Recognition: 2 theorem links
· Lean TheoremSharp Capacity Scaling of Spectral Optimizers in Learning Associative Memory
Pith reviewed 2026-05-14 23:34 UTC · model grok-4.3
The pith
Muon matches Newton's method storage capacity while using only first-order information
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Our main result sharply characterizes the recovery rates of one step of Muon, SGD, and Newton's method on the logistic regression loss under a power law frequency distribution. We show that the storage capacity of Muon significantly exceeds that of SGD, and even matches Newton's method while only using first-order information. Moreover, Muon saturates at a larger critical batch size. We further analyze the multi-step dynamics under a thresholded gradient approximation and show that Muon achieves a substantially faster initial recovery rate than SGD, while both methods eventually converge to the information-theoretic limit at comparable speeds.
What carries the argument
The spectral preconditioner in Muon, which applies a transformation based on the gradient covariance to amplify signals from low-frequency associations in the power-law setting.
If this is right
- Muon achieves substantially faster initial recovery than SGD in multi-step dynamics.
- Muon and SGD both converge to the same information-theoretic limit after the initial phase.
- The predicted scaling laws hold in synthetic task experiments.
- Muon supports larger critical batch sizes before performance saturates.
Where Pith is reading between the lines
- Spectral preconditioning may explain empirical gains of Muon in full-scale language model training.
- The analysis framework could be extended to study non-Gaussian embeddings or deeper transformer layers.
- Similar first-order spectral methods might be designed for other associative or retrieval tasks.
Load-bearing premise
The linear associative memory problem with Gaussian inputs and outputs accurately models factual recall in transformer-based models.
What would settle it
An experiment measuring one-step recovery rates on logistic regression with Gaussian embeddings and power-law frequencies where Muon fails to exceed SGD capacity or match Newton's method would falsify the main scaling claim.
Figures


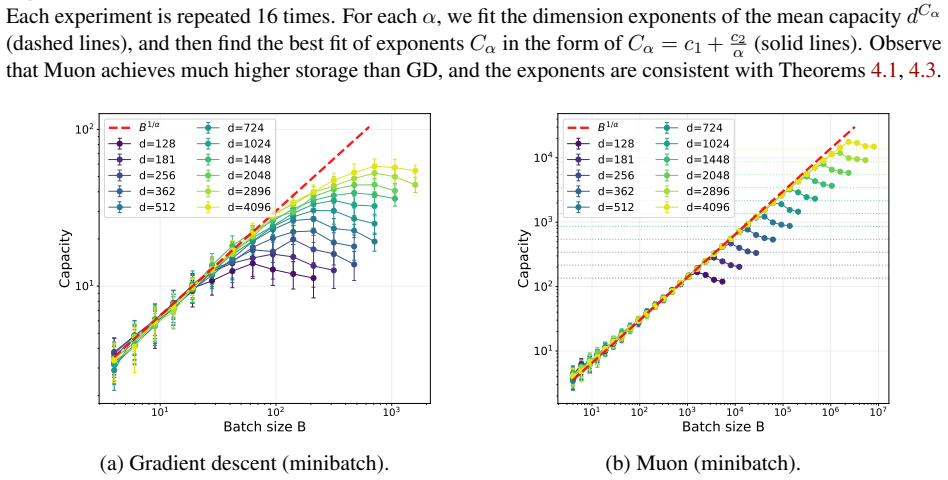





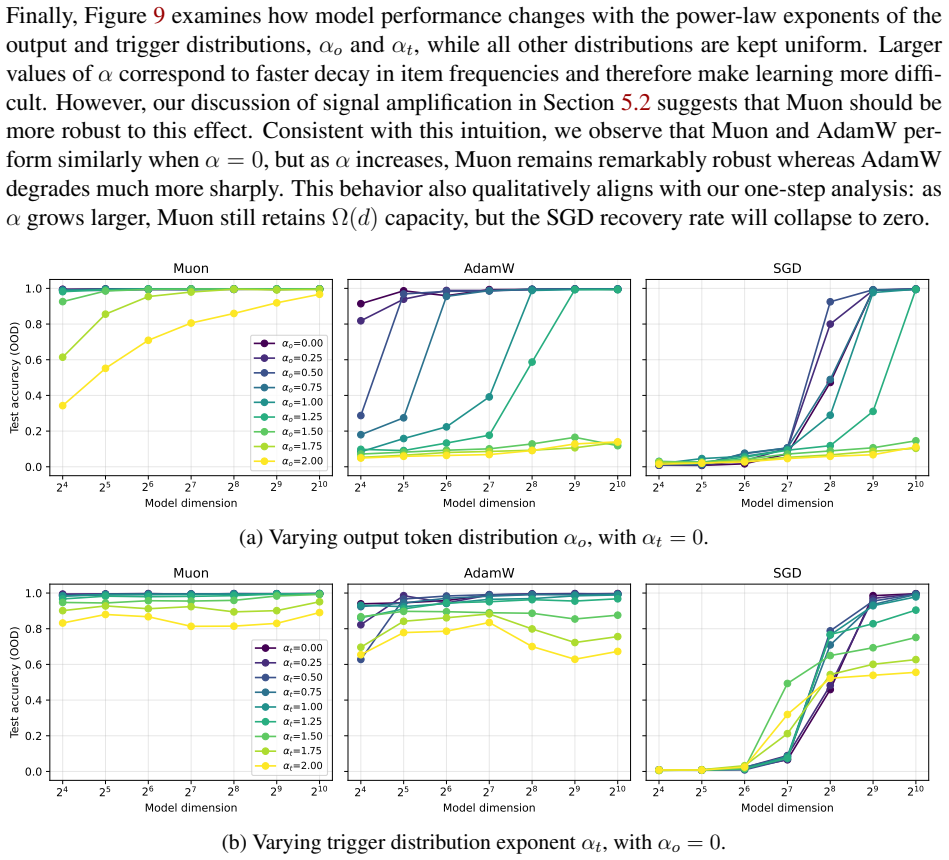
read the original abstract
Spectral optimizers such as Muon have recently shown strong empirical performance in large-scale language model training, but the source and extent of their advantage remain poorly understood. We study this question through the linear associative memory problem, a tractable model for factual recall in transformer-based models. In particular, we go beyond orthogonal embeddings and consider Gaussian inputs and outputs, which allows the number of stored associations to greatly exceed the embedding dimension. Our main result sharply characterizes the recovery rates of one step of Muon, SGD, and Newton's method on the logistic regression loss under a power law frequency distribution. We show that the storage capacity of Muon significantly exceeds that of SGD, and even matches Newton's method while only using first-order information. Moreover, Muon saturates at a larger critical batch size. We further analyze the multi-step dynamics under a thresholded gradient approximation and show that Muon achieves a substantially faster initial recovery rate than SGD, while both methods eventually converge to the information-theoretic limit at comparable speeds. Experiments on synthetic tasks validate the predicted scaling laws. Our analysis provides a quantitative understanding of the signal amplification of spectral preconditioners and lays the groundwork for establishing scaling laws across more practical language modeling tasks and optimizers.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper studies spectral optimizers such as Muon through the linear associative memory problem with Gaussian inputs and outputs under power-law frequency distributions. It derives sharp one-step recovery rates for Muon, SGD, and Newton's method applied to logistic regression loss, showing that Muon achieves significantly higher storage capacity than SGD while matching Newton's method using only first-order information. The work further analyzes multi-step dynamics via a thresholded gradient approximation, claiming faster initial recovery for Muon, and validates the scaling laws on synthetic tasks.
Significance. If the one-step derivations hold, the results provide a quantitative explanation for the empirical advantages of spectral preconditioners in capacity scaling for associative memory tasks, which model factual recall in transformers. This could inform optimizer design and scaling laws beyond the current setting, particularly by highlighting how first-order spectral methods can approach second-order performance.
major comments (2)
- [§4] §4 (Multi-step dynamics): The thresholded-gradient approximation is invoked to argue faster initial Muon recovery and comparable asymptotic convergence, but no quantitative bound is provided on the accumulated approximation error over iterations, especially in the regime where the number of associations exceeds the embedding dimension and interacts with the power-law tail. This approximation error could systematically affect the claimed comparative advantage over SGD at the stated precision.
- [§3.1] §3.1, main recovery-rate theorems: The sharp characterizations for one-step Muon/SGD/Newton rely on the Gaussian association model; while the one-step formulas appear derived independently, the manuscript does not explicitly state the error-control assumptions needed to extend the capacity scaling claims beyond the orthogonal-embedding case to the non-orthogonal Gaussian setting.
minor comments (2)
- [§2] Notation for the power-law exponent and frequency distribution should be introduced with a dedicated definition early in §2 to avoid ambiguity when comparing recovery rates across methods.
- [Figure 3] Figure 3 (synthetic validation plots): axis labels and legend entries are too small for readability; consider increasing font size and adding error bars from multiple random seeds.
Simulated Author's Rebuttal
We thank the referee for the careful and constructive review. We address the two major comments point by point below and will revise the manuscript to improve clarity on assumptions and to discuss the limitations of the multi-step approximation.
read point-by-point responses
-
Referee: [§4] §4 (Multi-step dynamics): The thresholded-gradient approximation is invoked to argue faster initial Muon recovery and comparable asymptotic convergence, but no quantitative bound is provided on the accumulated approximation error over iterations, especially in the regime where the number of associations exceeds the embedding dimension and interacts with the power-law tail. This approximation error could systematically affect the claimed comparative advantage over SGD at the stated precision.
Authors: We agree that a rigorous quantitative bound on the accumulated error would be desirable. Deriving such a bound is technically involved because of the dependence structure induced by the power-law frequencies and the iterative updates. In the revision we will add a paragraph in §4 that explicitly discusses this limitation, provides a heuristic error analysis based on the one-step concentration, and reports additional synthetic experiments confirming that the qualitative advantage of Muon over SGD persists even when moderate approximation errors are present. The primary capacity claims will continue to rest on the exact one-step results. revision: partial
-
Referee: [§3.1] §3.1, main recovery-rate theorems: The sharp characterizations for one-step Muon/SGD/Newton rely on the Gaussian association model; while the one-step formulas appear derived independently, the manuscript does not explicitly state the error-control assumptions needed to extend the capacity scaling claims beyond the orthogonal-embedding case to the non-orthogonal Gaussian setting.
Authors: The one-step theorems are derived directly for the non-orthogonal Gaussian model (as stated in the problem formulation and abstract). The proofs control deviations via standard sub-Gaussian concentration and random-matrix bounds that hold without orthogonality. We will revise §3.1 to state these error-control assumptions explicitly in the theorem statements and proof sketches, making the passage from the orthogonal case to the general Gaussian case transparent. revision: yes
Circularity Check
Derivations derive directly from model equations without reduction to inputs by construction
full rationale
The paper's core results characterize one-step recovery rates for Muon, SGD, and Newton's method on logistic loss under Gaussian inputs and power-law frequencies by direct analysis of the linear associative memory model equations. The multi-step section invokes a thresholded-gradient approximation to compare initial rates, but presents this explicitly as an approximation rather than an exact claim that collapses to fitted parameters or self-referential definitions. No self-definitional steps, fitted inputs renamed as predictions, or load-bearing self-citations appear; the storage capacity comparisons follow from the stated assumptions independently of the target scaling laws.
Axiom & Free-Parameter Ledger
free parameters (1)
- power law exponent
axioms (2)
- domain assumption Linear associative memory with Gaussian inputs/outputs models factual recall in transformers
- domain assumption Thresholded gradient approximation captures multi-step optimizer dynamics
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Theorem 4.1: one-step Muon recovers i ≲ min{i*, B^{1/α} (log d)^{-1/α}}, i* ≍ d^{1+1/(2α)} (log d)^{-2-5/α} via h_λ(G) with λ ≍ max{(log d)^{2α+2}/d^α, (log d)^2/B}
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat recovery unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Theorem 5.4: multi-step Muon d_t = e^Θ(min{d^{2-(1-1/(2α))t}, B^{1/α}})
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 3 Pith papers
-
Factual recall in linear associative memories: sharp asymptotics and mechanistic insights
Linear associative memories store up to p_c log p_c / d^2 = 1/2 associations, with optimal weights pushing correct scores just above the extreme value of competing outputs.
-
Phases of Muon: When Muon Eclipses SignSGD
On power-law covariance least squares problems, SignSVD (Muon) and SignSGD (Adam proxy) show three phases of relative performance depending on data exponent α and target exponent β.
-
Sharp Capacity Thresholds in Linear Associative Memory: From Winner-Take-All to Listwise Retrieval
Winner-take-all linear memory capacity scales as d² ~ n log n due to extreme values; listwise retrieval via Tail-Average Margin yields d² ~ n with exact asymptotic theory.
Reference graph
Works this paper leans on
-
[1]
Zeyuan Allen-Zhu and Yuanzhi Li. Physics of language models: Part 3.3, knowledge capacity scaling laws.arXiv preprint arXiv:2404.05405, 2024
-
[2]
Jeremy Bernstein. Newton-Schulz, 2024. URL https://docs.modula.systems/algorithms/ newton-schulz/. Modula documentation
work page 2024
-
[3]
Old optimizer, new norm: An anthology.arXiv preprint arXiv:2409.20325, 2024
Jeremy Bernstein and Laker Newhouse. Old optimizer, new norm: An anthology.arXiv preprint arXiv:2409.20325, 2024
-
[4]
Birth of a transformer: A memory viewpoint.Advances in Neural Information Processing Systems, 2023
Alberto Bietti, Vivien Cabannes, Diane Bouchacourt, Herve Jegou, and Leon Bottou. Birth of a transformer: A memory viewpoint.Advances in Neural Information Processing Systems, 2023
work page 2023
-
[5]
A dynamical model of neural scaling laws.arXiv preprint arXiv:2402.01092, 2024
Blake Bordelon, Alexander Atanasov, and Cengiz Pehlevan. A dynamical model of neural scaling laws.arXiv preprint arXiv:2402.01092, 2024
-
[6]
Scaling laws for associative memories
Vivien Cabannes, Elvis Dohmatob, and Alberto Bietti. Scaling laws for associative memories. InThe Twelfth International Conference on Learning Representations, 2024
work page 2024
-
[7]
Andrea Caponnetto and Ernesto De Vito. Optimal rates for the regularized least-squares algorithm.Foundations of Computational mathematics, 7(3):331–368, 2007
work page 2007
-
[8]
Muon optimizes under spectral norm constraints
Lizhang Chen, Jonathan Li, and Qiang Liu. Muon optimizes under spectral norm constraints. arXiv preprint arXiv:2506.15054, 2025
-
[9]
When do spectral gradient updates help in deep learning?arXiv preprint arXiv:2512.04299, 2025
Damek Davis and Dmitriy Drusvyatskiy. When do spectral gradient updates help in deep learning?arXiv preprint arXiv:2512.04299, 2025
-
[10]
John Duchi, Elad Hazan, and Yoram Singer. Adaptive subgradient methods for online learn- ing and stochastic optimization.Journal of Machine Learning Research, 12(61):2121–2159, 2011. 20
work page 2011
-
[11]
Toy models of superposition.Transformer Circuits Thread, 2022
Nelson Elhage, Tristan Hume, Catherine Olsson, Nicholas Schiefer, Tom Henighan, Shauna Kravec, Zac Hatfield-Dodds, Robert Lasenby, Dawn Drain, Carol Chen, Roger Grosse, Sam McCandlish, Jared Kaplan, Dario Amodei, Martin Wattenberg, and Christopher Olah. Toy models of superposition.Transformer Circuits Thread, 2022. https://transformer- circuits.pub/2022/t...
work page 2022
-
[12]
Chen Fan, Mark Schmidt, and Christos Thrampoulidis. Implicit bias of spectral descent and Muon on multiclass separable data.arXiv preprint arXiv:2502.04664, 2025
-
[13]
Dimension-adapted momentum outscales SGD.arXiv preprint arXiv:2505.16098, 2025
Damien Ferbach, Katie Everett, Gauthier Gidel, Elliot Paquette, and Courtney Paquette. Dimension-adapted momentum outscales SGD.arXiv preprint arXiv:2505.16098, 2025
-
[14]
Transformer feed-forward layers are key-value memories
Mor Geva, Roei Schuster, Jonathan Berant, and Omer Levy. Transformer feed-forward layers are key-value memories. InProceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 5484–5495, 2021
work page 2021
-
[15]
Dissecting recall of fac- tual associations in auto-regressive language models
Mor Geva, Jasmijn Bastings, Katja Filippova, and Amir Globerson. Dissecting recall of fac- tual associations in auto-regressive language models. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 12216–12235, 2023
work page 2023
-
[16]
Insights on Muon from simple quadratics.arXiv preprint arXiv:2602.11948, 2026
Antoine Gonon, Andreea-Alexandra Mus ¸at, and Nicolas Boumal. Insights on Muon from simple quadratics.arXiv preprint arXiv:2602.11948, 2026
-
[17]
Shampoo: Preconditioned stochastic tensor optimization
Vineet Gupta, Tomer Koren, and Yoram Singer. Shampoo: Preconditioned stochastic tensor optimization. InInternational Conference on Machine Learning, pages 1842–1850. PMLR, 2018
work page 2018
-
[18]
Nicholas J Higham.Functions of matrices: Theory and computation. SIAM, 2008
work page 2008
-
[19]
John J Hopfield. Neural networks and physical systems with emergent collective computa- tional abilities.Proceedings of the national academy of sciences, 79(8):2554–2558, 1982
work page 1982
-
[20]
Ruichen Jiang, Zakaria Mhammedi, Mehryar Mohri, and Aryan Mokhtari. Adaptive matrix online learning through smoothing with guarantees for nonsmooth nonconvex optimization. arXiv preprint arXiv:2602.08232, 2026
-
[21]
Yibo Jiang, Goutham Rajendran, Pradeep Ravikumar, and Bryon Aragam. Do LLMs dream of elephants (when told not to)? Latent concept association and associative memory in trans- formers.Advances in Neural Information Processing Systems, 37:67712–67757, 2024
work page 2024
-
[22]
Muon: An optimizer for hidden layers in neural networks, 2024
Keller Jordan, Yuchen Jin, Vlado Boza, Jiacheng You, Franz Cesista, Laker Newhouse, and Jeremy Bernstein. Muon: An optimizer for hidden layers in neural networks, 2024. URL https://kellerjordan.github.io/posts/muon/
work page 2024
-
[23]
Convergence of muon with newton-schulz, 2026
Gyu Yeol Kim and Min-hwan Oh. Convergence of Muon with Newton-Schulz.arXiv preprint arXiv:2601.19156, 2026
-
[24]
Jihwan Kim, Dogyoon Song, and Chulhee Yun. Scaling laws of SignSGD in linear regression: When does it outperform SGD? InThe Fourteenth International Conference on Learning Representations, 2026. 21
work page 2026
-
[25]
Adam: A Method for Stochastic Optimization
Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization.arXiv preprint arXiv:1412.6980, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[26]
Fuad Kittaneh. On Lipschitz functions of normal operators.Proceedings of the American Mathematical Society, 94(3):416–418, 1985. ISSN 00029939, 10886826
work page 1985
-
[27]
Correlation matrix memories.IEEE Transactions on Computers, C-21: 353–359, 1972
Teuvo Kohonen. Correlation matrix memories.IEEE Transactions on Computers, C-21: 353–359, 1972. URL https://api.semanticscholar.org/CorpusID:21483100
work page 1972
-
[28]
Frederik Kunstner and Francis Bach. Scaling laws for gradient descent and sign descent for linear bigram models under Zipf’s law.arXiv preprint arXiv:2505.19227, 2025
-
[29]
Frederik Kunstner, Alan Milligan, Robin Yadav, Mark Schmidt, and Alberto Bietti. Heavy- tailed class imbalance and why adam outperforms gradient descent on language models.Ad- vances in Neural Information Processing Systems, 37:30106–30148, 2024
work page 2024
-
[30]
Tim Tsz-Kit Lau, Qi Long, and Weijie Su. Polargrad: A class of matrix-gradient optimizers from a unifying preconditioning perspective.arXiv preprint arXiv:2505.21799, 2025
-
[31]
Binghui Li, Kaifei Wang, Han Zhong, Pinyan Lu, and Liwei Wang. Muon in associative memory learning: Training dynamics and scaling laws.arXiv preprint arXiv:2602.05725, 2026
-
[32]
Licong Lin, Jingfeng Wu, Sham M Kakade, Peter L Bartlett, and Jason D Lee. Scaling laws in linear regression: Compute, parameters, and data.arXiv preprint arXiv:2406.08466, 2024
-
[33]
Muon is Scalable for LLM Training
Jingyuan Liu, Jianlin Su, Xingcheng Yao, Zhejun Jiang, Guokun Lai, Yulun Du, Yidao Qin, Weixin Xu, Enzhe Lu, Junjie Yan, et al. Muon is scalable for LLM training.arXiv preprint arXiv:2502.16982, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[34]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization, 2019. URL https: //arxiv.org/abs/1711.05101
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[35]
Preconditioning benefits of spectral orthogonalization in Muon.arXiv preprint arXiv:2601.13474, 2026
Jianhao Ma, Yu Huang, Yuejie Chi, and Yuxin Chen. Preconditioning benefits of spectral orthogonalization in Muon.arXiv preprint arXiv:2601.13474, 2026
-
[36]
Optimizing neural networks with kronecker-factored ap- proximate curvature
James Martens and Roger Grosse. Optimizing neural networks with kronecker-factored ap- proximate curvature. InInternational conference on machine learning, pages 2408–2417. PMLR, 2015
work page 2015
-
[37]
Kevin Meng, David Bau, Alex Andonian, and Yonatan Belinkov. Locating and editing factual associations in GPT.Advances in neural information processing systems, 35:17359–17372, 2022
work page 2022
-
[38]
The quantization model of neural scaling.Advances in Neural Information Processing Systems, 36, 2023
Eric Michaud, Ziming Liu, Uzay Girit, and Max Tegmark. The quantization model of neural scaling.Advances in Neural Information Processing Systems, 36, 2023
work page 2023
-
[39]
Eshaan Nichani, Jason D Lee, and Alberto Bietti. Understanding factual recall in transformers via associative memories.arXiv preprint arXiv:2412.06538, 2024. 22
-
[40]
In-context Learning and Induction Heads
Catherine Olsson, Nelson Elhage, Neel Nanda, Nicholas Joseph, Nova DasSarma, Tom Henighan, Ben Mann, Amanda Askell, Yuntao Bai, Anna Chen, Tom Conerly, Dawn Drain, Deep Ganguli, Zac Hatfield-Dodds, Danny Hernandez, Scott Johnston, Andy Jones, Jackson Kernion, Liane Lovitt, Kamal Ndousse, Dario Amodei, Tom Brown, Jack Clark, Jared Ka- plan, Sam McCandlish,...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[41]
Elliot Paquette, Courtney Paquette, Lechao Xiao, and Jeffrey Pennington. 4+3 phases of compute-optimal neural scaling laws.Advances in Neural Information Processing Systems, 2024
work page 2024
-
[42]
Steven T. Piantadosi. Zipf’s word frequency law in natural language: A critical review and future directions.Psychonomic Bulletin & Review, 21:1112–1130, 2014
work page 2014
-
[43]
Yunwei Ren, Eshaan Nichani, Denny Wu, and Jason D Lee. Emergence and scaling laws in SGD learning of shallow neural networks.arXiv preprint arXiv:2504.19983, 2025
-
[44]
Adam Roberts, Colin Raffel, and Noam Shazeer. How much knowledge can you pack into the parameters of a language model? InProceedings of the 2020 conference on empirical methods in natural language processing (EMNLP), pages 5418–5426, 2020
work page 2020
-
[45]
The smallest singular value of a random rectangular matrix
Mark Rudelson and Roman Vershynin. The smallest singular value of a random rectangular matrix.arXiv preprint arXiv:0802.3956, 2009
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[46]
Non-asymptotic theory of random matrices: extreme singular values
Mark Rudelson and Roman Vershynin. Non-asymptotic theory of random matrices: extreme singular values. InProceedings of the International Congress of Mathematicians 2010 (ICM 2010), pages 1576–1602, 2010
work page 2010
-
[47]
Transformers, parallel computation, and logarithmic depth
Clayton Sanford, Daniel Hsu, and Matus Telgarsky. Transformers, parallel computation, and logarithmic depth.arXiv preprint arXiv:2402.09268, 2024
-
[48]
Benchmarking optimizers for large language model pretraining.arXiv preprint arXiv:2509.01440, 2025
Andrei Semenov, Matteo Pagliardini, and Martin Jaggi. Benchmarking optimizers for large language model pretraining.arXiv preprint arXiv:2509.01440, 2025
-
[49]
On the Convergence Analysis of Muon
Wei Shen, Ruichuan Huang, Minhui Huang, Cong Shen, and Jiawei Zhang. On the conver- gence analysis of Muon.arXiv preprint arXiv:2505.23737, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[50]
Weijie Su. Isotropic curvature model for understanding deep learning optimization: Is gradi- ent orthogonalization optimal?arXiv preprint arXiv:2511.00674, 2025
-
[51]
Bhavya Vasudeva, Puneesh Deora, Yize Zhao, Vatsal Sharan, and Christos Thrampoulidis. How Muon’s spectral design benefits generalization: A study on imbalanced data.arXiv preprint arXiv:2510.22980, 2025
-
[52]
Vershynin.High-dimensional probability: An introduction with applications in data sci- ence
R. Vershynin.High-dimensional probability: An introduction with applications in data sci- ence. Cambridge Series in Statistical and Probabilistic Mathematics. Cambridge University Press, 2nd edition, 2018. 23
work page 2018
-
[53]
Learning to recall with transformers beyond orthogonal embeddings
Nuri Mert Vural, Alberto Bietti, Mahdi Soltanolkotabi, and Denny Wu. Learning to recall with transformers beyond orthogonal embeddings. InInternational Conference on Learning Representations, 2026
work page 2026
-
[54]
SOAP: Improving and Stabilizing Shampoo using Adam
Nikhil Vyas, Depen Morwani, Rosie Zhao, Mujin Kwun, Itai Shapira, David Brandfonbrener, Lucas Janson, and Sham Kakade. SOAP: Improving and stabilizing Shampoo using Adam. arXiv preprint arXiv:2409.11321, 2024
work page internal anchor Pith review arXiv 2024
-
[55]
Wainwright.High-dimensional statistics: A non-asymptotic viewpoint
Martin J. Wainwright.High-dimensional statistics: A non-asymptotic viewpoint. Cambridge Series in Statistical and Probabilistic Mathematics. Cambridge University Press, 2019
work page 2019
-
[56]
High-dimensional isotropic scaling dynamics of Muon and SGD
Guangyuan Wang, Elliot Paquette, and Atish Agarwala. High-dimensional isotropic scaling dynamics of Muon and SGD. InOPT 2025: Optimization for Machine Learning, 2025
work page 2025
-
[57]
Muon outperforms Adam in tail-end associative memory learning.arXiv preprint arXiv:2509.26030, 2025
Shuche Wang, Fengzhuo Zhang, Jiaxiang Li, Cunxiao Du, Chao Du, Tianyu Pang, Zhuoran Yang, Mingyi Hong, and Vincent YF Tan. Muon outperforms Adam in tail-end associative memory learning.arXiv preprint arXiv:2509.26030, 2025
-
[58]
Zixuan Wang, Eshaan Nichani, Alberto Bietti, Alex Damian, Daniel Hsu, Jason D Lee, and Denny Wu. Learning compositional functions with transformers from easy-to-hard data. arXiv preprint arXiv:2505.23683, 2025
-
[59]
Fantastic pretraining optimizers and where to find them.arXiv preprint arXiv:2509.02046, 2025
Kaiyue Wen, David Hall, Tengyu Ma, and Percy Liang. Fantastic pretraining optimizers and where to find them.arXiv preprint arXiv:2509.02046, 2025
-
[60]
Non- holographic associative memory.Nature, 222(5197):960–962, 1969
David J Willshaw, O Peter Buneman, and Hugh Christopher Longuet-Higgins. Non- holographic associative memory.Nature, 222(5197):960–962, 1969
work page 1969
-
[61]
Shuo Xie, Tianhao Wang, Sashank Reddi, Sanjiv Kumar, and Zhiyuan Li. Structured pre- conditioners in adaptive optimization: A unified analysis.arXiv preprint arXiv:2503.10537, 2025
-
[62]
Robin Yadav, Shuo Xie, Tianhao Wang, and Zhiyuan Li. Provable benefit of sign descent: A minimal model under heavy-tailed class imbalance.arXiv preprint arXiv:2512.00763, 2025. 24 Contents 1 Introduction 1 2 Related Work 4 3 Setting: Associative Memory 5 4 One Step of Muon 6 4.1 One-step recovery of Muon . . . . . . . . . . . . . . . . . . . . . . . . . ....
-
[63]
It follows thatrank(M)< d 2 and soλ d/2(M) = 0. Now supposeB≳d α. Choose a positive integerK≍ 1 d B1/α and define the setsI k :={(k−1)d+ d 2 ,· · ·, kd+ d 2 −1}fork≥1. Consider the decomposition M= d/2−1X i=1 q2 i uiu⊤ i | {z } =:M0 + X k∈[K] X i∈Ik q2 i uiu⊤ i | {z } =:Mk + NX i=(K+1/2)d q2 i uiu⊤ i | {z } =:Mtail . Sincerank(M 0)< d 2, we haveλ d/2(M0) ...
-
[64]
Observe that eachK ij:n is a multilinear polynomial of degree at most2nin the entriesu kℓ, vkℓ, thus by Gaussian hypercontractivity, E KL ij:n 1/L ≤(L−1) n E K2 ij:n 1/2 ≲ √ dL r (CρL) n−1/2 =: t√ L . By Markov’s inequality, Pr(|Kij:n|> t)≤t −L E KL ij:n ≲L −L/2 =d −ω(1). Therefore, union bounding over all1≤i, j≤dwithi̸=jandn≲(logd) 2, we conclude: | ˜Kij...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.