Capacity-Controlled Multi-View Stylization of 3D Gaussian Splatting
Pith reviewed 2026-06-26 05:19 UTC · model grok-4.3
The pith
Reformulating local style matching as a semi-balanced optimal transport problem with explicit column-capacity constraints enables controllable and consistent multi-view stylization of 3D Gaussian Splatting.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
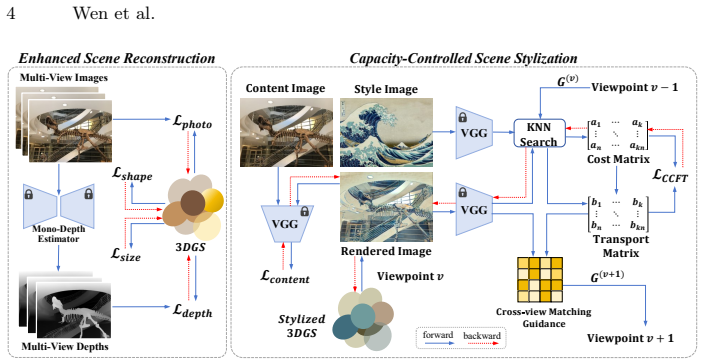
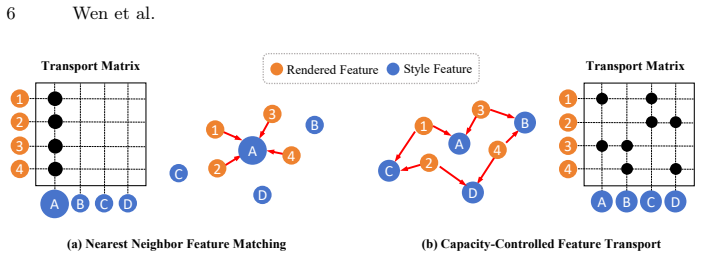
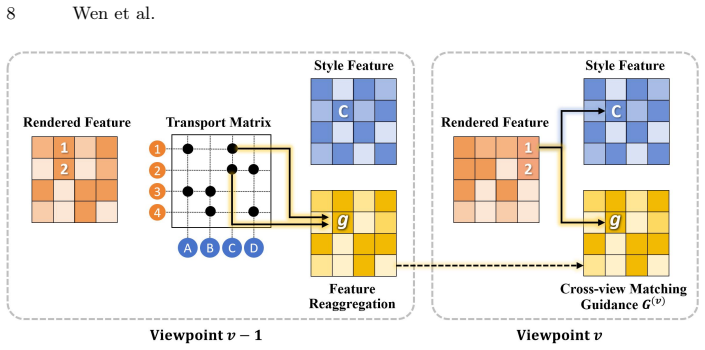
We propose a capacity-controlled framework for multi-view stylization of 3DGS, grounded in optimal transport. Specifically, we reformulate local style matching as a semi-balanced optimal transport problem. By introducing explicit column-capacity constraints with tunable strength, our formulation mitigates many-to-one matching and enables controllable allocation of style features. This transport-based objective provides a principled mechanism for balancing feature coverage and stylistic diversity while maintaining stable correspondences across viewpoints. To further enhance cross-view coherence, we incorporate a novel cross-view matching guidance to constrain correspondences between scene con
What carries the argument
Semi-balanced optimal transport problem with explicit tunable column-capacity constraints, which controls allocation of style features to scene points.
If this is right
- Mitigates many-to-one matching and enables controllable allocation of style features.
- Balances feature coverage and stylistic diversity while maintaining stable cross-view correspondences.
- Enhances cross-view coherence through novel matching guidance between scene content and style patterns.
- Allows optimized Gaussian primitives to represent finer-grained textures via added geometric regularizations.
- Produces stable, expressive 3D stylizations that preserve the core semantic structure of the scene.
Where Pith is reading between the lines
- The tunable capacity strength could be adapted as a user control for trading off between stylistic fidelity and scene preservation in editing tools.
- The transport formulation might reduce temporal flickering if extended to time-varying 3D content such as animated scenes.
- Cross-view guidance could generalize to other explicit 3D representations that suffer from view-dependent style drift.
Load-bearing premise
That reformulating style matching as a semi-balanced optimal transport problem with explicit column-capacity constraints will inherently provide a principled mechanism for balancing feature coverage, stylistic diversity, and stable cross-view correspondences without introducing new inconsistencies or artifacts.
What would settle it
A side-by-side comparison of rendered stylized views from multiple angles that measures whether the frequency of many-to-one feature reuse drops and cross-view style consistency scores rise compared to independent per-view feature-matching baselines.
Figures







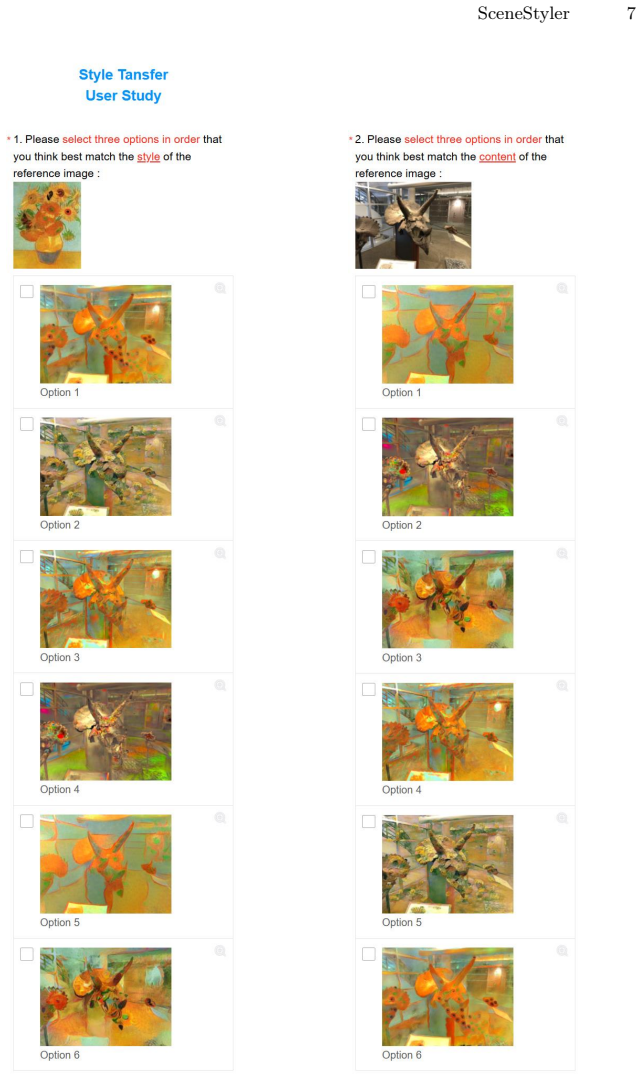

read the original abstract
While 3D Gaussian Splatting (3DGS) provides an efficient and explicit representation for novel view synthesis, enforcing stylistic coherence across viewpoints remains challenging. Existing 3D stylization methods typically apply 2D feature-matching losses independently per rendered view, which leads to unstable style allocation, many-to-one feature reuse, and limited cross-view consistency. We propose a capacity-controlled framework for multi-view stylization of 3DGS, grounded in optimal transport. Specifically, we reformulate local style matching as a semi-balanced optimal transport problem. By introducing explicit column-capacity constraints with tunable strength, our formulation mitigates many-to-one matching and enables controllable allocation of style features. This transport-based objective provides a principled mechanism for balancing feature coverage and stylistic diversity while maintaining stable correspondences across viewpoints. To further enhance cross-view coherence, we incorporate a novel cross-view matching guidance to constrain correspondences between scene content and style patterns. In addition, we introduce several geometric regularizations to enhance the vanilla 3DGS, thereby enabling optimized Gaussian primitives to represent finer-grained textures during stylization. Extensive experiments demonstrate that our approach significantly improves multi-view stylistic consistency and produces stable, expressive 3D stylizations while preserving the core semantic structure of the scene.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a capacity-controlled framework for multi-view stylization of 3D Gaussian Splatting (3DGS). It reformulates local style matching as a semi-balanced optimal transport problem with explicit column-capacity constraints of tunable strength to mitigate many-to-one matching and enable controllable style feature allocation. The transport objective is claimed to balance feature coverage, stylistic diversity, and stable cross-view correspondences; this is augmented by a novel cross-view matching guidance term and geometric regularizations on the 3DGS primitives. Extensive experiments are stated to demonstrate improved multi-view stylistic consistency while preserving scene semantics.
Significance. If the experimental validation holds, the work offers a novel application of capacity-constrained optimal transport to 3D stylization, potentially addressing limitations of independent per-view 2D feature matching. The explicit controllability via capacity constraints and the combination with cross-view guidance represent a concrete technical contribution to consistency in explicit 3D representations.
major comments (1)
- [Abstract] Abstract: The central claim that the semi-balanced OT objective with column-capacity constraints 'provides a principled mechanism for ... maintaining stable correspondences across viewpoints' is load-bearing yet appears undercut by the immediate follow-on statement that a separate 'novel cross-view matching guidance' is incorporated 'to further enhance cross-view coherence'. This raises a correctness-risk concern that the OT formulation alone may not deliver the attributed cross-view stability, requiring either stronger justification or rephrasing of the attribution in the abstract and §3/§4.
minor comments (1)
- [Abstract] Abstract: The phrase 'several geometric regularizations' is introduced without enumeration or reference to the specific equations; this should be expanded with a brief list or pointer to the relevant section for immediate clarity.
Simulated Author's Rebuttal
We thank the referee for the detailed comment on the abstract. We address the concern regarding attribution of cross-view stability below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that the semi-balanced OT objective with column-capacity constraints 'provides a principled mechanism for ... maintaining stable correspondences across viewpoints' is load-bearing yet appears undercut by the immediate follow-on statement that a separate 'novel cross-view matching guidance' is incorporated 'to further enhance cross-view coherence'. This raises a correctness-risk concern that the OT formulation alone may not deliver the attributed cross-view stability, requiring either stronger justification or rephrasing of the attribution in the abstract and §3/§4.
Authors: We agree that the current abstract phrasing risks implying that the semi-balanced OT with column-capacity constraints alone fully delivers cross-view stability, which could be read as overstated given the subsequent addition of the cross-view guidance term. The capacity constraints are intended to reduce many-to-one matching and thereby support more consistent feature allocation across views, but they do not explicitly enforce inter-view correspondence constraints. To resolve this, we will revise the abstract (and the corresponding descriptions in §3 and §4) to more precisely state that the OT objective balances coverage and diversity while contributing to stable allocations, with the novel cross-view matching guidance added as an explicit mechanism to further strengthen coherence. This rephrasing will clarify the complementary roles without changing the technical claims. revision: yes
Circularity Check
No circularity; claims rest on standard OT reformulation with no self-referential equations or load-bearing self-citations shown.
full rationale
The provided abstract and description contain no equations, derivations, or self-citations that reduce any prediction or result to its inputs by construction. The reformulation as semi-balanced OT with column-capacity constraints is presented as a modeling choice, supplemented by separate cross-view guidance and geometric regularizations. No fitted-input-called-prediction, self-definitional, or uniqueness-imported patterns are observable. This matches the default expectation of a self-contained proposal without circular steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Asim, M., Wewer, C., Wimmer, T., Schiele, B., Lenssen, J.E.: Met3r: measuring multi-view consistency in generated images. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 6034–6044 (2025)
2025
-
[2]
In: IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Barron, J.T., Mildenhall, B., Verbin, D., Srinivasan, P.P., Hedman, P.: Mip-nerf 360: Unbounded anti-aliased neural radiance fields. In: IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 5460–5469 (2022)
2022
-
[3]
In: European conference on computer vision (ECCV)
Chen, A., Xu, Z., Geiger, A., Yu, J., Su, H.: Tensorf: Tensorial radiance fields. In: European conference on computer vision (ECCV). pp. 333–350 (2022)
2022
-
[4]
IEEE Transactions on Image Processing (TIP)34, 7193–7208 (2025)
Chen, W., Zha, Z., Wang, S., Ali, L., Wen, B., Yuan, X., Zhou, J., Zhu, C.: Texture- consistent 3d scene style transfer via transformer-guided neural radiance fields. IEEE Transactions on Image Processing (TIP)34, 7193–7208 (2025)
2025
-
[5]
In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV)
Chiang, P.Z., Tsai, M.S., Tseng, H.Y., Lai, W.S., Chiu, W.C.: Stylizing 3d scene via implicit representation and hypernetwork. In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV). pp. 1475–1484 (2022)
2022
-
[6]
arXiv preprint arXiv:1607.05816 (2016)
Chizat, L., Peyré, G., Schmitzer, B., Vialard, F.X.: Scaling algorithms for unbal- anced transport problems. arXiv preprint arXiv:1607.05816 (2016)
Pith/arXiv arXiv 2016
-
[7]
In: Advances in Neural Information Processing Systems (NIPS)
Cuturi, M.: Sinkhorn distances: Lightspeed computation of optimal transport. In: Advances in Neural Information Processing Systems (NIPS). pp. 2292–2300 (2013)
2013
-
[8]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Galerne, B., Wang, J., Raad, L., Morel, J.M.: Sgsst: Scaling gaussian splatting style transfer. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 26535–26544 (2025)
2025
-
[9]
In: Proceedings of the IEEE conference on computer vision and pattern recognition (CVPR)
Gatys, L.A., Ecker, A.S., Bethge, M.: Image style transfer using convolutional neural networks. In: Proceedings of the IEEE conference on computer vision and pattern recognition (CVPR). pp. 2414–2423 (2016)
2016
-
[10]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Heitz, E., Vanhoey, K., Chambon, T., Belcour, L.: A sliced wasserstein loss for neu- ral texture synthesis. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 9412–9420 (2021)
2021
-
[11]
Howil, K., Borycki, P., Dziarmaga, T., Mazur, M., Spurek, P., et al.: Clipgaussian: Universalandmultimodalstyletransferbasedongaussiansplatting.arXivpreprint arXiv:2505.22854 (2025) 16 Wen et al
arXiv 2025
-
[12]
In: Proceedings of the IEEE international conference on computer vision (ICCV)
Huang, X., Belongie, S.: Arbitrary style transfer in real-time with adaptive instance normalization. In: Proceedings of the IEEE international conference on computer vision (ICCV). pp. 1501–1510 (2017)
2017
-
[13]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Huang, Y.H., He, Y., Yuan, Y.J., Lai, Y.K., Gao, L.: Stylizednerf: consistent 3d scene stylization as stylized nerf via 2d-3d mutual learning. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 18342–18352 (2022)
2022
-
[14]
Kantorovich, L.V.: On the translocation of masses. Dokl. Akad. Nauk. USSR (NS) 37, 199–201 (1942)
1942
-
[15]
ACM Transactions on Graphics (TOG)42(4) (July 2023)
Kerbl, B., Kopanas, G., Leimkühler, T., Drettakis, G.: 3d gaussian splatting for real-time radiance field rendering. ACM Transactions on Graphics (TOG)42(4) (July 2023)
2023
-
[16]
In: Proceedings of the aaai conference on artificial intelligence (AAAI)
Kim, G., Youwang, K., Oh, T.H.: Fprf: Feed-forward photorealistic style transfer of large-scale 3d neural radiance fields. In: Proceedings of the aaai conference on artificial intelligence (AAAI). pp. 2750–2758 (2024)
2024
-
[17]
ACM Transactions on Graphics (TOG)36(4), 1– 13 (2017)
Knapitsch, A., Park, J., Zhou, Q.Y., Koltun, V.: Tanks and temples: benchmarking large-scale scene reconstruction. ACM Transactions on Graphics (TOG)36(4), 1– 13 (2017)
2017
-
[18]
Kolkin, N., Salavon, J., Shakhnarovich, G.: Style transfer by relaxed optimal trans- portandself-similarity.In:ProceedingsoftheIEEE/CVFConferenceonComputer Vision and Pattern Recognition (CVPR). pp. 10051–10060 (2019)
2019
-
[19]
In: Computer Graphics Forum
Kovács, Á.S., Hermosilla, P., Raidou, R.G.: G-style: Stylized gaussian splatting. In: Computer Graphics Forum. vol. 43, p. e15259. Wiley Online Library (2024)
2024
-
[20]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Li, C., Wand, M.: Combining markov random fields and convolutional neural net- works for image synthesis. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 2479–2486 (2016)
2016
-
[21]
In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV)
Li, W., Wu, T., Zhong, F., Oztireli, C.: Arf-plus: Controlling perceptual factors in artistic radiance fields for 3d scene stylization. In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV). pp. 2301–2310 (2025)
2025
-
[22]
In: Proceedings of the AAAI Conference on Artificial Intelligence (AAAI)
Lin, Y., Lei, J., Jia, K.: Multi-stylegs: stylizing gaussian splatting with multiple styles. In: Proceedings of the AAAI Conference on Artificial Intelligence (AAAI). pp. 5289–5297 (2025)
2025
-
[23]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Liu, K., Zhan, F., Chen, Y., Zhang, J., Yu, Y., El Saddik, A., Lu, S., Xing, E.P.: Stylerf: Zero-shot 3d style transfer of neural radiance fields. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 8338–8348 (2023)
2023
-
[24]
In: SIGGRAPH Asia 2024 Technical Communications
Liu, K., Zhan, F., Xu, M., Theobalt, C., Shao, L., Lu, S.: Stylegaussian: Instant 3d style transfer with gaussian splatting. In: SIGGRAPH Asia 2024 Technical Communications. pp. 1–4 (2024)
2024
-
[25]
IEEE International Conference on Multi- media and Expo (ICME) (2025)
Liu, W., Liu, Z., Yang, X., Sha, M., Li, Y.: Abc-gs: Alignment-based controllable style transfer for 3d gaussian splatting. IEEE International Conference on Multi- media and Expo (ICME) (2025)
2025
-
[26]
ACM Transactions on Graphics (TOG)38(4), 1–14 (2019)
Mildenhall, B., Srinivasan, P.P., Ortiz-Cayon, R., Kalantari, N.K., Ramamoorthi, R., Ng, R., Kar, A.: Local light field fusion: practical view synthesis with pre- scriptive sampling guidelines. ACM Transactions on Graphics (TOG)38(4), 1–14 (2019)
2019
-
[27]
In: Eu- ropean Conference on Computer Vision (ECCV)
Mildenhall, B., Srinivasan, P.P., Tancik, M., Barron, J.T., Ramamoorthi, R., Ng, R.: Nerf: Representing scenes as neural radiance fields for view synthesis. In: Eu- ropean Conference on Computer Vision (ECCV). pp. 405–421 (2020) SceneStyler 17
2020
-
[28]
Monge, G.: Mémoire sur la théorie des déblais et des remblais. Mem. Math. Phys. Acad. Royale Sci. pp. 666–704 (1781)
-
[29]
ACM Transactions on Graphics (TOG)41(4), 1– 15 (2022)
Müller,T.,Evans,A.,Schied,C.,Keller,A.:Instantneuralgraphicsprimitiveswith a multiresolution hash encoding. ACM Transactions on Graphics (TOG)41(4), 1– 15 (2022)
2022
-
[30]
ACM Transactions on Graphics (TOG)41(4), 1–11 (2022)
Nguyen-Phuoc, T., Liu, F., Xiao, L.: Snerf: stylized neural implicit representations for 3d scenes. ACM Transactions on Graphics (TOG)41(4), 1–11 (2022)
2022
-
[31]
In: International conference on machine learning (ICML)
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al.: Learning transferable visual models from natural language supervision. In: International conference on machine learning (ICML). pp. 8748–8763 (2021)
2021
-
[32]
arXiv preprint arXiv:1701.08893 (2017)
Risser, E., Wilmot, P., Barnes, C.: Stable and controllable neural texture synthesis and style transfer using histogram losses. arXiv preprint arXiv:1701.08893 (2017)
Pith/arXiv arXiv 2017
-
[33]
In: International Conference on Learning Representations (ICLR) (2015)
Simonyan, K., Zisserman, A.: Very deep convolutional networks for large-scale im- age recognition. In: International Conference on Learning Representations (ICLR) (2015)
2015
-
[34]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Tumanyan, N., Bar-Tal, O., Bagon, S., Dekel, T.: Splicing vit features for semantic appearance transfer. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 10748–10757 (2022)
2022
-
[35]
In: DAGM German Conference on Pattern Recognition (GCPR)
Wright, M., Ommer, B.: Artfid: Quantitative evaluation of neural style transfer. In: DAGM German Conference on Pattern Recognition (GCPR). p. 560–576 (2022)
2022
-
[36]
arXiv preprint arXiv:2403.08310 (2024)
Xu, H., Chen, W., Xiao, F., Sun, B., Kang, W.: Styledyrf: Zero-shot 4d style transfer for dynamic neural radiance fields. arXiv preprint arXiv:2403.08310 (2024)
arXiv 2024
-
[37]
In: Proceedings of the 38th International Conference on Neural Information Processing Systems (NeurIPS)
Yang, L., Kang, B., Huang, Z., Zhao, Z., Xu, X., Feng, J., Zhao, H.: Depth anything v2. In: Proceedings of the 38th International Conference on Neural Information Processing Systems (NeurIPS). pp. 21875–21911 (2024)
2024
-
[38]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (CVPR)
Yu, A., Fridovich-Keil, S., Tancik, M., Chen, Q., Recht, B., Kanazawa, A.: Plenox- els: Radiance fields without neural networks. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (CVPR). pp. 5501–5510 (2022)
2022
-
[39]
IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI)47(12), 11961–11973 (2025)
Zhang, D., Yuan, Y.J., Chen, Z., Zhang, F.L., He, Z., Shan, S., Gao, L.: Stylizedgs: Controllable stylization for 3d gaussian splatting. IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI)47(12), 11961–11973 (2025)
2025
-
[40]
In: European Conference on Computer Vision (ECCV)
Zhang, K., Kolkin, N., Bi, S., Luan, F., Xu, Z., Shechtman, E., Snavely, N.: Arf: Artistic radiance fields. In: European Conference on Computer Vision (ECCV). pp. 717–733 (2022)
2022
-
[41]
arXiv preprint arXiv:2010.07492 (2020)
Zhang, K., Riegler, G., Snavely, N., Koltun, V.: Nerf++: Analyzing and improving neural radiance fields. arXiv preprint arXiv:2010.07492 (2020)
arXiv 2010
-
[42]
Zhou, Y., Chen, K., Xiao, R., Huang, H.: Neural texture synthesis with guided correspondence.In:Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 18095–18104 (2023)
2023
-
[43]
In: In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Zhou, Y., Chen, Z., Huang, H.: Deformable one-shot face stylization via dino se- mantic guidance. In: In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 7787–7796 (2024)
2024
-
[44]
Zhou, Y., Gao, X., Chen, Z., Huang, H.: Attention distillation: A unified approach to visual characteristics transfer. In: In Proceedings of the Computer Vision and Pattern Recognition Conference (CVPR). pp. 18270–18280 (2025) SceneStyler 1 A Supplementary Material This supplementary material contains additional details or results about our implementation...
arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.