Neural Certificate Pricing for Combinatorial Optimization Problems
Pith reviewed 2026-07-02 15:09 UTC · model grok-4.3
The pith
A neural network predicts dual prices for combinatorial optimization such that recovered solutions are globally feasible under a certificate-consistency condition, with first-order price errors inducing only second-order objective loss.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
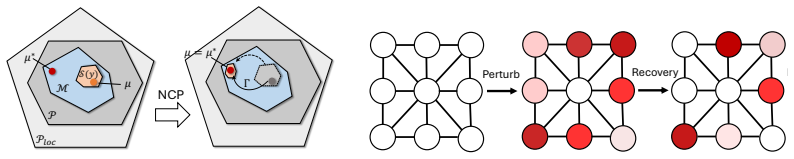
Neural Certificate Pricing trains a neural network to predict certificate-level dual prices for combinatorial optimization problems. A structured recovery layer then constructs the induced primal marginal. When the certificate-consistency condition holds, the recovered marginal is globally feasible. A local theory establishes that first-order errors in the predicted price induce only second-order loss in objective value.
What carries the argument
Amortized separation via learned residual prices: the neural network predicts certificate-level dual prices whose aggregate effect enters the recovery layer to construct the primal marginal.
If this is right
- The recovered marginal is globally feasible whenever the certificate-consistency condition holds.
- First-order errors in the predicted prices produce only second-order losses in objective value.
- NCP either outperforms state-of-the-art neural baselines by large margins or matches their performance at a fraction of the computation time.
- NCP exhibits stronger out-of-distribution generalization than the baselines across the three problem classes tested.
Where Pith is reading between the lines
- The same price-prediction approach could be tested on combinatorial problems whose separation oracles are expensive but still polynomial-time verifiable.
- Integration with existing branch-and-cut frameworks might allow the learned prices to guide branching or cutting decisions without full re-optimization.
- Empirical checks on problem sizes beyond those in the paper would clarify how far the local second-order error theory extends in practice.
Load-bearing premise
The certificate-consistency condition holds for the neural network's predicted prices.
What would settle it
An instance where the neural network's price predictions violate certificate consistency and the recovered marginal is infeasible, or where first-order price perturbations produce first-order rather than second-order degradation in objective value.
Figures
read the original abstract
Combinatorial optimization (CO) problems are difficult because certifiable discrete structure induces exponential search. One needs to search over the set exponentially many candidates to certify optimality, however, the structural feasibility of a path, packing, or cover can be verified in polynomial time once supplied. In this study, we introduce Neural Certificate Pricing (NCP) that exploits this asymmetry under an unsupervised learning framework. A neural network is trained to predict certificate-level dual prices, while a structured recovery layer constructs the induced primal marginal. NCP can be viewed as amortized separation: instead of enumerating violated inequalities, it learns the residual prices through which their aggregate effect enters recovery. When the certificate-consistency condition holds, the recovered marginal is globally feasible, and a local theory shows that first-order errors in the predicted price induce only second-order loss in objective value. Across three classes of CO problems, NCP either outperforms state-of-the-art neural baselines by large margins or matches them at a fraction of the computation time, and shows stronger out-of-distribution generalization.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Neural Certificate Pricing (NCP) for combinatorial optimization. A neural network is trained unsupervised to predict certificate-level dual prices; a structured recovery layer then constructs the induced primal marginal. The central claims are that, when a certificate-consistency condition holds, the recovered marginal is globally feasible and a local theory shows first-order price errors induce only second-order objective loss. Experiments across three CO problem classes report that NCP either outperforms neural baselines by large margins or matches them at lower compute, with stronger out-of-distribution generalization.
Significance. If the consistency condition can be shown to hold for the learned prices, the framework supplies a principled amortized separation method together with an explicit local error bound; this would be a substantive advance over existing neural CO approaches that lack such feasibility or error guarantees. The unsupervised training and recovery-layer design are potentially reusable strengths.
major comments (3)
- [Abstract] Abstract: the claim that 'when the certificate-consistency condition holds, the recovered marginal is globally feasible' and that 'a local theory shows that first-order errors ... induce only second-order loss' is presented without any derivation, proof sketch, or pointer to the section containing the argument. Both the feasibility guarantee and the error result are conditional on this premise, making its substantiation load-bearing.
- [NCP framework] NCP framework section: the manuscript trains the network to output prices and then applies recovery, yet supplies no architectural constraint, auxiliary loss term, or post-hoc projection that enforces the certificate-consistency condition. Without such enforcement or a post-training verification step, it is unclear whether the condition holds on instances seen at test time.
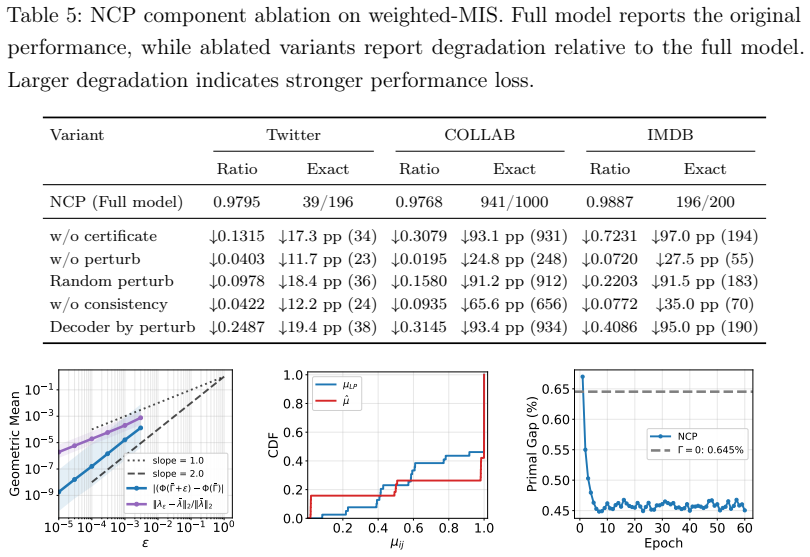
- [Experimental results] Experimental results section: performance tables and generalization plots are reported, but no ablation or diagnostic is included that checks whether the recovered marginals satisfy the feasibility claim or whether the consistency condition is satisfied by the trained prices on the evaluated instances.
minor comments (2)
- [Notation / Framework] Add an explicit equation or boxed definition for the certificate-consistency condition at the first point it is invoked, rather than leaving it as an informal hypothesis.
- [Figures] Figure captions for the recovery-layer diagram should state the precise input-output mapping and any assumptions required for the layer to produce a feasible marginal.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight opportunities to strengthen the presentation of the theoretical guarantees and to supply empirical verification of the consistency condition. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that 'when the certificate-consistency condition holds, the recovered marginal is globally feasible' and that 'a local theory shows that first-order errors ... induce only second-order loss' is presented without any derivation, proof sketch, or pointer to the section containing the argument. Both the feasibility guarantee and the error result are conditional on this premise, making its substantiation load-bearing.
Authors: The abstract is a high-level summary. The derivation of global feasibility (Theorem 1) and the local second-order error bound (Theorem 2) appears in Section 3. We will revise the abstract to include an explicit pointer to Section 3. revision: yes
-
Referee: [NCP framework] NCP framework section: the manuscript trains the network to output prices and then applies recovery, yet supplies no architectural constraint, auxiliary loss term, or post-hoc projection that enforces the certificate-consistency condition. Without such enforcement or a post-training verification step, it is unclear whether the condition holds on instances seen at test time.
Authors: The certificate-consistency condition is a sufficient condition for the stated guarantees rather than a constraint enforced at training time; the unsupervised objective encourages prices that support recovery but does not guarantee the condition. We will add a post-training diagnostic that reports the fraction of instances on which consistency holds. revision: yes
-
Referee: [Experimental results] Experimental results section: performance tables and generalization plots are reported, but no ablation or diagnostic is included that checks whether the recovered marginals satisfy the feasibility claim or whether the consistency condition is satisfied by the trained prices on the evaluated instances.
Authors: We will augment the experimental section with new diagnostics that verify global feasibility of recovered marginals and satisfaction of the certificate-consistency condition on both in-distribution and out-of-distribution instances. revision: yes
Circularity Check
No significant circularity; claims remain conditional and non-reductive
full rationale
The paper's core derivation states that feasibility of the recovered marginal and the first-to-second-order error result hold only when the certificate-consistency condition is satisfied by the neural network's predicted prices. No quoted equation or step in the provided text reduces this condition to a definition in terms of the network outputs themselves, nor does any recovery layer or unsupervised loss term force the consistency by construction. The framework is presented as amortized separation with an explicit external hypothesis, and empirical performance is reported separately from the conditional theory. No self-citation chain, ansatz smuggling, or renaming of known results appears in the load-bearing steps. The derivation is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- neural network parameters
axioms (1)
- domain assumption certificate-consistency condition holds for predicted prices
Reference graph
Works this paper leans on
-
[1]
Learning to explore and exploit with gnns for unsupervised combinatorial optimization
Utku Umur Acikalin, Aaron M Ferber, and Carla P Gomes. Learning to explore and exploit with gnns for unsupervised combinatorial optimization. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[2]
Differentiable convex optimization layers.Advances in neural information processing systems, 32, 2019
Akshay Agrawal, Brandon Amos, Shane Barratt, Stephen Boyd, Steven Diamond, and J Zico Kolter. Differentiable convex optimization layers.Advances in neural information processing systems, 32, 2019
2019
-
[3]
Optnet: Differentiable optimization as a layer in neural networks
Brandon Amos and J Zico Kolter. Optnet: Differentiable optimization as a layer in neural networks. InInternational conference on machine learning, pages 136–145. PMLR, 2017
2017
-
[4]
Deep equilibrium models
Shaojie Bai, J Zico Kolter, and Vladlen Koltun. Deep equilibrium models. Advances in neural information processing systems, 32, 2019
2019
-
[5]
Emergence of scaling in random networks.science, 286(5439):509–512, 1999
Albert-László Barabási and Réka Albert. Emergence of scaling in random networks.science, 286(5439):509–512, 1999
1999
-
[6]
Or-library: distributing test problems by electronic mail.Journal of the operational research society, 41(11):1069–1072, 1990
John E Beasley. Or-library: distributing test problems by electronic mail.Journal of the operational research society, 41(11):1069–1072, 1990
1990
-
[7]
Neural Combinatorial Optimization with Reinforcement Learning
Irwan Bello, Hieu Pham, Quoc V Le, Mohammad Norouzi, and Samy Bengio. Neural combinatorial optimization with reinforcement learning.arXiv preprint arXiv:1611.09940, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[8]
Machine learning for combinatorial optimization: a methodological tour d’horizon.European Journal of Operational Research, 290(2):405–421, 2021
Yoshua Bengio, Andrea Lodi, and Antoine Prouvost. Machine learning for combinatorial optimization: a methodological tour d’horizon.European Journal of Operational Research, 290(2):405–421, 2021
2021
-
[9]
Springer Science & Business Media, 2013
J Frédéric Bonnans and Alexander Shapiro.Perturbation analysis of optimization problems. Springer Science & Business Media, 2013. 14
2013
-
[10]
Unsupervised learning for the elementary shortest path problem.arXiv preprint arXiv:2508.01557, 2025
Jingyi Chen, Xinyuan Zhang, and Xinwu Qian. Unsupervised learning for the elementary shortest path problem.arXiv preprint arXiv:2508.01557, 2025
-
[11]
Neural combinatorial optimization with reinforcement learning in industrial engineering: a survey
Kwok Tung Chung, Carman KM Lee, and Yung Po Tsang. Neural combinatorial optimization with reinforcement learning in industrial engineering: a survey. Artificial Intelligence Review, 58(5):130, 2025
2025
-
[12]
Large language models for combinatorial optimization: A systematic review.ACM Computing Surveys, 2025
Francesca Da Ros, Michael Soprano, Luca Di Gaspero, and Kevin Roitero. Large language models for combinatorial optimization: A systematic review.ACM Computing Surveys, 2025
2025
-
[13]
Springer Science & Business Media, 2006
Guy Desaulniers, Jacques Desrosiers, and Marius M Solomon.Column generation, volume 5. Springer Science & Business Media, 2006
2006
-
[14]
Springer, 2009
Asen L Dontchev and R Tyrrell Rockafellar.Implicit functions and solution mappings, volume 543. Springer, 2009
2009
-
[15]
On random graphs i.Publ
P ERDdS and A R&wi. On random graphs i.Publ. math. debrecen, 6(290-297): 18, 1959
1959
-
[16]
Dominique Feillet, Pierre Dejax, Michel Gendreau, and Cyrille Gueguen. An exact algorithm for the elementary shortest path problem with resource constraints: Application to some vehicle routing problems.Networks: An International Journal, 44(3):216–229, 2004
2004
-
[17]
Exact combinatorial optimization with graph convolutional neural networks
Maxime Gasse, Didier Chételat, Nicola Ferroni, Laurent Charlin, and Andrea Lodi. Exact combinatorial optimization with graph convolutional neural networks. Advances in neural information processing systems, 32, 2019
2019
-
[18]
Geoffrion
Arthur M. Geoffrion. Lagrangean relaxation for integer programming.Mathe- matical Programming Study, 2:82–114, 1974
1974
-
[19]
Random graphs.The Annals of Mathematical Statistics, 30(4): 1141–1144, 1959
Edgar N Gilbert. Random graphs.The Annals of Mathematical Statistics, 30(4): 1141–1144, 1959
1959
-
[20]
Primal-dual neural algorithmic reasoning.arXiv preprint arXiv:2505.24067, 2025
Yu He and Ellen Vitercik. Primal-dual neural algorithmic reasoning.arXiv preprint arXiv:2505.24067, 2025
-
[21]
An efficient graph convo- lutional network technique for the travelling salesman problem,
Chaitanya K Joshi, Thomas Laurent, and Xavier Bresson. An efficient graph convolutional network technique for the travelling salesman problem.arXiv preprint arXiv:1906.01227, 2019
-
[22]
Snap datasets: Stanford large network dataset collection.Retrieved December 2021 from http://snap
Leskovec Jure. Snap datasets: Stanford large network dataset collection.Retrieved December 2021 from http://snap. stanford. edu/data, 2014. 15
2021
-
[23]
Erdos goes neural: an unsupervised learning framework for combinatorial optimization on graphs.Advances in Neural Information Processing Systems, 33:6659–6672, 2020
Nikolaos Karalias and Andreas Loukas. Erdos goes neural: an unsupervised learning framework for combinatorial optimization on graphs.Advances in Neural Information Processing Systems, 33:6659–6672, 2020
2020
-
[24]
The cutting-plane method for solving convex programs
James E Kelley, Jr. The cutting-plane method for solving convex programs. Journal of the society for Industrial and Applied Mathematics, 8(4):703–712, 1960
1960
-
[25]
Kriege, Christopher Morris, Petra Mutzel, and Marion Neumann
Kristian Kersting, Nils M. Kriege, Christopher Morris, Petra Mutzel, and Marion Neumann. Benchmark data sets for graph kernels.http://www.graphlearning. io/, 2020
2020
-
[26]
Learn- ing combinatorial optimization algorithms over graphs.Advances in neural information processing systems, 30, 2017
Elias Khalil, Hanjun Dai, Yuyu Zhang, Bistra Dilkina, and Le Song. Learn- ing combinatorial optimization algorithms over graphs.Advances in neural information processing systems, 30, 2017
2017
-
[27]
Attention, Learn to Solve Routing Problems!
Wouter Kool, Herke Van Hoof, and Max Welling. Attention, learn to solve routing problems!arXiv preprint arXiv:1803.08475, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[28]
Springer, 2002
Steven George Krantz and Harold R Parks.The implicit function theorem: history, theory, and applications, volume 202. Springer, 2002
2002
-
[29]
Pomo: Policy optimization with multiple optima for reinforcement learning.Advances in neural information processing systems, 33:21188–21198, 2020
Yeong-Dae Kwon, Jinho Choo, Byoungjip Kim, Iljoo Yoon, Youngjune Gwon, and Seungjai Min. Pomo: Policy optimization with multiple optima for reinforcement learning.Advances in neural information processing systems, 33:21188–21198, 2020
2020
-
[30]
Finding near-optimal independent sets at scale
Sebastian Lamm, Peter Sanders, Christian Schulz, Darren Strash, and Renato F Werneck. Finding near-optimal independent sets at scale. In2016 Proceedings of the eighteenth workshop on algorithm engineering and experiments (ALENEX), pages 138–150. SIAM, 2016
2016
-
[31]
Branch-and-bound methods: A survey
Eugene L Lawler and David E Wood. Branch-and-bound methods: A survey. Operations research, 14(4):699–719, 1966
1966
-
[32]
Yang Li, Jinpei Guo, Runzhong Wang, Hongyuan Zha, and Junchi Yan. Fast t2t: Optimization consistency speeds up diffusion-based training-to-testing solving for combinatorial optimization.Advances in Neural Information Processing Systems, 37:30179–30206, 2024
2024
-
[33]
Combinatorial optimization with graph convolutional networks and guided tree search.Advances in neural information processing systems, 31, 2018
Zhuwen Li, Qifeng Chen, and Vladlen Koltun. Combinatorial optimization with graph convolutional networks and guided tree search.Advances in neural information processing systems, 31, 2018
2018
-
[34]
Bruce T Lowerre.The harpy speech recognition system.Carnegie Mellon Univer- sity, 1976. 16
1976
-
[35]
Cambridge University Press, 1996
Zhi-Quan Luo, Jong-Shi Pang, and Daniel Ralph.Mathematical programs with equilibrium constraints. Cambridge University Press, 1996
1996
-
[36]
Sparsemap: Differentiable sparse structured inference
Vlad Niculae, Andre Martins, Mathieu Blondel, and Claire Cardie. Sparsemap: Differentiable sparse structured inference. InInternational Conference on Ma- chine Learning, pages 3799–3808. PMLR, 2018
2018
-
[37]
Strongly regular generalized equations.Mathematics of Operations Research, 5(1):43–62, 1980
Stephen M Robinson. Strongly regular generalized equations.Mathematics of Operations Research, 5(1):43–62, 1980
1980
-
[38]
Sebastian Sanokowski, Sepp Hochreiter, and Sebastian Lehner. A diffusion model framework for unsupervised neural combinatorial optimization.arXiv preprint arXiv:2406.01661, 2024
-
[39]
Combinatorial optimization augmented machine learning.arXiv preprint arXiv:2601.10583, 2026
Maximilian Schiffer, Heiko Hoppe, Yue Su, Louis Bouvier, and Axel Parmen- tier. Combinatorial optimization augmented machine learning.arXiv preprint arXiv:2601.10583, 2026
-
[40]
Graph neural networks for job shop scheduling problems: A survey.Computers & Operations Research, 176:106914, 2025
Igor G Smit, Jianan Zhou, Robbert Reijnen, Yaoxin Wu, Jian Chen, Cong Zhang, Zaharah Bukhsh, Yingqian Zhang, and Wim Nuijten. Graph neural networks for job shop scheduling problems: A survey.Computers & Operations Research, 176:106914, 2025
2025
-
[41]
Tightening LP Relaxations for MAP using Message Passing
David Sontag, Talya Meltzer, Amir Globerson, Tommi S Jaakkola, and Yair Weiss. Tightening lp relaxations for map using message passing.arXiv preprint arXiv:1206.3288, 2012
work page internal anchor Pith review Pith/arXiv arXiv 2012
-
[42]
Difusco: Graph-based diffusion solvers for combinatorial optimization.Advances in neural information processing systems, 36:3706–3731, 2023
Zhiqing Sun and Yiming Yang. Difusco: Graph-based diffusion solvers for combinatorial optimization.Advances in neural information processing systems, 36:3706–3731, 2023
2023
-
[43]
Jan Toenshoff, Martin Ritzert, Hinrikus Wolf, and Martin Grohe. Run-csp: unsu- pervised learning of message passing networks for binary constraint satisfaction problems.CoRR, abs/1909.08387, 2019
-
[44]
Pointer networks.Advances in neural information processing systems, 28, 2015
Oriol Vinyals, Meire Fortunato, and Navdeep Jaitly. Pointer networks.Advances in neural information processing systems, 28, 2015
2015
-
[45]
Graphical models, exponential families, and variational inference.Foundations and Trends®in Machine Learning, 1(1-2):1–305, 2008
Martin J Wainwright and Michael I Jordan. Graphical models, exponential families, and variational inference.Foundations and Trends®in Machine Learning, 1(1-2):1–305, 2008
2008
-
[46]
A new class of upper bounds on the log partition function.IEEE Transactions on Information Theory, 51(7):2313–2335, 2005
Martin J Wainwright, Tommi S Jaakkola, and Alan S Willsky. A new class of upper bounds on the log partition function.IEEE Transactions on Information Theory, 51(7):2313–2335, 2005. 17
2005
-
[47]
Satnet: Bridging deep learning and logical reasoning using a differentiable satisfiability solver
Po-Wei Wang, Priya Donti, Bryan Wilder, and Zico Kolter. Satnet: Bridging deep learning and logical reasoning using a differentiable satisfiability solver. In International Conference on Machine Learning, pages 6545–6554. PMLR, 2019
2019
-
[48]
A bi-level framework for learning to solve combinatorial optimization on graphs.Advances in neural information processing systems, 34:21453–21466, 2021
Runzhong Wang, Zhigang Hua, Gan Liu, Jiayi Zhang, Junchi Yan, Feng Qi, Shuang Yang, Jun Zhou, and Xiaokang Yang. A bi-level framework for learning to solve combinatorial optimization on graphs.Advances in neural information processing systems, 34:21453–21466, 2021
2021
-
[49]
Deep graph kernels
Pinar Yanardag and Svn VN Vishwanathan. Deep graph kernels. InProceedings of the 21th ACM SIGKDD international conference on knowledge discovery and data mining, pages 1365–1374, 2015
2015
-
[50]
Constructing free- energy approximations and generalized belief propagation algorithms.IEEE Transactions on information theory, 51(7):2282–2312, 2005
Jonathan S Yedidia, William T Freeman, and Yair Weiss. Constructing free- energy approximations and generalized belief propagation algorithms.IEEE Transactions on information theory, 51(7):2282–2312, 2005
2005
-
[51]
Learning for routing: A guided review of recent developments and future directions.Transportation Research Part E: Logistics and Transportation Review, 202:104278, 2025
Fangting Zhou, Attila Lischka, Balázs Kulcsár, Jiaming Wu, Morteza Haghir Chehreghani, and Gilbert Laporte. Learning for routing: A guided review of recent developments and future directions.Transportation Research Part E: Logistics and Transportation Review, 202:104278, 2025. 18 A Derivation of the Variational Outer Objective Forτ >0, define the Gibbs di...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.