GraspGen-X: Cross-Embodiment 6-DOF Diffusion-based Grasping
Pith reviewed 2026-06-28 17:24 UTC · model grok-4.3
The pith
Conditioning a diffusion-based 6-DOF grasping model on a swept-volume gripper representation enables zero-shot generalization to novel real-world grippers and objects.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
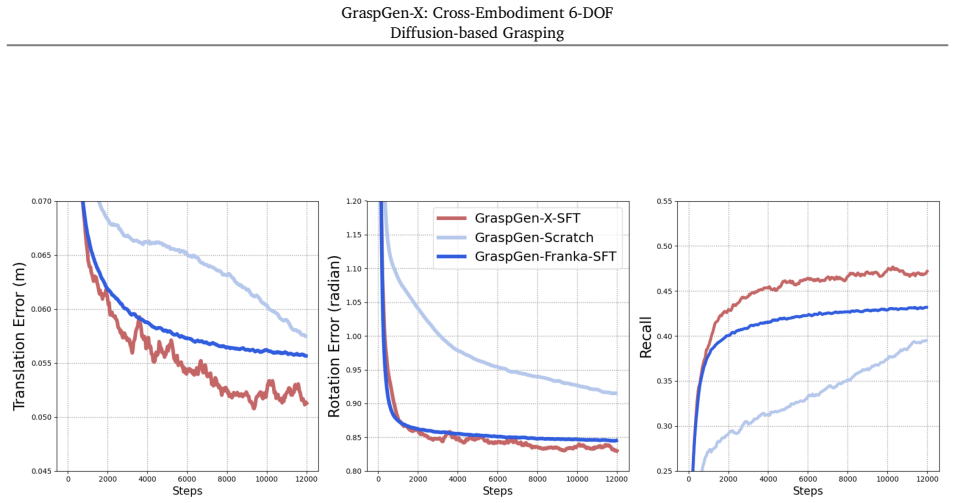
By extending diffusion-based 6-DOF grasp generators to accept an additional swept-volume encoding of the gripper and training on a large procedural-gripper dataset, the resulting model achieves the best zero-shot performance on novel real grippers and objects among compared methods, also serving as an effective starting point for fine-tuning.
What carries the argument
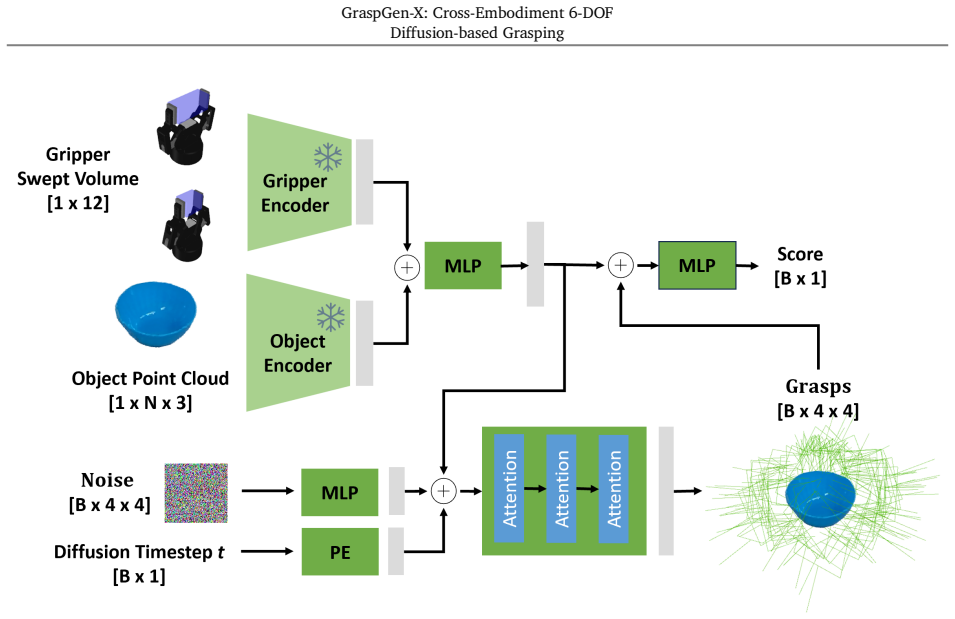
Swept-volume heuristic that encodes gripper morphology and the physical volume swept during closure, used as conditioning input to the diffusion model.
If this is right
- The model outperforms prior 6-DOF grasp generators on unseen grippers and objects in simulation without retraining.
- Fine-tuning the pre-trained model on a small amount of data for a new gripper yields faster adaptation than training from scratch.
- The same architecture demonstrates successful zero-shot transfer when deployed on physical robots with previously unseen grippers.
Where Pith is reading between the lines
- The approach could be tested on manipulation skills beyond grasping, such as placement or tool use, by replacing the grasp label with an appropriate task label.
- If the swept-volume representation proves robust, it may reduce the data-collection burden for each new end-effector in industrial or home robot deployments.
- Extending the conditioning to include joint limits or compliance parameters could further broaden the set of grippers handled without retraining.
Load-bearing premise
The swept-volume heuristic captures enough of the differences in gripper shape and closing motion that a single model conditioned on it can generalize to unseen real grippers.
What would settle it
A controlled test in which a novel real gripper whose swept volume is supplied to the model still produces grasp success rates no higher than an unconditioned baseline on the same objects.
Figures






read the original abstract
We study cross-embodiment 6-DOF robot grasping. Unlike prior works, we require the model not only to generalize to novel objects / scenes but also to novel gripper morphologies and physical grasping processes. Our method extends diffusion model based generative 6-DOF grasping models to condition on the additional gripper's representation. We propose a swept-volume heuristic for encoding the gripper. We train our cross-embodiment model with procedural grippers and a large-scale dataset of 2 Billion grasps. In simulation experiments, our model has the best zero-shot generalization to novel real-world grippers and objects over baseline methods. Our model also serves as a good initialization for fine-tuning to adapt to novel grippers. In ablations, we demonstrate the efficiency of our sweep-volume gripper representation and our procedural gripper training dataset. Last, we show zero-shot generalization to real-world novel grippers for 6-DOF grasping, surpassing baselines in cross-embodiment generalization.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces GraspGen-X, a diffusion-based model for 6-DOF grasping that extends prior generative approaches by conditioning on a swept-volume gripper representation to enable cross-embodiment generalization to novel grippers and objects. Trained on 2 billion grasps generated via procedural grippers, the method claims best-in-class zero-shot performance on novel real-world grippers and objects in simulation, utility as a fine-tuning initialization, and successful zero-shot transfer to real-world novel grippers, outperforming baselines in cross-embodiment settings. Ablations are said to validate the swept-volume representation and procedural dataset.
Significance. If the zero-shot cross-embodiment claims hold with rigorous quantitative support, the work would advance robotic grasping by showing that a purely geometric conditioning signal can bridge embodiment gaps at scale, reducing reliance on gripper-specific data collection. The 2B-grasp dataset size and reported real-world validation would be notable strengths for reproducibility and practical impact in the field.
major comments (1)
- [Abstract, method description] Abstract and method description: The central claim of zero-shot generalization to novel real-world grippers rests on the assertion that the swept-volume heuristic encodes gripper morphology and physical grasping process differences. As described, this is a geometric construct (collision and reachability volumes from gripper motion) that does not explicitly incorporate material properties, friction coefficients, compliance, or contact dynamics distinguishing real grippers from the procedural simulation set. This assumption is load-bearing for the cross-embodiment transfer result and requires either additional validation experiments or explicit discussion of its limitations to support the generalization claims.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the major comment below and outline revisions to improve clarity on the scope of our claims.
read point-by-point responses
-
Referee: [Abstract, method description] Abstract and method description: The central claim of zero-shot generalization to novel real-world grippers rests on the assertion that the swept-volume heuristic encodes gripper morphology and physical grasping process differences. As described, this is a geometric construct (collision and reachability volumes from gripper motion) that does not explicitly incorporate material properties, friction coefficients, compliance, or contact dynamics distinguishing real grippers from the procedural simulation set. This assumption is load-bearing for the cross-embodiment transfer result and requires either additional validation experiments or explicit discussion of its limitations to support the generalization claims.
Authors: We agree that the swept-volume representation is a purely geometric construct based on collision and reachability volumes and does not explicitly model material properties, friction coefficients, compliance, or contact dynamics. The method's cross-embodiment results rely on the empirical effectiveness of this encoding when trained at scale on procedural grippers, as validated through zero-shot simulation and real-world experiments on novel grippers. To address the concern, we will revise the method section and add an explicit limitations paragraph discussing these modeling assumptions and noting that generalization claims are supported by empirical evidence rather than a complete physical simulation of gripper-object interactions. revision: yes
Circularity Check
No circularity: empirical claims rest on held-out evaluation and external baselines
full rationale
The paper presents an empirical ML method: a diffusion model conditioned on a fixed swept-volume gripper heuristic, trained on 2B procedurally generated grasps, then evaluated zero-shot on novel real grippers and objects. No equations, predictions, or uniqueness claims reduce to author-fitted quantities by construction. The central results are measured success rates on held-out simulation and real-world test sets against baselines, which are independent of any self-referential definition or self-citation chain. The swept-volume heuristic is presented as an input representation, not derived from the model's outputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Swept-volume representation of a gripper is sufficient to condition the diffusion model for cross-embodiment generalization.
Reference graph
Works this paper leans on
-
[1]
Ac- cessed: 2024-03-07
Isaac sim - robotics simulation and synthetic data nvidia developer.https://www.einscan.com/. Ac- cessed: 2024-03-07. 7
2024
-
[2]
Geometry matching for multi-embodiment grasping
Maria Attarian, Muhammad Adil Asif, Jingzhou Liu, Ruthrash Hari, Animesh Garg, Igor Gilitschenski, and Jonathan Tompson. Geometry matching for multi-embodiment grasping. InProceedings of the 7th Conference on Robot Learning (CoRL 2023), 2023. 4
2023
-
[3]
Graspldm: Generative 6-dof grasp synthesis using latent diffusion models
Kuldeep Barad, Andrej Orsula, ANntoine Richard, Jan Dentler, Miguel Olivares-Mendez, and Carol Mar- tinez. Graspldm: Generative 6-dof grasp synthesis using latent diffusion models. InIEEE Access, 2024. 3
2024
-
[4]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
KevinBlack, NoahBrown, DannyDriess, AdnanEsmail, MichaelEqui, ChelseaFinn, NiccolòFusai, Lachy Groom, Karol Hausman, Brian Ichter, Szymon Jakubczak, Tim Jones, Liyiming Ke, Sergey Levine, Adrian Li-Bell,MohithMothukuri,SurajNair,KarlPertsch,LucyXiaoyangShi,JamesTanner,QuanVuong,Anna Walling, Haohuan Wang, and Ury Zhilinsky.𝜋0: A vision-language-action flo...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
Konstantinos Bousmalis, Giulia Vezzani, Dushyant Rao, Coline Devin, Alex X. Lee, Maria Bauza, Todor Davchev, Yuxiang Zhou, Agrim Gupta, Akhil Raju, Antoine Laurens, Claudio Fantacci, Valentin Dalibard, Martina Zambelli, Murilo Martins, Rugile Pevceviciute, Michiel Blokzijl, Misha Denil, Nathan Batche- lor, Thomas Lampe, Emilio Parisotto, Konrad Żołna, Sco...
2023
-
[6]
Le, Philipp Jahr, Qiao Sun, Julen Urain, Dorothea Koert, and Jan Peters
Joao Carvalho, An T. Le, Philipp Jahr, Qiao Sun, Julen Urain, Dorothea Koert, and Jan Peters. Grasp diffusionnetwork: Learninggraspgeneratorsfrompartialpointcloudswithdiffusionmodelsinso(3)xr3,
-
[7]
Multigrippergrasp: A datasetforroboticgraspingfromparalleljawgripperstodexteroushands
Luis Felipe Casas, Ninad Khargonkar, Balakrishnan Prabhakaran, and Yu Xiang. Multigrippergrasp: A datasetforroboticgraspingfromparalleljawgripperstodexteroushands. InProceedingsoftheIEEE/RSJ International Conference on Intelligent Robots and Systems (IROS 2024), pages 2978–2984, 2024. 4, 21
2024
-
[8]
Dexycb: A benchmark for capturing hand grasping of objects
Yu-WeiChao, WeiYang, YuXiang, PavloMolchanov, AnkurHanda, JonathanTremblay, YashrajSNarang, Karl Van Wyk, Umar Iqbal, Stan Birchfield, et al. Dexycb: A benchmark for capturing hand grasping of objects. InCVPR, 2021. 21
2021
-
[9]
Spacetools: Tool-augmented spatial reasoning via dou- ble interactive rl, 2025
Siyi Chen, Mikaela Angelina Uy, Chan Hee Song, Faisal Ladhak, Adithyavairavan Murali, Qing Qu, Stan Birchfield, Valts Blukis, and Jonathan Tremblay. Spacetools: Tool-augmented spatial reasoning via dou- ble interactive rl, 2025. 2
2025
-
[10]
Hardware conditioned policies for multi-robot transfer learning
Tao Chen, Adithyavairavan Murali, and Abhinav Gupta. Hardware conditioned policies for multi-robot transfer learning. InAdvances in Neural Information Processing Systems 31 (NeurIPS 2018), pages 9355– 9366, 2018. 3
2018
-
[11]
Local policies enable zero-shot long-horizon manipulation
Murtaza Dalal, Min Liu, Chen Chen, Deepak Pathak, Jian Zhang, and Ruslan Salakhutdinov. Local policies enable zero-shot long-horizon manipulation. InICRA, 2025. 2, 3
2025
-
[12]
Graspmolmo: Generalizable task-oriented grasping via large-scale synthetic data generation
Abhay Deshpande, Yuquan Deng, Arijit Ray, Jordi Salvador, Winson Han, Jiafei Duan, Kuo-Hao Zeng, Yuke Zhu, Ranjay Krishna, and Rose Hendrix. Graspmolmo: Generalizable task-oriented grasping via large-scale synthetic data generation. InCoRL, 2025. 2, 3 14 GraspGen-X: Cross-Embodiment 6-DOF Diffusion-based Grasping
2025
-
[13]
Learningmodularneural network policies for multi-task and multi-robot transfer
ColineDevin, AbhinavGupta, TrevorDarrell, PieterAbbeel, andSergeyLevine. Learningmodularneural network policies for multi-task and multi-robot transfer. InProceedings of the IEEE International Confer- ence on Robotics and Automation (ICRA 2017), pages 2169–2176, 2017. 3
2017
-
[14]
Scalingcross-embodiedlearning: One policy for manipulation, navigation, locomotion and aviation
RiaDoshi,HomerWalke,OierMees,SudeepDasari,andSergeyLevine. Scalingcross-embodiedlearning: One policy for manipulation, navigation, locomotion and aviation. InProceedings of the Conference on Robot Learning (CoRL 2024), 2024. 2, 3
2024
-
[15]
ACRONYM: A large-scale grasp dataset based on simulation
Clemens Eppner, Arsalan Mousavian, and Dieter Fox. ACRONYM: A large-scale grasp dataset based on simulation. InUnder Review at ICRA 2021, 2020. 2, 6, 20, 21
2021
-
[16]
Anygrasp: Robust and efficient grasp perception in spatial and temporal domains
Hao-Shu Fang, Chenxi Wang, Hongjie Fang, Minghao Gou, Jirong Liu, Hengxu Yan, Wenhai Liu, Yichen Xie, and Cewu Lu. Anygrasp: Robust and efficient grasp perception in spatial and temporal domains. Transactions on Robotics, 2023. 2, 3, 10, 11
2023
-
[17]
Xin Fei, Zhenyu Wang, Jiayu Luo, Chongkai Gao, Zhehao Cai, and Lin Shao. T(r,o) grasp: Efficient graph diffusion of robot-object spatial transformation for cross-embodiment dexterous grasping. arXiv preprint arXiv:2510.12724, 2025. 4
-
[18]
Diffusion for multi- embodiment grasping
Roman Freiberg, Alexander Qualmann, Ngo Anh Vien, and Gerhard Neumann. Diffusion for multi- embodiment grasping. InRobotics and Automation Letters, 2024. 3, 9, 23
2024
-
[19]
Diffusion for multi- embodiment grasping.IEEE Robotics and Automation Letters, PP(99):1–8, 2025
Roman Freiberg, Alexander Qualmann, Ngo Anh Vien, and Gerhard Neumann. Diffusion for multi- embodiment grasping.IEEE Robotics and Automation Letters, PP(99):1–8, 2025. 4
2025
-
[20]
CaP-X: A Framework for Benchmarking and Improving Coding Agents for Robot Manipulation
MaxFu, JustinYu, KarimEl-Refai, EthanKou, HaoruXue, HuangHuang, WenliXiao, GuanzhiWang, Fei- FeiLi,GuanyaShi,JiajunWu,ShankarSastry,YukeZhu,KenGoldberg,andJimFan. CaP-X:Aframework forbenchmarkingandimprovingcodingagentsforrobotmanipulation.arXivpreprintarXiv:2603.22435,
work page internal anchor Pith review arXiv
-
[21]
Robot learning in homes: Improvinggeneralizationandreducingdatasetbias
Abhinav Gupta, Adithyavairavan Murali, Dhiraj Gandhi, and Lerrel Pinto. Robot learning in homes: Improvinggeneralizationandreducingdatasetbias. InAdvancesinNeuralInformationProcessingSystems 31 (NeurIPS 2018), 2018. 3
2018
-
[22]
Robot learning in homes: Improving generalization and reducing dataset bias.NeurIPS, 2018
Abhinav Gupta, Adithyavairavan Murali, Dhiraj Gandhi, and Lerrel Pinto. Robot learning in homes: Improving generalization and reducing dataset bias.NeurIPS, 2018. 11
2018
-
[23]
Honnotate: A method for 3d annotation of hand and object poses
Shreyas Hampali, Mahdi Rad, Markus Oberweger, and Vincent Lepetit. Honnotate: A method for 3d annotation of hand and object poses. InCVPR, 2020. 21
2020
-
[24]
Dexpilot: Vision-based teleoperation of dexterous robotic hand-arm system
Ankur Handa, Karl Van Wyk, Wei Yang, Jacky Liang, Yu-Wei Chao, Qian Wan, Stan Birchfield, Nathan Ratliff, and Dieter Fox. Dexpilot: Vision-based teleoperation of dexterous robotic hand-arm system. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA 2020), pages 9164– 9170, 2020. 3
2020
-
[25]
Hu, Kun Huang, Oleh Rybkin, and Dinesh Jayaraman
Edward S. Hu, Kun Huang, Oleh Rybkin, and Dinesh Jayaraman. Know thyself: Transferable visual control policies through robot-awareness. InProceedings of the International Conference on Learning Representations (ICLR 2022), 2022. 3
2022
-
[26]
One policy to control them all: Shared modular policies for agent-agnostic control
Wenlong Huang, Igor Mordatch, and Deepak Pathak. One policy to control them all: Shared modular policies for agent-agnostic control. InProceedings of the International Conference on Machine Learning (ICML 2020), pages 4455–4464, 2020. 3
2020
-
[27]
Rekep: Spatio-temporal reason- ing of relational keypoint constraints for robotic manipulation
Wenlong Huang, Chen Wang, Yunzhu Li, Ruohan Zhang, and Li Fei-Fei. Rekep: Spatio-temporal reason- ing of relational keypoint constraints for robotic manipulation. InCoRL, 2024. 2, 3, 8 15 GraspGen-X: Cross-Embodiment 6-DOF Diffusion-based Grasping
2024
-
[28]
Procedural generation of articulated simulation-ready assets, 2025
Abhishek Joshi, Beining Han, Jack Nugent, Max Gonzalez Saez-Diez, Yiming Zuo, Jonathan Liu, Hongyu Wen, Stamatis Alexandropoulos, Karhan Kayan, Anna Calveri, Tao Sun, Gaowen Liu, Yi Shao, Alexander Raistrick, and Jia Deng. Procedural generation of articulated simulation-ready assets, 2025. 5, 20
2025
-
[29]
Learning hand-eye coordination for robotic grasping with deep learning and large-scale data collection, 2016
Sergey Levine, Peter Pastor, Alex Krizhevsky, and Deirdre Quillen. Learning hand-eye coordination for robotic grasping with deep learning and large-scale data collection, 2016. 3
2016
-
[30]
Hongyu Li, Lingfeng Sun, Yafei Hu, Duy Ta, Jennifer Barry, George Konidaris, and Jiahui Fu. Novaflow: Zero-shot manipulation via actionable flow from generated videos.arXiv preprint arXiv:2510.08568,
-
[31]
Jinming Li, Yichen Zhu, Zhibin Tang, Junjie Wen, Minjie Zhu, Xiaoyu Liu, Chengmeng Li, Ran Cheng, Yaxin Peng, Yan Peng, and Feifei Feng. Coa-vla: Improving vision-language-action models via visual- textual chain-of-affordance. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV 2025), 2025. arXiv preprint arXiv:2412.20451. 2, 3
-
[32]
Gendexgrasp: Generalizable dexterous grasping
PuhaoLi,TengyuLiu,YuyangLi,YiranGeng,YixinZhu,YaodongYang,andSiyuanHuang. Gendexgrasp: Generalizable dexterous grasping. InProceedings of the IEEE International Conference on Robotics and Automation (ICRA 2023), 2023. 4
2023
-
[33]
Pointnetgpd: Detecting grasp configurations from point sets
HongzhuoLiang,XiaojianMa,ShuangLi,MichaelGorner,SongTang,BinFang,FuchunSun,andJianwei Zhang. Pointnetgpd: Detecting grasp configurations from point sets. InICRA, 2019. 3
2019
-
[34]
Equigraspflow: Se(3)- equivariant 6-dof grasp pose generative flows
Byeongdo Lim, Jongmin Kim, Jihwan Kim, Yonghyeon Lee, and Frank C Park. Equigraspflow: Se(3)- equivariant 6-dof grasp pose generative flows. InCoRL, 2024. 3
2024
-
[35]
Deepdifferentiablegraspplanner for high-dof grippers.arXiv preprint arXiv:2002.01530, 2020
MinLiu,ZherongPan,KaiXu,KanishkaGanguly,andDineshManocha. Deepdifferentiablegraspplanner for high-dof grippers.arXiv preprint arXiv:2002.01530, 2020. 21
-
[36]
Peiqi Liu, Yaswanth Orru, Chris Paxton, Nur Muhammad Mahi Shafiullah, and Lerrel Pinto. Ok-robot: What really matters in integrating open-knowledge models for robotics.preprint arXiv:2401.12202,
-
[37]
Li, Preston Culbertson, Krishnan Srinivasan, Aaron Ames, Mac Schwager, and Jeannette Bohg
Tyler Ga Wei Lum, Albert H. Li, Preston Culbertson, Krishnan Srinivasan, Aaron Ames, Mac Schwager, and Jeannette Bohg. Get a grip: Multi-finger grasp evaluation at scale enables robust sim-to-real transfer. InCoRL, 2024. 3
2024
-
[38]
Unified particle physics for real-time applications.ACM Transactions on Graphics (TOG), 33(4):1–12, 2014
Miles Macklin, Matthias Müller, Nuttapong Chentanez, and Tae-Yong Kim. Unified particle physics for real-time applications.ACM Transactions on Graphics (TOG), 33(4):1–12, 2014. 21
2014
-
[39]
Jeffrey Mahler, Jacky Liang, Sherdil Niyaz, Michael Laskey, Richard Doan, Xinyu Liu, Juan Aparicio Ojea, and Ken Goldberg. Dex-net 2.0: Deep learning to plan robust grasps with synthetic point clouds and analytic grasp metrics.arXiv preprint arXiv:1703.09312, 2017. 2, 3
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[40]
nvblox: Gpu-acceleratedincrementalsigneddistancefieldmapping
Alexander Millane, Helen Oleynikova, Emilie Wirbel, Remo Steiner, Vikram Ramasamy, David Tingdahl, andRolandSiegwart. nvblox: Gpu-acceleratedincrementalsigneddistancefieldmapping. InProceedings of the IEEE International Conference on Robotics and Automation, pages 2698–2705, 2024. 2
2024
-
[41]
nvblox: Gpu-accelerated incremental signed distance field mapping, 2024
Alexander Millane, Helen Oleynikova, Emilie Wirbel, Remo Steiner, Vikram Ramasamy, David Tingdahl, and Roland Siegwart. nvblox: Gpu-accelerated incremental signed distance field mapping, 2024. 23
2024
-
[42]
Egad! an evolved grasping analysis dataset for diversity and reproducibility in robotic manipulation.IEEE Robotics and Automation Letters, 5(3):4368– 4375, 2020
Douglas Morrison, Peter Corke, and Jürgen Leitner. Egad! an evolved grasping analysis dataset for diversity and reproducibility in robotic manipulation.IEEE Robotics and Automation Letters, 5(3):4368– 4375, 2020. 21 16 GraspGen-X: Cross-Embodiment 6-DOF Diffusion-based Grasping
2020
-
[43]
6-dof graspnet: Variational grasp generation for object manipulation
Arsalan Mousavian, Clemens Eppner, and Dieter Fox. 6-dof graspnet: Variational grasp generation for object manipulation. InICCV, 2019. 1, 2, 3
2019
-
[44]
Same object, different grasps: Data and semantic knowledge for task-oriented grasping
Adithyavairavan Murali, Weiyu Liu, Kenneth Marino, Sonia Chernova, and Abhinav Gupta. Same object, different grasps: Data and semantic knowledge for task-oriented grasping. InCoRL, 2020. 2, 8
2020
-
[45]
6-dof grasp- ing for target-driven object manipulation in clutter
Adithyavairavan Murali, Arsalan Mousavian, Clemens Eppner, Chris Paxton, and Dieter Fox. 6-dof grasp- ing for target-driven object manipulation in clutter. InICRA, 2020. 2, 3
2020
-
[46]
Graspgen: A diffusion-based framework for 6-dof grasping with on- generator training,
Adithyavairavan Murali, Balakumar Sundaralingam, Yu-Wei Chao, Jun Yamada, Wentao Yuan, Mark Carlson, Fabio Ramos, Stan Birchfield, Dieter Fox, and Clemens Eppner. Graspgen: A diffusion-based framework for 6-dof grasping with on-generator training.arXiv preprint arXiv:2507.13097, 2025. 1, 2, 3, 4, 5, 6, 7, 8, 10, 11, 21, 22, 23
-
[47]
Deep learning approaches to grasp synthesis: A review.IEEE Transactions on Robotics, 2023
RhysNewbury, MorrisGu, LachlanChumbley, ArsalanMousavian, ClemensEppner, JürgenLeitner, Jean- nette Bohg, Antonio Morales, Tamim Asfour, Danica Kragic, et al. Deep learning approaches to grasp synthesis: A review.IEEE Transactions on Robotics, 2023. 2, 3
2023
-
[48]
Nvidia isaac sim, 2023
NVIDIA. Nvidia isaac sim, 2023. 21
2023
-
[49]
Pointnet++: Deep hierarchical feature learning on point sets in a metric space.Advances in neural information processing systems, 30, 2017
Charles Ruizhongtai Qi, Li Yi, Hao Su, and Leonidas J Guibas. Pointnet++: Deep hierarchical feature learning on point sets in a metric space.Advances in neural information processing systems, 30, 2017. 4, 9, 21
2017
-
[50]
arXiv preprint arXiv:2307.04577 (2023)
Yuzhe Qin, Wei Yang, Binghao Huang, Karl Van Wyk, Hao Su, Xiaolong Wang, Yu-Wei Chao, and Dieter Fox. Anyteleop: A general vision-based dexterous robot arm-hand teleoperation system. arXiv preprint arXiv:2307.04577v1, 2023. 3
-
[51]
Infinite photorealistic worlds using procedural generation
Alexander Raistrick, Lahav Lipson, Zeyu Ma, Lingjie Mei, Mingzhe Wang, Yiming Zuo, Karhan Kayan, Hongyu Wen, Beining Han, Yihan Wang, et al. Infinite photorealistic worlds using procedural generation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 12630– 12641, 2023. 20
2023
-
[52]
Infinite indoors: Photorealistic indoor scenes using procedural generation
AlexanderRaistrick,MeiLingjie,KaanKayanKarhan,YanDavid,ZuoYiming,HanBeining,WenHongyu, Parakh Meenal, Stamatis Alexandropoulos, Lipson Lahav, Ma Zeyu, and Deng Jia. Infinite indoors: Photorealistic indoor scenes using procedural generation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024. 20
2024
-
[53]
SAM 2: Segment Anything in Images and Videos
Nikhila Ravi, Valentin Gabeur, Yuan-Ting Hu, Ronghang Hu, Chaitanya Ryali, Tengyu Ma, Haitham Khedr, Roman Rädle, Chloe Rolland, Laura Gustafson, Eric Mintun, Junting Pan, Kalyan Vasudev Alwala, NicolasCarion,Chao-YuanWu,RossGirshick,PiotrDollár,andChristophFeichtenhofer. Sam2: Segment anything in images and videos.arXiv preprint arXiv:2408.00714, 2024. 2, 23
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[54]
Sukhatme
Gaurav Salhotra, I-Chun Arthur Liu, and Gaurav S. Sukhatme. Learning robot manipulation from cross- morphology demonstration. InProceedings of the 7th Annual Conference on Robot Learning (CoRL 2023),
2023
-
[55]
Unigrasp: Learning a unified model to grasp with multifingered robotic hands.IEEE Robotics and Automation Letters, 5(2):2286–2293, 2020
LinShao,FabioFerreira,MikaelJorda,VarunNambiar,JianlanLuo,EugenSolowjow,JuanAparicioOjea, Oussama Khatib, and Jeannette Bohg. Unigrasp: Learning a unified model to grasp with multifingered robotic hands.IEEE Robotics and Automation Letters, 5(2):2286–2293, 2020. 4, 9, 21
2020
-
[56]
William Shen, Nishanth Kumar, Sahit Chintalapudi, Jie Wang, Christopher Watson, Edward S. Hu, Jing Cao, Dinesh Jayaraman, Leslie Pack Kaelbling, and Tomás Lozano-Pérez. TiPToP: A modular open- vocabulary planning system for robotic manipulation.arXiv preprint arXiv:2603.09971, 2026. 2 17 GraspGen-X: Cross-Embodiment 6-DOF Diffusion-based Grasping
-
[57]
JunyaoShi, RujiaYang, KaitianChao, SelinaBingqingWan, YifeiShao, JiahuiLei, JianingQian, LongLe, PratikChaudhari,KostasDaniilidis,ChuanWen,andDineshJayaraman. Maestro: Orchestratingrobotics modules with vision-language models for zero-shot generalist robots.arXiv preprint arXiv:2511.00917,
-
[58]
Implicit grasp diffusion: Bridging the gap between dense prediction and sampling-based grasping
Pinhao Song, Pengteng Li, and Renaud Detry. Implicit grasp diffusion: Bridging the gap between dense prediction and sampling-based grasping. InCoRL, 2024. 3
2024
-
[59]
Curobo: Parallelized collision-freerobotmotiongeneration
Balakumar Sundaralingam, Siva Kumar Sastry Hari, Adam Fishman, Caelan Garrett, Karl Van Wyk, Valts Blukis, Alexander Millane, Helen Oleynikova, Ankur Handa, Fabio Ramos, et al. Curobo: Parallelized collision-freerobotmotiongeneration. In2023IEEEInternationalConferenceonRoboticsandAutomation (ICRA), pages 8112–8119. IEEE, 2023. 2
2023
-
[60]
curobo: Parallelized collision-free minimum-jerk robot motion generation
Balakumar Sundaralingam, Siva Kumar Sastry Hari, Adam Fishman, Caelan Garrett, Karl Van Wyk, Valts Blukis, AlexanderMillane, HelenOleynikova, AnkurHanda, FabioRamos, NathanRatliff, andDieterFox. curobo: Parallelized collision-free minimum-jerk robot motion generation. InICRA, 2023. 11, 23
2023
-
[61]
Contact-graspnet: Efficient 6-dof grasp generation in cluttered scenes
Martin Sundermeyer, Arsalan Mousavian, Rudolph Triebel, and Dieter Fox. Contact-graspnet: Efficient 6-dof grasp generation in cluttered scenes. In2021 IEEE International Conference on Robotics and Au- tomation (ICRA), pages 13438–13444. IEEE, 2021. 2, 3, 6
2021
-
[62]
Graspgpt: Leveraging semantic knowledge from a large language model for task-oriented grasping.RAL, 2023
Chao Tang, Dehao Huang, Wenqi Ge, Weiyu Liu, and Hong Zhang. Graspgpt: Leveraging semantic knowledge from a large language model for task-oriented grasping.RAL, 2023. 3
2023
-
[63]
Grasp pose detection in point clouds
Andreas ten Pas, Marcus Gualtieri, Kate Saenko, and Robert Platt. Grasp pose detection in point clouds. The International Journal of Robotics Research, 36(13–14):1455–1473, 2017. 3
2017
-
[64]
Domain ran- domization and generative models for robotic grasping
Josh Tobin, Lukas Biewald, Rocky Duan, Marcin Andrychowicz, Ankur Handa, Vikash Kumar, Bob Mc- Grew, Alex Ray, Jonas Schneider, Peter Welinder, Wojciech Zaremba, and Pieter Abbeel. Domain ran- domization and generative models for robotic grasping. InIROS, 2018. 3
2018
-
[65]
Dylan Turpin, Tao Zhong, Shutong Zhang, Guanglei Zhu, Jingzhou Liu, Ritvik Singh, Eric Heiden, Miles Macklin, Stavros Tsogkas, Sven Dickinson, et al. Fast-grasp’d: Dexterous multi-finger grasp generation through differentiable simulation.arXiv:2306.08132, 2023. 21
-
[66]
Se(3)-diffusionfields: Learning smooth cost functions for joint grasp and motion optimization through diffusion.ICRA, 2023
Julen Urain, Niklas Funk, Jan Peters, and Georgia Chalvatzaki. Se(3)-diffusionfields: Learning smooth cost functions for joint grasp and motion optimization through diffusion.ICRA, 2023. 1, 3
2023
-
[67]
Dexgrasp- net: A large-scale robotic dexterous grasp dataset for general objects based on simulation
Ruicheng Wang, Jialiang Zhang, Jiayi Chen, Yinzhen Xu, Puhao Li, Tengyu Liu, and He Wang. Dexgrasp- net: A large-scale robotic dexterous grasp dataset for general objects based on simulation. InICRA, 2023. 21
2023
-
[68]
Transferring grasping across grippers: Learning–optimization hybrid framework for generalized planar grasp generation.IEEE Transactions on Robotics, 2024
Xianli Wang and Qingsong Xu. Transferring grasping across grippers: Learning–optimization hybrid framework for generalized planar grasp generation.IEEE Transactions on Robotics, 2024. 4
2024
-
[69]
Learning compositional models of robot skills for task and motion planning.The International Journal of Robotics Research, 2020
Zi Wang, Caelan Reed Garrett, Leslie Pack Kaelbling, and Tomas Lozano-Pérez. Learning compositional models of robot skills for task and motion planning.The International Journal of Robotics Research, 2020. 2
2020
-
[70]
Approximate convex decomposition for 3d meshes with collision-aware concavity and tree search.ACM Transactions on Graphics (TOG), 41(4):1–18, 2022
Xinyue Wei, Minghua Liu, Zhan Ling, and Hao Su. Approximate convex decomposition for 3d meshes with collision-aware concavity and tree search.ACM Transactions on Graphics (TOG), 41(4):1–18, 2022. 20 18 GraspGen-X: Cross-Embodiment 6-DOF Diffusion-based Grasping
2022
-
[71]
D(r,o) grasp: A unified representation of robot and object interaction for cross-embodiment dex- terous grasping
Zhenyu Wei, Zhixuan Xu, Jingxiang Guo, Yiwen Hou, Chongkai Gao, Zhehao Cai, Jiayu Luo, and Lin Shao. D(r,o) grasp: A unified representation of robot and object interaction for cross-embodiment dex- terous grasping. InProceedings of the IEEE International Conference on Robotics and Automation (ICRA 2025), 2025. 4
2025
-
[72]
Bowen Wen, Wei Yang, Jan Kautz, and Stan Birchfield. Foundationpose: Unified 6d pose estimation and tracking of novel objects.arXiv preprint arXiv:2312.08344, 2023. 2, 24
-
[73]
Founda- tionstereo: Zero-shot stereo matching
Bowen Wen, Matthew Trepte, Joseph Aribido, Jan Kautz, Orazio Gallo, and Stan Birchfield. Founda- tionstereo: Zero-shot stereo matching. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 5249–5260, 2025. 2, 23
2025
-
[74]
Dexdiffuser: Generating dexterous grasps with diffusion models.Robotics and Automation Letters, 2024
Zehang Weng, Haofei Lu, Danica Kragic, and Jens Lundell. Dexdiffuser: Generating dexterous grasps with diffusion models.Robotics and Automation Letters, 2024. 3
2024
-
[75]
Point transformer v3: Simpler, faster, stronger
Xiaoyang Wu, Li Jiang, Peng-Shuai Wang, Zhijian Liu, Xihui Liu, Yu Qiao, Wanli Ouyang, Tong He, and Hengshuang Zhao. Point transformer v3: Simpler, faster, stronger. InCVPR, 2024. 4
2024
-
[76]
Learning generalizable dexterous manipulation from human grasp affordance
Yueh-Hua Wu, Jiashun Wang, and Xiaolong Wang. Learning generalizable dexterous manipulation from human grasp affordance. InCoRL, 2023. 3
2023
-
[77]
Open x-embodiment: Robotic learning datasets and rt-x models
Open X-Team. Open x-embodiment: Robotic learning datasets and rt-x models. InProceedings of the IEEE International Conference on Robotics and Automation (ICRA 2024), pages 6892–6903, 2024. 2, 3
2024
-
[78]
Rethinking 6-dof grasp detection: A flexible framework for high-quality grasping.Pattern Recognition, 2025
Pengwei Xie, Siang Chen, Wei Tang, Dingchang Hu, Wenming Yang, and Guijin Wang. Rethinking 6-dof grasp detection: A flexible framework for high-quality grasping.Pattern Recognition, 2025. 3
2025
-
[79]
Adagrasp: Learning an adaptive gripper- aware grasping policy
Zhenjia Xu, Beichun Qi, Shubham Agrawal, and Shuran Song. Adagrasp: Learning an adaptive gripper- aware grasping policy. In2021 IEEE International Conference on Robotics and Automation (ICRA), pages 4620–4626. IEEE, 2021. 4, 9, 23
2021
-
[80]
Grasp-mpc: Closed-loopvisualgraspingviavalue-guidedmodelpredictivecontrol
Jun Yamada, Adithyavairavan Murali, Ajay Mandlekar, Clemens Eppner, Ingmar Posner, and Balakumar Sundaralingam. Grasp-mpc: Closed-loopvisualgraspingviavalue-guidedmodelpredictivecontrol. arXiv preprint arXiv:2509.06201v1, 2025. 8
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.