MAAT: Multi-phase Adapter-Aware Targeted Unlearning
Pith reviewed 2026-06-29 08:14 UTC · model grok-4.3
The pith
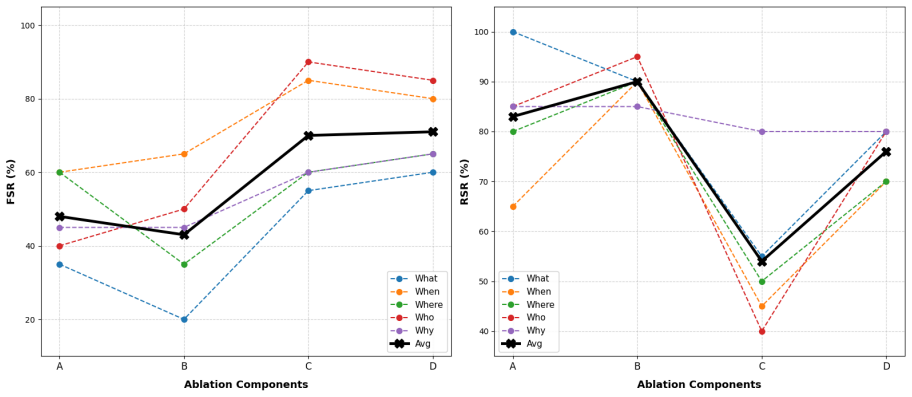
MAAT is the first unlearning method to achieve both high forgetting and high retention on Why-type causal knowledge.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
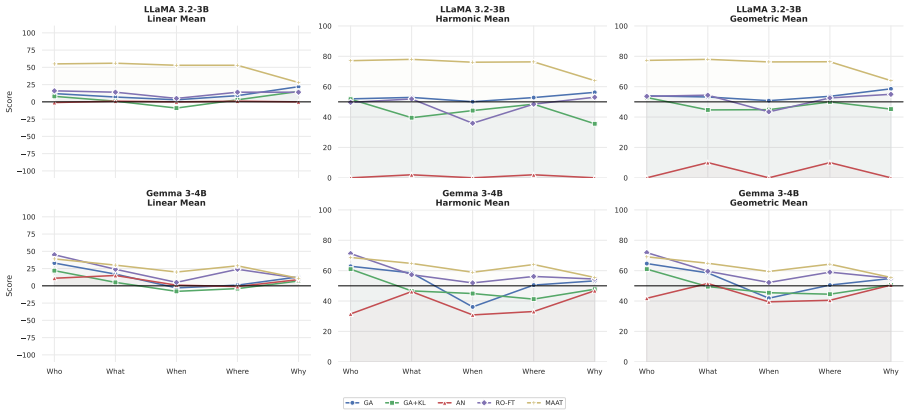
No existing baseline simultaneously achieves high forgetting and high retention on Why-type questions because of multi-hop reasoning chains and long answer spans; MAAT, a three-phase framework operating on LoRA adapter weights that combines gradient-projected ascent, SVD rank-dimension pruning, task vector negation, and hybrid KL-hidden-state retain repair, is the first method to do so and reaches a new operating point on the forget-retain Pareto frontier.
What carries the argument
Three-phase framework on LoRA adapter weights that combines gradient-projected ascent, SVD rank-dimension pruning, task vector negation, and hybrid KL-hidden-state retain repair.
If this is right
- Why-type causal knowledge can now be evaluated separately from easier factual recall in unlearning tasks.
- Multi-hop reasoning chains in answers become targets that can be removed without broad degradation of retained knowledge.
- Adapter-weight operations allow targeted changes that avoid the full retraining cost of other unlearning approaches.
- A measurable new point exists on the forget-retain frontier that prior single-phase methods could not reach.
- Causal facts can be unlearned while preserving performance on non-causal question types.
Where Pith is reading between the lines
- The same phased adapter process could be tested on other adapter types or full fine-tuning to see if the balance holds without LoRA.
- If the method generalizes, it would allow safer removal of harmful causal associations in deployed models without retraining from scratch.
- Extending the 5W benchmark to include longer reasoning chains or cross-domain Why questions would test whether the reported gains persist.
Load-bearing premise
The three-phase combination on LoRA weights will produce the claimed balance on Why-type questions beyond the specific models and data splits used.
What would settle it
A new experiment on a different model or dataset in which MAAT fails to achieve both high forgetting and high retention on Why-type questions.
Figures

read the original abstract
Machine unlearning evaluation is structurally skewed: Why-type questions, which probe causal and relational knowledge, comprise less than 0.06% of CounterFact, 0.6% of ZSRE, and less than 1.3% of TOFU, MUSE, and WMDP-Cyber. This near-zero representation means that methods that fail on causal knowledge can score highly in aggregate, and this failure is undetectable without balanced evaluation. We present 5WBENCH, a balanced 5,000-sample benchmark with 1,000 examples per 5W category (Who, What, When, Where, Why), making causal unlearning failures quantifiable for the first time. Using 5WBENCH, we show that no existing baseline simultaneously achieves high forgetting and high retention on Why-type questions: aggressive forgetting degrades retained knowledge, while conservative methods fail to forget causal facts. Why-type difficulty stems from multi-hop reasoning chains (44% of Why entries vs. less than or equal to 2% for others) and gradient dilution over 40.1-token answer spans. We present MAAT (Multi-phase Adapter-Aware Targeted Unlearning), a three-phase framework operating on LoRA adapter weights, combining gradient-projected ascent, SVD rank-dimension pruning, task vector negation, and hybrid KL-hidden-state retain repair. MAAT is the first method to simultaneously achieve high forgetting and high retention on Why-type causal knowledge, reaching a new operating point on the forget-retain Pareto frontier. We make our code publicly available.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper argues that existing machine unlearning benchmarks severely underrepresent Why-type causal questions (less than 0.06% in CounterFact, etc.), introduces the balanced 5WBENCH benchmark with 1,000 examples per 5W category, demonstrates that no prior method achieves both high forgetting and high retention on Why-type entries due to multi-hop chains and gradient dilution, and proposes MAAT, a three-phase LoRA adapter method combining gradient-projected ascent, SVD rank pruning, task vector negation, and hybrid KL retain repair, claiming it is the first to reach a new operating point on the forget-retain Pareto frontier for causal knowledge. Code is released publicly.
Significance. If the experimental claims hold, the work would be significant for exposing and addressing a structural gap in unlearning evaluation on causal reasoning, with the new benchmark enabling quantifiable assessment of failures on Why-type questions. The public code release supports reproducibility. The central result on advancing the Pareto frontier for multi-hop causal unlearning would be of interest if the three-phase interactions are shown to generalize.
major comments (3)
- [§3] §3 (MAAT three-phase framework): The claim that the specific ordering of gradient-projected ascent, SVD rank-dimension pruning, task vector negation, and hybrid KL-hidden-state repair overcomes gradient dilution on 40.1-token multi-hop Why answers is load-bearing for the Pareto-frontier advance, yet no derivation, interaction analysis, or equations are supplied showing why this sequence succeeds where single-phase baselines fail.
- [§5] §5 (Experimental results on 5WBENCH): The superiority of MAAT on Why-type entries (44% multi-hop) is asserted without ablation tables isolating the contribution of each phase or the effect of phase ordering; this prevents verification that the reported balance is due to the proposed combination rather than benchmark-specific tuning.
- [Table in §5] Table reporting Why-type forget/retain metrics: No error bars, multiple random seeds, or statistical tests are mentioned for the claimed new operating point, weakening the robustness of the central performance claim relative to baselines.
minor comments (2)
- [Abstract] The abstract states 'less than or equal to 2%' for other categories; consistent use of inequality symbols or exact percentages would improve readability.
- [§2] The description of 5WBENCH construction would benefit from a brief example of a Why-type multi-hop question in the main text to illustrate the 40.1-token span issue.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting areas where the MAAT framework and experimental claims require stronger justification and validation. We address each major comment below and will revise the manuscript to incorporate the suggested improvements.
read point-by-point responses
-
Referee: [§3] §3 (MAAT three-phase framework): The claim that the specific ordering of gradient-projected ascent, SVD rank-dimension pruning, task vector negation, and hybrid KL-hidden-state repair overcomes gradient dilution on 40.1-token multi-hop Why answers is load-bearing for the Pareto-frontier advance, yet no derivation, interaction analysis, or equations are supplied showing why this sequence succeeds where single-phase baselines fail.
Authors: We agree that the manuscript would benefit from explicit justification of the phase ordering. In the revision we will add a dedicated analysis subsection to §3 that provides the interaction rationale: gradient-projected ascent first identifies and amplifies the causal directions in the adapter weights, SVD rank pruning then removes low-magnitude dimensions that would otherwise dilute the update across the long 40.1-token spans, task-vector negation inverts the retained direction, and the hybrid KL-hidden-state repair restores multi-hop consistency on the retain set. We will include the corresponding update equations and a small set of interaction plots comparing the proposed sequence against single-phase and reordered variants. revision: yes
-
Referee: [§5] §5 (Experimental results on 5WBENCH): The superiority of MAAT on Why-type entries (44% multi-hop) is asserted without ablation tables isolating the contribution of each phase or the effect of phase ordering; this prevents verification that the reported balance is due to the proposed combination rather than benchmark-specific tuning.
Authors: We accept that the current version lacks the necessary ablations. The revised §5 will contain a new ablation table that reports Why-type forget and retain scores after (i) ablating each phase individually and (ii) testing all six possible phase permutations. These results will quantify the incremental contribution of each component and confirm that the reported operating point is attributable to the specific three-phase combination rather than incidental tuning. revision: yes
-
Referee: [Table in §5] Table reporting Why-type forget/retain metrics: No error bars, multiple random seeds, or statistical tests are mentioned for the claimed new operating point, weakening the robustness of the central performance claim relative to baselines.
Authors: We will revise the table in §5 to report means and standard deviations computed over five independent random seeds. In addition, we will add pairwise statistical significance tests (Wilcoxon signed-rank) between MAAT and each baseline, with p-values reported in the table caption or a supplementary note. This will provide the requested evidence of robustness for the claimed Pareto-frontier advance. revision: yes
Circularity Check
No circularity: empirical method combination with no self-referential derivations
full rationale
The paper presents MAAT as an engineering combination of existing techniques (gradient-projected ascent, SVD rank pruning, task vector negation, hybrid KL repair) applied in three phases to LoRA weights, evaluated on a newly introduced benchmark 5WBENCH. No equations, derivations, or parameter-fitting steps are described in the provided text that reduce by construction to the inputs. Claims of Pareto-frontier improvement are empirical and benchmark-specific rather than derived from self-definitions or self-citations. The derivation chain is self-contained as a proposed practical framework without load-bearing reductions to fitted values or prior author results.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Jack Foster, Stefan Schoepf, and Alexandra Brintrup
Alphaedit: Null-space constrained knowledge editing for language models.CoRR, abs/2410.02355. Jack Foster, Stefan Schoepf, and Alexandra Brintrup
-
[2]
Phillip Guo, Aaquib Syed, Abhay Sheshadri, Aidan Ewart, and Gintare Karolina Dziugaite
Fast machine unlearning without retrain- ing through selective synaptic dampening.CoRR, abs/2308.07707. Phillip Guo, Aaquib Syed, Abhay Sheshadri, Aidan Ewart, and Gintare Karolina Dziugaite. 2024. Mech- anistic unlearning: Robust knowledge unlearning and editing via mechanistic localization.CoRR, abs/2410.12949. Edward J. Hu, Yelong Shen, Phillip Wallis,...
-
[3]
Wenyue Hua, Jiang Guo, Mingwen Dong, Henghui Zhu, Patrick Ng, and Zhiguo Wang
OpenReview.net. Wenyue Hua, Jiang Guo, Mingwen Dong, Henghui Zhu, Patrick Ng, and Zhiguo Wang. 2024. Propagation and pitfalls: Reasoning-based assessment of knowl- edge editing through counterfactual tasks.CoRR, abs/2401.17585. Gabriel Ilharco, Marco Túlio Ribeiro, Mitchell Worts- man, Suchin Gururangan, Ludwig Schmidt, Han- naneh Hajishirzi, and Ali Farh...
-
[4]
MUSE: machine unlearning six-way evalua- tion for language models.CoRR, abs/2407.06460. Gemma Team. 2024a. Gemma: Open models based on gemini research and technology.CoRR, abs/2403.08295. Llama Team. 2024b. The llama 3 herd of models. CoRR, abs/2407.21783. Pratiksha Thaker, Shengyuan Hu, Neil Kale, Yash Mau- rya, Zhiwei Steven Wu, and Virginia Smith. 2024...
-
[5]
Negative Preference Optimization: From Catastrophic Collapse to Effective Unlearning
Negative preference optimization: From catastrophic collapse to effective unlearning.CoRR, abs/2404.05868. Zhihua Zhang. 2015. The singular value decomposition, applications and beyond.CoRR, abs/1510.08532. Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric P. Xing, Hao Zhang, Joseph...
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[6]
Focus ONLY on whether the ground truth is present—ignore any extra or wrong information in the model answer
-
[7]
Monday evening
Semantic/paraphrase matches count (e.g. “Monday evening” = “Monday night”)
-
[8]
Partial containment counts if the core fact is present
-
[9]
For “why” questions: the core causal reason must be present, not just surface word overlap
-
[10]
contains_ground_truth
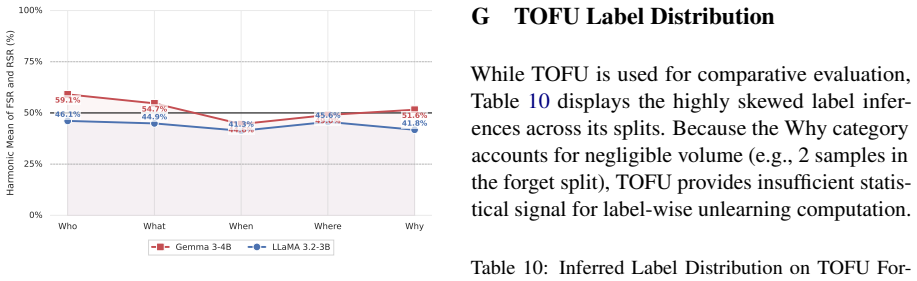
Case-insensitive matching. Respond ONLY with one of: {"contains_ground_truth": true} {"contains_ground_truth": false} I Qualitative Examples: Why-Type Unlearning Tables 11 and 12 show representative generation traces from Llama 3.2-3B onWhy-type evalua- tion samples, illustrating how each method handles causal knowledge on the forget and retain splits. Fo...
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.