BlazeEdit: Generalist Image Editing on Mobile Devices with Image-to-Image Diffusion Models
Pith reviewed 2026-06-29 12:41 UTC · model grok-4.3
The pith
BlazeEdit is a 195M-parameter image-to-image diffusion model that runs multiple editing tasks on phones in 290 milliseconds by dropping text conditioning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
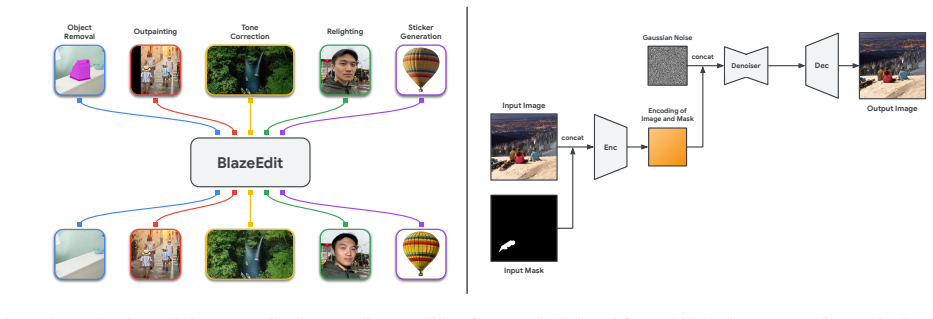
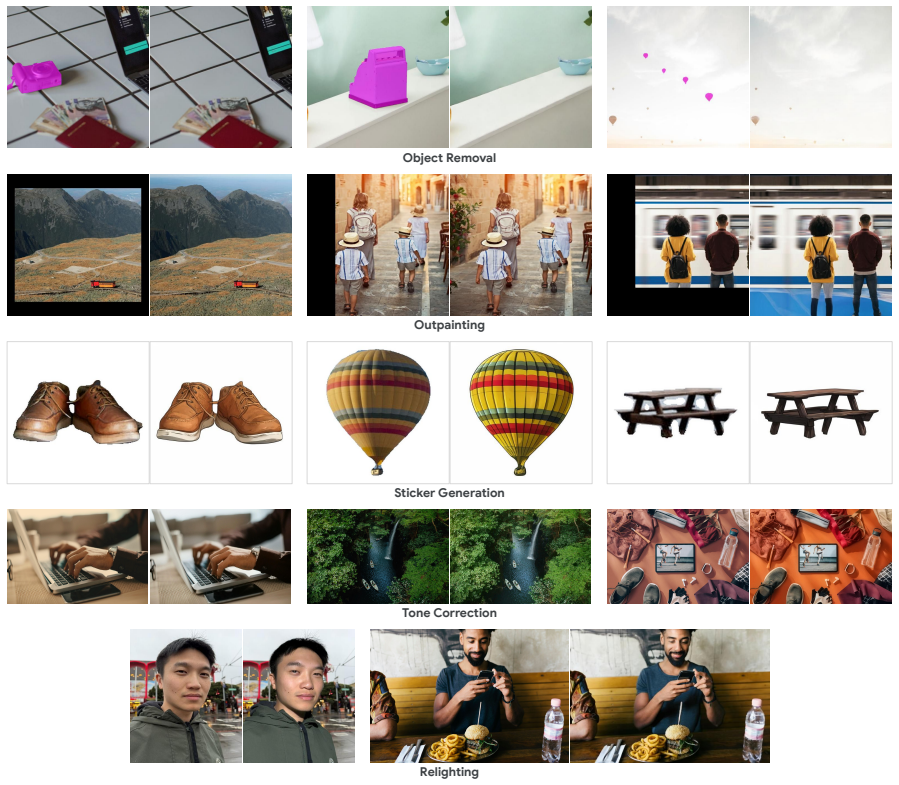
By identifying that many practical image editing tasks do not require text-based guidance, BlazeEdit eliminates the text-conditioning components and develops a multi-task architecture that consolidates object removal, outpainting, tone correction, relighting, and sticker generation into a single, compact model of only 195M parameters that completes a full inference pass in 290ms on a Pixel 10.
What carries the argument
The multi-task image-to-image diffusion architecture without text-conditioning, which shrinks the model to 195M parameters while supporting five editing tasks in one network.
If this is right
- Download size and memory overhead drop substantially compared with 0.5B–1B parameter text-to-image models.
- A single model handles five distinct editing tasks without task-specific networks.
- Full inference completes in 290ms on Pixel 10 hardware.
- All processing stays on the device, removing the need to send images to servers.
- Generation quality stays competitive with larger models on the supported tasks.
Where Pith is reading between the lines
- The same removal of conditioning might shrink models for other mobile vision tasks such as segmentation or depth estimation.
- Real-time video editing could become feasible if the 290ms speed holds or improves under successive frames.
- Hybrid designs that add optional light text guidance only when needed could test whether quality gains justify modest size increases.
- On-device generalist editing opens the possibility of fully local creative tools that do not depend on cloud availability.
Load-bearing premise
Many practical image editing tasks can succeed without text-based guidance.
What would settle it
Direct comparison on the listed editing tasks showing that text-free versions produce visibly worse results than text-conditioned versions of similar size.
Figures
read the original abstract
The remarkable generation quality of modern diffusion models often comes at the cost of massive parameter counts, which necessitate server-side inference with significant computational costs and potential privacy risks. Consequently, there is growing momentum toward developing efficient on-device alternatives. While recent efforts have optimized text-to-image models for mobile hardware, they remain relatively bulky, typically ranging from 0.5B to 1B parameters. We present BlazeEdit, a highly efficient, generalist image-to-image diffusion model tailored for on-device deployment. By identifying that many practical image editing tasks do not require text-based guidance, we eliminate the text-conditioning components and develop a multi-task architecture that consolidates object removal, outpainting, tone correction, relighting, and sticker generation into a single, compact model of only 195M parameters. BlazeEdit achieves a substantial reduction in download size and memory overhead while maintaining competitive generation quality. It completes a full inference pass in just 290ms on a Pixel 10, delivering a seamless, privacy-preserving, and lightning-fast experience for generalist image editing on the edge.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces BlazeEdit, a 195M-parameter image-to-image diffusion model for on-device deployment that performs multiple editing tasks (object removal, outpainting, tone correction, relighting, and sticker generation) by entirely removing text-conditioning components and training a single multi-task model. It claims substantial reductions in download size and memory overhead, competitive generation quality, and a full inference time of 290ms on a Pixel 10 device, enabling privacy-preserving generalist editing on the edge.
Significance. If the efficiency and quality claims are validated through rigorous experiments, the work would offer a meaningful contribution to on-device diffusion models by demonstrating that task-specific simplification can yield compact, fast models suitable for mobile hardware. This could reduce server dependency and privacy risks in consumer image editing applications. The absence of any quantitative support in the manuscript, however, prevents assessment of whether these gains are realized without quality trade-offs.
major comments (2)
- [Abstract] Abstract: The claim that BlazeEdit 'maintains competitive generation quality' after eliminating text-conditioning components is unsupported, as the manuscript supplies no quantitative results, baselines, ablation studies, or error analysis to substantiate performance on the listed tasks.
- [Abstract] Abstract: The key assumption that 'many practical image editing tasks do not require text-based guidance' is stated without any comparison to a text-conditioned baseline of comparable size; this assumption is load-bearing for the reported parameter count (195M) and inference speed (290ms), as any need for semantic guidance would require reintroducing conditioning and undermine the efficiency gains.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback emphasizing the need for quantitative validation. We agree that the current manuscript does not provide sufficient numerical evidence or comparisons to support the abstract claims, and we will revise the paper to address both major comments through added experiments.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that BlazeEdit 'maintains competitive generation quality' after eliminating text-conditioning components is unsupported, as the manuscript supplies no quantitative results, baselines, ablation studies, or error analysis to substantiate performance on the listed tasks.
Authors: We agree that the claim of competitive generation quality is currently unsupported by quantitative evidence. The manuscript presents only qualitative examples. In the revised version we will add a new Experiments section containing task-specific quantitative metrics (e.g., PSNR/SSIM for tone correction and relighting, mask IoU for object removal, perceptual scores for outpainting and sticker generation), comparisons against single-task baselines of similar size, and ablation studies on multi-task training. Error analysis and failure-case discussion will also be included. revision: yes
-
Referee: [Abstract] Abstract: The key assumption that 'many practical image editing tasks do not require text-based guidance' is stated without any comparison to a text-conditioned baseline of comparable size; this assumption is load-bearing for the reported parameter count (195M) and inference speed (290ms), as any need for semantic guidance would require reintroducing conditioning and undermine the efficiency gains.
Authors: We acknowledge that the assumption lacks direct empirical support via a same-size text-conditioned counterpart. While the selected tasks are defined via image inputs (masks, reference images) rather than text, we will add an ablation study in the revision that trains and measures a text-conditioned variant of comparable parameter count. This will quantify the impact on model size, inference latency on the Pixel 10, and task performance, thereby validating whether text conditioning can be omitted without quality loss for these specific editing operations. revision: yes
Circularity Check
No circularity: applied system description with no equations or fitted predictions
full rationale
The paper presents an engineering system for on-device image editing by removing text-conditioning components and training a compact multi-task image-to-image diffusion model. No derivation chain, equations, or parameter-fitting steps are described that would reduce reported outcomes (parameter count, inference time, quality) to prior fitted values by construction. The central design choice is an explicit assumption about task requirements rather than a self-referential prediction or self-citation load-bearing premise. The work is self-contained as a practical implementation report without the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Many practical image editing tasks do not require text-based guidance
Reference graph
Works this paper leans on
-
[1]
Build- ing normalizing flows with stochastic interpolants
Michael Samuel Albergo and Eric Vanden-Eijnden. Build- ing normalizing flows with stochastic interpolants. InInter- national Conference on Learning Representations, 2023. 1
2023
-
[2]
MaskGIT: Masked generative image transformer
Huiwen Chang, Han Zhang, Lu Jiang, Ce Liu, and William T Freeman. MaskGIT: Masked generative image transformer. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 11315–11325, 2022. 3
2022
-
[3]
Gary Chan, Mingming Gong, Sergey Tulyakov, Anil Kag, Yanwu Xu, and Jian Ren
Jierun Chen, Dongting Hu, Xijie Huang, Huseyin Coskun, Arpit Sahni, Aarush Gupta, Anujraaj Goyal, Dishani Lahiri, Rajesh Singh, Yerlan Idelbayev, Junli Cao, Yanyu Li, Kwang-Ting Cheng, S.-H. Gary Chan, Mingming Gong, Sergey Tulyakov, Anil Kag, Yanwu Xu, and Jian Ren. Snap- Gen: Taming high-resolution text-to-image models for mo- bile devices with efficien...
2025
-
[4]
Scaling rec- tified flow transformers for high-resolution image synthesis
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas M ¨uller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, Dustin Podell, Tim Dockhorn, Zion English, and Robin Rombach. Scaling rec- tified flow transformers for high-resolution image synthesis. InInternational Conference on Machine Learning, 2024. 1
2024
-
[5]
UniVG: A generalist diffusion model for unified image generation and editing
Tsu-Jui Fu, Yusu Qian, Chen Chen, Wenze Hu, Zhe Gan, and Yinfei Yang. UniVG: A generalist diffusion model for unified image generation and editing. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 17160–17170, 2025. 2
2025
-
[6]
Controllable light diffusion for portraits
David Futschik, Kelvin Ritland, James Vecore, Sean Fanello, Sergio Orts-Escolano, Brian Curless, Daniel S`ykora, and Ro- hit Pandey. Controllable light diffusion for portraits. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8412–8421, 2023. 3
2023
-
[7]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. InProceed- ings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 770–778, 2016. 2
2016
-
[8]
Masked autoencoders are scalable vision learners
Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Doll´ar, and Ross Girshick. Masked autoencoders are scalable vision learners. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 16000– 16009, 2022. 3
2022
-
[9]
Denoising dif- fusion probabilistic models
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising dif- fusion probabilistic models. InAdvances in Neural Informa- tion Processing Systems, 2020. 1
2020
-
[10]
sim- ple diffusion: End-to-end diffusion for high resolution im- ages
Emiel Hoogeboom, Jonathan Heek, and Tim Salimans. sim- ple diffusion: End-to-end diffusion for high resolution im- ages. InInternational Conference on Machine Learning,
-
[11]
LoRA: Low-rank adaptation of large language models
Edward J Hu, yelong shen, Phillip Wallis, Zeyuan Allen- Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. LoRA: Low-rank adaptation of large language models. InIn- ternational Conference on Learning Representations, 2022. 3
2022
-
[12]
Le, Tuan Pham, Sangho Lee, Christopher Clark, Aniruddha Kembhavi, Stephan Mandt, Ranjay Krishna, and Jiasen Lu
Duong H. Le, Tuan Pham, Sangho Lee, Christopher Clark, Aniruddha Kembhavi, Stephan Mandt, Ranjay Krishna, and Jiasen Lu. One diffusion to generate them all. InProceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2671–2682, 2025. 2
2025
-
[13]
Snap- Fusion: Text-to-image diffusion model on mobile devices within two seconds
Yanyu Li, Huan Wang, Qing Jin, Ju Hu, Pavlo Chemerys, Yun Fu, Yanzhi Wang, Sergey Tulyakov, and Jian Ren. Snap- Fusion: Text-to-image diffusion model on mobile devices within two seconds. InAdvances in Neural Information Pro- cessing Systems, 2023. 1, 2, 4
2023
-
[14]
Yaron Lipman, Ricky T. Q. Chen, Heli Ben-Hamu, Maxim- ilian Nickel, and Matthew Le. Flow matching for generative modeling. InInternational Conference on Learning Repre- sentations, 2023. 1
2023
-
[15]
Flow straight and fast: Learning to generate and transfer data with rectified flow
Xingchao Liu, Chengyue Gong, and Qiang Liu. Flow straight and fast: Learning to generate and transfer data with rectified flow. InInternational Conference on Learning Rep- resentations, 2023. 1
2023
-
[16]
UniControl: A unified diffusion model for controllable visual generation in the wild
Can Qin, Shu Zhang, Ning Yu, Yihao Feng, Xinyi Yang, Yingbo Zhou, Huan Wang, Juan Carlos Niebles, Caiming Xiong, Silvio Savarese, Stefano Ermon, Yun Fu, and Ran Xu. UniControl: A unified diffusion model for controllable visual generation in the wild. InAdvances in Neural Infor- mation Processing Systems, 2023. 2
2023
-
[17]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision. InInternational Conference on Machine Learning, 2021. 1
2021
-
[18]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj ¨orn Ommer. High-resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10684–10695, 2022. 2
2022
-
[19]
Palette: Image-to-image diffusion models
Chitwan Saharia, William Chan, Huiwen Chang, Chris Lee, Jonathan Ho, Tim Salimans, David Fleet, and Mohammad Norouzi. Palette: Image-to-image diffusion models. In ACM SIGGRAPH 2022 Conference Proceedings, pages 1– 10, 2022. 2, 3
2022
-
[20]
Deep unsupervised learning using nonequilibrium thermodynamics
Jascha Sohl-Dickstein, Eric Weiss, Niru Maheswaranathan, and Surya Ganguli. Deep unsupervised learning using nonequilibrium thermodynamics. InInternational Confer- ence on Machine Learning, 2015. 1
2015
-
[21]
Score-based generative modeling through stochastic differential equa- tions
Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Ab- hishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equa- tions. InInternational Conference on Learning Represen- tations, 2021. 1
2021
-
[22]
Gemma Team, Morgane Riviere, Shreya Pathak, Pier Giuseppe Sessa, Cassidy Hardin, Surya Bhupati- raju, L´eonard Hussenot, Thomas Mesnard, Bobak Shahriari, Alexandre Ram´e, Johan Ferret, Peter Liu, Pouya Tafti, Abe Friesen, Michelle Casbon, Sabela Ramos, Ravin Kumar, Charline Le Lan, Sammy Jerome, Anton Tsitsulin, Nino Vieillard, Piotr Stanczyk, Sertan Girg...
2024
-
[23]
Attention is all you need
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszko- reit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. InAdvances in neural information processing systems, 2017. 2
2017
-
[24]
ObjectDrop: Bootstrap- ping counterfactuals for photorealistic object removal and in- sertion
Daniel Winter, Matan Cohen, Shlomi Fruchter, Yael Pritch, Alex Rav-Acha, and Yedid Hoshen. ObjectDrop: Bootstrap- ping counterfactuals for photorealistic object removal and in- sertion. InEuropean Conference on Computer Vision, pages 112–129. Springer, 2024. 3
2024
-
[25]
Qwen-Image technical report,
Chenfei Wu, Jiahao Li, Jingren Zhou, Junyang Lin, Kaiyuan Gao, Kun Yan, Sheng ming Yin, Shuai Bai, Xiao Xu, Yilei Chen, Yuxiang Chen, Zecheng Tang, Zekai Zhang, Zhengyi Wang, An Yang, Bowen Yu, Chen Cheng, Dayiheng Liu, De- qing Li, Hang Zhang, Hao Meng, Hu Wei, Jingyuan Ni, Kai Chen, Kuan Cao, Liang Peng, Lin Qu, Minggang Wu, Peng Wang, Shuting Yu, Tingk...
-
[26]
DreamOmni: Unified image generation and editing
Bin Xia, Yuechen Zhang, Jingyao Li, Chengyao Wang, Yitong Wang, Xinglong Wu, Bei Yu, and Jiaya Jia. DreamOmni: Unified image generation and editing. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 28533–28543, 2025
2025
-
[27]
OmniGen: Unified image genera- tion
Shitao Xiao, Yueze Wang, Junjie Zhou, Huaying Yuan, Xin- grun Xing, Ruiran Yan, Chaofan Li, Shuting Wang, Tiejun Huang, and Zheng Liu. OmniGen: Unified image genera- tion. InProceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition, pages 13294–13304, 2025
2025
-
[28]
Versatile Diffusion: Text, images and variations all in one diffusion model
Xingqian Xu, Zhangyang Wang, Gong Zhang, Kai Wang, and Humphrey Shi. Versatile Diffusion: Text, images and variations all in one diffusion model. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 7754–7765, 2023. 2
2023
-
[29]
Improved distribution matching distillation for fast image synthesis
Tianwei Yin, Micha ¨el Gharbi, Taesung Park, Richard Zhang, Eli Shechtman, Fredo Durand, and Bill Freeman. Improved distribution matching distillation for fast image synthesis. In Advances in neural information processing systems, 2024. 3
2024
-
[30]
One-step diffusion with distribution matching distillation
Tianwei Yin, Micha ¨el Gharbi, Richard Zhang, Eli Shecht- man, Fredo Durand, William T Freeman, and Taesung Park. One-step diffusion with distribution matching distillation. In Proceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition, pages 6613–6623, 2024. 3
2024
-
[31]
Uni- ControlNet: All-in-one control to text-to-image diffusion models
Shihao Zhao, Dongdong Chen, Yen-Chun Chen, Jianmin Bao, Shaozhe Hao, Lu Yuan, and Kwan-Yee K Wong. Uni- ControlNet: All-in-one control to text-to-image diffusion models. InAdvances in neural information processing sys- tems, 2023. 2
2023
-
[32]
MobileDiffusion: Instant text-to-image gener- ation on mobile devices
Yang Zhao, Yanwu Xu, Zhisheng Xiao, Haolin Jia, and Tingbo Hou. MobileDiffusion: Instant text-to-image gener- ation on mobile devices. InEuropean Conference on Com- puter Vision, pages 225–242. Springer, 2024. 1, 2, 3, 4
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.