Towards Dys-XAI: Influence-Based Explanations for Dysarthria Severity Assessment
Pith reviewed 2026-06-26 14:29 UTC · model grok-4.3
The pith
Gradient-based influence scores identify supportive and competing training samples to explain dysarthria severity predictions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Using gradient-based influence approximations, per-utterance influence scores can be computed to identify supportive and competing training samples for each prediction in dysarthria severity assessment, providing auditable explanations by linking decisions to perceptible reference cases.
What carries the argument
Gradient-based influence approximations that generate per-utterance influence scores to distinguish supportive from competing training utterances.
If this is right
- Removing 5-20% of highly influential training samples systematically shifts the model's severity predictions.
- Explanations become more interpretable for clinicians by referencing actual speech samples rather than feature scores.
- The framework enables auditing of model decisions through traceable influences from training data.
Where Pith is reading between the lines
- Such influence explanations might help standardize severity ratings across different clinicians by providing consistent reference points.
- Applying this to other clinical speech tasks could improve trust in AI-assisted diagnostics.
- Integration into therapy software could allow real-time feedback on why a severity level was assigned.
Load-bearing premise
That removing 5-20% of highly influential training samples in controlled deletion experiments will systematically shift predictions in a manner that validates the influence scores as faithful explanations.
What would settle it
A deletion experiment in which removing the highest-influence samples leaves the severity prediction unchanged or shifts it in the opposite direction from what the influence scores predict.
Figures

read the original abstract
Dysarthria severity assessment is essential for therapy planning and longitudinal monitoring, yet manual perceptual rating is time-consuming and variable across clinicians. Although deep learning models achieve strong performance, their black-box nature limits clinical adoption. Existing speech explainability methods typically provide acoustic feature importance scores that are difficult for end-users to interpret. We propose an influence-based, instance-level explainability framework that explains each decision through supportive and competing training samples. Using gradient-based influence approximations, we compute per-utterance influence scores to identify supportive and competing training samples for each prediction. Controlled deletion experiments from 5 to 20 percent validate the explanations, showing that removing highly influential samples systematically shifts predictions. This approach provides auditable explanations by linking decisions to perceptible reference cases.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Dys-XAI, an influence-based instance-level explainability framework for deep learning models in dysarthria severity assessment. It computes per-utterance influence scores via gradient-based approximations to identify supportive and competing training samples for each prediction, with validation via controlled deletion experiments (removing 5-20% of highly influential samples) that show systematic prediction shifts, aiming to provide auditable explanations linked to perceptible reference cases rather than acoustic feature importances.
Significance. If the influence scores prove faithful, the method could advance clinical adoption of speech models by offering instance-level, human-interpretable explanations tied to reference utterances, addressing limitations of existing feature-based XAI approaches in a high-stakes domain like therapy planning and monitoring.
major comments (2)
- [Abstract] Abstract: The validation claim rests on deletion experiments showing that removing 5-20% highly influential samples 'systematically shifts predictions,' but provides no details on controls (random deletion of equal size or low-influence samples) or quantitative outcomes (e.g., magnitude of shifts, statistical tests). Without these, observed shifts could reflect general data sensitivity in non-convex speech models rather than specific faithfulness of the gradient-based influence ranking, undermining the auditable-explanation claim.
- [Abstract] Abstract: The method relies on standard first-order gradient influence approximations, which lack strong guarantees in non-convex settings typical of speech severity models; the paper does not address approximation error or provide any comparison to more accurate (but costlier) influence methods to support the faithfulness needed for clinical use.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting areas where the abstract could better convey experimental controls and methodological limitations. We respond point-by-point below and will revise the manuscript to address the concerns.
read point-by-point responses
-
Referee: [Abstract] Abstract: The validation claim rests on deletion experiments showing that removing 5-20% highly influential samples 'systematically shifts predictions,' but provides no details on controls (random deletion of equal size or low-influence samples) or quantitative outcomes (e.g., magnitude of shifts, statistical tests). Without these, observed shifts could reflect general data sensitivity in non-convex speech models rather than specific faithfulness of the gradient-based influence ranking, undermining the auditable-explanation claim.
Authors: We agree the abstract's brevity omits these details. The full manuscript (Section 4.3) reports controlled experiments comparing high-influence removals against random deletions of equal size and low-influence samples, with larger systematic shifts for influential samples (quantified via mean absolute prediction change) and statistical significance via paired tests. We will revise the abstract to briefly note the use of random and low-influence controls plus the observed shift magnitudes, clarifying that the ranking demonstrates specificity beyond general sensitivity. revision: yes
-
Referee: [Abstract] Abstract: The method relies on standard first-order gradient influence approximations, which lack strong guarantees in non-convex settings typical of speech severity models; the paper does not address approximation error or provide any comparison to more accurate (but costlier) influence methods to support the faithfulness needed for clinical use.
Authors: The comment accurately identifies a limitation of first-order approximations in non-convex regimes. The manuscript cites supporting literature on their practical utility but does not quantify approximation error or benchmark against higher-order methods. We will expand the discussion in Section 3 to explicitly address approximation error and note the computational trade-offs, while acknowledging this constrains claims of faithfulness for high-stakes clinical deployment. revision: partial
Circularity Check
No significant circularity detected
full rationale
The paper applies standard gradient-based influence approximations to derive per-utterance influence scores and uses controlled deletion experiments (5-20%) as an independent validation step. No derivation step reduces by construction to the target result via self-definition, fitted inputs renamed as predictions, or load-bearing self-citations. The central claims rest on external ML influence methods and falsifiable deletion tests rather than internal equivalence to inputs.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Gradient-based influence approximations faithfully identify supportive and competing training samples for model predictions
- domain assumption Systematic prediction shifts after removing influential samples validate the explanations
Reference graph
Works this paper leans on
-
[1]
why a particular severity level was assigned
Introduction Dysarthria severity assessment aims to quantify the degree of speech motor impairment in individuals, playing a critical role in clinical therapy planning, rehabilitation monitoring, and lon- gitudinal disease tracking [1, 2]. In current clinical practice, severity is commonly judged via auditory–perceptual rating protocols, which are time-co...
Pith/arXiv arXiv 2026
-
[2]
Task formulation We follow the severity annotation provided in TORGO [9] and formulate dysarthria severity assessment as a 4-class or- dinal classification task
Methodology 2.1. Task formulation We follow the severity annotation provided in TORGO [9] and formulate dysarthria severity assessment as a 4-class or- dinal classification task. Given an utterancex, the label is y∈ {0,1,2,3}, corresponding to{typical, mild, moderate, and severe}dysarthria (with moderate-to-severe merged into severe). The training set isD...
-
[3]
We conduct experiments on the TORGO [9], a widely used English dysarthric dataset, which contains approximately 21 hours of recordings from 15 speakers
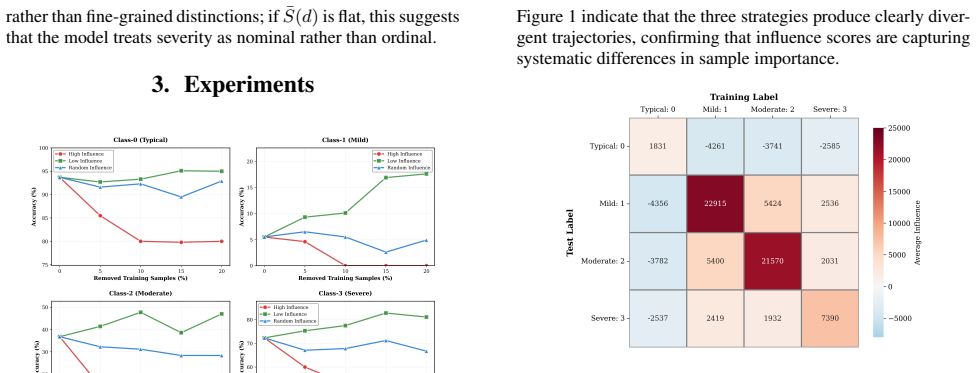
Experiments Figure 1:Validation from controlled deletion strategies indicate performance changes across severity levels.•: high influence removal.■: low influence removal.▲: random removal. We conduct experiments on the TORGO [9], a widely used English dysarthric dataset, which contains approximately 21 hours of recordings from 15 speakers. TORGO includes...
-
[4]
For the controlled deletion experiments, we use the same model archi- tecture and training protocol on the modified training sets
with a learning rate of 3e-4 and a batch size of 32. For the controlled deletion experiments, we use the same model archi- tecture and training protocol on the modified training sets
-
[5]
Our results summarise the faithfulness of our proposed influence scores via a set of con- trolled deletion experiments
Results and discussion We present the outcome of evaluating our explanation frame- work quantitatively and qualitatively. Our results summarise the faithfulness of our proposed influence scores via a set of con- trolled deletion experiments. Finally, we present our analysis of cross-severity influence patterns and qualitative case studies. 4.1. Validation...
2031
-
[6]
Conclusion We proposed an influence-based instance-level explainability framework for dysarthria severity assessment that explains each prediction through training utterances that provide supporting and opposing evidence/influence, enabling perceptual verifica- tion via reference audio examples. Through controlled dele- tion experiments, we validated that...
-
[7]
Acknowledgements This work was supported by the Engineering and Physical Sci- ences Research Council (EPSRC) through the National Edge AI Hub for Real Data: Edge Intelligence for Cyberdisturbances and Data Quality (EP/Y028813/1) and Responsible AI UK (EP/Y009800/1)
-
[8]
Generative AI Tools Disclosure Generative artificial intelligence tools were used solely to assist with language editing and clarity of presentation. All research ideas, methodology, experiments, and interpretations were con- ceived and carried out by the authors, who take full responsibil- ity for the originality, validity, and integrity of the work
-
[9]
Comprehensi- bility of dysarthric speech: Implications for assessment and treat- ment planning,
K. M. Yorkston, E. A. Strand, and M. R. Kennedy, “Comprehensi- bility of dysarthric speech: Implications for assessment and treat- ment planning,”American Journal of Speech-Language Pathol- ogy, vol. 5, no. 1, pp. 55–66, 1996
1996
-
[10]
J. R. Duffyet al.,Motor speech disorders: Substrates, differential diagnosis, and management. Elsevier Health Sciences, 2012
2012
-
[11]
Acoustic studies of dysarthric speech: Methods, progress, and potential,
R. D. Kent, G. Weismer, J. F. Kent, H. K. V orperian, and J. R. Duffy, “Acoustic studies of dysarthric speech: Methods, progress, and potential,”Journal of communication disorders, vol. 32, no. 3, pp. 141–186, 1999
1999
-
[12]
“you say severe, i say mild
K. L. Stipancic, K. M. Palmer, H. P. Rowe, Y . Yunusova, J. D. Berry, and J. R. Green, ““you say severe, i say mild”: Toward an empirical classification of dysarthria severity,”Journal of Speech, Language, and Hearing Research, vol. 64, no. 12, pp. 4718–4735, 2021
2021
-
[13]
Dysarthric Speech Recognition, Detection and Classification using Raw Phase and Magnitude Spectra,
Z. Yue, E. Loweimi, and Z. Cvetkovic, “Dysarthric Speech Recognition, Detection and Classification using Raw Phase and Magnitude Spectra,” inInterspeech 2023, 2023, pp. 1533–1537
2023
-
[14]
Dysarthric speech intelligibility assessment by custom keyword spotting,
M. Anuprabha, K. Gurugubelli, and A. K. Vuppala, “Dysarthric speech intelligibility assessment by custom keyword spotting,” IEEE Journal of Selected Topics in Signal Processing, 2025
2025
-
[15]
Sand challenge: Four approaches for dysartria severity classification,
G. Deshpande, H. Battula, A. Panda, and S. K. Kopparapu, “Sand challenge: Four approaches for dysartria severity classification,” arXiv preprint arXiv:2512.02669, 2025
arXiv 2025
-
[16]
E. Yeo, J. M. Liss, V . Berisha, and D. R. Mortensen, “Multilin- gual dysarthric speech assessment using universal phone recog- nition and language-specific phonemic contrast modeling,”arXiv preprint arXiv:2601.21205, 2026
arXiv 2026
-
[17]
The torgo database of acoustic and articulatory speech from speakers with dysarthria,
F. Rudzicz, A. Namasivayam, and T. Wolff, “The torgo database of acoustic and articulatory speech from speakers with dysarthria,”Language Resources and Evaluation, vol. 46, no. 4, pp. 523–541, 2012
2012
-
[18]
Dysarthric speech database for universal access research
H. Kim, M. Hasegawa-Johnson, A. Perlman, J. R. Gunderson, T. S. Huang, K. L. Watkin, S. Frameet al., “Dysarthric speech database for universal access research.” inInterspeech, vol. 2008, 2008, pp. 1741–1744
2008
-
[19]
Cdsd: Chinese dysarthria speech database,
M. Sun, M. Gao, X. Kang, S. Wang, J. Du, D. Yao, and S.- J. Wang, “Cdsd: Chinese dysarthria speech database,”arXiv preprint arXiv:2310.15930, 2023
arXiv 2023
-
[20]
Evaluating the interpretability of clinical speech ai models: Lessons from two user studies,
L. Xu, V . Berisha, and J. Liss, “Evaluating the interpretability of clinical speech ai models: Lessons from two user studies,”Avail- able at SSRN 6019779
-
[21]
Exploring explain- ability: a definition, a model, and a knowledge catalogue,
L. Chazette, W. Brunotte, and T. Speith, “Exploring explain- ability: a definition, a model, and a knowledge catalogue,” in 2021 IEEE 29th international requirements engineering confer- ence (RE). IEEE, 2021, pp. 197–208
2021
-
[23]
Explanations for automatic speech recognition,
X. Wu, P. Bell, and A. Rajan, “Explanations for automatic speech recognition,” 2023. [Online]. Available: https://arxiv.org/ abs/2302.14062
Pith/arXiv arXiv 2023
-
[24]
Explainable attribute-based speaker verification,
X. Wu, C. Luu, P. Bell, and A. Rajan, “Explainable attribute-based speaker verification,” 2024. [Online]. Available: https://arxiv.org/abs/2405.19796
arXiv 2024
-
[25]
Attribution-based xai for dysarthria assessment: Validation of acoustic feature attribu- tions,
M. Kim, J. Oh, W. Jeong, and J.-H. Kim, “Attribution-based xai for dysarthria assessment: Validation of acoustic feature attribu- tions,” 2025
2025
-
[26]
Enhanced dysarthria detection in cerebral palsy and als patients using wavenet and cnn-bilstm models: A comparative study with model interpretability,
E. Hassan, A. Saber, T. Abd El-Hafeez, T. Medhat, and M. Y . Shams, “Enhanced dysarthria detection in cerebral palsy and als patients using wavenet and cnn-bilstm models: A comparative study with model interpretability,”Biomedical Signal Processing and Control, vol. 110, p. 108128, 2025
2025
-
[27]
Dysarthria detection based on a deep learning model with a clinically-interpretable layer,
L. Xu, J. Liss, and V . Berisha, “Dysarthria detection based on a deep learning model with a clinically-interpretable layer,”JASA Express Letters, vol. 3, no. 1, 2023
2023
-
[28]
Evaluating model interpretability in speech-based clinical artificial intelligence sys- tems,
L. Xu, V . Berisha, R. L. Utianski, and J. Liss, “Evaluating model interpretability in speech-based clinical artificial intelligence sys- tems,”Perspectives of the ASHA Special Interest Groups, vol. 10, no. 5, pp. 1637–1648, 2025
2025
-
[29]
Fusing heterogeneous speech tasks for automated dysarthria severity classification,
J. Lee and H.-M. Park, “Fusing heterogeneous speech tasks for automated dysarthria severity classification,” 2025
2025
-
[30]
Can we trust explainable ai methods on asr? an evaluation on phoneme recognition,
X. Wu, P. Bell, and A. Rajan, “Can we trust explainable ai methods on asr? an evaluation on phoneme recognition,” 2023. [Online]. Available: https://arxiv.org/abs/2305.18011
arXiv 2023
-
[31]
Attention to phonetics: A visually informed explanation of speech transformers,
E. A. Shams and J. Carson-Berndsen, “Attention to phonetics: A visually informed explanation of speech transformers,” inInter- national Conference on Text, Speech, and Dialogue. Springer, 2024, pp. 81–93
2024
-
[32]
Explainability of speech recognition transformers via gradient-based attention visu- alization,
T. Sun, H. Chen, G. Hu, L. He, and C. Zhao, “Explainability of speech recognition transformers via gradient-based attention visu- alization,”IEEE Transactions on Multimedia, vol. 26, pp. 1395– 1406, 2023
2023
-
[33]
Easy, interpretable, effective: opensmile for voice deepfake detection,
O. Pascu, D. Oneata, H. Cucu, and N. M. M ¨uller, “Easy, interpretable, effective: opensmile for voice deepfake detection,”
-
[34]
Available: https://arxiv.org/abs/2408.15775
[Online]. Available: https://arxiv.org/abs/2408.15775
-
[35]
Probing whisper for dysarthric speech in detection and assessment,
Z. Yue, D. Kayande, Z. Cvetkovic, and E. Loweimi, “Probing whisper for dysarthric speech in detection and assessment,”arXiv preprint arXiv:2510.04219, 2025
arXiv 2025
-
[36]
Perceived listener effort as an out- come measure for disordered speech,
K. F. Nagle and T. L. Eadie, “Perceived listener effort as an out- come measure for disordered speech,”Journal of Communication Disorders, vol. 73, pp. 34–49, 2018
2018
-
[37]
Estimating training data influence by tracing gradient descent,
G. Pruthi, F. Liu, M. Sundararajan, and S. Kale, “Estimating training data influence by tracing gradient descent,” 2020. [Online]. Available: https://arxiv.org/abs/2002.08484
arXiv 2020
-
[38]
Understanding black-box predictions via influence functions,
P. W. Koh and P. Liang, “Understanding black-box predictions via influence functions,” 2020. [Online]. Available: https: //arxiv.org/abs/1703.04730
arXiv 2020
-
[39]
A study of cross-validation and bootstrap for accuracy es- timation and model selection,
R. K., “A study of cross-validation and bootstrap for accuracy es- timation and model selection,”IJCAI, pp. 1137–1145, 1995
1995
-
[40]
Scikit-learn: ,
F. Pedregosa, G. Varoquaux, A. Gramfort, V . Michel, B. Thirion, O. Grisel, M. Blondel, P. Prettenhofer, R. Weiss, V . Dubourg, J. Vanderplas, A. Passos, D. Cournapeau, M. Brucher, M. Perrot, and E. Duchesnay, “Scikit-learn: ,” 2011. [Online]. Available: https://scikit-learn.org/stable/index.html
2011
-
[41]
Towards understanding con- vergence and generalization of adamw,
P. Zhou, X. Xie, Z. Lin, and S. Yan, “Towards understanding con- vergence and generalization of adamw,”IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024
2024
-
[42]
A unified approach to interpreting model predictions,
S. Lundberg and S.-I. Lee, “A unified approach to interpreting model predictions,” 2017. [Online]. Available: https://arxiv.org/ abs/1705.07874
Pith/arXiv arXiv 2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.