From Player to Master: Enhancing Test-Time Learning of LLM Agents via Reinforcement Learning over Memory
Pith reviewed 2026-06-27 18:46 UTC · model grok-4.3
The pith
MemoPilot trains memory updates with multi-turn GRPO so frozen LLM agents improve through sequential experience.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
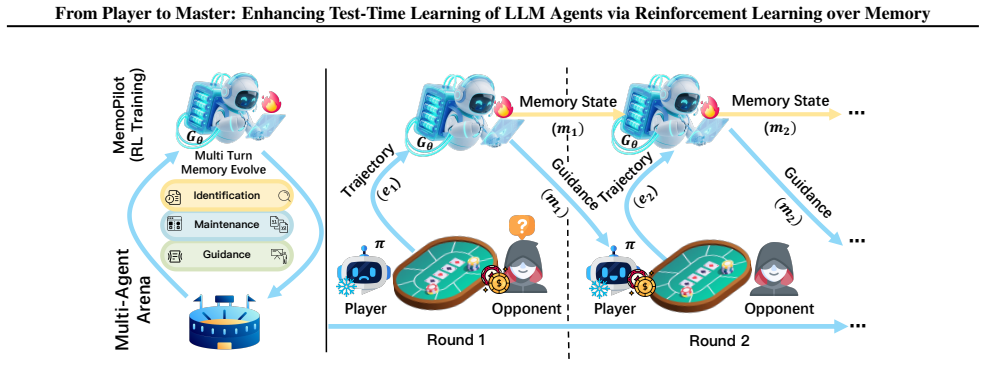
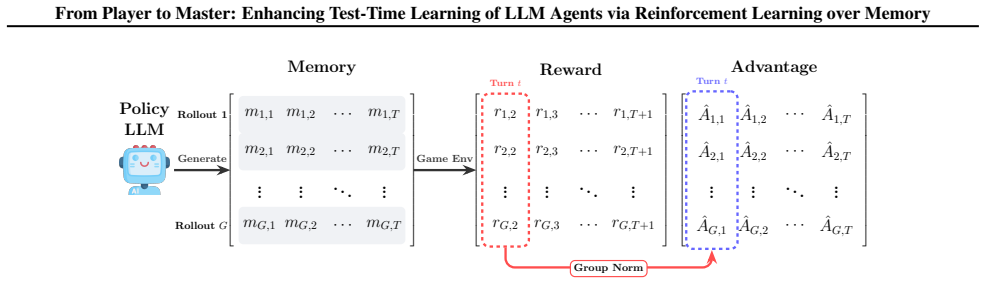
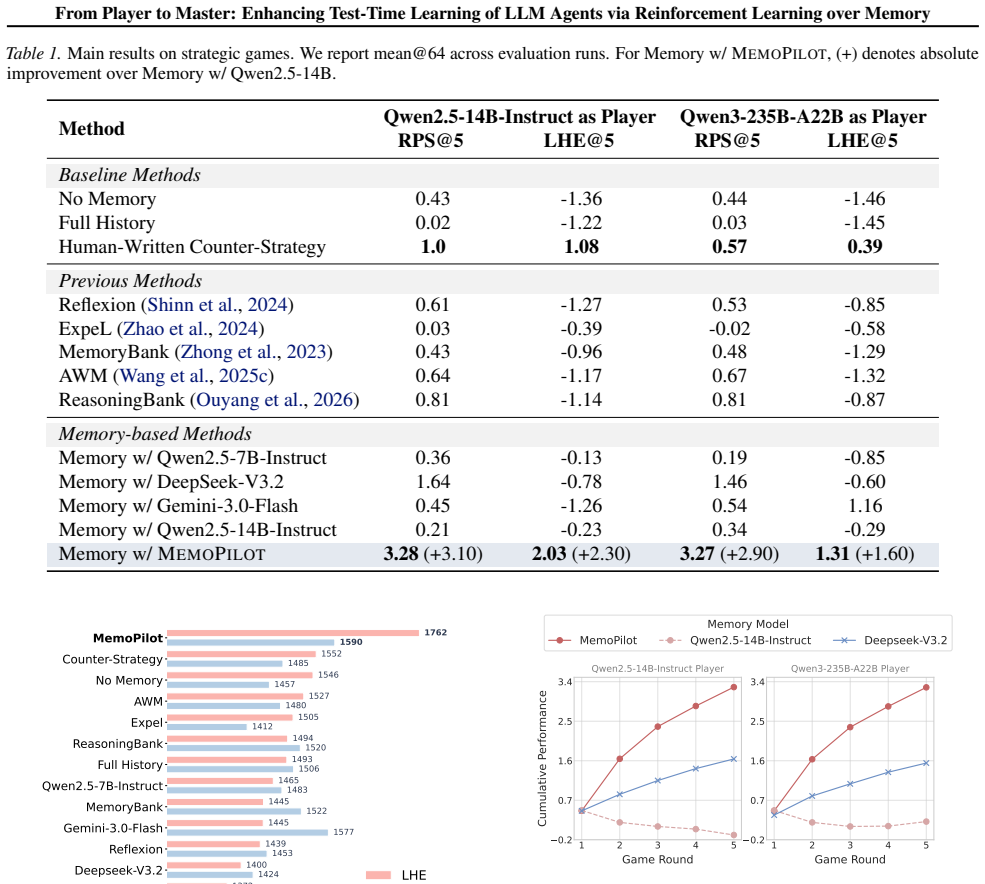
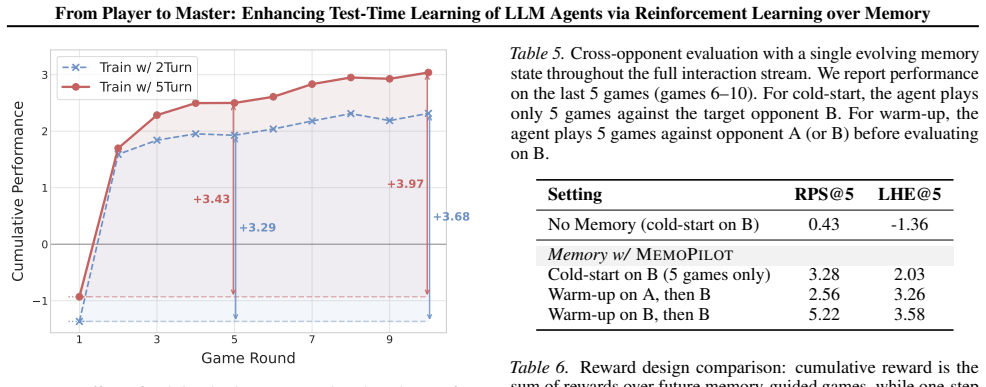
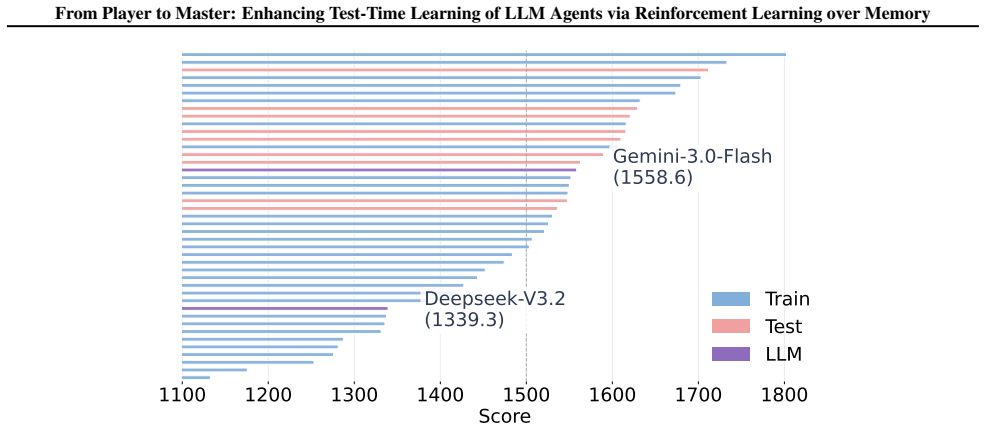
MemoPilot is a plug-in memory copilot that formulates memory updating as a multi-turn decision problem and optimizes it end-to-end with multi-turn GRPO. The training recipe supplies a turn-wise reward signal together with context-independent, turn-level advantage estimation across rollouts. This yields memory updates that let a frozen player reach first-place Elo ratings of 1762 on Limit Texas Hold'em and 1590 on multi-round Rock-Paper-Scissors while surpassing all compared baseline memory methods and proprietary models including DeepSeek-V3.2.
What carries the argument
MemoPilot, the trained memory-update policy that treats each memory revision as an action in a multi-turn RL problem solved by GRPO with turn-wise rewards and context-independent advantage estimation.
If this is right
- The frozen base LLM reaches the highest Elo ratings (1762 on LHE, 1590 on RPS) among all tested systems.
- Performance exceeds every baseline memory-update method and several proprietary models including DeepSeek-V3.2.
- Turn-wise rewards plus context-independent advantage estimates produce more stable training and finer credit assignment than standard multi-turn RL.
- Test-time learning improves across both game environments without any change to the underlying player model.
Where Pith is reading between the lines
- The same training approach could be applied to non-game sequential tasks such as multi-turn dialogue or tool-use chains.
- Context-independent advantage estimation may allow the method to scale to interaction lengths longer than those seen in the two testbeds.
- If the learned memory policy transfers, developers could swap in different base LLMs without retraining the memory component.
- The plug-in design suggests that memory training can be added to existing agent pipelines without modifying the core model weights.
Load-bearing premise
The multi-turn GRPO recipe with turn-wise rewards and context-independent advantage estimation produces memory updates that generalize beyond the two game testbeds.
What would settle it
Running MemoPilot on a third sequential decision task unrelated to RPS or LHE and checking whether the Elo or win-rate gains over baselines disappear.
Figures


read the original abstract
Large language model (LLM) agents are increasingly deployed in long-running settings where improving through experience at test time becomes important. A common approach is to update an explicit memory after each interaction to guide future decisions. However, most existing methods rely on hand-designed prompting rules, making it difficult to align memory updates with downstream objectives over multi-step horizons consistently. We propose MemoPilot, a plug-in memory copilot that explicitly trains the memory update process to improve a frozen LLM's performance across sequential interactions. We formulate memory updating as a multi-turn decision problem and optimize it end-to-end with multi-turn GRPO. Our training recipe introduces (i) a turn-wise reward signal and (ii) a context-independent, turn-level advantage estimation across rollouts, enabling finer-grained credit assignment and more stable training in multi-turn settings. We evaluate MemoPilot on two testbeds: multi-round Rock-Paper-Scissors (RPS) and Limit Texas Hold'em (LHE). Across both environments, MemoPilot substantially improves test-time learning of a frozen player over strong baselines, ranking first in Elo ratings on both games (1762 on LHE and 1590 on RPS) and outperforming all baseline memory methods and proprietary models, including DeepSeek-V3.2.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes MemoPilot, a plug-in memory copilot that formulates memory updating as a multi-turn decision problem and optimizes it end-to-end via multi-turn GRPO using turn-wise rewards and context-independent turn-level advantage estimation. The method is evaluated on multi-round Rock-Paper-Scissors and Limit Texas Hold'em, where the trained memory policy yields top Elo ratings (1590 on RPS, 1762 on LHE) and outperforms baseline memory methods as well as proprietary models including DeepSeek-V3.2.
Significance. If the empirical results prove robust, the work would establish a concrete RL recipe for learning memory-update policies that align with downstream objectives over multi-step horizons, moving beyond hand-designed prompts. The explicit handling of credit assignment via turn-wise signals is a clear technical contribution for sequential agent settings.
major comments (2)
- [Abstract and §4 (Experiments)] Abstract and §4 (Experiments): no description is given of baseline implementations, the exact base LLM used for the frozen player, statistical tests, number of independent runs, or variance in the reported Elo scores. Without these, the central claim that MemoPilot ranks first on both games cannot be verified or compared.
- [§3 (Method)] §3 (Method): the context-independent advantage estimation is presented as enabling stable multi-turn training, yet no analysis or ablation shows whether this estimator (or the turn-wise reward) exploits properties specific to the dense, fully-observable, zero-sum reward structures of RPS and LHE. If the gains are tied to these testbeds, the headline improvements would not transfer.
minor comments (1)
- [Abstract] Abstract: the phrase 'substantially improves' is used without stating the absolute or relative Elo margin over the strongest baseline.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which helps strengthen the clarity and generality of our claims. We address each major comment point by point below.
read point-by-point responses
-
Referee: [Abstract and §4 (Experiments)] Abstract and §4 (Experiments): no description is given of baseline implementations, the exact base LLM used for the frozen player, statistical tests, number of independent runs, or variance in the reported Elo scores. Without these, the central claim that MemoPilot ranks first on both games cannot be verified or compared.
Authors: We agree these details are necessary for reproducibility and verification of the ranking claims. The full manuscript specifies the base LLM in §4.1 and describes baselines in §4.2, but we will expand both the abstract and §4 to explicitly detail baseline implementations, the exact base LLM (including version), statistical tests used, number of independent runs, and variance/confidence intervals for all Elo scores. This revision will make the top-ranking results fully verifiable. revision: yes
-
Referee: [§3 (Method)] §3 (Method): the context-independent advantage estimation is presented as enabling stable multi-turn training, yet no analysis or ablation shows whether this estimator (or the turn-wise reward) exploits properties specific to the dense, fully-observable, zero-sum reward structures of RPS and LHE. If the gains are tied to these testbeds, the headline improvements would not transfer.
Authors: The context-independent advantage estimation is formulated to support general multi-turn credit assignment without requiring full trajectory context, and the turn-wise rewards align with sequential objectives. While RPS and LHE feature dense zero-sum rewards, the method itself does not rely on those properties. We will add a targeted discussion and ablation in the revised §3 and §5 to analyze the estimator's sensitivity to reward density and observability, and explicitly note limitations for transfer to sparser or non-zero-sum settings. revision: yes
Circularity Check
No circularity; empirical training and evaluation on target tasks
full rationale
The paper describes an end-to-end trained memory-update policy via multi-turn GRPO on the exact RPS and LHE environments used for evaluation, with explicit turn-wise rewards and advantage estimation. No equations, uniqueness theorems, or self-citations are invoked to derive performance; the reported Elo gains are direct outcomes of the training procedure on those testbeds rather than any reduction of a claimed prediction to its fitted inputs or prior self-referential results. The derivation chain is therefore self-contained empirical work with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Advances in Neural Information Processing Systems , volume=
Language Models are Few-Shot Learners , author=. Advances in Neural Information Processing Systems , volume=
-
[2]
Advances in Neural Information Processing Systems , volume=
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models , author=. Advances in Neural Information Processing Systems , volume=
-
[3]
Proceedings of the 36th Annual ACM Symposium on User Interface Software and Technology , pages=
Generative Agents: Interactive Simulacra of Human Behavior , author=. Proceedings of the 36th Annual ACM Symposium on User Interface Software and Technology , pages=
-
[4]
Forty-second International Conference on Machine Learning , year=
Agent Workflow Memory , author=. Forty-second International Conference on Machine Learning , year=
-
[5]
2025 , eprint=
A-MEM: Agentic Memory for LLM Agents , author=. 2025 , eprint=
2025
-
[6]
2025 , eprint=
MEM1: Learning to Synergize Memory and Reasoning for Efficient Long-Horizon Agents , author=. 2025 , eprint=
2025
-
[7]
arXiv preprint arXiv:2509.24704 , year=
MemGen: Weaving Generative Latent Memory for Self-Evolving Agents , author=. arXiv preprint arXiv:2509.24704 , year=
-
[8]
The Fourteenth International Conference on Learning Representations , year=
ReasoningBank: Scaling Agent Self-Evolving with Reasoning Memory , author=. The Fourteenth International Conference on Learning Representations , year=
-
[9]
Advances in Neural Information Processing Systems , volume=
Streambench: Towards benchmarking continuous improvement of language agents , author=. Advances in Neural Information Processing Systems , volume=
-
[10]
2025 , eprint=
SkillWeaver: Web Agents can Self-Improve by Discovering and Honing Skills , author=. 2025 , eprint=
2025
-
[11]
2026 , eprint=
PolySkill: Learning Generalizable Skills Through Polymorphic Abstraction , author=. 2026 , eprint=
2026
-
[12]
2026 , url=
Bo Liu and Simon Yu and Zichen Liu and Leon Guertler and Penghui Qi and Daniel Balcells and Mickel Liu and Cheston Tan and Weiyan Shi and Min Lin and Wee Sun Lee and Natasha Jaques , booktitle=. 2026 , url=
2026
-
[13]
arXiv preprint arXiv:2406.04271 , year=
Buffer of Thoughts: Thought-Augmented Reasoning with Large Language Models , author=. arXiv preprint arXiv:2406.04271 , year=
-
[14]
Thirty-Eighth
Andrew Zhao and Daniel Huang and Quentin Xu and Matthieu Lin and Yong-Jin Liu and Gao Huang , title =. Thirty-Eighth. 2024 , pages =
2024
-
[15]
Advances in Neural Information Processing Systems , volume=
Reflexion: Language Agents with Verbal Reinforcement Learning , author=. Advances in Neural Information Processing Systems , volume=
-
[16]
arXiv preprint arXiv:2504.07952 , year=
Dynamic Cheatsheet: Test-Time Learning with Adaptive Memory , author=. arXiv preprint arXiv:2504.07952 , year=
-
[17]
2025 , eprint=
EvaLearn: Quantifying the Learning Capability and Efficiency of LLMs via Sequential Problem Solving , author=. 2025 , eprint=
2025
-
[18]
arXiv preprint arXiv:2505.11942 , year=
LifelongAgentBench: Evaluating LLM Agents as Lifelong Learners , author=. arXiv preprint arXiv:2505.11942 , year=
-
[19]
arXiv preprint arXiv:2506.14448 , year=
How Far Can LLMs Improve from Experience? Measuring Test-Time Learning Ability in LLMs with Human Comparison , author=. arXiv preprint arXiv:2506.14448 , year=
-
[20]
arXiv preprint arXiv:2510.04618 , year=
Agentic Context Engineering: Evolving Contexts for Self-Improving Language Models , author=. arXiv preprint arXiv:2510.04618 , year=
-
[21]
arXiv preprint arXiv:2508.16153 , year=
AgentFly: Fine-tuning LLM Agents without Fine-tuning LLMs , author=. arXiv preprint arXiv:2508.16153 , year=
-
[22]
2024 , eprint=
Large Language Models Cannot Self-Correct Reasoning Yet , author=. 2024 , eprint=
2024
-
[23]
Advances in Neural Information Processing Systems , volume=
Self-Refine: Iterative Refinement with Self-Feedback , author=. Advances in Neural Information Processing Systems , volume=
-
[24]
Deng, Mingkai and Wang, Jianyu and Hsieh, Cheng-Ping and Wang, Yihan and Guo, Han and Shu, Tianmin and Song, Meng and Xing, Eric P and Hu, Zhiting , booktitle=
-
[25]
arXiv preprint arXiv:2309.03409 , year=
Large Language Models as Optimizers , author=. arXiv preprint arXiv:2309.03409 , year=
-
[26]
arXiv preprint arXiv:2401.08189 , year=
PRewrite: Prompt Rewriting with Reinforcement Learning , author=. arXiv preprint arXiv:2401.08189 , year=
-
[27]
arXiv preprint arXiv:2511.01016 , year=
Prompt-R1: Collaborative Automatic Prompting Framework via End-to-end Reinforcement Learning , author=. arXiv preprint arXiv:2511.01016 , year=
-
[28]
arXiv preprint arXiv:2510.02263 , year=
RLAD: Training LLMs to Discover Abstractions for Solving Reasoning Problems , author=. arXiv preprint arXiv:2510.02263 , year=
-
[29]
arXiv preprint arXiv:2508.19282 , year=
CORE-RAG: Lossless Compression for Retrieval-Augmented LLMs via Reinforcement Learning , author=. arXiv preprint arXiv:2508.19282 , year=
-
[30]
arXiv preprint arXiv:2510.02453 , year=
How to Train Your Advisor: Steering Black-Box LLMs with Advisor Models , author=. arXiv preprint arXiv:2510.02453 , year=
-
[31]
Shao, Zhihong and Wang, Peiyi and Zhu, Qihao and Xu, Runxin and Song, Junxiao and Zhang, Mingchuan and Li, YK and Wu, Y and Guo, Daya , journal=. Deep
-
[32]
2025 , eprint=
RAGEN: Understanding Self-Evolution in LLM Agents via Multi-Turn Reinforcement Learning , author=. 2025 , eprint=
2025
-
[33]
2025 , eprint=
Teaching Language Models to Critique via Reinforcement Learning , author=. 2025 , eprint=
2025
-
[34]
2025 , eprint=
ReMA: Learning to Meta-think for LLMs with Multi-Agent Reinforcement Learning , author=. 2025 , eprint=
2025
-
[35]
arXiv preprint arXiv:2504.15257 , year=
Flowreasoner: Reinforcing query-level meta-agents , author=. arXiv preprint arXiv:2504.15257 , year=
-
[36]
2025 , eprint=
Metacognitive Reuse: Turning Recurring LLM Reasoning Into Concise Behaviors , author=. 2025 , eprint=
2025
-
[37]
arXiv preprint arXiv:2309.04658 , year=
Exploring Large Language Models for Communication Games: An Empirical Study on Werewolf , author=. arXiv preprint arXiv:2309.04658 , year=
-
[38]
2025 , eprint=
Cogito, Ergo Ludo: An Agent that Learns to Play by Reasoning and Planning , author=. 2025 , eprint=
2025
-
[39]
2025 , eprint=
TextArena , author=. 2025 , eprint=
2025
-
[40]
arXiv preprint arXiv:2409.12917 , year=
Training Language Models to Self-Correct via Reinforcement Learning , author=. arXiv preprint arXiv:2409.12917 , year=
-
[41]
arXiv preprint arXiv:2408.03314 , year=
Scaling LLM Test-Time Compute Optimally Can Be More Effective than Scaling Model Parameters , author=. arXiv preprint arXiv:2408.03314 , year=
-
[42]
MemAgent: Reshaping Long-Context
Hongli Yu and Tinghong Chen and Jiangtao Feng and Jiangjie Chen and Weinan Dai and Qiying Yu and Ya-Qin Zhang and Wei-Ying Ma and Jingjing Liu and Mingxuan Wang and Hao Zhou , booktitle=. MemAgent: Reshaping Long-Context. 2026 , url=
2026
-
[43]
2025 , eprint=
Understanding R1-Zero-Like Training: A Critical Perspective , author=. 2025 , eprint=
2025
-
[44]
arXiv preprint arXiv:1910.04376 , year=
Rlcard: A toolkit for reinforcement learning in card games , author=. arXiv preprint arXiv:1910.04376 , year=
arXiv 1910
-
[45]
arXiv preprint arXiv:2305.10250 , year=
MemoryBank: Enhancing Large Language Models with Long-Term Memory , author=. arXiv preprint arXiv:2305.10250 , year=
-
[46]
Lianmin Zheng and Wei-Lin Chiang and Ying Sheng and Tianle Li and Sijie Zeng and Hongxu Chen and Hao Zhang and Zhihao Jiang and Diana Li and Danqi Chen and Ion Stoica , year=. Judging. 2306.05685 , archivePrefix=
-
[47]
2025 , eprint=
DeepSeek-V3 Technical Report , author=. 2025 , eprint=
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.