Agreement in Representation Space for Open-Ended Self-Consistency
Pith reviewed 2026-06-27 10:05 UTC · model grok-4.3
The pith
Agreement measured by clustering generations in embedding space provides a signal of self-consistency for open-ended LLM tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
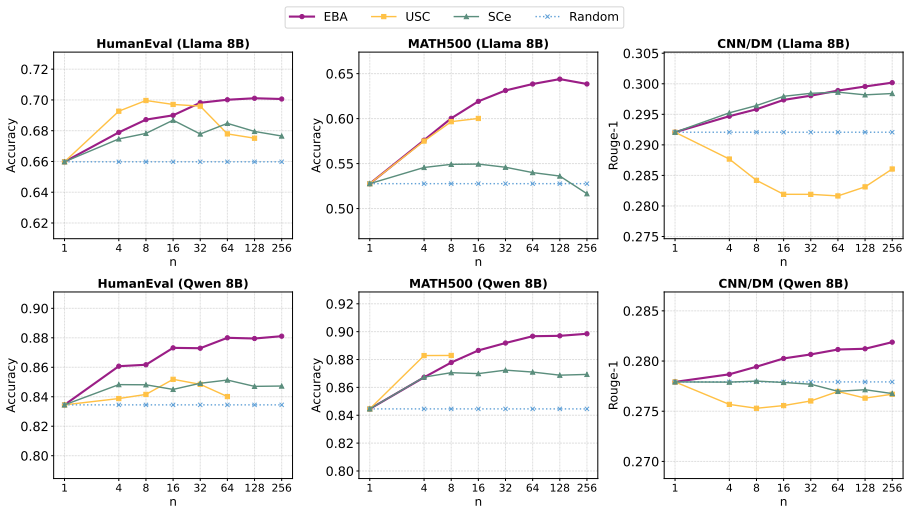
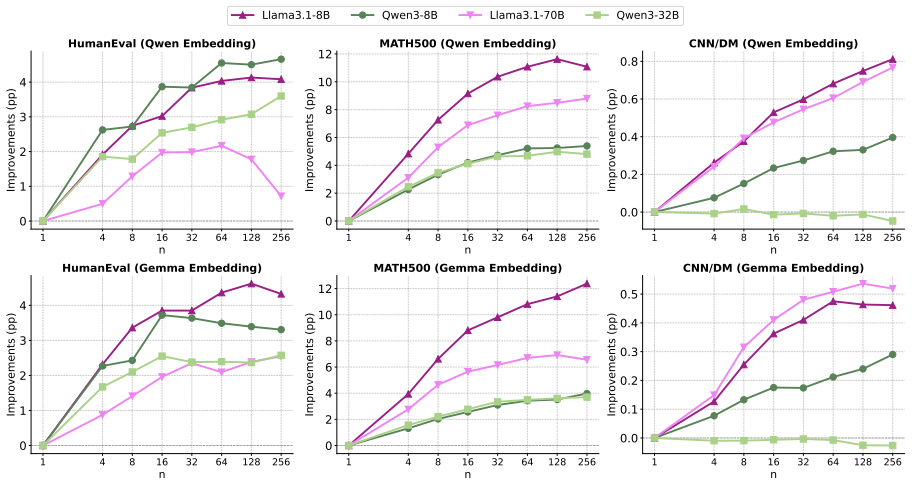
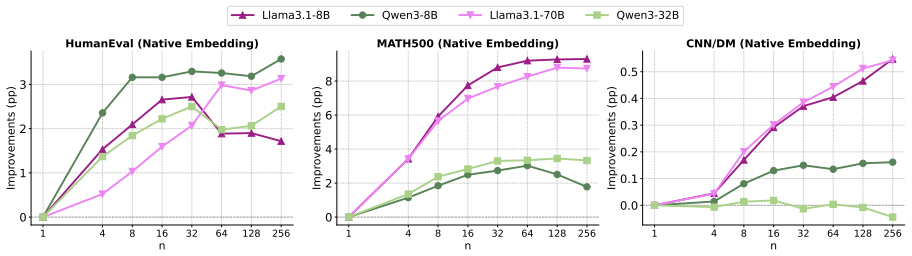
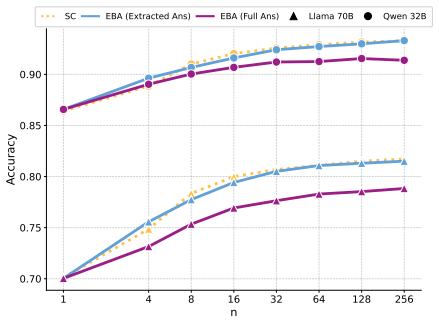
We hypothesize that semantically compatible generations concentrate in similar regions of representation space. We operationalize this via Embedding-Based Agreement (EBA), a training-free procedure that clusters sampled generations in embedding space and treats cluster membership as a proxy for agreement. On mathematical reasoning, code generation, and summarization tasks, EBA outperforms random selection, exhibits more stable scaling than LLM-based evaluators or uncertainty estimators, remains consistent across model families and embedding spaces, and shows that centrally located generations are substantially more accurate than peripheral ones.
What carries the argument
Embedding-Based Agreement (EBA), which measures agreement by clustering sampled generations in embedding space and selects from the densest clusters.
If this is right
- EBA works on tasks with open-ended outputs where exact matching fails.
- The method requires no additional training and uses off-the-shelf embeddings.
- Agreement signals stay stable when swapping model families or using native hidden states.
- Outputs near the center of the sampled distribution are more reliable than those farther out.
- Scaling the number of samples improves EBA performance more predictably than alternative selection methods.
Where Pith is reading between the lines
- If geometric clustering tracks semantic agreement, the same idea could extend to selecting among image or audio generations without task-specific rules.
- The observed center-periphery quality gradient suggests a simple post-processing step: discard generations that fall outside a radius threshold around the mean embedding.
- Because EBA does not require the model to evaluate its own outputs, it may avoid certain self-preference biases that affect LLM-as-judge methods.
- The approach invites testing whether the same clustering principle identifies consistent chains of thought in multi-step reasoning traces.
Load-bearing premise
Generations that mean similar things will end up close together when placed in an embedding space.
What would settle it
A controlled test on an open-ended task where generations chosen by EBA clustering show no accuracy or quality advantage over randomly chosen generations from the same sample set.
Figures


read the original abstract
Self-consistency improves LLM reasoning by sampling multiple outputs and selecting the most consistent answer, but existing formulations largely rely on exact matching and therefore remain limited to tasks with categorical outputs. In this work, we study self-consistency in open-ended generation tasks such as code synthesis and text summarization. We hypothesize that consistency can be understood as a geometric property of the generation space, where semantically compatible generations concentrate in similar regions of representation space. To study this hypothesis, we introduce Embedding-Based Agreement (EBA), a simple training-free operationalization that estimates agreement by clustering sampled generations in embedding space. Through experiments on mathematical reasoning, code generation, and summarization, we show that agreement in representation space provides a robust and scalable signal of self-consistency for open-ended tasks. In particular, EBA consistently outperforms random selection and exhibits more stable scaling behavior than recent selection approaches based on LLM evaluation or uncertainty estimation. We further show that these agreement signals remain stable across model families and embedding spaces, even with native hidden representations. Finally, our analysis shows that the geometric location occupied by sampled generations is strongly correlated with generation quality: generations concentrated near central regions of representation space tend to correspond to more reliable outputs, whereas peripheral generations are substantially less accurate. Overall, our findings support viewing self-consistency as a property of the geometric organization of sampled generations rather than exact symbolic overlap.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Embedding-Based Agreement (EBA), a training-free method that clusters LLM generations in embedding space to estimate self-consistency for open-ended tasks like code synthesis and text summarization. It hypothesizes that semantically compatible generations concentrate in similar regions of representation space. Experiments on mathematical reasoning, code generation, and summarization tasks show that EBA outperforms random selection, exhibits stable scaling compared to LLM evaluation or uncertainty estimation baselines, remains stable across model families and embedding spaces, and that central generations in representation space correlate with higher quality.
Significance. If the central claims hold, this work would extend the self-consistency paradigm beyond tasks with categorical outputs to open-ended generation without requiring exact string matches or additional LLM-based judges. The geometric interpretation and stability across embeddings are notable strengths, as is the multi-task evaluation including code and summarization. This could enable more reliable selection mechanisms for generative tasks.
major comments (1)
- [Experiments] The load-bearing hypothesis that embedding clusters reflect semantic agreement (rather than superficial features such as token length or syntactic patterns) lacks direct validation. The manuscript reports no controls such as human semantic similarity ratings on cluster members or task-specific equivalence oracles (e.g., code execution equivalence), which is required to substantiate the outperformance claims and the correlation between central location and generation quality.
minor comments (1)
- [Abstract] The abstract asserts that EBA 'consistently outperforms' baselines and that location is 'strongly correlated' with quality, but provides no quantitative metrics, effect sizes, or statistical details to support these statements.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and positive assessment of the work's potential impact. We address the single major comment below.
read point-by-point responses
-
Referee: [Experiments] The load-bearing hypothesis that embedding clusters reflect semantic agreement (rather than superficial features such as token length or syntactic patterns) lacks direct validation. The manuscript reports no controls such as human semantic similarity ratings on cluster members or task-specific equivalence oracles (e.g., code execution equivalence), which is required to substantiate the outperformance claims and the correlation between central location and generation quality.
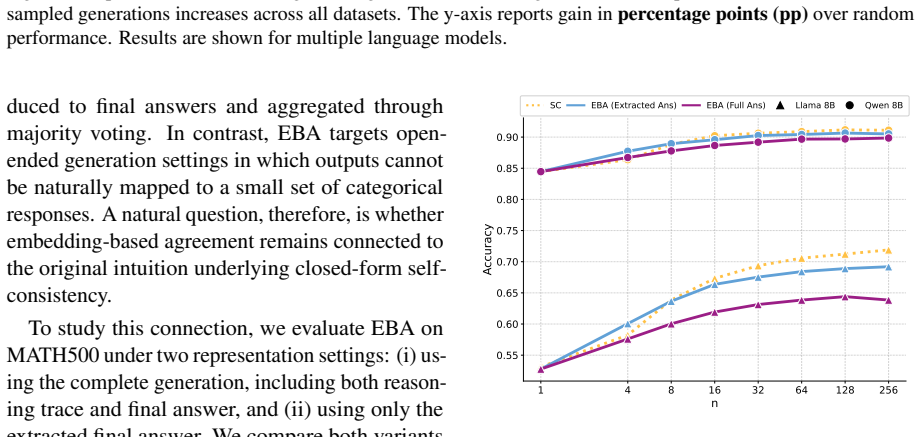
Authors: We agree that direct validation via human semantic similarity ratings or explicit equivalence oracles would strengthen the claims. Our current evidence is indirect but task-grounded: on mathematical reasoning (verifiable exact-match correctness) and code generation (where performance gains over random selection are measured), EBA-selected central generations improve accuracy, which would be unlikely if clusters primarily captured superficial features such as length or syntax. The stable scaling and cross-embedding consistency further suggest semantic structure. Nevertheless, we will add a new analysis subsection in the revision that applies code-execution equivalence checks to cluster members on the code task and reports intra-cluster semantic similarity statistics, directly addressing the validation gap. revision: yes
Circularity Check
No circularity; hypothesis directly operationalized via clustering without reduction to inputs or self-references.
full rationale
The paper states a geometric hypothesis and defines EBA directly as embedding-space clustering to operationalize agreement for open-ended tasks. No equations, fitted parameters renamed as predictions, self-citation chains, or ansatzes appear in the provided text. Claims rest on experimental comparisons (outperformance vs. random/LLM-eval baselines) rather than any derivation that reduces to the hypothesis by construction. This is self-contained empirical work with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption semantically compatible generations concentrate in similar regions of representation space
Reference graph
Works this paper leans on
-
[1]
Advances in Neural Information Processing Systems , volume=
Mind the gap: Understanding the modality gap in multi-modal contrastive representation learning , author=. Advances in Neural Information Processing Systems , volume=
-
[2]
arXiv preprint arXiv:2311.17311 , year=
Universal self-consistency for large language model generation , author=. arXiv preprint arXiv:2311.17311 , year=
-
[3]
Advances in neural information processing systems , volume=
Teaching machines to read and comprehend , author=. Advances in neural information processing systems , volume=
-
[4]
Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Get to the point: Summarization with pointer-generator networks , author=. Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[5]
arXiv preprint arXiv:2107.03374 , year=
Evaluating large language models trained on code , author=. arXiv preprint arXiv:2107.03374 , year=
-
[6]
arXiv preprint arXiv:2103.03874 , year=
Measuring mathematical problem solving with the math dataset , author=. arXiv preprint arXiv:2103.03874 , year=
-
[7]
arXiv preprint arXiv:2305.20050 , year=
Let's Verify Step by Step , author=. arXiv preprint arXiv:2305.20050 , year=
-
[8]
arXiv preprint arXiv:2407.21783 , year=
The llama 3 herd of models , author=. arXiv preprint arXiv:2407.21783 , year=
-
[9]
2025 , eprint=
Qwen3 Technical Report , author=. 2025 , eprint=
2025
-
[10]
arXiv preprint arXiv:2506.05176 , year=
Qwen3 embedding: Advancing text embedding and reranking through foundation models , author=. arXiv preprint arXiv:2506.05176 , year=
-
[11]
arXiv preprint arXiv:2509.20354 , year=
Embeddinggemma: Powerful and lightweight text representations , author=. arXiv preprint arXiv:2509.20354 , year=
-
[12]
Advances in neural information processing systems , volume=
Scalable best-of-n selection for large language models via self-certainty , author=. Advances in neural information processing systems , volume=
-
[13]
arXiv preprint arXiv:2203.11171 , year=
Self-consistency improves chain of thought reasoning in language models , author=. arXiv preprint arXiv:2203.11171 , year=
-
[14]
arXiv preprint arXiv:2509.23067 , year=
Semantic Voting: A Self-Evaluation-Free Approach for Efficient LLM Self-Improvement on Unverifiable Open-ended Tasks , author=. arXiv preprint arXiv:2509.23067 , year=
-
[15]
Journal of computational and applied mathematics , volume=
Silhouettes: a graphical aid to the interpretation and validation of cluster analysis , author=. Journal of computational and applied mathematics , volume=. 1987 , publisher=
1987
-
[16]
arXiv preprint arXiv:1109.2378 , year=
Modern hierarchical, agglomerative clustering algorithms , author=. arXiv preprint arXiv:1109.2378 , year=
-
[17]
Sentence-bert: Sentence embeddings using siamese bert-networks , author=. Proceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (EMNLP-IJCNLP) , pages=
2019
-
[18]
Proceedings of the 2020 conference on empirical methods in natural language processing (EMNLP) , pages=
Dense passage retrieval for open-domain question answering , author=. Proceedings of the 2020 conference on empirical methods in natural language processing (EMNLP) , pages=
2020
-
[19]
Mining text data , pages=
A survey of text clustering algorithms , author=. Mining text data , pages=. 2012 , publisher=
2012
-
[20]
Proceedings of the 27th international conference on computational linguistics , pages=
Neural network models for paraphrase identification, semantic textual similarity, natural language inference, and question answering , author=. Proceedings of the 27th international conference on computational linguistics , pages=
-
[21]
Text summarization branches out , pages=
Rouge: A package for automatic evaluation of summaries , author=. Text summarization branches out , pages=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.