zhao, Z., Zhu, Y., Gong, C.: Ners: Negative relational smoothing for graph contrastive learning. Pattern Recognition179, 113714 (2026)
2026
-
[32]
Neural Networks199, 108749 (2026)
Wan, S., Zhan, Y., Pan, S., Yang, J., Gong, C.: Contrastive knowledge embedding with discriminative self-weighted sampling. Neural Networks199, 108749 (2026)
2026
-
[33]
In: Proceedings of the AAAI conference on artificial intelligence
Wang, Y., Lipka, N., Rossi, R.A., Siu, A., Zhang, R., Derr, T.: Knowledge graph prompting for multi-document question answering. In: Proceedings of the AAAI conference on artificial intelligence. vol. 38, pp. 19206–19214 (2024)
2024
-
[34]
In: Proceedings of the 63rd Annual Meeting of the Asso- ciation for Computational Linguistics (Volume 1: Long Papers)
Wu, J., Zhu, J., Qi, Y., Chen, J., Xu, M., Menolascina, F., Jin, Y., Grau, V.: Med- ical graph rag: Evidence-based medical large language model via graph retrieval- augmented generation. In: Proceedings of the 63rd Annual Meeting of the Asso- ciation for Computational Linguistics (Volume 1: Long Papers). pp. 28443–28467 (2025)
2025
-
[35]
IEEE transactions on neural networks and learning systems32(1), 4–24 (2020)
Wu, Z., Pan, S., Chen, F., Long, G., Zhang, C., Yu, P.S.: A comprehensive survey on graph neural networks. IEEE transactions on neural networks and learning systems32(1), 4–24 (2020)
2020
-
[36]
In: Findings of the Association for Computational Linguistics ACL 2024
Xiong, G., Jin, Q., Lu, Z., Zhang, A.: Benchmarking retrieval-augmented gener- ation for medicine. In: Findings of the Association for Computational Linguistics ACL 2024. pp. 6233–6251 (2024)
2024
-
[37]
In: Biocom- puting 2025: Proceedings of the Pacific Symposium
Xiong, G., Jin, Q., Wang, X., Zhang, M., Lu, Z., Zhang, A.: Improving retrieval- augmented generation in medicine with iterative follow-up questions. In: Biocom- puting 2025: Proceedings of the Pacific Symposium. pp. 199–214. World Scientific (2024)
2025
-
[38]
arXiv preprint arXiv:2505.09388 (2025)
Yang, A., Li, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Gao, C., Huang, C., Lv, C., et al.: Qwen3 technical report. arXiv preprint arXiv:2505.09388 (2025)
Pith/arXiv arXiv 2025
-
[39]
In: Joint European conference on machine learning and knowl- edge discovery in databases
Zhao, Z., Luo, L., Pan, S., Nguyen, Q.V.H., Gong, C.: Towards few-shot inductive link prediction on knowledge graphs: A relational anonymous walk-guided neural process approach. In: Joint European conference on machine learning and knowl- edge discovery in databases. pp. 515–532. Springer (2023)
2023
-
[40]
ACM Transactions on Intelligent Systems and Technology17(1), 1–23 (2025)
Zhao, Z., Luo, L., Pan, S., Zhang, C., Gong, C.: Graph stochastic neural process for inductive few-shot knowledge graph completion. ACM Transactions on Intelligent Systems and Technology17(1), 1–23 (2025)
2025
-
[41]
arXiv preprint arXiv:2205.11725 (2022)
Zhou, S., Yu, B., Sun, A., Long, C., Li, J., Yu, H., Sun, J., Li, Y.: A survey on neural open information extraction: Current status and future directions. arXiv preprint arXiv:2205.11725 (2022)
arXiv 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.