SPAR: Semantic-Pixel Self-Alignment and Adaptive Routing for Unified Multimodal Models
Pith reviewed 2026-06-26 09:06 UTC · model grok-4.3
The pith
SPAR reconciles semantic perception and pixel reconstruction in one tokenizer to let multimodal models generate and understand without external teachers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
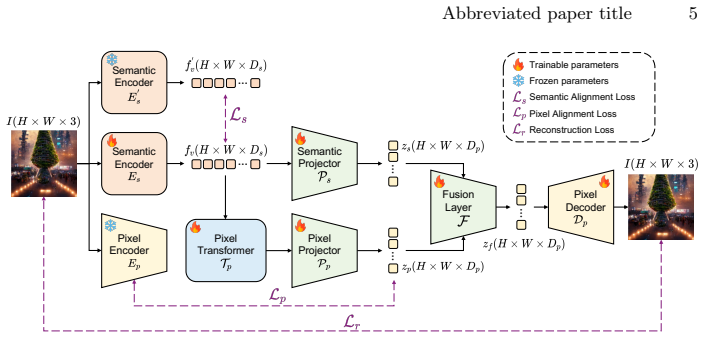
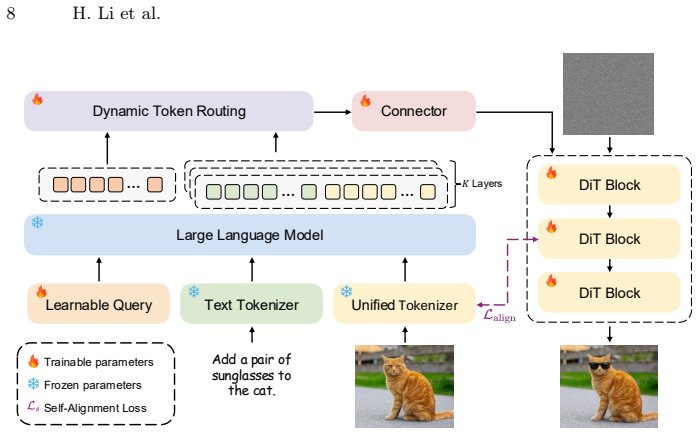
The central claim is that an asymmetric dual-stream unified tokenizer can reconcile semantic perception with pixel-level reconstruction by anchoring discriminative features in a lightweight semantic stream and recovering fine-grained details in a Transformer-augmented pixel stream within a unified compact latent space, and that this tokenizer can natively serve as an internal alignment teacher for a diffusion model in a self-aligned generation paradigm, while Dynamic Token Routing enables flexible multimodal interaction, allowing the unified model to achieve state-of-the-art generation and reconstruction quality while preserving visual understanding.
What carries the argument
Asymmetric dual-stream unified tokenizer, which anchors discriminative features in a lightweight semantic stream and recovers fine-grained visual details in a Transformer-augmented pixel stream inside one compact latent space, then used as internal teacher for diffusion.
If this is right
- Unified models reach state-of-the-art generation and reconstruction quality.
- Visual understanding capabilities stay intact without separate training branches.
- Dynamic token routing lets tokens adaptively aggregate multi-layer features according to their semantic demands.
- Generation proceeds without external alignment teachers or added dependencies.
Where Pith is reading between the lines
- If the internal teacher scales reliably, multimodal training pipelines could drop separate pre-alignment stages and reduce compute overhead.
- The routing mechanism might extend naturally to video or audio by swapping the pixel stream while keeping the semantic anchor.
- Token-level adaptation could improve efficiency at inference time by skipping unneeded layers for simple tokens.
Load-bearing premise
The dual-stream tokenizer can deliver both high discriminative power for understanding and high-fidelity reconstruction for generation in the same space without one weakening the other.
What would settle it
A controlled ablation where the internal self-alignment produces measurably lower generation quality than an external teacher baseline on standard metrics such as FID while the semantic stream is kept fixed.
Figures


read the original abstract
Multimodal Large Language Models (MLLMs) have achieved remarkable success in visual understanding but remain constrained in visual generation due to the fundamental feature discrepancy between semantic perception and pixel-level reconstruction. Bridging this gap requires overcoming two core challenges: endowing semantic encoders with high-fidelity reconstruction capabilities, and effectively aligning generative models with semantic spaces without relying on external teachers. To this end, we propose a novel unified multimodal framework featuring \textbf{S}emantic-\textbf{P}ixel self-alignment and \textbf{A}daptive \textbf{R}outing (\textbf{SPAR}). First, to reconcile semantic perception with pixel-level reconstruction, we introduce an asymmetric dual-stream unified tokenizer. A lightweight semantic stream anchors discriminative features, while a Transformer-augmented pixel stream recovers fine-grained visual details into a unified compact latent space. Second, to eliminate external dependencies, we propose a self-aligned generation paradigm that natively leverages this optimized tokenizer as an internal alignment teacher for the diffusion model. Furthermore, to facilitate flexible multimodal interaction within this unified space, we introduce Dynamic Token Routing, which enables each token to adaptively aggregate multi-layer MLLM features based on its distinct semantic demands. Extensive experiments demonstrate that SPAR establishes the state-of-the-art for unified architectures, achieving exceptional generation and reconstruction quality while preserving foundational visual understanding capabilities.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SPAR, a unified multimodal framework to bridge semantic perception and pixel-level reconstruction in MLLMs. It introduces an asymmetric dual-stream unified tokenizer (lightweight semantic stream + Transformer-augmented pixel stream) to create a compact latent space, a self-aligned diffusion paradigm that uses this tokenizer as an internal teacher without external dependencies, and Dynamic Token Routing to let tokens adaptively aggregate multi-layer MLLM features. The central claim is that SPAR achieves SOTA performance among unified architectures on generation and reconstruction while preserving visual understanding capabilities.
Significance. If the experimental validation holds, the self-aligned internal-teacher approach and asymmetric tokenizer design could meaningfully advance unified multimodal models by reducing reliance on external alignment mechanisms and addressing the semantic-pixel discrepancy directly in the architecture. The explicit motivation of design choices (lightweight semantic anchor, pixel augmentation) is a strength.
major comments (2)
- [Abstract] Abstract: The claim that SPAR 'establishes the state-of-the-art for unified architectures' and achieves 'exceptional generation and reconstruction quality' is presented without any metrics, baselines, ablation studies, tables, or figures. This absence makes the central empirical claim impossible to evaluate and is load-bearing for the paper's contribution.
- [Abstract] The description of the asymmetric dual-stream tokenizer and self-aligned paradigm (Abstract) asserts that the tokenizer serves as an internal alignment teacher 'without relying on external teachers' and preserves 'foundational visual understanding capabilities,' but no derivation, loss formulation, or verification is supplied to show that the lightweight semantic stream does not degrade discriminative power or that the pixel stream recovers details without introducing new discrepancies.
Simulated Author's Rebuttal
We thank the referee for the comments. We address each major point regarding the abstract below and outline revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that SPAR 'establishes the state-of-the-art for unified architectures' and achieves 'exceptional generation and reconstruction quality' is presented without any metrics, baselines, ablation studies, tables, or figures. This absence makes the central empirical claim impossible to evaluate and is load-bearing for the paper's contribution.
Authors: We acknowledge the referee's point that the abstract's SOTA and quality claims would be easier to evaluate with supporting numbers. The full manuscript reports these results in Sections 4 and 5, with quantitative tables against unified baselines (e.g., Chameleon, Show-o) on FID, reconstruction metrics, and understanding benchmarks, plus ablations. To address the concern directly, we will revise the abstract to include a small number of key metrics supporting the claims. revision: yes
-
Referee: [Abstract] The description of the asymmetric dual-stream tokenizer and self-aligned paradigm (Abstract) asserts that the tokenizer serves as an internal alignment teacher 'without relying on external teachers' and preserves 'foundational visual understanding capabilities,' but no derivation, loss formulation, or verification is supplied to show that the lightweight semantic stream does not degrade discriminative power or that the pixel stream recovers details without introducing new discrepancies.
Authors: The abstract is a concise summary; the asymmetric dual-stream tokenizer (lightweight semantic stream + Transformer-augmented pixel stream) and its motivation are derived in Section 3.1, the self-aligned diffusion paradigm with internal-teacher losses (no external models) is formulated in Section 3.2, and verification that semantic power is preserved (no drop on VQA/understanding tasks) while pixel details improve is shown via ablations and comparisons in Section 4.3. We will revise the abstract wording to avoid over-assertion and briefly note the empirical support. revision: partial
Circularity Check
No significant circularity; architecture claims are self-contained
full rationale
The abstract and method outline introduce an asymmetric dual-stream tokenizer, self-aligned diffusion using the tokenizer as internal teacher, and dynamic token routing as explicit design choices to address stated challenges of semantic-pixel discrepancy. No equations, fitted parameters renamed as predictions, or self-citation chains are present in the provided text that would reduce any central claim to its own inputs by construction. The derivation chain remains independent, with performance claims tied to asserted experimental validation rather than definitional equivalence.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Semantic perception and pixel-level reconstruction can be reconciled via an asymmetric dual-stream tokenizer in a unified compact latent space.
- domain assumption The optimized tokenizer can serve as an internal alignment teacher for the diffusion model without external dependencies.
invented entities (1)
-
Dynamic Token Routing
no independent evidence
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2511.21631 (2025) 1
Bai, S., Cai, Y., Chen, R., Chen, K., Chen, X., Cheng, Z., Deng, L., Ding, W., Gao, C., Ge, C., Ge, W., Guo, Z., Huang, Q., Huang, J., Huang, F., Hui, B., Jiang, S., Li, Z., Li, M., Li, M., Li, K., Lin, Z., Lin, J., Liu, X., Liu, J., Liu, C., Liu, Y., Liu, D., Liu, S., Lu, D., Luo, R., Lv, C., Men, R., Meng, L., Ren, X., Ren, X., Song, S., Sun, Y., Tang, ...
Pith/arXiv arXiv 2025
-
[2]
arXiv preprint arXiv:2502.13923 (2025) 11
Bai, S., Chen, K., Liu, X., Wang, J., Ge, W., Song, S., Dang, K., Wang, P., Wang, S., Tang, J., Zhong, H., Zhu, Y., Yang, M., Li, Z., Wan, J., Wang, P., Ding, W., Fu, Z., Xu, Y., Ye, J., Zhang, X., Xie, T., Cheng, Z., Zhang, H., Yang, Z., Xu, H., Lin, J.: Qwen2.5-vl technical report. arXiv preprint arXiv:2502.13923 (2025) 11
Pith/arXiv arXiv 2025
-
[3]
Black Forest Labs: FLUX.2: Analyzing and enhancing the latent space of FLUX – representation comparison (2025),https://bfl.ai/research/representation- comparison3
2025
-
[4]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Brooks, T., Holynski, A., Efros, A.A.: Instructpix2pix: Learning to follow image editing instructions. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 18392–18402 (2023) 14
2023
-
[5]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Changpinyo, S., Sharma, P., Ding, N., Soricut, R.: Conceptual 12m: Pushing web- scale image-text pre-training to recognize long-tail visual concepts. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 3558–3568 (2021) 10
2021
-
[6]
Chen, J., Xu, Z., Pan, X., Hu, Y., Qin, C., Goldstein, T., Huang, L., Zhou, T., Xie, S., Savarese, S., et al.: Blip3-o: A family of fully open unified multimodal 16 H. Li et al. models-architecture, training and dataset. arXiv preprint arXiv:2505.09568 (2025) 4, 10, 11, 12
Pith/arXiv arXiv 2025
-
[7]
Chen, J., Cai, Z., Chen, P., Chen, S., Ji, K., Wang, X., Yang, Y., Wang, B.: Sharegpt-4o-image: Aligning multimodal models with gpt-4o-level image genera- tion (2025),https://arxiv.org/abs/2506.1809511
arXiv 2025
-
[8]
arXiv preprint arXiv:2410.10733 (2024) 10
Chen, J., Cai, H., Chen, J., Xie, E., Yang, S., Tang, H., Li, M., Lu, Y., Han, S.: Deep compression autoencoder for efficient high-resolution diffusion models. arXiv preprint arXiv:2410.10733 (2024) 10
arXiv 2024
-
[9]
arXiv preprint arXiv:2501.17811 (2025) 11, 12
Chen, X., Wu, Z., Liu, X., Pan, Z., Liu, W., Xie, Z., Yu, X., Ruan, C.: Janus-pro: Unified multimodal understanding and generation with data and model scaling. arXiv preprint arXiv:2501.17811 (2025) 11, 12
Pith/arXiv arXiv 2025
-
[10]
arXiv preprint arXiv:2505.14683 (2025) 4, 11, 12, 14
Deng, C., Zhu, D., Li, K., Gou, C., Li, F., Wang, Z., Zhong, S., Yu, W., Nie, X., Song, Z., Shi, G., Fan, H.: Emerging properties in unified multimodal pretraining. arXiv preprint arXiv:2505.14683 (2025) 4, 11, 12, 14
Pith/arXiv arXiv 2025
-
[11]
In: Forty-first international conference on machine learning (2024) 2, 12
Esser, P., Kulal, S., Blattmann, A., Entezari, R., Müller, J., Saini, H., Levi, Y., Lorenz, D., Sauer, A., Boesel, F., et al.: Scaling rectified flow transformers for high-resolution image synthesis. In: Forty-first international conference on machine learning (2024) 2, 12
2024
-
[12]
arXiv preprint arXiv:2306.13394 (2023) 11
Fu, C., Chen, P., Shen, Y., Qin, Y., Zhang, M., Lin, X., Yang, J., Zheng, X., Li, K., Sun, X., et al.: Mme: A comprehensive evaluation benchmark for multimodal large language models. arXiv preprint arXiv:2306.13394 (2023) 11
Pith/arXiv arXiv 2023
-
[13]
arXiv preprint arXiv:2404.14396 (2024) 11
Ge,Y.,Zhao,S.,Zhu,J.,Ge,Y.,Yi,K.,Song,L.,Li,C.,Ding,X.,Shan,Y.:Seed-x: Multimodal models with unified multi-granularity comprehension and generation. arXiv preprint arXiv:2404.14396 (2024) 11
Pith/arXiv arXiv 2024
-
[14]
Advances in Neural Information Processing Systems36, 52132–52152 (2023) 12
Ghosh, D., Hajishirzi, H., Schmidt, L.: Geneval: An object-focused framework for evaluating text-to-image alignment. Advances in Neural Information Processing Systems36, 52132–52152 (2023) 12
2023
-
[15]
arXiv preprint arXiv:2506.18898 (2025) 11, 12
Han, J., Chen, H., Zhao, Y., Wang, H., Zhao, Q., Yang, Z., He, H., Yue, X., Jiang, L.: Vision as a dialect: Unifying visual understanding and generation via text-aligned representations. arXiv preprint arXiv:2506.18898 (2025) 11, 12
arXiv 2025
-
[16]
arXiv preprint arXiv:2504.01934 (2025) 10
Huang, R., Wang, C., Yang, J., Lu, G., Yuan, Y., Han, J., Hou, L., Zhang, W., Hong, L., Zhao, H., et al.: Illume+: Illuminating unified mllm with dual visual tokenization and diffusion refinement. arXiv preprint arXiv:2504.01934 (2025) 10
arXiv 2025
-
[17]
arXiv preprint arXiv:1312.6114 (2013) 2
Kingma, D.P., Welling, M.: Auto-encoding variational bayes. arXiv preprint arXiv:1312.6114 (2013) 2
Pith/arXiv arXiv 2013
-
[18]
Labs, B.F.: Flux.https://github.com/black-forest-labs/flux(2024) 12
2024
-
[19]
Labs, B.F.: FLUX.2: Frontier Visual Intelligence.https://bfl.ai/blog/flux-2 (2025) 2
2025
-
[20]
Labs,B.F.,Batifol,S.,Blattmann,A.,Boesel,F.,Consul,S.,Diagne,C.,Dockhorn, T., English, J., English, Z., Esser, P., Kulal, S., Lacey, K., Levi, Y., Li, C., Lorenz, D., Müller, J., Podell, D., Rombach, R., Saini, H., Sauer, A., Smith, L.: Flux.1 kontext: Flow matching for in-context image generation and editing in latent space (2025),https://arxiv.org/abs/2...
Pith/arXiv arXiv 2025
-
[21]
arXiv preprint arXiv:2408.03326 (2024) 11
Li, B., Zhang, Y., Guo, D., Zhang, R., Li, F., Zhang, H., Zhang, K., Zhang, P., Li, Y., Liu, Z., et al.: Llava-onevision: Easy visual task transfer. arXiv preprint arXiv:2408.03326 (2024) 11
Pith/arXiv arXiv 2024
-
[22]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Li, B., Ge, Y., Ge, Y., Wang, G., Wang, R., Zhang, R., Shan, Y.: Seed- bench: Benchmarking multimodal large language models. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 13299– 13308 (2024) 11 Abbreviated paper title 17
2024
-
[23]
arXiv preprint arXiv:2506.03147 (2025) 4, 14
Lin, B., Li, Z., Cheng, X., Niu, Y., Ye, Y., He, X., Yuan, S., Yu, W., Wang, S., Ge, Y., et al.: Uniworld-v1: High-resolution semantic encoders for unified visual understanding and generation. arXiv preprint arXiv:2506.03147 (2025) 4, 14
Pith/arXiv arXiv 2025
-
[24]
arXiv preprint arXiv:2505.05422 (2025) 11
Lin, H., Wang, T., Ge, Y., Ge, Y., Lu, Z., Wei, Y., Zhang, Q., Sun, Z., Shan, Y.: Toklip: Marry visual tokens to clip for multimodal comprehension and generation. arXiv preprint arXiv:2505.05422 (2025) 11
arXiv 2025
-
[25]
Advances in neural information processing systems36, 34892–34916 (2023) 1
Liu, H., Li, C., Wu, Q., Lee, Y.J.: Visual instruction tuning. Advances in neural information processing systems36, 34892–34916 (2023) 1
2023
-
[26]
arXiv preprint arXiv:2504.17761 (2025) 14
Liu, S., Han, Y., Xing, P., Yin, F., Wang, R., Cheng, W., Liao, J., Wang, Y., Fu, H., Han, C., et al.: Step1x-edit: A practical framework for general image editing. arXiv preprint arXiv:2504.17761 (2025) 14
Pith/arXiv arXiv 2025
-
[27]
Liu, Y., Duan, H., Zhang, Y., Li, B., Zhang, S., Zhao, W., Yuan, Y., Wang, J., He, C., Liu, Z., et al.: Mmbench: Is your multi-modal model an all-around player? In: European conference on computer vision. pp. 216–233. Springer (2024) 11
2024
-
[28]
Luo, Z., Shi, F., Ge, Y., Yang, Y., Wang, L., Shan, Y.: Open-magvit2: An open-source project toward democratizing auto-regressive visual generation (2025), https://arxiv.org/abs/2409.0441010
arXiv 2025
-
[29]
arXiv preprint arXiv:2502.20321 (2025) 4
Ma, C., Jiang, Y., Wu, J., Yang, J., Yu, X., Yuan, Z., Peng, B., Qi, X.: Uni- tok: A unified tokenizer for visual generation and understanding. arXiv preprint arXiv:2502.20321 (2025) 4
arXiv 2025
-
[30]
arXiv preprint arXiv:2503.07265 (2025) 12
Niu, Y., Ning, M., Zheng, M., Jin, W., Lin, B., Jin, P., Liao, J., Ning, K., Feng, C., Zhu, B., Yuan, L.: Wise: A world knowledge-informed semantic evaluation for text-to-image generation. arXiv preprint arXiv:2503.07265 (2025) 12
Pith/arXiv arXiv 2025
-
[31]
OpenAI: Introducing 4o Image Generation (2025),https://openai.com/index/ introducing-4o-image-generation/14
2025
-
[32]
Oquab, M., Darcet, T., Moutakanni, T., Vo, H.V., Szafraniec, M., Khalidov, V., Fernandez,P.,Haziza,D.,Massa,F.,El-Nouby,A.,Howes,R.,Huang,P.Y.,Xu,H., Sharma, V., Li, S.W., Galuba, W., Rabbat, M., Assran, M., Ballas, N., Synnaeve, G., Misra, I., Jegou, H., Mairal, J., Labatut, P., Joulin, A., Bojanowski, P.: Dinov2: Learning robust visual features without ...
2023
-
[33]
arXiv preprint arXiv:2307.01952 (2023) 12
Podell, D., English, Z., Lacey, K., Blattmann, A., Dockhorn, T., Müller, J., Penna, J., Rombach, R.: Sdxl: Improving latent diffusion models for high-resolution image synthesis. arXiv preprint arXiv:2307.01952 (2023) 12
Pith/arXiv arXiv 2023
-
[34]
In: Proceedings of the Computer Vision and Pattern Recognition Con- ference
Qu, L., Zhang, H., Liu, Y., Wang, X., Jiang, Y., Gao, Y., Ye, H., Du, D.K., Yuan, Z., Wu, X.: Tokenflow: Unified image tokenizer for multimodal understanding and generation. In: Proceedings of the Computer Vision and Pattern Recognition Con- ference. pp. 2545–2555 (2025) 4, 10, 12
2025
-
[35]
Qwen, :, Yang, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Li, C., Liu, D., Huang, F., Wei, H., Lin, H., Yang, J., Tu, J., Zhang, J., Yang, J., Yang, J., Zhou, J., Lin, J., Dang, K., Lu, K., Bao, K., Yang, K., Yu, L., Li, M., Xue, M., Zhang, P., Zhu, Q., Men, R., Lin, R., Li, T., Tang, T., Xia, T., Ren, X., Ren, X., Fan, Y., Su, Y., Zhang, Y., Wa...
Pith/arXiv arXiv 2025
-
[36]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., Ommer, B.: High-resolution image synthesis with latent diffusion models. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 10684–10695 (2022) 2, 10
2022
- [37]
-
[38]
arXiv preprint arXiv:2503.14324 (2025) 10
Song, W., Wang, Y., Song, Z., Li, Y., Sun, H., Chen, W., Zhou, Z., Xu, J., Wang, J., Yu, K.: Dualtoken: Towards unifying visual understanding and generation with dual visual vocabularies. arXiv preprint arXiv:2503.14324 (2025) 10
Pith/arXiv arXiv 2025
-
[39]
Advances in neural information processing systems36, 49659–49678 (2023) 11
Sun, K., Pan, J., Ge, Y., Li, H., Duan, H., Wu, X., Zhang, R., Zhou, A., Qin, Z., Wang, Y., et al.: Journeydb: A benchmark for generative image understanding. Advances in neural information processing systems36, 49659–49678 (2023) 11
2023
-
[40]
arXiv preprint arXiv:2406.06525 (2024) 10
Sun, P., Jiang, Y., Chen, S., Zhang, S., Peng, B., Luo, P., Yuan, Z.: Autoregres- sive model beats diffusion: Llama for scalable image generation. arXiv preprint arXiv:2406.06525 (2024) 10
Pith/arXiv arXiv 2024
-
[41]
In: Proceed- ings of the IEEE/CVF conference on computer vision and pattern recognition
Sun, Q., Cui, Y., Zhang, X., Zhang, F., Yu, Q., Wang, Y., Rao, Y., Liu, J., Huang, T., Wang, X.: Generative multimodal models are in-context learners. In: Proceed- ings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 14398–14409 (2024) 4, 10
2024
-
[42]
arXiv preprint arXiv:2307.05222 (2023) 4
Sun, Q., Yu, Q., Cui, Y., Zhang, F., Zhang, X., Wang, Y., Gao, H., Liu, J., Huang, T., Wang, X.: Emu: Generative pretraining in multimodality. arXiv preprint arXiv:2307.05222 (2023) 4
Pith/arXiv arXiv 2023
-
[43]
arXiv preprint arXiv:2507.23278 (2025) 4, 10
Tang, H., Xie, C., Bao, X., Weng, T., Li, P., Zheng, Y., Wang, L.: Unilip: Adapting clip for unified multimodal understanding, generation and editing. arXiv preprint arXiv:2507.23278 (2025) 4, 10
arXiv 2025
-
[44]
Team,C.:Chameleon:Mixed-modalearly-fusionfoundationmodels.arXivpreprint arXiv:2405.09818 (2024) 4, 11
Pith/arXiv arXiv 2024
-
[45]
Tian, K., Jiang, Y., Yuan, Z., Peng, B., Wang, L.: Visual autoregressive modeling: Scalableimagegenerationvianext-scaleprediction.Advancesinneuralinformation processing systems37, 84839–84865 (2024) 2, 10
2024
-
[46]
arXiv preprint arXiv:2412.14164 (2024) 11
Tong, S., Fan, D., Zhu, J., Xiong, Y., Chen, X., Sinha, K., Rabbat, M., LeCun, Y., Xie, S., Liu, Z.: Metamorph: Multimodal understanding and generation via instruction tuning. arXiv preprint arXiv:2412.14164 (2024) 11
Pith/arXiv arXiv 2024
-
[47]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Tong, S., Liu, Z., Zhai, Y., Ma, Y., LeCun, Y., Xie, S.: Eyes wide shut? exploring the visual shortcomings of multimodal llms. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 9568–9578 (2024) 11
2024
-
[48]
arXiv preprint arXiv:2302.13971 (2023) 1
Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.A., Lacroix, T., Rozière, B., Goyal, N., Hambro, E., Azhar, F., et al.: Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971 (2023) 1
Pith/arXiv arXiv 2023
-
[49]
Advances in neural information processing systems30(2017) 4
Van Den Oord, A., Vinyals, O., et al.: Neural discrete representation learning. Advances in neural information processing systems30(2017) 4
2017
-
[50]
arXiv preprint arXiv:2508.18265 (2025) 1
Wang, W., Gao, Z., Gu, L., Pu, H., Cui, L., Wei, X., Liu, Z., Jing, L., Ye, S., Shao, J., et al.: Internvl3.5: Advancing open-source multimodal models in versatility, reasoning, and efficiency. arXiv preprint arXiv:2508.18265 (2025) 1
Pith/arXiv arXiv 2025
-
[51]
arXiv preprint arXiv:2409.18869 (2024) 11, 12
Wang, X., Zhang, X., Luo, Z., Sun, Q., Cui, Y., Wang, J., Zhang, F., Wang, Y., Li, Z., Yu, Q., et al.: Emu3: Next-token prediction is all you need. arXiv preprint arXiv:2409.18869 (2024) 11, 12
Pith/arXiv arXiv 2024
-
[52]
arXiv preprint arXiv:2507.21033 (2025) 11
Wang, Y., Yang, S., Zhao, B., Zhang, L., Liu, Q., Zhou, Y., Xie, C.: Gpt- image-edit-1.5 m: A million-scale, gpt-generated image dataset. arXiv preprint arXiv:2507.21033 (2025) 11
arXiv 2025
-
[53]
arXiv preprint arXiv:2506.18871 (2025) 14
Wu, C., Zheng, P., Yan, R., Xiao, S., Luo, X., Wang, Y., Li, W., Jiang, X., Liu, Y., Zhou, J., et al.: Omnigen2: Exploration to advanced multimodal generation. arXiv preprint arXiv:2506.18871 (2025) 14
Pith/arXiv arXiv 2025
-
[54]
arXiv preprint arXiv:2505.23661 (2025) 4, 12 Abbreviated paper title 19
Wu, S., Wu, Z., Gong, Z., Tao, Q., Jin, S., Li, Q., Li, W., Loy, C.C.: Openuni: A simple baseline for unified multimodal understanding and generation. arXiv preprint arXiv:2505.23661 (2025) 4, 12 Abbreviated paper title 19
arXiv 2025
-
[55]
Wu, S., Zhang, W., Xu, L., Jin, S., Wu, Z., Tao, Q., Liu, W., Li, W., Loy, C.C.: Harmonizing visual representations for unified multimodal understanding and gen- eration (2025),https://arxiv.org/abs/2503.2197911, 12
arXiv 2025
-
[56]
arXiv preprint arXiv:2409.04429 (2024) 4, 10, 11, 12
Wu, Y., Zhang, Z., Chen, J., Tang, H., Li, D., Fang, Y., Zhu, L., Xie, E., Yin, H., Yi, L., et al.: Vila-u: a unified foundation model integrating visual understanding and generation. arXiv preprint arXiv:2409.04429 (2024) 4, 10, 11, 12
Pith/arXiv arXiv 2024
-
[57]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Xiao, S., Wang, Y., Zhou, J., Yuan, H., Xing, X., Yan, R., Li, C., Wang, S., Huang, T., Liu, Z.: Omnigen: Unified image generation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 13294–13304 (2025) 14
2025
-
[58]
Xie, E., Chen, J., Chen, J., Cai, H., Tang, H., Lin, Y., Zhang, Z., Li, M., Zhu, L., Lu, Y., Han, S.: Sana: Efficient high-resolution image synthesis with linear diffusion transformer (2024),https://arxiv.org/abs/2410.1062910, 12
Pith/arXiv arXiv 2024
-
[59]
arXiv preprint arXiv:2408.12528 (2024) 4, 11
Xie, J., Mao, W., Bai, Z., Zhang, D.J., Wang, W., Lin, K.Q., Gu, Y., Chen, Z., Yang, Z., Shou, M.Z.: Show-o: One single transformer to unify multimodal under- standing and generation. arXiv preprint arXiv:2408.12528 (2024) 4, 11
Pith/arXiv arXiv 2024
-
[60]
arXiv preprint arXiv:2506.15564 (2025) 12
Xie,J.,Yang,Z.,Shou,M.Z.:Show-o2:Improvednativeunifiedmultimodalmodels. arXiv preprint arXiv:2506.15564 (2025) 12
Pith/arXiv arXiv 2025
-
[61]
arXiv preprint arXiv:2505.09388 (2025) 1
Yang, A., Li, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Gao, C., Huang, C., Lv, C., Zheng, C., Liu, D., Zhou, F., Huang, F., Hu, F., Ge, H., Wei, H., Lin, H., Tang, J., Yang, J., Tu, J., Zhang, J., Yang, J., Yang, J., Zhou, J., Zhou, J., Lin, J., Dang, K., Bao, K., Yang, K., Yu, L., Deng, L., Li, M., Xue, M., Li, M., Zhang, P., Wang, P., Zhu, Q...
Pith/arXiv arXiv 2025
-
[62]
generation: Taming optimization dilemma in latent diffusion models
Yao, J., Yang, B., Wang, X.: Reconstruction vs. generation: Taming optimization dilemma in latent diffusion models. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 15703–15712 (2025) 2, 3, 10
2025
-
[63]
Yu, L., Shi, B., Pasunuru, R., Muller, B., Golovneva, O., Wang, T., Babu, A., Tang, B., Karrer, B., Sheynin, S., Ross, C., Polyak, A., Howes, R., Sharma, V., Xu, P., Tamoyan, H., Ashual, O., Singer, U., Li, S.W., Zhang, S., James, R., Ghosh, G., Taigman, Y., Fazel-Zarandi, M., Celikyilmaz, A., Zettlemoyer, L., Aghajanyan, A.: Scaling autoregressive multi-...
arXiv 2023
-
[64]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Yu, Q., Chow, W., Yue, Z., Pan, K., Wu, Y., Wan, X., Li, J., Tang, S., Zhang, H., Zhuang, Y.: Anyedit: Mastering unified high-quality image editing for any idea. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 26125–26135 (2025) 14
2025
-
[65]
Advances in Neural Information Processing Systems37, 128940–128966 (2024) 2
Yu, Q., Weber, M., Deng, X., Shen, X., Cremers, D., Chen, L.C.: An image is worth 32 tokens for reconstruction and generation. Advances in Neural Information Processing Systems37, 128940–128966 (2024) 2
2024
-
[66]
In: International Conference on Learning Representations (2025) 2, 3, 4
Yu, S., Kwak, S., Jang, H., Jeong, J., Huang, J., Shin, J., Xie, S.: Representation alignment for generation: Training diffusion transformers is easier than you think. In: International Conference on Learning Representations (2025) 2, 3, 4
2025
-
[67]
arXiv preprint arXiv:2308.02490 (2023) 11
Yu, W., Yang, Z., Li, L., Wang, J., Lin, K., Liu, Z., Wang, X., Wang, L.: Mm- vet: Evaluating large multimodal models for integrated capabilities. arXiv preprint arXiv:2308.02490 (2023) 11
Pith/arXiv arXiv 2023
-
[68]
Li et al
Yue, X., Ni, Y., Zhang, K., Zheng, T., Liu, R., Zhang, G., Stevens, S., Jiang, D., Ren, W., Sun, Y., et al.: Mmmu: A massive multi-discipline multimodal 20 H. Li et al. understanding and reasoning benchmark for expert agi. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 9556–9567 (2024) 11
2024
-
[69]
arXiv preprint arXiv:2510.10575 (2025) 4
Yue, Z., Zhang, H., Zeng, X., Chen, B., Wang, C., Zhuang, S., Dong, L., Du, K., Wang, Y., Wang, L., et al.: Uniflow: A unified pixel flow tokenizer for visual understanding and generation. arXiv preprint arXiv:2510.10575 (2025) 4
arXiv 2025
-
[70]
Advances in Neural Information Pro- cessing Systems36, 31428–31449 (2023) 14
Zhang, K., Mo, L., Chen, W., Sun, H., Su, Y.: Magicbrush: A manually annotated dataset for instruction-guided image editing. Advances in Neural Information Pro- cessing Systems36, 31428–31449 (2023) 14
2023
-
[71]
arXiv preprint arXiv:2512.17909 (2025) 3, 4
Zhang, S., Zhang, H., Zhang, Z., Ge, C., Xue, S., Liu, S., Ren, M., Kim, S.Y., Zhou, Y., Liu, Q., et al.: Both semantics and reconstruction matter: Making repre- sentation encoders ready for text-to-image generation and editing. arXiv preprint arXiv:2512.17909 (2025) 3, 4
arXiv 2025
-
[72]
Zhang, Z., Xie, J., Lu, Y., Yang, Z., Yang, Y.: Enabling instructional image editing within-contextgenerationinlargescalediffusiontransformer.In:TheThirty-ninth Annual Conference on Neural Information Processing Systems (2025) 14
2025
-
[73]
Advances in Neural Information Processing Systems37, 3058–3093 (2024) 14
Zhao, H., Ma, X.S., Chen, L., Si, S., Wu, R., An, K., Yu, P., Zhang, M., Li, Q., Chang, B.: Ultraedit: Instruction-based fine-grained image editing at scale. Advances in Neural Information Processing Systems37, 3058–3093 (2024) 14
2024
-
[74]
arXiv preprint arXiv:2510.11690 (2025) 2, 4, 10
Zheng, B., Ma, N., Tong, S., Xie, S.: Diffusion transformers with representation autoencoders. arXiv preprint arXiv:2510.11690 (2025) 2, 4, 10
Pith/arXiv arXiv 2025
-
[75]
arXiv preprint arXiv:2408.11039 (2024) 4
Zhou, C., Yu, L., Babu, A., Tirumala, K., Yasunaga, M., Shamis, L., Kahn, J., Ma, X., Zettlemoyer, L., Levy, O.: Transfusion: Predict the next token and diffuse images with one multi-modal model. arXiv preprint arXiv:2408.11039 (2024) 4
Pith/arXiv arXiv 2024
-
[76]
arXiv preprint arXiv:2504.10479 (2025) 10, 11
Zhu, J., Wang, W., Chen, Z., Liu, Z., Ye, S., Gu, L., Tian, H., Duan, Y., Su, W., Shao, J., et al.: Internvl3: Exploring advanced training and test-time recipes for open-source multimodal models. arXiv preprint arXiv:2504.10479 (2025) 10, 11
Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.