Towards Understanding the Power and Limits of the Muon Optimizer: A River-Valley Perspective
Pith reviewed 2026-06-26 14:21 UTC · model grok-4.3
The pith
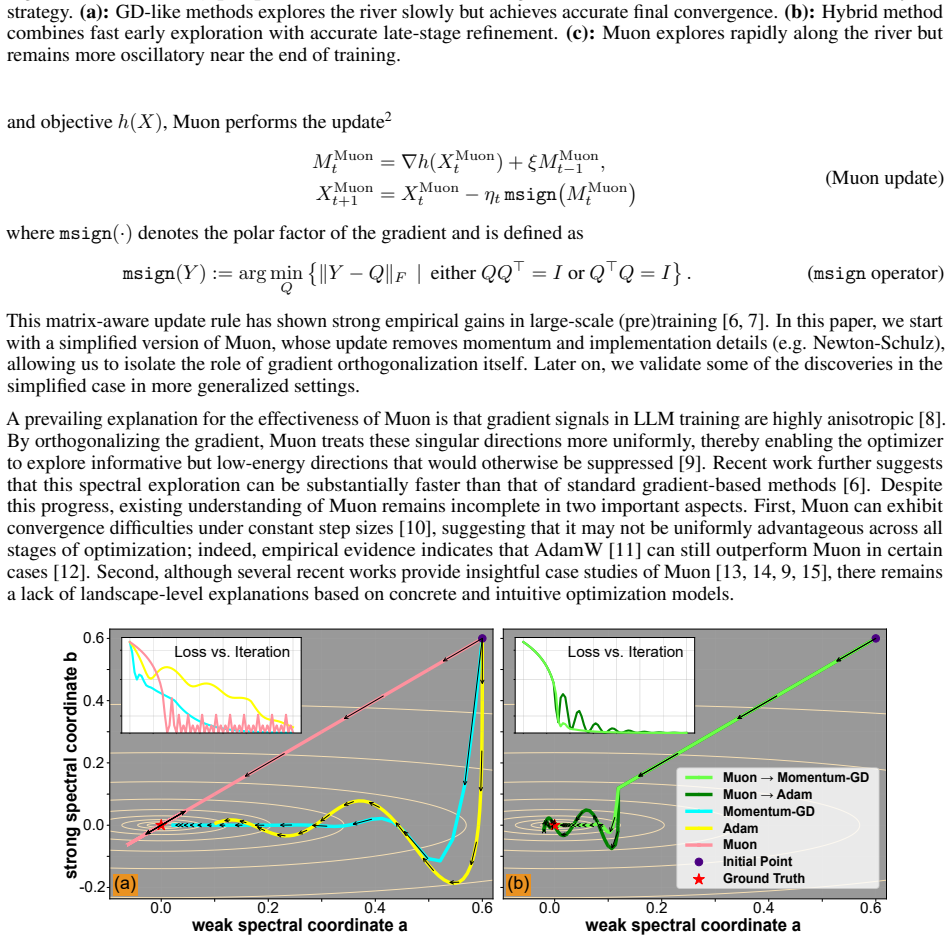
Muon moves faster early along the key direction but can oscillate and slow near the solution compared to gradient descent.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
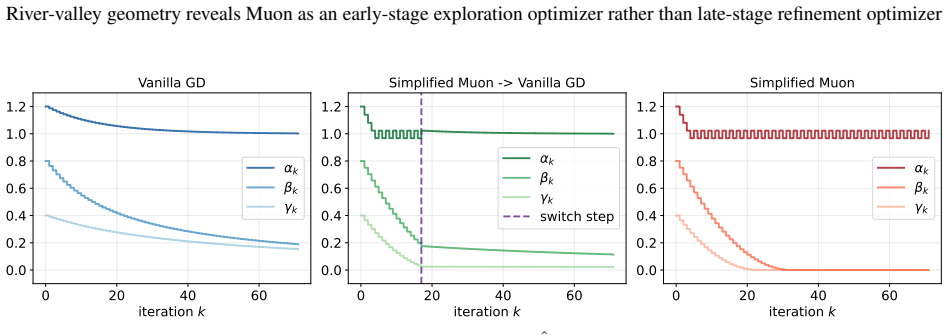
In the momentum-free setting, Muon moves faster along the information-bearing river direction during early optimization, but can converge much more slowly near the river bottom than gradient descent. Extending to general nonconvex objectives with momentum, Muon's orthogonalized update removes residual scale information, making it prone to overshooting and oscillation near the target solution.
What carries the argument
The river-valley perspective that decomposes the landscape into a primary river direction toward the solution and perpendicular hill directions of nuisance information, constructed on the mixed-spiked matrix sensing model.
If this is right
- Muon supplies early speed advantages in landscapes that contain both strong directional signal and long-tail bulk components.
- Near the target, Muon's orthogonal updates tend to discard scale cues and produce overshooting.
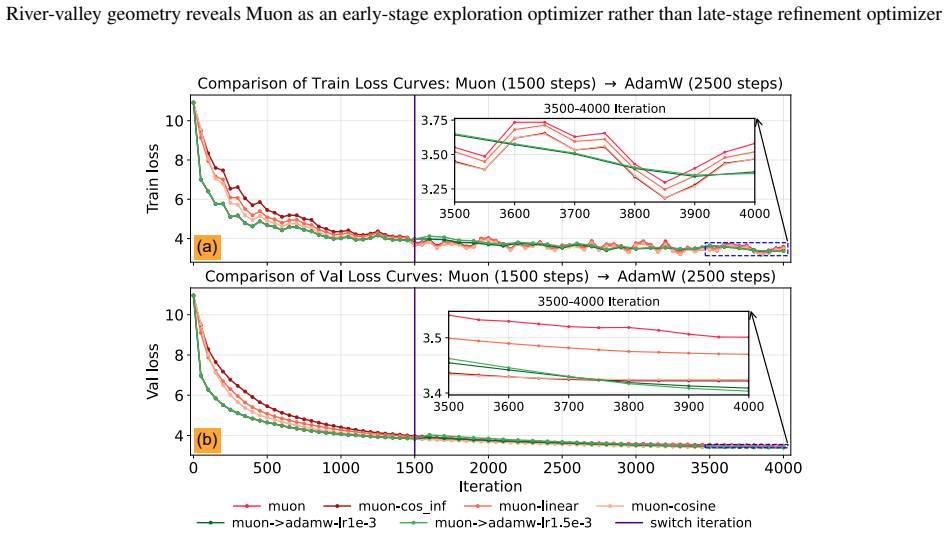
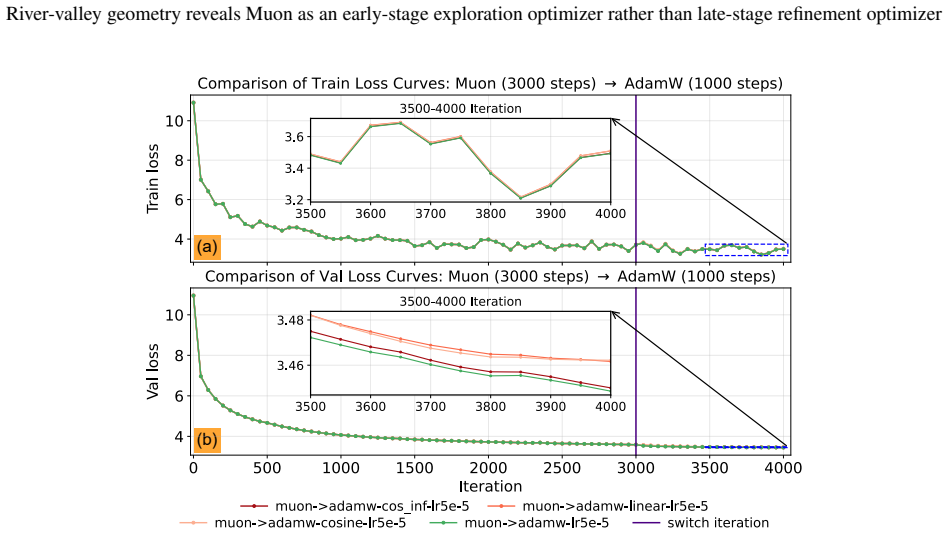
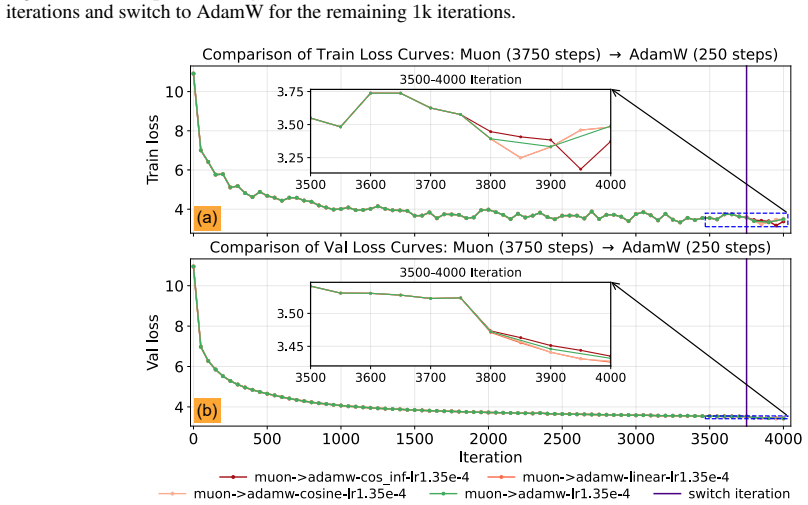
- Switching from Muon to a gradient-descent-style optimizer in the final phase can reduce oscillation and improve final accuracy.
- The two-stage schedule outperforms a single fixed learning-rate schedule for Muon on language model tasks.
Where Pith is reading between the lines
- The same river-valley lens could be applied to other spectral-normalization optimizers to check whether they share the late-stage oscillation pattern.
- A hybrid optimizer that keeps Muon's early directional speed while restoring scale information late could be designed and tested.
- The mixed-spiked model offers a concrete testbed for measuring how much bulk-component strength is needed before Muon's disadvantage appears.
Load-bearing premise
The mixed-spiked matrix sensing model whose sensing operator decomposes into signal, spike, and bulk components captures the mixture of anisotropic structure and long-tail information in LLM training landscapes.
What would settle it
Direct measurement of convergence speed near the river bottom in the mixed-spiked model, or observation of oscillation amplitude in late-stage Muon runs during actual language model training.
Figures








read the original abstract
Recently, Muon has gained substantial attention as an appealing alternative to Adam-like optimizers, with many works highlighting its advantages through spectral normalization and improved conditioning. Yet this positive theoretical narrative contrasts with its empirical performance in large language model (LLM) training, where Muon's gains over Adam/AdamW are often mixed, schedule-sensitive, and not uniformly superior. To address this gap, we develop a trajectory-level theory characterizing both the strengths and limitations of Muon. We introduce a mixed-spiked matrix sensing model whose sensing operator decomposes into signal, spike, and bulk components, capturing a mixture of anisotropic structure and long-tail information reminiscent of LLM training. On top of it, we adopted a river-valley perspective in which we view the landscape as composed of a river direction flowing to the desired solution and hill directions encoding nuisance or task-irrelevant information. In the momentum-free setting, we show that Muon moves faster along the information-bearing river direction during early optimization, but can converge much more slowly near the river bottom than gradient descent. We then extend the river-valley perspective to general nonconvex objectives with momentum by studying points on the spectral river. There, while Muon converges faster early on, its orthogonalized update removes residual scale information, making it prone to overshooting and oscillation near the target solution. Together, these results suggest that our characterizations extend beyond spiked matrix sensing and motivate switching to GD-like refinement optimizers in the final phase, rather than relying only on a fixed learning-rate schedule for Muon. We also provide preliminary evidence supporting this two-stage approach in language model training experiments.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces a mixed-spiked matrix sensing model whose sensing operator decomposes into signal, spike, and bulk components, together with a river-valley perspective that decomposes the landscape into a river direction (information-bearing) and hill directions (nuisance). In the momentum-free setting the paper claims Muon moves faster along the river early but converges more slowly near the river bottom than gradient descent. Extending the perspective to general nonconvex objectives with momentum, the authors argue that Muon's orthogonalized updates remove residual scale information and therefore induce overshooting and oscillation near spectral river points; they recommend a two-stage strategy that switches to GD-like refinement in the final phase and supply preliminary LLM training evidence for this approach.
Significance. If the characterizations hold, the work supplies a trajectory-level explanation for the schedule-sensitive and mixed empirical gains of Muon over Adam/AdamW in LLM training. The mixed-spiked model and river-valley decomposition constitute a novel modeling choice that captures anisotropic structure plus long-tail information; the preliminary experiments provide concrete support for the suggested two-stage optimizer switch. These elements could usefully inform the design of hybrid first-order methods.
major comments (1)
- [Extension to general nonconvex objectives with momentum] The extension of the river-valley analysis to general nonconvex objectives with momentum (abstract and the corresponding theoretical section) asserts that the orthogonalized update removes residual scale information and thereby produces overshooting/oscillation. No explicit conditions on curvature, momentum coefficient, or bulk/spike ratios are supplied that would guarantee persistence of the scale-removal effect once the trajectory leaves the spiked sensing operator. Because this step is load-bearing for the two-stage recommendation, the oscillation claim requires additional derivation or counter-example analysis to be fully grounded.
minor comments (2)
- [Introduction] Notation for the river and hill directions is introduced in the abstract but would benefit from an explicit one-sentence definition in the first paragraph of the introduction for readers encountering the perspective for the first time.
- [Experiments] The preliminary experiments section would be strengthened by reporting the precise learning-rate schedules and the point at which the switch to the GD-like refinement occurs, so that the two-stage protocol can be reproduced.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of the work's significance and for the detailed comment on the extension to general nonconvex objectives. We address the concern below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: The extension of the river-valley analysis to general nonconvex objectives with momentum (abstract and the corresponding theoretical section) asserts that the orthogonalized update removes residual scale information and thereby produces overshooting/oscillation. No explicit conditions on curvature, momentum coefficient, or bulk/spike ratios are supplied that would guarantee persistence of the scale-removal effect once the trajectory leaves the spiked sensing operator. Because this step is load-bearing for the two-stage recommendation, the oscillation claim requires additional derivation or counter-example analysis to be fully grounded.
Authors: We agree that the manuscript's extension relies on the mechanism identified at spectral river points within the mixed-spiked model and does not furnish explicit conditions guaranteeing that the scale-removal effect of orthogonal updates persists for arbitrary nonconvex objectives once the trajectory departs the spiked sensing operator. The core observation—that Muon's update discards residual scale information along the river direction—follows directly from the orthogonality property and is illustrated at those points, but the claim for broader applicability is indeed heuristic at present. In the revised version we will supply a short derivation of sufficient conditions on local curvature (near the river bottom) and momentum coefficient under which overshooting is expected, or, if the conditions turn out to be restrictive, include a brief counter-example analysis that delineates when the effect may not hold. This will better support the two-stage recommendation without overstating the current theoretical reach. revision: yes
Circularity Check
No circularity; model and river-valley perspective introduced independently without self-referential reductions
full rationale
The abstract and provided text introduce the mixed-spiked matrix sensing model and river-valley perspective as new constructs to characterize Muon trajectories. Claims of faster early river progress but slower bottom convergence (momentum-free) and scale-removal leading to overshoot (with momentum) are presented as derived results within this framework, with an empirical two-stage suggestion. No equations, self-citations, or fitted parameters are shown that reduce any prediction to the inputs by construction. The extension to general nonconvex objectives is described conceptually rather than via a load-bearing self-citation chain or ansatz smuggling. This is self-contained against external benchmarks, consistent with a normal non-circular finding.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Standard assumptions underlying convergence analysis of first-order methods in nonconvex settings
invented entities (2)
-
mixed-spiked matrix sensing model
no independent evidence
-
river-valley perspective
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Improving generalization performance by switching from adam to sgd
Nitish Shirish Keskar and Richard Socher. Improving generalization performance by switching from adam to sgd. arXiv preprint arXiv:1712.07628, 2017
Pith/arXiv arXiv 2017
-
[2]
Adam: A method for stochastic optimization.arXiv preprint arXiv:1412.6980, 2014
Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization.arXiv preprint arXiv:1412.6980, 2014
Pith/arXiv arXiv 2014
-
[3]
Evolution of optimization methods: Algorithms, scenarios, and evaluations
Tong Zhang, Jiangning Zhang, Zhucun Xue, Juntao Jiang, Yicheng Xu, Chengming Xu, Teng Hu, Xingyu Xie, Xiaobin Hu, Yabiao Wang, et al. Evolution of optimization methods: Algorithms, scenarios, and evaluations. arXiv preprint arXiv:2604.12968, 2026
Pith/arXiv arXiv 2026
-
[4]
Michael Crawshaw, Chirag Modi, Mingrui Liu, and Robert M Gower. An exploration of non-euclidean gradient descent: Muon and its many variants.arXiv preprint arXiv:2510.09827, 2025
arXiv 2025
-
[5]
Muon: An optimizer for hidden layers in neural networks, 2024.URL https://kellerjordan
Keller Jordan, Yuchen Jin, Vlado Boza, You Jiacheng, Franz Cesista, Laker Newhouse, and Jeremy Bernstein. Muon: An optimizer for hidden layers in neural networks, 2024.URL https://kellerjordan. github. io/posts/muon, 6(3):4, 2024
2024
-
[6]
Muon is scalable for llm training.arXiv preprint arXiv:2502.16982, 2025
Jingyuan Liu, Jianlin Su, Xingcheng Yao, Zhejun Jiang, Guokun Lai, Yulun Du, Yidao Qin, Weixin Xu, Enzhe Lu, Junjie Yan, et al. Muon is scalable for llm training.arXiv preprint arXiv:2502.16982, 2025
Pith/arXiv arXiv 2025
-
[7]
Practical efficiency of muon for pretraining.arXiv preprint arXiv:2505.02222, 2025
Ishaan Shah, Anthony M Polloreno, Karl Stratos, Philip Monk, Adarsh Chaluvaraju, Andrew Hojel, Andrew Ma, Anil Thomas, Ashish Tanwer, Darsh J Shah, et al. Practical efficiency of muon for pretraining.arXiv preprint arXiv:2505.02222, 2025
arXiv 2025
-
[8]
Zhendong Huang, Hengjie Cao, Fang Dong, Ruijun Huang, Mengyi Chen, Yifeng Yang, Xin Zhang, Anrui Chen, Mingzhi Dong, Yujiang Wang, et al. Spectra: Rethinking optimizers for llms under spectral anisotropy.arXiv preprint arXiv:2602.11185, 2026
arXiv 2026
-
[9]
Guillaume Braun, Han Bao, Wei Huang, and Masaaki Imaizumi. Spectral gradient descent mitigates anisotropy- driven misalignment: A case study in phase retrieval.arXiv preprint arXiv:2601.22652, 2026
arXiv 2026
-
[10]
On the convergence analysis of muon
Wei Shen, Ruichuan Huang, Minhui Huang, Cong Shen, and Jiawei Zhang. On the convergence analysis of muon. arXiv preprint arXiv:2505.23737, 2025
Pith/arXiv arXiv 2025
-
[11]
Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101, 2017
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101, 2017
Pith/arXiv arXiv 2017
-
[12]
Kimi k2: Open agentic intelligence.arXiv preprint arXiv:2507.20534, 2025
Kimi Team, Yifan Bai, Yiping Bao, Y Charles, Cheng Chen, Guanduo Chen, Haiting Chen, Huarong Chen, Jiahao Chen, Ningxin Chen, et al. Kimi k2: Open agentic intelligence.arXiv preprint arXiv:2507.20534, 2025
Pith/arXiv arXiv 2025
-
[13]
Muon: Training and trade-offs with latent attention and moe.arXiv preprint arXiv:2509.24406, 2025
Sushant Mehta, Raj Dandekar, Rajat Dandekar, and Sreedath Panat. Muon: Training and trade-offs with latent attention and moe.arXiv preprint arXiv:2509.24406, 2025
arXiv 2025
-
[14]
Preconditioning benefits of spectral orthogonalization in muon.arXiv preprint arXiv:2601.13474, 2026
Jianhao Ma, Yu Huang, Yuejie Chi, and Yuxin Chen. Preconditioning benefits of spectral orthogonalization in muon.arXiv preprint arXiv:2601.13474, 2026
arXiv 2026
-
[16]
Kaiyue Wen, Zhiyuan Li, Jason Wang, David Hall, Percy Liang, and Tengyu Ma. Understanding warmup-stable- decay learning rates: A river valley loss landscape perspective.arXiv preprint arXiv:2410.05192, 2024
arXiv 2024
-
[17]
The anisotropy of time.The Monist, 48(2):219–247, 1964
Adolf Grünbaum. The anisotropy of time.The Monist, 48(2):219–247, 1964
1964
-
[18]
OUP Oxford, 2004
Robert E Newnham.Properties of materials: anisotropy, symmetry, structure. OUP Oxford, 2004
2004
-
[19]
Mapping the large-scale anisotropy in the wmap data.Astronomy & Astrophysics, 464(2):479–485, 2007
Armando Bernui, B Mota, Marcelo J Reboucas, and R Tavakol. Mapping the large-scale anisotropy in the wmap data.Astronomy & Astrophysics, 464(2):479–485, 2007
2007
-
[20]
Anisotropy is everywhere, to see, to measure, and to model.Rock Mechanics and Rock Engineering, 48(4):1323–1339, 2015
Nick Barton and Eda Quadros. Anisotropy is everywhere, to see, to measure, and to model.Rock Mechanics and Rock Engineering, 48(4):1323–1339, 2015
2015
-
[21]
Neural anisotropy directions.Advances in Neural Information Processing Systems, 33:17896–17906, 2020
Guillermo Ortiz-Jiménez, Apostolos Modas, Seyed-Mohsen Moosavi, and Pascal Frossard. Neural anisotropy directions.Advances in Neural Information Processing Systems, 33:17896–17906, 2020
2020
-
[22]
Learning shape correspondence with anisotropic convolutional neural networks.Advances in neural information processing systems, 29, 2016
Davide Boscaini, Jonathan Masci, Emanuele Rodolà, and Michael Bronstein. Learning shape correspondence with anisotropic convolutional neural networks.Advances in neural information processing systems, 29, 2016
2016
-
[23]
Deformable convolutional networks
Jifeng Dai, Haozhi Qi, Yuwen Xiong, Yi Li, Guodong Zhang, Han Hu, and Yichen Wei. Deformable convolutional networks. InProceedings of the IEEE international conference on computer vision, pages 764–773, 2017. 10 River-valley geometry reveals Muon as an early-stage exploration optimizer rather than late-stage refinement optimizer
2017
-
[24]
Anisotropy is inherent to self-attention in transformers
Nathan Godey, Éric Clergerie, and Benoît Sagot. Anisotropy is inherent to self-attention in transformers. In Proceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers), pages 35–48, 2024
2024
-
[25]
Anisotropy is not inherent to transformers
Anemily Machina and Robert Mercer. Anisotropy is not inherent to transformers. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pages 4892–4907, 2024
2024
-
[26]
Shuchen Zhu, Rizhen Hu, Mingze Wang, Mou Sun, Xue Wang, Kun Yuan, and Zaiwen Wen. Accelerating llm pre-training through flat-direction dynamics enhancement.arXiv preprint arXiv:2602.22681, 2026
arXiv 2026
-
[27]
Raphael Bernas, Fanny Jourdan, Antonin Poché, and Céline Hudelot. Revisiting anisotropy in language transform- ers: The geometry of learning dynamics.arXiv preprint arXiv:2604.08764, 2026
Pith/arXiv arXiv 2026
-
[28]
Accelerating block coordinate descent for llm finetuning via landscape expansion.Advances in Neural Information Processing Systems, 38:56619–56645, 2026
Qijun Luo, Yifei Shen, Liangzu Peng, Dongsheng Li, and Xiao Li. Accelerating block coordinate descent for llm finetuning via landscape expansion.Advances in Neural Information Processing Systems, 38:56619–56645, 2026
2026
-
[29]
Riccardo Di Sipio. Rethinking llm training through information geometry and quantum metrics.arXiv preprint arXiv:2506.15830, 2025
arXiv 2025
-
[30]
Jeremy M Cohen, Simran Kaur, Yuanzhi Li, J Zico Kolter, and Ameet Talwalkar. Gradient descent on neural networks typically occurs at the edge of stability.arXiv preprint arXiv:2103.00065, 2021
arXiv 2021
-
[31]
Analyzing sharpness along gd trajectory: Progressive sharpening and edge of stability.Advances in Neural Information Processing Systems, 35:9983–9994, 2022
Zixuan Wang, Zhouzi Li, and Jian Li. Analyzing sharpness along gd trajectory: Progressive sharpening and edge of stability.Advances in Neural Information Processing Systems, 35:9983–9994, 2022
2022
-
[32]
The origin of edge of stability.arXiv preprint arXiv:2604.20446, 2026
Litman Elon. The origin of edge of stability.arXiv preprint arXiv:2604.20446, 2026
Pith/arXiv arXiv 2026
-
[33]
Weijie Su. Isotropic curvature model for understanding deep learning optimization: Is gradient orthogonalization optimal?arXiv preprint arXiv:2511.00674, 2025
arXiv 2025
-
[34]
Muon outperforms adam in tail-end associative memory learning.arXiv preprint arXiv:2509.26030, 2025
Shuche Wang, Fengzhuo Zhang, Jiaxiang Li, Cunxiao Du, Chao Du, Tianyu Pang, Zhuoran Yang, Mingyi Hong, and Vincent YF Tan. Muon outperforms adam in tail-end associative memory learning.arXiv preprint arXiv:2509.26030, 2025
arXiv 2025
-
[35]
Juno Kim, Eshaan Nichani, Denny Wu, Alberto Bietti, and Jason D. Lee. Sharp capacity scaling of spectral optimizers in learning associative memory.arXiv preprint arXiv:2603.26554, 2026
Pith/arXiv arXiv 2026
-
[36]
Muon optimizes under spectral norm constraints.arXiv preprint arXiv:2506.15054, 2025
Lizhang Chen, Jonathan Li, and Qiang Liu. Muon optimizes under spectral norm constraints.arXiv preprint arXiv:2506.15054, 2025
arXiv 2025
-
[37]
Lions and muons: Optimization via stochastic frank-wolfe.arXiv preprint arXiv:2506.04192, 2025
Maria-Eleni Sfyraki and Jun-Kun Wang. Lions and muons: Optimization via stochastic frank-wolfe.arXiv preprint arXiv:2506.04192, 2025
arXiv 2025
-
[38]
Training deep learning models with norm-constrained lmos
Thomas Pethick, Wanyun Xie, Kimon Antonakopoulos, Zhenyu Zhu, Antonio Silveti-Falls, and V olkan Cevher. Training deep learning models with norm-constrained lmos. InInternational Conference on Machine Learning, pages 49069–49104. PMLR, 2025
2025
-
[39]
Noah Amsel, David Persson, Christopher Musco, and Robert M. Gower. The polar express: Optimal matrix sign methods and their application to the muon algorithm.arXiv preprint arXiv:2505.16932, 2025
Pith/arXiv arXiv 2025
-
[40]
Convergence of muon with newton-schulz.arXiv preprint arXiv:2601.19156, 2026
Gyu Yeol Kim and Min-hwan Oh. Convergence of muon with newton-schulz.arXiv preprint arXiv:2601.19156, 2026
arXiv 2026
-
[41]
Swin transformer v2: Scaling up capacity and resolution
Ze Liu, Han Hu, Yutong Lin, Zhuliang Yao, Zhenda Xie, Yixuan Wei, Jia Ning, Yue Cao, Zheng Zhang, Li Dong, et al. Swin transformer v2: Scaling up capacity and resolution. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 12009–12019, 2022
2022
-
[42]
An analysis of single-layer networks in unsupervised feature learning
Adam Coates, Andrew Ng, and Honglak Lee. An analysis of single-layer networks in unsupervised feature learning. InProceedings of the fourteenth international conference on artificial intelligence and statistics, pages 215–223. JMLR Workshop and Conference Proceedings, 2011
2011
-
[43]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016
2016
-
[44]
Alex Krizhevsky and Geoffrey E. Hinton. Learning multiple layers of features from tiny images. Technical report, University of Toronto, Toronto, ON, Canada, 2009
2009
-
[45]
Introduction to compressed sensing., 2012
Mark A Davenport, Marco F Duarte, Yonina C Eldar, and Gitta Kutyniok. Introduction to compressed sensing., 2012
2012
-
[46]
Andreas M Tillmann and Marc E Pfetsch. The computational complexity of the restricted isometry property, the nullspace property, and related concepts in compressed sensing.IEEE Transactions on Information Theory, 60(2):1248–1259, 2013. 11 River-valley geometry reveals Muon as an early-stage exploration optimizer rather than late-stage refinement optimizer
2013
-
[47]
Phase retrieval via matrix completion.SIAM review, 57(2):225–251, 2015
Emmanuel J Candes, Yonina C Eldar, Thomas Strohmer, and Vladislav V oroninski. Phase retrieval via matrix completion.SIAM review, 57(2):225–251, 2015
2015
-
[48]
Universal low-rank matrix recovery from pauli measurements.Advances in Neural Information Processing Systems, 24, 2011
Yi-Kai Liu. Universal low-rank matrix recovery from pauli measurements.Advances in Neural Information Processing Systems, 24, 2011
2011
-
[49]
A blind compressed sensing formulation for collaborative filtering
Anuj Rajani, Paritosh Mittal, Aishwarya Jain, and Angshul Majumdar. A blind compressed sensing formulation for collaborative filtering. In2014 IEEE International Symposium on Signal Processing and Information Technology (ISSPIT), pages 000438–000443. IEEE, 2014
2014
-
[50]
Towards robust and scalable power system state estimation
Ming Jin, Igor Molybog, Reza Mohammadi-Ghazi, and Javad Lavaei. Towards robust and scalable power system state estimation. In2019 IEEE 58th Conference on Decision and Control (CDC), pages 3245–3252. IEEE, 2019
2019
-
[51]
Algorithmic regularization in over-parameterized matrix sensing and neural networks with quadratic activations
Yuanzhi Li, Tengyu Ma, and Hongyang Zhang. Algorithmic regularization in over-parameterized matrix sensing and neural networks with quadratic activations. InConference On Learning Theory, pages 2–47. PMLR, 2018
2018
-
[52]
Imagenet: A large-scale hierarchical image database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. In2009 IEEE conference on computer vision and pattern recognition, pages 248–255. Ieee, 2009
2009
-
[53]
Distribution of eigenvalues for some sets of random matrices.Mathematics of the USSR-Sbornik, 1(4):457–483, 1967
Vladimir A Mar ˇcenko and Leonid Andreevich Pastur. Distribution of eigenvalues for some sets of random matrices.Mathematics of the USSR-Sbornik, 1(4):457–483, 1967
1967
-
[54]
Applied linear statistical models, 2008
Herman F Senter. Applied linear statistical models, 2008
2008
-
[55]
Dominik Stöger and Mahdi Soltanolkotabi. Small random initialization is akin to spectral learning: Optimiza- tion and generalization guarantees for overparameterized low-rank matrix reconstruction.Advances in Neural Information Processing Systems, 34:23831–23843, 2021
2021
-
[56]
Llama: Open and efficient foundation language models.arXiv preprint arXiv:2302.13971, 2023
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. Llama: Open and efficient foundation language models.arXiv preprint arXiv:2302.13971, 2023
Pith/arXiv arXiv 2023
-
[57]
Language models are unsupervised multitask learners.OpenAI blog, 1(8):9, 2019
Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, et al. Language models are unsupervised multitask learners.OpenAI blog, 1(8):9, 2019
2019
-
[58]
Leo Gao, Stella Biderman, Sid Black, Laurence Golding, Travis Hoppe, Charles Foster, Jason Phang, Horace He, Anish Thite, Noa Nabeshima, et al. The pile: An 800gb dataset of diverse text for language modeling.arXiv preprint arXiv:2101.00027, 2020
Pith/arXiv arXiv 2020
-
[59]
Springer, 2018
Yurii Nesterov et al.Lectures on convex optimization, volume 137. Springer, 2018
2018
-
[60]
Perturbation theory for the singular value decomposition.SVD and Signal Processing II, Algorithms, Analysis and Applications, pages 99–109, 1991
Gilbert W Stewart. Perturbation theory for the singular value decomposition.SVD and Signal Processing II, Algorithms, Analysis and Applications, pages 99–109, 1991
1991
-
[61]
The mnist database of handwritten digit images for machine learning research [best of the web].IEEE signal processing magazine, 29(6):141–142, 2012
Li Deng. The mnist database of handwritten digit images for machine learning research [best of the web].IEEE signal processing magazine, 29(6):141–142, 2012
2012
-
[62]
Muon→AdamW
Vinod Nair and Geoffrey E Hinton. Rectified linear units improve restricted boltzmann machines. InProceedings of the 27th international conference on machine learning (ICML-10), pages 807–814, 2010. 12 River-valley geometry reveals Muon as an early-stage exploration optimizer rather than late-stage refinement optimizer Appendix Contents A Additional Detai...
2010
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.