Test-Input Generation for Tensor Programs: What Actually Finds Kernel Bugs
Pith reviewed 2026-06-29 01:57 UTC · model grok-4.3
The pith
Boundary-only shape sampling detects 78% of seeded tensor kernel bugs with zero false positives on correct kernels.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
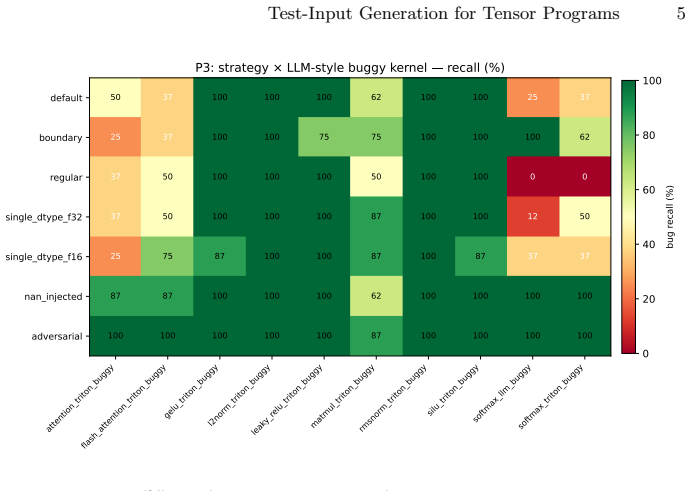
Through systematic evaluation of test input generation strategies on a 26-operation corpus, boundary-only shape sampling achieves 78% recall on the 10 buggy kernels while maintaining a 0% false-positive rate on the 16 correct controls. Adversarial value sampling reaches 99% recall but inflates the false-positive rate to 94% because the validator's checks on NaN and Inf propagation fire on both buggy and correct kernels. On the two softmax tail-mask bugs, the strategy without boundary shapes catches zero instances, whereas boundary shapes raise recall to 100% and 62% respectively. The results concern which seeded transcription patterns each strategy detects rather than overall bug rates in de
What carries the argument
Comparison of seven test-generation strategies that vary the shape candidate set, dtype mix, and input value distribution, with performance measured by bug recall against controls and false-positive rate.
If this is right
- Boundary-only shape sampling serves as an operationally safe default for test input generation that avoids false alarms while still detecting most seeded transcription errors.
- Regular shape sampling without boundaries misses all instances of the two softmax tail-mask bugs examined.
- Adversarial value sampling increases recall but produces high false-positive rates when validators check for NaN and Inf propagation.
- Shape sampling choice has larger impact on detection of specific bug patterns than dtype mix or value distribution alone.
- Test strategies must be evaluated jointly with the validator's treatment of special values to avoid inflated false-positive rates.
Where Pith is reading between the lines
- Tensor framework maintainers could adopt boundary shape sampling as a default in their validation pipelines to reduce missed bugs without added noise from false positives.
- The performance gap on softmax bugs indicates that boundary conditions are especially important for operations involving masks or tail elements.
- Future work could test whether the same strategy rankings hold when the validator uses different methods for handling NaN and Inf values.
- Extending the evaluation corpus beyond seeded transcription patterns to include bugs found in actual user reports would test how well the findings generalize.
Load-bearing premise
The 10 LLM-style buggy variants seeded with documented transcription patterns are representative of the bug types that matter in practice, and observed recall differences are driven by the test strategies rather than validator handling of NaN and Inf.
What would settle it
Applying the same seven strategies to a larger collection of real, reported tensor kernel bugs from production code and checking whether boundary-only sampling maintains 78% or higher recall with zero false positives on correct implementations.
Figures
read the original abstract
Test-input generation for tensor kernels is folkloric. Most projects pick a representative shape and dtype, run a fixed-shape allclose-style check, and ship. We make the choices explicit and measure them. Using the gpuemu op-schema-aware seeded fuzzer (arXiv:2606.20128), we evaluate seven test-generation strategies across a 26-op corpus (16 correct controls and 10 LLM-style buggy variants seeded with documented transcription patterns) on an RTX 3060 GPU instance. Strategies vary the shape candidate set, the dtype mix, and the input value distribution. We report each strategy on two axes: bug recall and control false-positive (FP) rate. Boundary-only shape sampling is the operationally safe winner: 78% recall on the 10 buggy kernels with 0% FP on the 16 controls. Adversarial value sampling reaches higher recall (99%) but inflates control FP to 94% because the strategy injects NaN and Inf inputs and the validator's NaN check fires on every kernel that propagates them, not only on buggy kernels. On the two softmax tail-mask bugs the "regular" strategy (no boundary shapes) catches 0%, while boundary raises recall to 100% and 62% respectively. That gap is the clearest single signal in the data. The corpus result is about which seeded bug patterns each strategy catches, not about the bug rate of any specific deployed LLM.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper evaluates seven test-input generation strategies for tensor kernels via the gpuemu seeded fuzzer on a 26-op corpus (16 correct controls + 10 LLM-style buggy variants created by seeding documented transcription patterns). Strategies differ in shape candidate sets, dtype mix, and value distributions. Results are reported as bug recall and control FP rate. Boundary-only shape sampling is presented as the operationally safe winner (78% recall, 0% FP), while adversarial sampling reaches 99% recall but 94% FP due to NaN/Inf propagation triggering the validator on controls. Specific gaps are noted for softmax tail-mask bugs where boundary shapes raise recall from 0% to 100%/62%. The manuscript explicitly states that the corpus results concern which seeded patterns each strategy catches, not real bug rates in deployed LLMs.
Significance. If the seeded patterns prove representative of practically relevant kernel bugs, the work supplies concrete, reproducible empirical data on the trade-offs among shape, dtype, and value strategies, including a clear demonstration that boundary shapes catch certain transcription bugs missed by regular sampling. The explicit two-axis measurement (recall vs. FP) and use of an op-schema-aware fuzzer constitute a strength that can guide testing practice even if the absolute numbers are corpus-specific.
major comments (2)
- [Abstract] Abstract: The headline claim that boundary-only shape sampling is the 'operationally safe winner' is load-bearing, yet the evaluation is performed exclusively on 10 artificially seeded LLM transcription bugs. The manuscript itself notes that results address which seeded patterns are caught rather than real bug rates; without additional evidence that these patterns are representative of the bug types that matter in practice, the operational-safety interpretation is not fully supported by the data.
- [Abstract] Abstract (and methods description of the validator): The 94% FP rate for adversarial sampling is attributed to the validator's NaN check firing on controls that propagate NaN/Inf. No details are supplied on the exact implementation of that NaN/Inf check, the precise shape candidate sets used for each strategy, or any statistical significance assessment of the recall differences (e.g., the softmax tail-mask cases). Because validator mechanics are already shown to affect the metrics, these omissions prevent readers from determining whether observed gaps are driven by the shape strategy itself.
minor comments (1)
- The manuscript would benefit from an explicit limitations subsection that restates the synthetic nature of the corpus and the dependence on the validator implementation, even if the current abstract caveat is retained.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below, proposing revisions to clarify scope and add missing details where feasible. The manuscript already qualifies its claims as applying to the seeded patterns rather than real-world rates.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline claim that boundary-only shape sampling is the 'operationally safe winner' is load-bearing, yet the evaluation is performed exclusively on 10 artificially seeded LLM transcription bugs. The manuscript itself notes that results address which seeded patterns are caught rather than real bug rates; without additional evidence that these patterns are representative of the bug types that matter in practice, the operational-safety interpretation is not fully supported by the data.
Authors: We agree the evaluation uses 10 seeded bugs derived from documented transcription patterns, and the manuscript already states explicitly that results concern which seeded patterns each strategy catches rather than real bug rates in deployed LLMs. The 'operationally safe winner' label rests on the empirical 78% recall paired with 0% FP rate on the 16 correct controls in this corpus. To prevent overinterpretation, we will revise the abstract to qualify the claim more explicitly as applying to these seeded patterns (representative of common LLM transcription errors) rather than implying general operational safety across all possible bugs. This revision maintains the data-driven observation while addressing the concern. revision: partial
-
Referee: [Abstract] Abstract (and methods description of the validator): The 94% FP rate for adversarial sampling is attributed to the validator's NaN check firing on controls that propagate NaN/Inf. No details are supplied on the exact implementation of that NaN/Inf check, the precise shape candidate sets used for each strategy, or any statistical significance assessment of the recall differences (e.g., the softmax tail-mask cases). Because validator mechanics are already shown to affect the metrics, these omissions prevent readers from determining whether observed gaps are driven by the shape strategy itself.
Authors: We will expand the methods section to describe the validator's NaN/Inf check (any output containing NaN or Inf is flagged) and provide the exact shape candidate sets for each strategy (boundary shapes use edge values such as 0, 1, and maximum dimensions per the op schema; regular shapes use typical schema values). For the recall differences, including the softmax tail-mask cases (0% to 100% and 62%), we report descriptive rates given the small corpus; no statistical significance tests were performed. These additions will allow readers to evaluate the contribution of each component. revision: yes
Circularity Check
No circularity: empirical measurement on fixed corpus
full rationale
The paper reports direct measurements of bug recall and control FP rates across seven test-generation strategies on a corpus of 16 correct kernels and 10 seeded buggy variants. No equations, fitted parameters, predictions derived from inputs, or self-referential definitions appear in the provided text. The central claims are observational counts (78% recall, 0% FP for boundary sampling) obtained by running the strategies and validator on the corpus; these do not reduce to the inputs by construction. The cited prior arXiv:2606.20128 supplies the fuzzer tool but is not used to derive the reported metrics. This is a standard empirical evaluation study with no load-bearing self-citation chains or ansatz smuggling.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The 10 seeded buggy variants with documented transcription patterns are representative of bugs that occur when LLMs generate tensor kernels
- domain assumption The validator's NaN/Inf check fires on propagation behavior rather than on kernel correctness
Reference graph
Works this paper leans on
-
[1]
Deng, Y., Yang, C., Wei, A., Zhang, L.: Fuzzing deep-learning libraries via au- tomated relational API inference. In: Proc. 30th ACM Joint Eur. Softw. Eng. Conf. and Symp. Found. Softw. Eng. (ESEC/FSE). pp. 44–56 (2022). https: //doi.org/10.1145/3540250.3549085
-
[2]
arXiv preprint (2025), https://arxiv.org/abs/2510.16996
Dong, J., Yang, Y., Liu, T., Wang, Y., Qi, F., Tarokh, V., Rangadurai, K., Yang, S.: STARK: Strategic team of agents for refining kernels. arXiv preprint (2025), https://arxiv.org/abs/2510.16996
arXiv 2025
-
[3]
Wiley (1979)
Myers, G.J.: The Art of Software Testing. Wiley (1979)
1979
-
[4]
Ouyang, A., Guo, S., Arora, S., Zhang, A.L., Hu, W., R´ e, C., Mirhoseini, A.: KernelBench: Can LLMs write efficient GPU kernels? arXiv preprint (2025), https: //arxiv.org/abs/2502.10517
Pith/arXiv arXiv 2025
-
[5]
arXiv preprint (2025),https://arxiv.org/abs/2509.14626
Qin, F., Naziri, M.M.A., Ai, H., Dutta, S., d’Amorim, M.: Evaluating the effec- tiveness of coverage-guided fuzzing for testing deep learning library APIs. arXiv preprint (2025),https://arxiv.org/abs/2509.14626
arXiv 2025
-
[6]
arXiv preprint (2025), https://arxiv.org/ abs/2511.18868 8 D
Ran, D., Xie, S., Ji, M., Liu, A., Wu, M., Cao, Y., Guo, Y., Yu, H., Li, L., Hu, Y., Yang, W., Xie, T.: KernelBand: Steering LLM-based kernel optimization via hardware-aware multi-armed bandits. arXiv preprint (2025), https://arxiv.org/ abs/2511.18868 8 D. Sarkar
arXiv 2025
-
[7]
arXiv preprint (2026),https://arxiv.org/abs/2606.20128
Sarkar, D.: The correctness illusion in LLM-generated GPU kernels. arXiv preprint (2026),https://arxiv.org/abs/2606.20128
Pith/arXiv arXiv 2026
-
[8]
Draft source at https://github.com/sarkar-d ipankar/gpuemu-arxiv-paper/tree/main/p2
Sarkar, D.: Operator-aware mixed-precision tolerance calibration for tensor kernels (2026), manuscript in preparation. Draft source at https://github.com/sarkar-d ipankar/gpuemu-arxiv-paper/tree/main/p2
2026
-
[9]
arXiv preprint (2026),https://arxiv.org/abs/2605.04956
Wang, H., Zhang, J., Jiang, K., Wang, H., Chen, J., Zhu, J.: KernelBenchX: A comprehensive benchmark for evaluating LLM-generated GPU kernels. arXiv preprint (2026),https://arxiv.org/abs/2605.04956
Pith/arXiv arXiv 2026
-
[10]
arXiv preprint (2025),https://arxiv.org/abs/2507.23194
Wang, J., Joshi, V., Majumder, S., Xu Chao, Ding, B., Liu, Z., Brahma, P.P., Li, D., Liu, Z., Barsoum, E.: GEAK: Introducing Triton kernel AI agent & evaluation benchmarks. arXiv preprint (2025),https://arxiv.org/abs/2507.23194
arXiv 2025
-
[11]
Wei, A., Deng, Y., Yang, C., Zhang, L.: Free lunch for testing: Fuzzing deep- learning libraries from open source. In: Proc. 44th Int. Conf. Software Engineering (ICSE). pp. 995–1007 (2022). https://doi.org/10.1145/3510003.3510041 , https://arxiv.org/abs/2201.06589
-
[12]
Xie, D., Li, Y., Kim, M., Pham, H.V., Tan, L., Zhang, X., Godfrey, M.W.: DocTer: Documentation-guided fuzzing for testing deep learning API functions. In: Proc. 31st ACM SIGSOFT Int. Symp. Software Testing and Analysis (ISSTA). pp. 176– 188 (2022). https://doi.org/10.1145/3533767.3534220 , https://arxiv.org/ abs/2109.01002
-
[13]
Automated program repair in the era of large pre- trained language models
Yang, C., Deng, Y., Yao, J., Tu, Y., Li, H., Zhang, L.: Fuzzing automatic differen- tiation in deep-learning libraries. In: Proc. 45th Int. Conf. Software Engineering (ICSE). pp. 1174–1186 (2023). https://doi.org/10.1109/ICSE48619.2023.00105, https://arxiv.org/abs/2302.04351
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.