The Score Granularity Gap in Black-Box LLM Classification: A Comparative Study of Confidence Constructions
Pith reviewed 2026-06-26 11:42 UTC · model grok-4.3
The pith
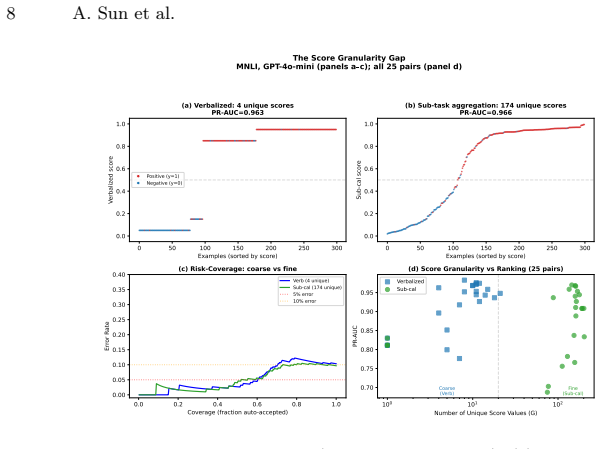
Single-shot verbalized confidence from LLMs ranks cases well but supplies only a handful of distinct values for setting risk thresholds.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
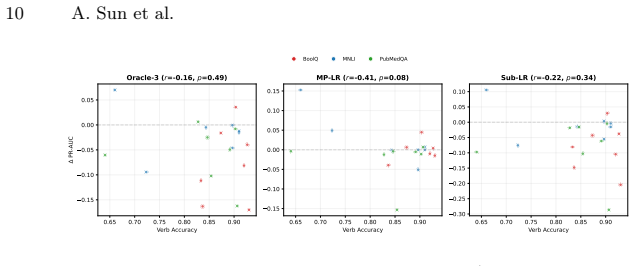
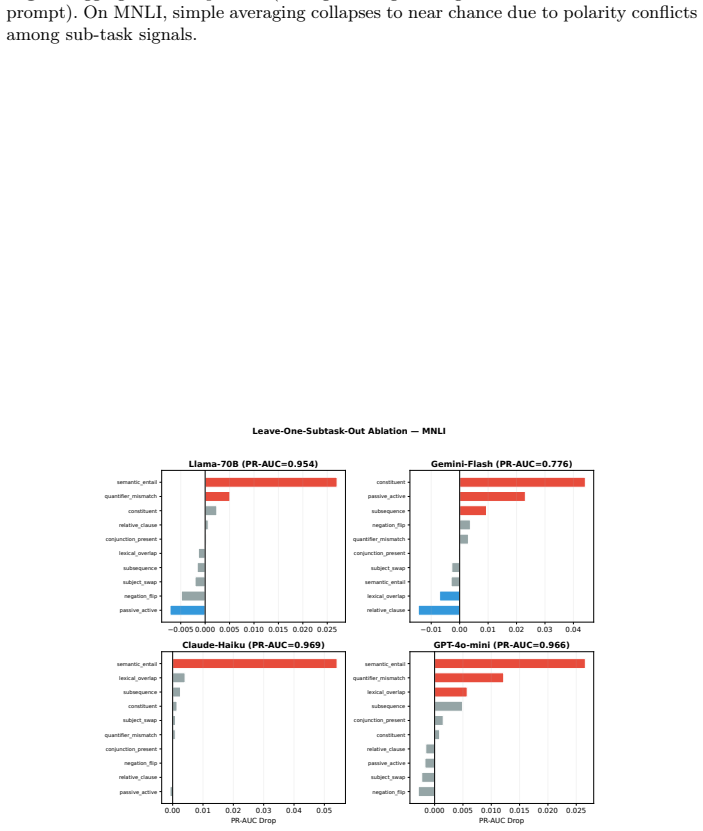
The score granularity gap measures how many distinct thresholdable values a confidence construction actually supplies once mapped to class probabilities. Single-shot verbalized confidence, after correct conversion, ranks cases effectively across the tested setups but collapses to only a handful of distinct values. Token-probability constructions and multi-query aggregations produce more distinct values at different inference costs, with the latter improving weak models while sometimes harming already-strong ones. These patterns hold across the nine LLMs and three benchmarks examined.
What carries the argument
The score granularity gap: the effective number of distinct, usable threshold points a confidence score supplies after conversion to class probabilities.
If this is right
- Multi-query aggregation widens granularity for weaker models but can reduce ranking quality for stronger models.
- Token-probability scores supply finer threshold resolution than single verbalized numbers.
- Operators must trade off the number of available thresholds against ranking performance and inference cost when choosing a construction.
- Proper conversion of verbalized confidence to probabilities is required to realize its ranking strength despite low granularity.
Where Pith is reading between the lines
- Systems that combine verbalized scores with token probabilities could achieve both strong ranking and finer control without always incurring multi-query cost.
- The handful-of-values pattern may limit selective prediction on tasks requiring many risk levels even if ranking remains good.
- Deployment pipelines could pre-compute the distinct values for each construction to decide thresholds in advance rather than assuming continuous scores.
Load-bearing premise
The 25 model-dataset pairs and seven chosen confidence constructions represent the space of black-box LLM classification deployments that use selective prediction.
What would settle it
An experiment on additional LLMs or benchmarks in which single-shot verbalized confidence produces many more than a handful of distinct values after conversion to probabilities would falsify the claimed coarseness.
Figures





read the original abstract
Large language models (LLMs) are increasingly deployed as black-box classifiers in pipelines that automate confident decisions and route uncertain ones to human review. Such selective prediction needs a confidence score that an operator can threshold at a chosen risk level. Prior work asks whether LLM confidence is well calibrated or well ranked; we ask a complementary, deployment-oriented question that has been largely overlooked: at what resolution can the score be thresholded? We call the answer the score granularity gap. Through a controlled comparison of seven ways to build a confidence score, from a single verbalized number, to token probabilities, to querying the model many times and combining the answers, across 25 model-dataset pairs (9 LLMs, 3 benchmarks), we find that single-shot verbalized confidence, once correctly converted to a class probability, ranks cases surprisingly well, yet takes only a handful of distinct values. It therefore offers an operator only a few coarse thresholds, no matter how well it ranks. We show which constructions widen this gap, at what inference cost, and with what effect on ranking, notably that multi-query aggregation helps weak models but can degrade already-strong ones. We translate these trade-offs into concrete deployment guidance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper conducts a controlled empirical comparison of seven confidence constructions (single-shot verbalized, token probabilities, multi-query aggregation, etc.) for black-box LLM classification on 25 model-dataset pairs (9 LLMs, 3 benchmarks). It claims that single-shot verbalized confidence, after conversion to class probability, ranks cases well yet supplies only a handful of distinct values and thus only coarse thresholds for selective prediction; multi-query methods widen granularity at varying inference cost and can improve weak models while degrading strong ones.
Significance. If the granularity-gap finding is robust, the work supplies a deployment-oriented insight that complements calibration and ranking studies, with direct measurements across multiple constructions and a translation into concrete guidance on cost-granularity-ranking trade-offs. The purely empirical design with no fitted parameters or self-referential predictions is a methodological strength.
major comments (2)
- [Experimental setup] Experimental setup (likely §3 or §4): no selection criteria, ablation on model scale/family, or sensitivity analysis are provided for the 9 LLMs and 3 benchmarks. The central claim that verbalized confidence yields only a handful of distinct values (and therefore coarse thresholds) is load-bearing on these setups being representative; without such checks the observed gap could be an artifact of the chosen pool rather than a general property of black-box verbalized scores.
- [Methods] Methods (likely §3.2–3.3): the exact conversion procedure from raw verbalized strings to class probabilities, the statistical tests for ranking quality, error-bar computation, and any data-exclusion rules are not described at the level needed to reproduce or verify the ranking-versus-granularity results.
minor comments (2)
- [Figures] Figure captions and axis labels should explicitly state the exact metric (e.g., AUC, number of distinct values, or threshold count) and whether error bars represent standard deviation across seeds or datasets.
- [Section 3] A short table summarizing the seven constructions (input format, output format, inference cost) would improve readability before the main results.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. We address the two major comments point by point below, indicating where the manuscript will be revised to improve clarity and robustness.
read point-by-point responses
-
Referee: [Experimental setup] Experimental setup (likely §3 or §4): no selection criteria, ablation on model scale/family, or sensitivity analysis are provided for the 9 LLMs and 3 benchmarks. The central claim that verbalized confidence yields only a handful of distinct values (and therefore coarse thresholds) is load-bearing on these setups being representative; without such checks the observed gap could be an artifact of the chosen pool rather than a general property of black-box verbalized scores.
Authors: The nine LLMs were selected to cover distinct families (GPT, Llama, Mistral, and others) and scales (7B to >100B parameters), while the three benchmarks are standard classification tasks used in prior LLM evaluation work. We acknowledge that explicit selection criteria and sensitivity checks were not stated in the submitted version. We will add a dedicated paragraph in Section 3 describing the rationale for model and dataset diversity and include an appendix reporting results on a held-out model scale and an additional benchmark to verify that the granularity gap persists. revision: yes
-
Referee: [Methods] Methods (likely §3.2–3.3): the exact conversion procedure from raw verbalized strings to class probabilities, the statistical tests for ranking quality, error-bar computation, and any data-exclusion rules are not described at the level needed to reproduce or verify the ranking-versus-granularity results.
Authors: We agree that the current description is insufficient for full reproducibility. We will expand Sections 3.2–3.3 with (i) the precise string-to-probability mapping (including rules for non-numeric or out-of-range verbalizations), (ii) the ranking metric and associated statistical test, (iii) the bootstrap procedure used for error bars, and (iv) explicit data-exclusion criteria. Pseudocode for the conversion and evaluation pipeline will be added to the appendix. revision: yes
Circularity Check
No circularity: purely empirical comparative measurements
full rationale
The paper performs direct empirical comparisons of seven confidence constructions across 25 model-dataset pairs. No derivations, equations, fitted parameters renamed as predictions, or self-citation chains appear in the load-bearing claims. All reported findings (ranking quality, number of distinct values, granularity) are measurements taken from the experiments themselves, with no reduction to inputs by construction. The representativeness concern is an external-validity issue, not a circularity issue.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The 25 model-dataset pairs and seven constructions are representative of black-box LLM selective prediction deployments.
Reference graph
Works this paper leans on
-
[1]
Angelopoulos, A.N., Bates, S., Fisch, A., et al.: Conformal Risk Control (Jun 2025).https://doi.org/10.48550/arXiv.2208.02814,http://arxiv.org/abs/ 2208.02814, arXiv:2208.02814 [stat]
-
[2]
Clark, C., Lee, K., Chang, M.W., et al.: BoolQ: Exploring the Surprising Dif- ficulty of Natural Yes/No Questions (May 2019).https://doi.org/10.48550/ arXiv.1905.10044,http://arxiv.org/abs/1905.10044, arXiv:1905.10044 [cs]
Pith/arXiv arXiv 2019
-
[3]
Geifman, Y., El-Yaniv, R.: Selective Classification for Deep Neural Networks (Jun 2017).https://doi.org/10.48550/arXiv.1705.08500,http://arxiv.org/abs/ 1705.08500, arXiv:1705.08500 [cs]
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1705.08500 2017
-
[4]
Guo, C., Pleiss, G., Sun, Y., Weinberger, K.Q.: On Calibration of Modern Neural Networks (Aug 2017).https://doi.org/10.48550/arXiv.1706.04599,http:// arxiv.org/abs/1706.04599, arXiv:1706.04599 [cs]
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1706.04599 2017
-
[5]
Jin,Q.,Dhingra,B.,Liu,Z.,etal.:PubMedQA:ADatasetforBiomedicalResearch Question Answering (Sep 2019).https://doi.org/10.48550/arXiv.1909.06146, http://arxiv.org/abs/1909.06146, arXiv:1909.06146 [cs]
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1909.06146 2019
-
[6]
Kadavath,S.,Conerly,T.,Askell,A.,etal.:LanguageModels(Mostly)KnowWhat They Know (Nov 2022),http://arxiv.org/abs/2207.05221, arXiv:2207.05221 [cs]
Pith/arXiv arXiv 2022
-
[7]
Khot, T., Trivedi, H., Finlayson, M., et al.: Decomposed Prompting: A Modular Approach for Solving Complex Tasks (Apr 2023).https://doi.org/10.48550/ arXiv.2210.02406,http://arxiv.org/abs/2210.02406, arXiv:2210.02406 [cs]
Pith/arXiv arXiv 2023
-
[8]
Kuhn, L., Gal, Y., Farquhar, S.: Semantic Uncertainty: Linguistic Invari- ances for Uncertainty Estimation in Natural Language Generation (Apr 2023).https://doi.org/10.48550/arXiv.2302.09664,http://arxiv.org/abs/ 2302.09664, arXiv:2302.09664 [cs]
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2302.09664 2023
-
[9]
In: Pro- ceedings of Machine Learning Research
Kull, M., Silva Filho, T., Flach, P.: Beta calibration: A well-founded and easily implemented improvement on logistic calibration for binary classifiers. In: Pro- ceedings of Machine Learning Research. vol. 54, pp. 623–635 (2017)
2017
-
[10]
Lin, S., Hilton, J., Evans, O.: Teaching Models to Express Their Uncertainty in Words (Jun 2022).https://doi.org/10.48550/arXiv.2205.14334,http:// arxiv.org/abs/2205.14334, arXiv:2205.14334 [cs]
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2205.14334 2022
-
[11]
McCoy, R.T., Pavlick, E., Linzen, T.: Right for the Wrong Reasons: Diagnos- ing Syntactic Heuristics in Natural Language Inference (Jun 2019).https: //doi.org/10.48550/arXiv.1902.01007,http://arxiv.org/abs/1902.01007, arXiv:1902.01007 [cs]
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1902.01007 2019
-
[12]
Pedapati, T., Dhurandhar, A., Ghosh, S., et al.: Large Language Model Confidence Estimation via Black-Box Access (Jul 2025).https://doi.org/10.48550/arXiv. 2406.04370,http://arxiv.org/abs/2406.04370, arXiv:2406.04370 [cs] The Score Granularity Gap 15
work page internal anchor Pith review doi:10.48550/arxiv 2025
-
[13]
In: Proceedings of the 3rd Workshop on Trustworthy Natural Language Process- ing (TrustNLP 2023)
Portillo Wightman, G., Delucia, A., Dredze, M.: Strength in Numbers: Es- timating Confidence of Large Language Models by Prompt Agreement. In: Proceedings of the 3rd Workshop on Trustworthy Natural Language Process- ing (TrustNLP 2023). pp. 326–362. Association for Computational Linguistics, Toronto, Canada (2023).https://doi.org/10.18653/v1/2023.trustnlp...
-
[14]
Tian, K., Mitchell, E., Zhou, A., et al.: Just Ask for Calibration: Strategies for Eliciting Calibrated Confidence Scores from Language Models Fine-Tuned with Human Feedback. In: Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. pp. 5433–5442. Association for Computational Linguistics, Singapore (2023).https://doi.org...
-
[15]
https://doi.org/10.48550/ARXIV.2308.01222,https://arxiv.org/abs/2308
Wang, C.: Calibration in Deep Learning: A Survey of the State-of-the-Art (2023). https://doi.org/10.48550/ARXIV.2308.01222,https://arxiv.org/abs/2308. 01222, version Number: 4
-
[16]
48550/arXiv.2402.11279,http://arxiv.org/abs/2402.11279, arXiv:2402.11279 [cs]
Wang,P.,Wang,Y.,Diao,M.,etal.:Multi-PerspectiveConsistencyEnhancesCon- fidence Estimation in Large Language Models (Feb 2024).https://doi.org/10. 48550/arXiv.2402.11279,http://arxiv.org/abs/2402.11279, arXiv:2402.11279 [cs]
arXiv 2024
-
[17]
Wei, J., Wang, X., Schuurmans, D., et al.: Chain-of-Thought Prompting Elicits Reasoning in Large Language Models (Jan 2023).https://doi.org/10.48550/ arXiv.2201.11903,http://arxiv.org/abs/2201.11903, arXiv:2201.11903 [cs]
Pith/arXiv arXiv 2023
-
[18]
Wen, B., Yao, J., Feng, S., et al.: Know Your Limits: A Survey of Abstention in Large Language Models
-
[19]
A Broad-Coverage Challenge Corpus for Sentence Understanding through Inference
Williams, A., Nangia, N., Bowman, S.: A Broad-Coverage Challenge Corpus for Sentence Understanding through Inference. In: Proceedings of the 2018 Confer- ence of the North American Chapter of the Association for Computational Lin- guistics: Human Language Technologies, Volume 1 (Long Papers). pp. 1112–1122. Association for Computational Linguistics, New O...
work page internal anchor Pith review doi:10.18653/v1/n18-1101 2018
-
[20]
Xiong, M., Hu, Z., Lu, X., et al.: CAN LLMS EXPRESS THEIR UNCERTAINTY? AN EMPIRICAL EVALUATION OF CONFIDENCE ELICI- TATION IN LLMS (2024)
2024
-
[21]
Xue, B., Wang, H., Wang, R., et al.: MlingConf: A Comprehensive Study of Multilingual Confidence Estimation on Large Language Models (May 2025).https://doi.org/10.48550/arXiv.2402.13606,http://arxiv.org/abs/ 2402.13606, arXiv:2402.13606 [cs]
-
[22]
Yang, D., Tsai, Y.H.H., Yamada, M.: On Verbalized Confidence Scores for LLMs
-
[23]
48550/arXiv.2602.00977,http://arxiv.org/abs/2602.00977, arXiv:2602.00977 [cs]
Yang, P., Wen, J., Jin, H., et al.: Trust in One Round: Confidence Estimation for Large Language Models via Structural Signals (Feb 2026).https://doi.org/10. 48550/arXiv.2602.00977,http://arxiv.org/abs/2602.00977, arXiv:2602.00977 [cs]
arXiv 2026
-
[24]
Zhao, T.Z., Wallace, E., Feng, S., et al.: Calibrate Before Use:Improving Few-Shot Performance of Language Models
-
[25]
Zhou, K., Hwang, J.D., Ren, X., Sap, M.: Relying on the Unreliable: The Impact of Language Models’ Reluctance to Express Uncertainty (Jul 2024).https://doi.org/10.48550/arXiv.2401.06730,http://arxiv.org/abs/ 2401.06730, arXiv:2401.06730 [cs] 16 A. Sun et al. A Full Per-Pair Results Table 4 reports every model–dataset pair. Verb is single-shot verbalized c...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.