Iterate Until Retrieved: Factual Nugget Optimization for Discoverable Continual Corrections in Agentic RAG
Pith reviewed 2026-06-29 22:12 UTC · model grok-4.3
The pith
Factual corrections from free-form feedback become discoverable after iterative revision with the production RAG agent.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
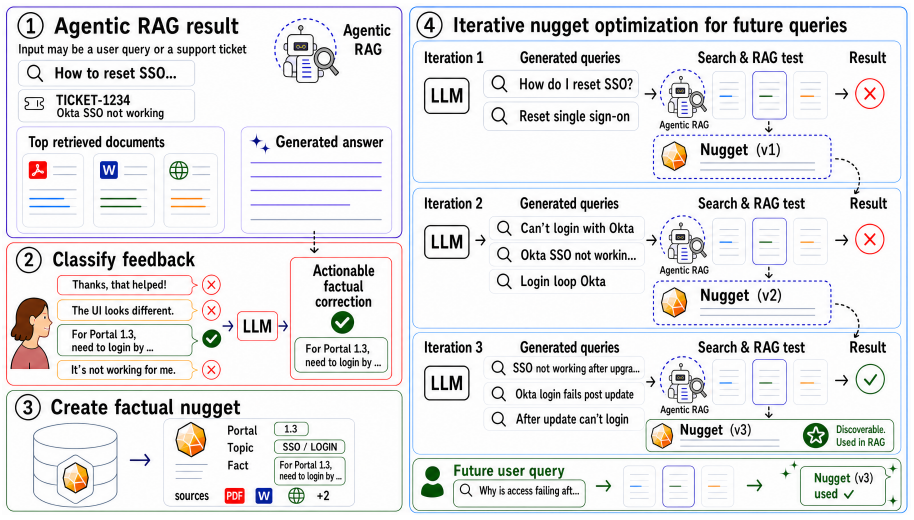
Iterative Nugget Optimization (INO) converts factual corrections into nuggets, then repeatedly probes them with the production agentic RAG on the triggering query and paraphrases, reflects on retrieval and answer failures, and revises the nugget until it is discoverable and produces correct answers.
What carries the argument
Iterative Nugget Optimization (INO), the index-time loop that uses the production agent itself as a test harness to probe, reflect on, and revise factual nuggets until retrieval succeeds.
If this is right
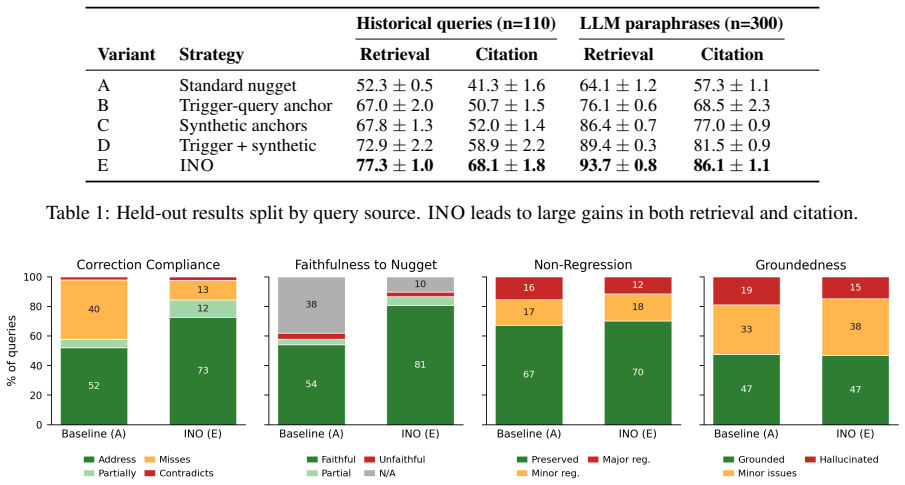
- Optimized nuggets achieve higher discoverability than static baselines in both automated and human evaluations.
- The factual corrections appear more often in the answers generated by the agent.
- The gains hold for both a product-support agent and a support-ticket agent across multiple companies.
- The same production agent can serve as its own optimization harness without external tools.
Where Pith is reading between the lines
- This loop could reduce manual maintenance of knowledge bases if corrections arrive continuously.
- The approach might be extended to style or preference feedback if the nugget conversion step is adapted.
- Running the optimization on live traffic rather than offline queries could surface different failure modes.
Load-bearing premise
Factual corrections from free-form feedback can be turned into compact nuggets whose discoverability can be improved by iterative probing and revision with the same agent without introducing bias or overfitting to the test queries.
What would settle it
A test on corrections from a held-out company where nuggets after INO show no gain or a loss in retrieval rate and answer correctness compared with the initial nuggets on fresh queries.
Figures

read the original abstract
Agentic retrieval-augmented generation (RAG) systems in complex B2B (business-to-business) settings may often receive free-form response feedback. Rather than generic feedback signals such as style, preference, or overall response quality, we focus on actionable factual corrections. We identify these instances and convert them into compact knowledge-base entries, which we call factual nuggets. We introduce Iterative Nugget Optimization (INO), an index-time optimization method that uses the production agentic RAG as a test harness: it creates an initial nugget, probes it with the triggering query and paraphrases, reflects over failed retrieval and answer traces, and revises the nugget until it is discoverable. We evaluate INO with two production B2B knowledge-assistance agents across multiple companies that use our system: a product support agent that answers questions over company-specific knowledge bases, and a support ticket agent that assists support engineers. INO consistently improves results over baselines in terms of discoverability and usage of factual corrections, in automated and human evaluations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Iterative Nugget Optimization (INO), an index-time procedure that converts free-form factual corrections into compact 'factual nuggets,' then uses the production agentic RAG system itself as a test harness: an initial nugget is created, probed with the triggering query plus paraphrases, and iteratively revised on the basis of failed retrieval/answer traces until the nugget becomes discoverable. The authors report that INO yields consistent gains over baselines in discoverability and usage of the corrections, measured by both automated metrics and human evaluation, across two production B2B agents (product-support and ticket-assistance).
Significance. If the central claim survives a properly controlled evaluation, INO would constitute a practical, agent-driven mechanism for continual knowledge-base maintenance that directly exploits the retrieval idiosyncrasies of the deployed system, potentially reducing manual curation overhead in complex B2B settings.
major comments (2)
- [Evaluation] Evaluation section: the optimization loop is driven by the exact triggering queries (and their paraphrases) that produced the original feedback. No description is given of a held-out query split or a generalization test on new feedback; therefore the reported gains in discoverability may be an artifact of closed-loop tuning to the evaluation queries rather than a genuine improvement in nugget quality.
- [Abstract and §4] Abstract and §4 (results): the claim of 'consistent improvements' is asserted without any reported baseline definitions, concrete metrics, number of test cases, or statistical significance tests. This absence prevents assessment of whether the data actually support the central claim.
minor comments (2)
- [Introduction] The term 'factual nugget' is introduced without a precise operational definition or comparison to related constructs (e.g., atomic facts, knowledge snippets) already present in the RAG literature.
- [Method] Notation for the iterative revision step (probe-reflect-revise) is described only in prose; a compact pseudocode or state-transition diagram would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the evaluation design and the clarity of our experimental reporting. These observations identify areas where additional detail will strengthen the manuscript. We respond to each major comment below and will make the corresponding revisions.
read point-by-point responses
-
Referee: [Evaluation] Evaluation section: the optimization loop is driven by the exact triggering queries (and their paraphrases) that produced the original feedback. No description is given of a held-out query split or a generalization test on new feedback; therefore the reported gains in discoverability may be an artifact of closed-loop tuning to the evaluation queries rather than a genuine improvement in nugget quality.
Authors: The INO procedure is intentionally driven by the triggering queries and paraphrases because its purpose is to make each factual correction discoverable within the specific retrieval behavior of the deployed agent. Paraphrases provide a limited form of robustness testing. We agree, however, that the absence of an explicit held-out query split leaves open the possibility of overfitting to the optimization queries. In the revised manuscript we will add a held-out evaluation that applies nuggets optimized on one set of feedback instances to new, previously unseen queries and feedback. revision: yes
-
Referee: [Abstract and §4] Abstract and §4 (results): the claim of 'consistent improvements' is asserted without any reported baseline definitions, concrete metrics, number of test cases, or statistical significance tests. This absence prevents assessment of whether the data actually support the central claim.
Authors: We will revise the abstract and Section 4 to (i) explicitly name the baselines, (ii) define the concrete metrics (discoverability rate and usage rate), (iii) state the total number of test cases and the split across the two production agents, and (iv) report the statistical significance tests performed. These additions will allow readers to evaluate the strength of the reported improvements. revision: yes
Circularity Check
INO discoverability gains reduce to 'iterate until retrieved' stopping condition by construction
specific steps
-
self definitional
[Abstract]
"it creates an initial nugget, probes it with the triggering query and paraphrases, reflects over failed retrieval and answer traces, and revises the nugget until it is discoverable. We evaluate INO with two production B2B knowledge-assistance agents [...] INO consistently improves results over baselines in terms of discoverability and usage of factual corrections, in automated and human evaluations."
The method is defined to continue revision until the nugget meets the discoverability criterion (successful retrieval by the production agent on the same queries). The claimed improvement in discoverability is therefore equivalent to the input definition of the optimization loop rather than derived independently.
full rationale
The paper defines INO as an iterative process that explicitly revises nuggets until retrieval succeeds on the triggering queries and paraphrases used in evaluation. The central claim of improved discoverability over baselines is therefore a direct consequence of this design rather than an independent result. No equations, external benchmarks, or held-out splits are described that would separate the optimization target from the reported metric. This matches the self-definitional pattern where the output property is guaranteed by the method's termination criterion.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Factual corrections from free-form feedback can be represented as compact knowledge-base entries called nuggets.
invented entities (1)
-
factual nugget
no independent evidence
Reference graph
Works this paper leans on
-
[1]
jina-embeddings-v5-text: Task-Targeted Embedding Distillation
jina- embeddings-v5-text: Task-targeted embedding distil- lation.Preprint, arXiv:2602.15547. Jihwan Bang, Seunghan Yang, Kyuhong Shim, Simyung Chang, Juntae Lee, and Sungha Choi
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Feedback Adaptation for Retrieval-Augmented Generation
Feed- back adaptation for retrieval-augmented generation. Preprint, arXiv:2604.06647. Mohammad Baqar
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Rag4tickets: Ai-powered ticket resolution via retrieval-augmented genera- tion on jira and github data.arXiv preprint arXiv:2510.08667. Jonathan D Chang, Andrew Drozdov, Shubham Tosh- niwal, Owen Oertell, Alexander Trott, Jacob Portes, Abhay Gupta, Pallavi Koppol, Ashutosh Baheti, Sean Kulinski, and 1 others
-
[4]
Jianlv Chen, Shitao Xiao, Peitian Zhang, Kun Luo, Defu Lian, and Zheng Liu
Karl: Knowledge agents via reinforcement learning.arXiv preprint arXiv:2603.05218. Jianlv Chen, Shitao Xiao, Peitian Zhang, Kun Luo, Defu Lian, and Zheng Liu
-
[5]
Bge m3-embedding: Multi-lingual, multi-functionality, multi-granularity text embeddings through self-knowledge distillation. Preprint, arXiv:2402.03216. Prateek Chhikara, Dev Khant, Saket Aryan, Taranjeet Singh, and Deshraj Yadav
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory
Mem0: Building production-ready ai agents with scalable long-term memory.Preprint, arXiv:2504.19413. Shashank Kirtania, Naman Gupta, Priyanshu Gupta, Sumit Gulwani, Arun Iyer, Suresh Parthasarathy Iyen- gar, Arjun Radhakrishna, Sriram K. Rajamani, and Gustavo Soares
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing: Industry Track, pages 2588–2606, Suzhou (China)
STACKFEED: Structured tex- tual actor-critic knowledge base editing with FEED- back. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing: Industry Track, pages 2588–2606, Suzhou (China). Association for Computational Linguistics. Chaofan Li, Zheng Liu, Shitao Xiao, and Yingxia Shao
2025
-
[8]
Rodrigo Nogueira and Jimmy Lin
Making large language models a better founda- tion for dense retrieval.Preprint, arXiv:2312.15503. Rodrigo Nogueira and Jimmy Lin
-
[9]
Document expansion by query prediction.arXiv preprint arXiv:1904.08375,
Document expansion by query prediction.arXiv preprint arXiv:1904.08375. Sarah Packowski, Inge Halilovic, Jenifer Schlotfeldt, and Trish Smith
-
[10]
Optimizing and evaluating en- terprise retrieval-augmented generation (rag): A con- tent design perspective.Preprint, arXiv:2410.12812. Orion Weller, Kyle Lo, David Wadden, Dawn Lawrie, Benjamin Van Durme, Arman Cohan, and Luca Sol- daini
-
[11]
InFindings of the Association for Computational Linguistics: EACL 2024, pages 1987–2003, St
When do generative query and docu- ment expansions fail? a comprehensive study across methods, retrievers, and datasets. InFindings of the Association for Computational Linguistics: EACL 2024, pages 1987–2003, St. Julian’s, Malta. Associa- tion for Computational Linguistics. Wujiang Xu, Zujie Liang, Kai Mei, Hang Gao, Juntao Tan, and Yongfeng Zhang
2024
-
[12]
A-MEM: Agentic Memory for LLM Agents
A-mem: Agentic memory for llm agents.Preprint, arXiv:2502.12110. Zhentao Xu, Mark Jerome Cruz, Matthew Guevara, Tie Wang, Manasi Deshpande, Xiaofeng Wang, and Zheng Li
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
InProceedings of the 47th International ACM SIGIR Conference on Research and Develop- ment in Information Retrieval, SIGIR 2024, page 2905–2909
Retrieval-augmented generation with knowledge graphs for customer service question answering. InProceedings of the 47th International ACM SIGIR Conference on Research and Develop- ment in Information Retrieval, SIGIR 2024, page 2905–2909. ACM. Jason Yip, Nikhil Gupta, and Marcin Wojtyczka
2024
-
[14]
In Proceedings of the 37th International Conference on Neural Information Processing Systems, NIPS ’23, Red Hook, NY , USA
Judging llm-as-a-judge with mt-bench and chatbot arena. In Proceedings of the 37th International Conference on Neural Information Processing Systems, NIPS ’23, Red Hook, NY , USA. Curran Associates Inc. 8 A Prompt and Model Details The production prompts include customer-specific examples and are not reproduced verbatim. This appendix describes the prompt...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.