PixIE: Prompted Pixel-Space Low-Light Image Enhancement
Pith reviewed 2026-05-25 05:08 UTC · model grok-4.3
The pith
PixIE enhances low-light images by injecting DINOv3 features into per-pixel modulation blocks after cross-scale denoising.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
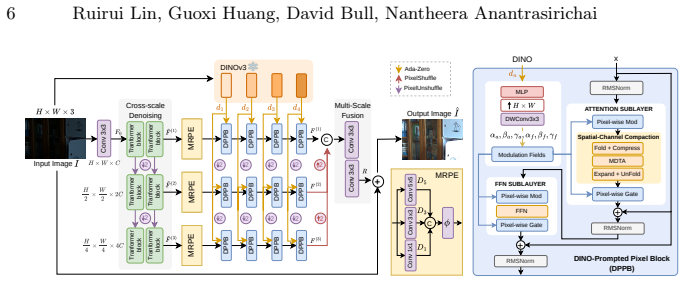
PixIE performs cross-scale denoising followed by refinement in DINO-Prompted Pixel Blocks that inject intermediate DINOv3 features via patch-conditioned, spatially continuous per-pixel modulation; Spatial-Channel Compaction folds features into a compact grid to bound attention cost across scales, while Multi-Receptive-Field Pixel Embedding supplies neighborhood-aware representations before prompting, yielding average PSNR gains of 1.9-15.0 percent and LPIPS reductions of 8.5-44.4 percent on LLIE benchmarks along with sharper details and stable textures.
What carries the argument
DINO-Prompted Pixel Blocks (DPPB) that inject intermediate DINOv3 features via patch-conditioned per-pixel modulation to refine details after initial denoising.
If this is right
- Cross-scale denoising suppresses noise while preserving structure before semantic refinement.
- Spatial-Channel Compaction enables pixel-attention computation with bounded cost across multiple scales.
- Multi-Receptive-Field Pixel Embedding increases robustness to signal-dependent noise compared with point-wise embeddings.
- The overall pipeline recovers sharper details and more stable textures than recent state-of-the-art methods.
Where Pith is reading between the lines
- The same prompting structure could be tested on related restoration tasks such as dehazing or low-light video to check if foundation-model features transfer.
- Efficiency from compaction might allow the framework to run on mobile hardware if the modulation blocks are further quantized.
- Replacing DINOv3 with a different foundation model could reveal whether the gains depend on specific semantic properties of that model.
Load-bearing premise
The assumption that DINOv3 features can be injected via patch-conditioned per-pixel modulation to improve detail recovery without introducing semantic errors or artifacts in noisy low-light inputs.
What would settle it
A set of low-light test images where the enhanced outputs exhibit semantic artifacts, such as invented textures or misidentified object boundaries, traceable to mismatched DINOv3 feature injection.
Figures






read the original abstract
Low-light images exhibit severe noise, contrast loss, and semantic ambiguity, making enhancement a joint problem of denoising and detail recovery. We propose PixIE, a feed-forward pixel-space LLIE framework semantically-prompted by a vision foundation model. PixIE first performs a cross-scale denoising to suppress noise and preserve structure, then refines details with DINO-Prompted Pixel Blocks (DPPB) that inject intermediate DINOv3 features via patch-conditioned, spatially continuous per-pixel modulation. We introduce a Spatial-Channel Compaction (SCC), which folds features into a compact spatial grid and compresses in the channel dimension, so pixel-attention is computed efficiently with bounded cost across scales. We further propose Multi-Receptive-Field Pixel Embedding (MRPE) to provide neighborhood-aware pixel representations before semantic prompting, improving robustness to signal-dependent noise beyond point-wise embeddings. Experiments on LLIE benchmarks show that PixIE improves the average PSNR by 1.9-15.0% over recent state-of-the-art methods and reduces LPIPS by 8.5-44.4%. Qualitative comparisons further demonstrate that PixIE recovers sharper details and more stable textures, resulting in improved reconstruction fidelity and perceptual quality.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes PixIE, a feed-forward pixel-space low-light image enhancement (LLIE) framework that first applies cross-scale denoising and then refines details using DINO-Prompted Pixel Blocks (DPPB) to inject intermediate DINOv3 features via patch-conditioned per-pixel modulation. It introduces Spatial-Channel Compaction (SCC) for efficient pixel-attention and Multi-Receptive-Field Pixel Embedding (MRPE) for neighborhood-aware representations. Experiments claim average PSNR gains of 1.9-15.0% and LPIPS reductions of 8.5-44.4% over recent SOTA methods on LLIE benchmarks, with qualitative improvements in detail and texture stability.
Significance. If the reported gains hold under rigorous validation and the DPPB modulation proves robust to signal-dependent noise without semantic artifacts, the work could meaningfully advance LLIE by showing how vision foundation model features can be efficiently integrated into pixel-space processing. The SCC mechanism for bounded-cost attention across scales is a potentially useful efficiency contribution if its implementation details are fully specified.
major comments (2)
- [DPPB and experiments sections] The central empirical claim of consistent PSNR/LPIPS gains rests on the assumption that DINOv3 features (trained on standard lighting) can be injected via DPPB without introducing semantic mismatches or artifacts in noisy low-light inputs; the manuscript provides no quantitative ablation isolating DPPB's contribution or failure-case analysis on signal-dependent noise, which is load-bearing for attributing improvements to the prompting mechanism rather than the denoising or embedding stages.
- [Experiments and results] The abstract and method description report average metric improvements but the manuscript lacks per-dataset tables with standard deviations, dataset splits, or statistical tests; without these, it is impossible to determine whether the 1.9-15.0% PSNR range reflects robust gains or is driven by particular benchmarks or post-hoc tuning.
minor comments (2)
- [Method] Notation for patch-conditioned modulation and the exact form of per-pixel modulation in DPPB should be formalized with equations to allow reproducibility.
- [Method] The paper should clarify the cross-scale denoising architecture (e.g., number of scales, loss terms) to distinguish its contribution from the novel DPPB component.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and will incorporate revisions to strengthen the empirical support for PixIE.
read point-by-point responses
-
Referee: [DPPB and experiments sections] The central empirical claim of consistent PSNR/LPIPS gains rests on the assumption that DINOv3 features (trained on standard lighting) can be injected via DPPB without introducing semantic mismatches or artifacts in noisy low-light inputs; the manuscript provides no quantitative ablation isolating DPPB's contribution or failure-case analysis on signal-dependent noise, which is load-bearing for attributing improvements to the prompting mechanism rather than the denoising or embedding stages.
Authors: We agree that a dedicated quantitative ablation isolating DPPB is necessary to attribute gains specifically to the prompting mechanism. The manuscript presents the full framework results but does not isolate DPPB from the cross-scale denoising and MRPE stages. In the revised version we will add an ablation study that removes or substitutes the DPPB module and reports the resulting metric changes. We will also include a failure-case analysis on low-light images exhibiting strong signal-dependent noise to examine potential semantic mismatches or artifacts introduced by DINOv3 features. revision: yes
-
Referee: [Experiments and results] The abstract and method description report average metric improvements but the manuscript lacks per-dataset tables with standard deviations, dataset splits, or statistical tests; without these, it is impossible to determine whether the 1.9-15.0% PSNR range reflects robust gains or is driven by particular benchmarks or post-hoc tuning.
Authors: We concur that per-dataset breakdowns with variability measures would improve transparency. The reported ranges are averages across the evaluated LLIE benchmarks, but the manuscript does not tabulate individual dataset results or standard deviations. In revision we will add per-dataset tables that include PSNR and LPIPS for each benchmark, along with standard deviations computed over multiple runs where available, and explicit details on the train/test splits employed. We will also explore the inclusion of statistical significance tests to support the observed improvements. revision: yes
Circularity Check
No significant circularity; empirical method with independent experimental validation
full rationale
The paper describes a proposed architecture (cross-scale denoising + DPPB with DINOv3 injection via SCC and MRPE) and validates it via standard benchmark metrics (PSNR, LPIPS) on LLIE datasets. No equations or claims reduce by construction to fitted parameters or self-referential definitions; performance numbers are external measurements, not tautological. No load-bearing self-citations or uniqueness theorems are invoked in the provided text. This is a standard empirical ML paper whose central claims rest on reproducible experiments rather than internal redefinitions.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
DINO-Prompted Pixel Block (DPPB) ... patch-conditioned, spatially continuous per-pixel modulation ... Spatial-Channel Compaction (SCC) ... Multi-Receptive-Field Pixel Embedding (MRPE)
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
PixIE ... feed-forward pixel-space LLIE framework semantically-prompted by a vision foundation model
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Bai, J., Yin, Y., He, Q., Li, Y., Zhang, X.: Retinexmamba: Retinex-based mamba for low-light image enhancement. In: International Conference on Neural Informa- tion Processing (2024),https://api.semanticscholar.org/CorpusID:269604860
work page 2024
-
[2]
Cai, Y., Bian, H., Lin, J., Wang, H., Timofte, R., Zhang, Y.: Retinexformer: One- stage retinex-based transformer for low-light image enhancement. In: IEEE/CVF ICCV. pp. 12504–12513 (October 2023)
work page 2023
-
[3]
Chang, M., Li, Q., Feng, H., Xu, Z.: Spatial-adaptive network for single image de- noising. In: ECCV. p. 171–187. Springer-Verlag, Berlin, Heidelberg (2020).https: //doi.org/10.1007/978-3-030-58577-8_11,https://doi.org/10.1007/978-3- 030-58577-8_11
-
[4]
arXiv preprint arXiv:2504.07963 (2025)
Chen, S., Ge, C., Zhang, S., Sun, P., Luo, P.: Pixelflow: Pixel-space generative models with flow. arXiv preprint arXiv:2504.07963 (2025)
-
[5]
arXiv preprint arXiv:2511.18822 (2025)
Chen, Z., Zhu, J., Chen, X., Zhang, J., Hu, X., Zhao, H., Wang, C., Yang, J., Tai, Y.: Dip: Taming diffusion models in pixel space. arXiv preprint arXiv:2511.18822 (2025)
- [6]
-
[7]
IEEE TIP17(10), 1737–1754 (2008).https://doi.org/10.1109/TIP.2008.2001399
Foi, A., Trimeche, M., Katkovnik, V., Egiazarian, K.: Practical poissonian-gaussian noise modeling and fitting for single-image raw-data. IEEE TIP17(10), 1737–1754 (2008).https://doi.org/10.1109/TIP.2008.2001399
-
[8]
Gou, Y., Hu, P., Lv, J., Zhou, J.T., Peng, X.: Multi-scale adaptive network for single image denoising. In: NeurIPS. Curran Associates Inc. (2022)
work page 2022
-
[9]
In: Proceedings of the IEEE conference on computer vision and pattern recognition (CVPR)
Guo, C.G., Li, C., Guo, J., Loy, C.C., Hou, J., Kwong, S., Cong, R.: Zero-reference deep curve estimation for low-light image enhancement. In: Proceedings of the IEEE conference on computer vision and pattern recognition (CVPR). pp. 1780– 1789 (June 2020)
work page 2020
-
[10]
IEEE Transactions on image processing26(2), 982–993 (2016)
Guo, X., Li, Y., Ling, H.: Lime: Low-light image enhancement via illumination map estimation. IEEE Transactions on image processing26(2), 982–993 (2016)
work page 2016
-
[11]
Journal of Visual Communication and Image Representation90, 103712 (2023)
Hai, J., Xuan, Z., Yang, R., Hao, Y., Zou, F., Lin, F., Han, S.: R2rnet: Low- light image enhancement via real-low to real-normal network. Journal of Visual Communication and Image Representation90, 103712 (2023)
work page 2023
- [12]
-
[13]
Advances in Neural Information Processing Systems36, 79734–79747 (2023)
Hou, J., Zhu, Z., Hou, J., Liu, H., Zeng, H., Yuan, H.: Global structure-aware diffusion process for low-light image enhancement. Advances in Neural Information Processing Systems36, 79734–79747 (2023)
work page 2023
-
[14]
In: Machine Learning from Challenging Data 2025
Huang, G., Lin, R., Li, Y., Bull, D., Anantrasirichai, N.: Bvi-mamba: video en- hancement using a visual state-space model for low-light and underwater environ- ments. In: Machine Learning from Challenging Data 2025. vol. 13460, pp. 74–81. SPIE (2025)
work page 2025
-
[15]
Proceedings of the AAAI Conference on Artificial Intelligence (2026)
Huang, G., Yang, Q., Qi, Z., Lin, R., Bull, D., Anantrasirichai, N.: Bayesian neu- ral networks for one-to-many mapping in image enhancement. Proceedings of the AAAI Conference on Artificial Intelligence (2026)
work page 2026
-
[16]
IEEE/CVF TCE53(4), 1752–1758 (2007)
Ibrahim, H., Pik Kong, N.S.: Brightness Preserving Dynamic Histogram Equaliza- tion for Image Contrast Enhancement. IEEE/CVF TCE53(4), 1752–1758 (2007)
work page 2007
-
[17]
ACM TOG42(6), 1–14 (2023) 16 Ruirui Lin, Guoxi Huang, David Bull, Nantheera Anantrasirichai
Jiang, H., Luo, A., Fan, H., Han, S., Liu, S.: Low-light image enhancement with wavelet-based diffusion models. ACM TOG42(6), 1–14 (2023) 16 Ruirui Lin, Guoxi Huang, David Bull, Nantheera Anantrasirichai
work page 2023
-
[18]
Jiang, H., Luo, A., Liu, X., Han, S., Liu, S.: Lightendiffusion: Unsupervised low- light image enhancement with latent-retinex diffusion models. In: ECCV (2024)
work page 2024
-
[19]
Jiang, Y., Gong, X., Liu, D., Cheng, Y., Fang, C., Shen, X., Yang, J., Zhou, P., Wang, Z.: Enlightengan: Deep light enhancement without paired supervision. IEEE TIP30, 2340–2349 (2021)
work page 2021
-
[20]
arXiv preprint arXiv:2306.15870 (2023)
Jin, Z., Chen, S., Chen, Y., Xu, Z., Feng, H.: Let segment anything help image dehaze. arXiv preprint arXiv:2306.15870 (2023)
-
[21]
Adam: A Method for Stochastic Optimization
Kingma, D.P., Ba, J.: Adam: A method for stochastic optimization. CoRR abs/1412.6980(2014),https://api.semanticscholar.org/CorpusID:6628106
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[22]
Auto-Encoding Variational Bayes
Kingma, D.P., Welling, M.: Auto-encoding variational bayes. In: ICLR (2014), http://arxiv.org/abs/1312.6114
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[23]
Kirillov, A., Mintun, E., Ravi, N., Mao, H., Rolland, C., Gustafson, L., Xiao, T., Whitehead, S., Berg, A.C., Lo, W.Y., Dollár, P., Girshick, R.: Segment anything. arXiv:2304.02643 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[24]
Scientific American237 6, 108–28 (1977)
Land, E.H.: The retinex theory of color vision. Scientific American237 6, 108–28 (1977)
work page 1977
-
[25]
IEEE transactions on image processing22(12), 5372–5384 (2013)
Lee, C., Lee, C., Kim, C.S.: Contrast enhancement based on layered difference representation of 2d histograms. IEEE transactions on image processing22(12), 5372–5384 (2013)
work page 2013
-
[26]
Li, S., Liu, M., Zhang, Y., Chen, S., Li, H., Dou, Z., Chen, H.: Sam-deblur: Let segmentanythingboostimagedeblurring.In:ICASSP.pp.2445–2449.IEEE(2024)
work page 2024
-
[27]
Lin, J., Anantrasirichai, N., Bull, D.: Multi-scale denoising in the feature space for low-light instance segmentation. In: IEEE ICASSP. pp. 1–5 (2025)
work page 2025
-
[28]
arXiv preprint arXiv:2312.01677 (2023)
Lin, X., Yue, J., Chan, K.C., Qi, L., Ren, C., Pan, J., Yang, M.H.: Multi-task image restoration guided by robust dino features. arXiv preprint arXiv:2312.01677 (2023)
-
[29]
Pattern Recognition61, 650–662 (2017)
Lore,K.G.,Akintayo,A.,Sarkar,S.:Llnet:Adeepautoencoderapproachtonatural low-light image enhancement. Pattern Recognition61, 650–662 (2017)
work page 2017
-
[30]
Luo, Z., Gustafsson, F.K., Zhao, Z., Sjolund, J., Schon, T.B.: Controlling vision- language models for multi-task image restoration. In: ICLR (2023),https://api. semanticscholar.org/CorpusID:263605463
work page 2023
-
[31]
Lv, F., Lu, F., Wu, J., Lim, C.: Mbllen: Low-light image/video enhancement using cnns. In: BMVC (2018)
work page 2018
-
[32]
IEEE Transactions on Image Processing24(11), 3345–3356 (2015)
Ma, K., Zeng, K., Wang, Z.: Perceptual quality assessment for multi-exposure image fusion. IEEE Transactions on Image Processing24(11), 3345–3356 (2015)
work page 2015
-
[33]
DeCo: Frequency-Decoupled Pixel Diffusion for End-to-End Image Generation
Ma, Z., Wei, L., Wang, S., Zhang, S., Tian, Q.: Deco: Frequency-decoupled pixel diffusion for end-to-end image generation. arXiv preprint arXiv:2511.19365 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[34]
Mittal, A., Soundararajan, R., Bovik, A.C.: Making a “completely blind” image quality analyzer. IEEE Signal Processing Letters20(3), 209–212 (2013).https: //doi.org/10.1109/LSP.2012.2227726
-
[35]
Oquab, M., Darcet, T., Moutakanni, T., Vo, H.V., Szafraniec, M., Khalidov, V., Fernandez,P.,Haziza,D.,Massa,F.,El-Nouby,A.,Howes,R.,Huang,P.Y.,Xu,H., Sharma, V., Li, S.W., Galuba, W., Rabbat, M., Assran, M., Ballas, N., Synnaeve, G., Misra, I., Jegou, H., Mairal, J., Labatut, P., Joulin, A., Bojanowski, P.: Dinov2: Learning robust visual features without ...
work page 2023
-
[36]
In: 2023 IEEE/CVF International Conference on Computer Vision (ICCV)
Peebles, W., Xie, S.: Scalable diffusion models with transformers. In: IEEE/CVF ICCV. pp. 4172–4182 (2023).https://doi.org/10.1109/ICCV51070.2023.00387
- [37]
-
[38]
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., Krueger, G., Sutskever, I.: Learning transferable visual models from natural language supervision. In: ICML (2021),https://api. semanticscholar.org/CorpusID:231591445
work page 2021
-
[39]
SAM 2: Segment Anything in Images and Videos
Ravi, N., Gabeur, V., Hu, Y.T., Hu, R., Ryali, C., Ma, T., Khedr, H., Rädle, R., Rolland, C., Gustafson, L., Mintun, E., Pan, J., Alwala, K.V., Carion, N., Wu, C.Y., Girshick, R., Dollár, P., Feichtenhofer, C.: Sam 2: Segment anything in images and videos. arXiv preprint arXiv:2408.00714 (2024),https://arxiv.org/ abs/2408.00714
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[40]
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., Ommer, B.: High-resolution image synthesis with latent diffusion models. CVPR pp. 10674–10685 (2021), https://api.semanticscholar.org/CorpusID:245335280
work page 2021
-
[41]
Siméoni, O., Vo, H.V., Seitzer, M., Baldassarre, F., Oquab, M., Jose, C., Khalidov, V., Szafraniec, M., Yi, S., Ramamonjisoa, M., Massa, F., Haziza, D., Wehrstedt, L., Wang, J., Darcet, T., Moutakanni, T., Sentana, L., Roberts, C., Vedaldi, A., Tolan, J., Brandt, J., Couprie, C., Mairal, J., Jégou, H., Labatut, P., Bojanowski, P.: DINOv3 (2025),https://ar...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[42]
Multimedia Tools and Applications77, 9211–9231 (2018)
Vonikakis, V., Kouskouridas, R., Gasteratos, A.: On the evaluation of illumina- tion compensation algorithms. Multimedia Tools and Applications77, 9211–9231 (2018)
work page 2018
-
[43]
Wang, J., Chan, K.C., Loy, C.C.: Exploring clip for assessing the look and feel of images. In: AAAI (2023)
work page 2023
-
[44]
IEEE transactions on image processing 22(9), 3538–3548 (2013)
Wang, S., Zheng, J., Hu, H.M., Li, B.: Naturalness preserved enhancement algo- rithm for non-uniform illumination images. IEEE transactions on image processing 22(9), 3538–3548 (2013)
work page 2013
-
[45]
Wei, C., Wang, W., Yang, W., Liu, J.: Deep retinex decomposition for low-light enhancement. In: BMVC (2018)
work page 2018
-
[46]
IEEE TPAMI44(11), 8520–8537 (2021)
Wei, K., Fu, Y., Zheng, Y., Yang, J.: Physics-based noise modeling for extreme low-light photography. IEEE TPAMI44(11), 8520–8537 (2021)
work page 2021
-
[47]
Xu, X., Wang, R., Fu, C.W., Jia, J.: Snr-aware low-light image enhancement. In: CVPR (2022)
work page 2022
-
[48]
ACM TOMM21(11) (Nov 2025).https://doi.org/10
Xue, M., He, J., Wang, W., Zhou, M.: Low-light image enhancement via clip-fourier guided wavelet diffusion. ACM TOMM21(11) (Nov 2025).https://doi.org/10. 1145/3764933,https://doi.org/10.1145/3764933
-
[49]
Yan, Q., Feng, Y., Zhang, C., Pang, G., Shi, K., Wu, P., Dong, W., Sun, J., Zhang, Y.:Hvi:Anewcolorspaceforlow-lightimageenhancement.In:IEEE/CVFCVPR. pp. 5678–5687 (2025).https://doi.org/10.1109/CVPR52734.2025.00533
-
[50]
IEEE Transactions on Image Processing30, 2072–2086 (2021)
Yang, W., Wang, W., Huang, H., Wang, S., Liu, J.: Sparse gradient regularized deep retinex network for robust low-light image enhancement. IEEE Transactions on Image Processing30, 2072–2086 (2021)
work page 2072
-
[51]
Yu, Y., Xiong, W., Nie, W., Sheng, Y., Liu, S., Luo, J.: Pixeldit: Pixel diffusion transformers for image generation (2025),https://arxiv.org/abs/2511.20645
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[52]
Yuhui, W., Chen, P., Guoqing, W., Yang, Y., Jiwei, W., Chongyi, L., Shen, H.T.: Learning semantic-aware knowledge guidance for low-light image enhancement. In: IEEE/CVF CVPR (2023)
work page 2023
-
[53]
Zamir, S.W., Arora, A., Khan, S., Hayat, M., Khan, F.S., Yang, M.H.: Restormer: Efficient transformer for high-resolution image restoration. In: CVPR (2022)
work page 2022
-
[54]
Zhang, Q., Liu, X., Li, W., Chen, H., Liu, J., Hu, J., Xiong, Z., Yuan, C., Wang, Y.: Distilling semantic priors from sam to efficient image restoration models. IEEE/CVF CVPR pp. 25409–25419 (2024),https://api.semanticscholar.org/ CorpusID:268681086 18 Ruirui Lin, Guoxi Huang, David Bull, Nantheera Anantrasirichai
work page 2024
-
[55]
Zhang, R., Isola, P., Efros, A.A., Shechtman, E., Wang, O.: The unreasonable effectiveness of deep features as a perceptual metric. In: IEEE/CVF CVPR (2018)
work page 2018
-
[56]
Diffusion Transformers with Representation Autoencoders
Zheng, B., Ma, N., Tong, S., Xie, S.: Diffusion transformers with representation autoencoders. arXiv preprint arXiv:2510.11690 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[57]
In: Proceedings of the IEEE/CVF Winter conference on applications of computer vision
Zheng, S., Gupta, G.: Semantic-guided zero-shot learning for low-light image/video enhancement. In: Proceedings of the IEEE/CVF Winter conference on applications of computer vision. pp. 581–590 (2022)
work page 2022
-
[58]
In: ACM MM (2024),https: //openreview.net/forum?id=oQahsz6vWe
Zou, W., Gao, H., Yang, W., Liu, T.: Wave-mamba: Wavelet state space model for ultra-high-definition low-light image enhancement. In: ACM MM (2024),https: //openreview.net/forum?id=oQahsz6vWe
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.