A conceptual framework for learning to listen by reward: Curiosity-driven search for novel sources
Pith reviewed 2026-05-20 04:19 UTC · model grok-4.3
The pith
Agents learn to listen through reinforcement by continuously hunting for novel sound sources.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that a conceptual framework centered on the continuous search for novel sound sources supplies an intrinsic reward signal sufficient for agents to learn listening behaviors in a reinforcement-learning setting, without requiring granular labels or external supervision.
What carries the argument
Continuous search for novel sound sources, which functions as the intrinsic reward that drives the acquisition of listening skills.
If this is right
- Audio systems could be trained in unlabeled, real-world acoustic environments.
- Learning becomes possible in settings where sound sources are dynamic and previously unknown.
- The framework reduces dependence on large labeled audio datasets.
- Open technical challenges in reward formulation and exploration efficiency must still be solved.
Where Pith is reading between the lines
- The same novelty-search principle could be tested in multi-modal settings that combine audio with vision or touch.
- Agents using this reward might adapt more readily to new acoustic conditions than models trained on fixed datasets.
- Scaling the approach to long-duration recordings would require efficient ways to detect and remember novel sources.
Load-bearing premise
That rewarding an agent solely for finding new sound sources supplies enough guidance to produce useful listening abilities without any other supervision.
What would settle it
An experiment in which an agent trained only on novelty rewards shows no measurable improvement on downstream audio tasks such as source separation or classification relative to an agent that receives random rewards.
Figures

read the original abstract
Reinforcement learning is a powerful learning paradigm that has spearheaded progress in numerous domains. Its core promise lies in learning through high-level goals without the need for granular labels. However, it still remains elusive in the realm of audio, where it has received substantially less attention than in computer vision or other domains. The key question remains: how can agents learn to listen purely via reward-driven exploration? In this contribution, we present an overview of previous attempts and a new conceptual framework for learning to listen by reward. Our approach depends on the continuous search for novel sound sources. We formulate our framework, discuss open technical challenges, and present a first proof-of-concept implementation that showcases the feasibility of our approach.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript reviews prior attempts at reinforcement learning for audio tasks and proposes a conceptual framework for unsupervised 'learning to listen' driven by reward from continuous curiosity-based search for novel sound sources. It formulates the framework, identifies open technical challenges, and presents a proof-of-concept implementation intended to demonstrate basic feasibility.
Significance. If the circularity between novelty quantification and learned audio representations can be resolved, the framework could supply a label-free, exploration-driven paradigm for auditory learning that parallels successful curiosity methods in vision and control, with potential impact on unsupervised audio understanding and embodied agents.
major comments (2)
- [Framework section] Framework section (novelty-driven reward formulation): the central claim that continuous search for novel sound sources supplies a sufficient reward signal presupposes a mechanism to quantify novelty. Any concrete implementation (prediction error, embedding distance, or density estimation) requires an internal audio representation; the manuscript does not specify whether this representation is learned jointly, hand-crafted, or drawn from a pre-trained model, leaving the approach vulnerable to the circularity noted in the stress-test.
- [Proof-of-concept implementation] Proof-of-concept implementation: the manuscript states that the POC 'showcases the feasibility of our approach,' yet provides no description of the audio representation used, the novelty metric, training dynamics, quantitative metrics, or controls for collapse. This omission makes it impossible to evaluate whether the joint optimization avoids the very circularity that would undermine the framework's core promise.
minor comments (2)
- [Abstract and introduction] The abstract and introduction could more explicitly distinguish the proposed framework from existing curiosity-driven RL methods in other modalities to clarify the audio-specific contribution.
- [Open technical challenges] Open technical challenges are listed but would benefit from prioritized discussion of which must be solved before a non-circular implementation is possible.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. The comments correctly identify areas where additional clarity would strengthen the manuscript. We address each major comment below and have revised the manuscript to incorporate the suggested improvements while preserving the conceptual focus of the work.
read point-by-point responses
-
Referee: [Framework section] Framework section (novelty-driven reward formulation): the central claim that continuous search for novel sound sources supplies a sufficient reward signal presupposes a mechanism to quantify novelty. Any concrete implementation (prediction error, embedding distance, or density estimation) requires an internal audio representation; the manuscript does not specify whether this representation is learned jointly, hand-crafted, or drawn from a pre-trained model, leaving the approach vulnerable to the circularity noted in the stress-test.
Authors: We agree that the circularity between novelty quantification and the underlying audio representation is a central technical challenge. The Framework section was written at a conceptual level and explicitly flags this issue in the open challenges discussion rather than asserting a complete solution. To address the referee's point, we have revised the section to enumerate concrete options (jointly learned representations via iterative bootstrapping, initialization from pre-trained self-supervised models, or hand-crafted features as a baseline) and to emphasize that joint optimization is the intended long-term direction for avoiding circularity. These additions provide guidance without altering the high-level framework. revision: yes
-
Referee: [Proof-of-concept implementation] Proof-of-concept implementation: the manuscript states that the POC 'showcases the feasibility of our approach,' yet provides no description of the audio representation used, the novelty metric, training dynamics, quantitative metrics, or controls for collapse. This omission makes it impossible to evaluate whether the joint optimization avoids the very circularity that would undermine the framework's core promise.
Authors: The referee is right that the current POC description is too terse to permit independent evaluation. The implementation was deliberately minimal to illustrate basic feasibility of the reward formulation rather than to serve as a full experimental validation. In the revised manuscript we have expanded the POC section with the missing details: log-mel spectrogram input, a predictive-model novelty metric based on reconstruction error, the reinforcement-learning training loop, quantitative exploration metrics, and controls demonstrating that the agent does not collapse to trivial policies. We have also added a short discussion of how the chosen representation and metric interact with the circularity concern. revision: yes
Circularity Check
Conceptual framework introduces no self-referential derivations or fitted predictions
full rationale
The paper presents a high-level conceptual overview and framework for curiosity-driven audio learning via continuous novelty search, without any equations, parameter fitting, or quantitative derivations that could reduce to inputs by construction. No load-bearing self-citations, uniqueness theorems, or ansatzes are invoked to justify the core premise; the approach is explicitly framed as depending on an open technical challenge (novelty quantification) while acknowledging implementation difficulties. The proof-of-concept is described only as demonstrating basic feasibility rather than closing a loop or renaming prior results. This is a standard non-circular outcome for a conceptual proposal paper.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Reward-driven exploration via novelty search can produce effective learning in audio domains.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Our approach depends on the continuous search for novel sound sources... reward agents whenever they successfully approach a new sound source
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
The optimal value function is given by the Bellman equation
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
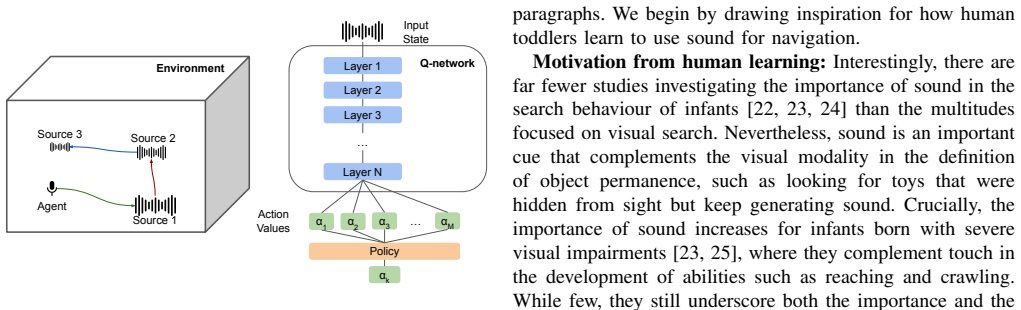
The agent was assumed to reach the source when their Euclidean distance was< .6m. A small negative rewardr − was given for every step where the agent failed to reach the source (−.1) and a larger one when it stepped out-of-bounds −1. For exploration, we used theϵ-greedy strategy, withϵ initialised at.6and gradually annealed to.95at the end of each epoch w...
-
[2]
R. S. Sutton and A. G. Barto,Reinforcement learning: An introduction. MIT press Cambridge, 1998, vol. 1
work page 1998
-
[3]
Playing Atari with Deep Reinforcement Learning
V . Mnih, K. Kavukcuoglu, D. Silver, A. Graves, I. Antonoglou, D. Wierstra, and M. Riedmiller, “Playing atari with deep reinforcement learning,”arXiv preprint arXiv:1312.5602, 2013
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[4]
Mastering the game of go with deep neural networks and tree search,
D. Silver, A. Huang, C. J. Maddison, A. Guez, L. Sifre, G. Van Den Driessche, J. Schrittwieser, I. Antonoglou, V . Panneershelvam, M. Lanctot, et al., “Mastering the game of go with deep neural networks and tree search,”nature, vol. 529, no. 7587, pp. 484–489, 2016
work page 2016
-
[5]
Deep reinforcement learning for autonomous driving: A survey,
B. R. Kiran, I. Sobh, V . Talpaert, P. Mannion, A. A. Al Sallab, S. Yogamani, and P. P´erez, “Deep reinforcement learning for autonomous driving: A survey,”IEEE Transactions on Intelligent Transportation Systems, vol. 23, no. 6, pp. 4909–4926, 2021
work page 2021
-
[6]
Reinforcement learning in robotics: A survey,
J. Kober, J. A. Bagnell, and J. Peters, “Reinforcement learning in robotics: A survey,”The International Journal of Robotics Research, vol. 32, no. 11, pp. 1238–1274, 2013
work page 2013
-
[7]
Formal mathematical reasoning: A new frontier in ai.arXiv preprint arXiv:2412.16075, 2024
K. Yang, G. Poesia, J. He, W. Li, K. Lauter, S. Chaudhuri, and D. Song, “Formal mathematical reasoning: A new frontier in ai,”arXiv preprint arXiv:2412.16075, 2024
-
[8]
Training language models to follow instructions with human feedback,
L. Ouyang, J. Wu, X. Jiang, D. Almeida, C. Wainwright, P. Mishkin, C. Zhang, S. Agarwal, K. Slama, A. Ray, et al., “Training language models to follow instructions with human feedback,”Advances in neural information processing systems, vol. 35, pp. 27 730–27 744, 2022
work page 2022
-
[9]
A novel policy for pre-trained deep reinforcement learning for speech emotion recognition,
T. Rajapakshe, R. Rana, S. Khalifa, J. Liu, and B. Schuller, “A novel policy for pre-trained deep reinforcement learning for speech emotion recognition,” inProceedings of the Australasian Computer Science Week, 2022, pp. 96–105
work page 2022
-
[10]
A CRNN-GRU based rein- forcement learning approach to audio captioning.,
X. Xu, H. Dinkel, M. Wu, and K. Yu, “A CRNN-GRU based rein- forcement learning approach to audio captioning.,” inProc. DCASE, 2020, pp. 225–229
work page 2020
-
[11]
X. Mei, Q. Huang, X. Liu, G. Chen, J. Wu, Y . Wu, J. Zhao, S. Li, T. Ko, H. L. Tang, et al., “An encoder-decoder based audio captioning system with transfer and reinforcement learning for dcase challenge 2021 task 6,”DCASE2021 Challenge, Tech. Rep, Tech. Rep, 2021
work page 2021
-
[12]
Beyond the status quo: A contemporary survey of advances and challenges in audio captioning,
X. Xu, Z. Xie, M. Wu, and K. Yu, “Beyond the status quo: A contemporary survey of advances and challenges in audio captioning,” IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 32, pp. 95–112, 2023
work page 2023
-
[13]
Audio self-supervised learning: A survey,
S. Liu, A. Mallol-Ragolta, E. Parada-Cabaleiro, K. Qian, X. Jing, A. Kathan, B. Hu, and B. W. Schuller, “Audio self-supervised learning: A survey,”Patterns, vol. 3, no. 12, 2022
work page 2022
-
[14]
Computer audition: From task-specific machine learning to foundation models,
A. Triantafyllopoulos, I. Tsangko, A. Gebhard, A. Mesaros, T. Vir- tanen, and B. W. Schuller, “Computer audition: From task-specific machine learning to foundation models,”Proceedings of the IEEE, 2025
work page 2025
-
[15]
SoundSpaces: Audio-Visual Navigation in 3D Environments,
C. Chen, U. Jain, C. Schissler, S. V . A. Gari, Z. Al-Halah, V . K. Ithapu, P. Robinson, and K. Grauman, “SoundSpaces: Audio-Visual Navigation in 3D Environments,” inProc. ECCV, 2020
work page 2020
-
[16]
Habitat: A platform for embodied ai research,
M. Savva, A. Kadian, O. Maksymets, Y . Zhao, E. Wijmans, B. Jain, J. Straub, J. Liu, V . Koltun, J. Malik, et al., “Habitat: A platform for embodied ai research,” inProceedings of the IEEE/CVF international conference on computer vision, 2019, pp. 9339–9347
work page 2019
-
[17]
Move2hear: Active audio-visual source separation,
S. Majumder, Z. Al-Halah, and K. Grauman, “Move2hear: Active audio-visual source separation,” inProc. ICCV, 2021, pp. 275–285
work page 2021
-
[18]
Soundspaces 2.0: A simulation platform for visual-acoustic learning,
C. Chen, C. Schissler, S. Garg, P. Kobernik, A. Clegg, P. Calamia, D. Batra, P. Robinson, and K. Grauman, “Soundspaces 2.0: A simulation platform for visual-acoustic learning,”Advances in Neural Information Processing Systems, vol. 35, pp. 8896–8911, 2022
work page 2022
-
[19]
A unified audio-visual learning framework for localization, separation, and recognition,
S. Mo and P. Morgado, “A unified audio-visual learning framework for localization, separation, and recognition,” inInternational Conference on Machine Learning, PMLR, 2023, pp. 25 006–25 017
work page 2023
- [20]
-
[21]
Agents that Listen: High- Throughput Reinforcement Learning with Multiple Sensory Systems,
S. Hegde, A. Kanervisto, and A. Petrenko, “Agents that Listen: High- Throughput Reinforcement Learning with Multiple Sensory Systems,” in2021 IEEE Conference on Games (CoG), Copenhagen, Denmark: IEEE, Aug. 2021, pp. 1–5,ISBN: 978-1-6654-3886-5. Accessed: Aug. 21, 2025
work page 2021
-
[22]
A Deep Reinforce- ment Learning Approach To Audio-Based Navigation In A Multi- Speaker Environment,
P. Giannakopoulos, A. Pikrakis, and Y . Cotronis, “A Deep Reinforce- ment Learning Approach To Audio-Based Navigation In A Multi- Speaker Environment,” inICASSP 2021 - 2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada: IEEE, Jun. 2021, pp. 3475–3479,ISBN: 978-1- 7281-7605-5. Accessed: Aug. 21, 2025
work page 2021
-
[23]
Development of the use of sound in the search behavior of infants.,
A. E. Bigelow, “Development of the use of sound in the search behavior of infants.,”Developmental Psychology, vol. 19, no. 3, p. 317, 1983
work page 1983
-
[24]
Reach on sound: A key to object permanence in visually impaired children,
E. Fazzi, S. G. Signorini, M. Bomba, A. Luparia, J. Lanners, and U. Balottin, “Reach on sound: A key to object permanence in visually impaired children,”Early human development, vol. 87, no. 4, pp. 289– 296, 2011
work page 2011
-
[25]
Sound effects: Multimodal input helps infants find dis- placed objects,
J. L. Shinskey, “Sound effects: Multimodal input helps infants find dis- placed objects,”British Journal of Developmental Psychology, vol. 35, no. 3, pp. 317–333, 2017
work page 2017
-
[26]
The development of blind infants’ search for dropped objects,
A. Bigelow, “The development of blind infants’ search for dropped objects,”Infant Behavior and Development, vol. 7, p. 36, 1984
work page 1984
-
[27]
Overview and evaluation of sound event localization and detection in dcase 2019,
A. Politis, A. Mesaros, S. Adavanne, T. Heittola, and T. Virtanen, “Overview and evaluation of sound event localization and detection in dcase 2019,”IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 29, pp. 684–698, 2020
work page 2019
-
[28]
Sound event detection: A tutorial,
A. Mesaros, T. Heittola, T. Virtanen, and M. D. Plumbley, “Sound event detection: A tutorial,”IEEE Signal Processing Magazine, vol. 38, no. 5, pp. 67–83, 2021
work page 2021
-
[29]
A theoretical analysis of deep q-learning,
J. Fan, Z. Wang, Y . Xie, and Z. Yang, “A theoretical analysis of deep q-learning,” inLearning for dynamics and control, PMLR, 2020, pp. 486–489
work page 2020
-
[30]
Self-improving reactive agents based on reinforcement learning, planning and teaching,
L.-J. Lin, “Self-improving reactive agents based on reinforcement learning, planning and teaching,”Machine learning, vol. 8, no. 3, pp. 293–321, 1992
work page 1992
-
[31]
Pyroomacoustics: A python package for audio room simulation and array processing algorithms,
R. Scheibler, E. Bezzam, and I. Dokmani ´c, “Pyroomacoustics: A python package for audio room simulation and array processing algorithms,” inProc. ICASSP, IEEE, 2018, pp. 351–355
work page 2018
-
[32]
gpuRIR: A python library for room impulse response simulation with GPU acceleration,
D. Diaz-Guerra, A. Miguel, and J. R. Beltran, “gpuRIR: A python library for room impulse response simulation with GPU acceleration,” Multimedia Tools and Applications, vol. 80, no. 4, pp. 5653–5671, 2021
work page 2021
-
[33]
Vizdoom: A doom-based AI research platform for visual reinforce- ment learning,
M. Kempka, M. Wydmuch, G. Runc, J. Toczek, and W. Ja ´skowski, “Vizdoom: A doom-based AI research platform for visual reinforce- ment learning,” inProc. IEEE Conference on Computational Intelli- gence and Games (CIG), IEEE, 2016, pp. 1–8
work page 2016
-
[34]
Acoustic volume rendering for neural impulse response fields,
Z. Lan, C. Zheng, Z. Zheng, and M. Zhao, “Acoustic volume rendering for neural impulse response fields,”Advances in Neural Information Processing Systems, vol. 37, pp. 44 600–44 623, 2024
work page 2024
-
[35]
Mesh2ir: Neural acoustic impulse response generator for complex 3d scenes,
A. Ratnarajah, Z. Tang, R. Aralikatti, and D. Manocha, “Mesh2ir: Neural acoustic impulse response generator for complex 3d scenes,” inProc. ACM Multimedia, 2022, pp. 924–933
work page 2022
-
[36]
Panns: Large-scale pretrained audio neural networks for audio pattern recognition,
Q. Kong, Y . Cao, T. Iqbal, Y . Wang, W. Wang, and M. D. Plumb- ley, “Panns: Large-scale pretrained audio neural networks for audio pattern recognition,”IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 28, pp. 2880–2894, 2020
work page 2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.