Probing Memorization of Tabular In-Context Learning
Pith reviewed 2026-07-01 06:35 UTC · model grok-4.3
The pith
Tabular in-context models show moderate parametric memorization under single-task fine-tuning with repeated samples, but signals vanish in realistic training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
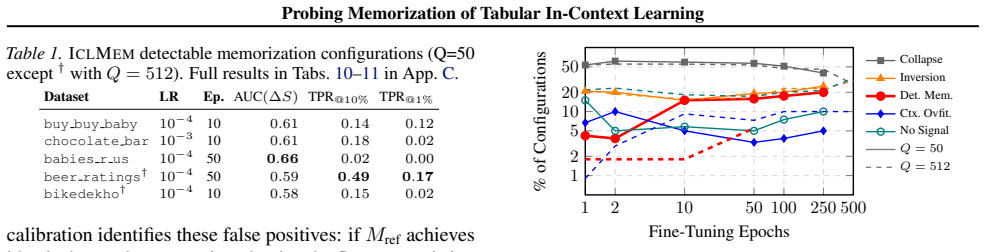
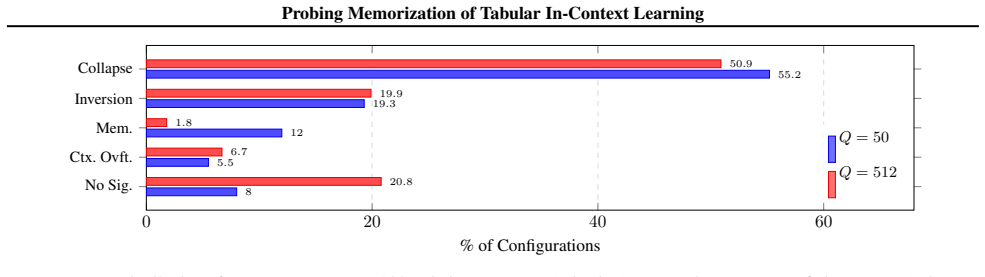
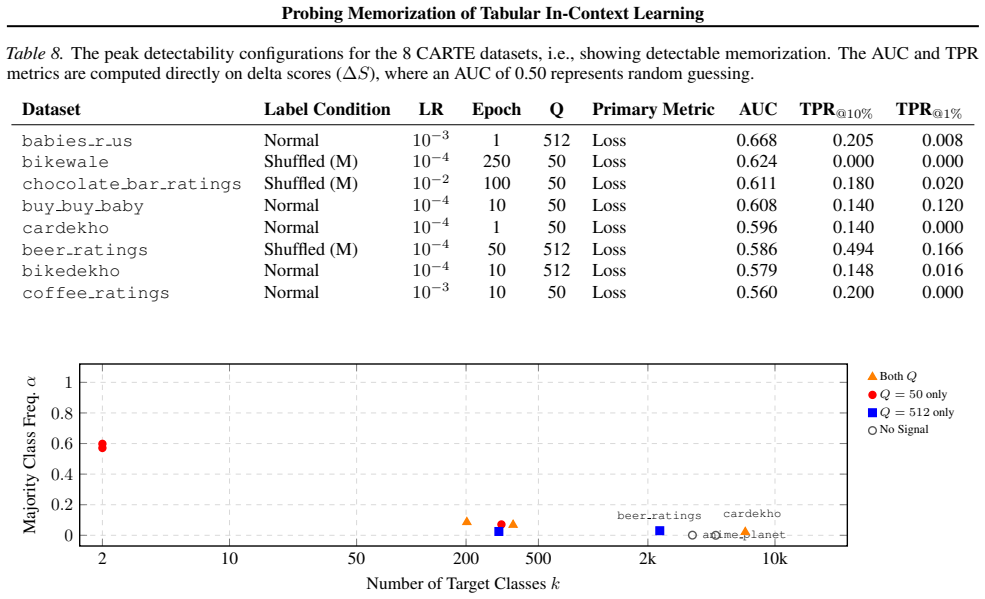
The ICLMEM framework isolates parametric memorization by feeding the model a zero-information multiple-choice context after controlled single-task fine-tuning; under these conditions a leading LTM exhibits detectable memorization (AUC up to 0.67) on eight of ten tasks, strongest for low-cardinality and binary targets, yet the effect disappears under realistic training conditions.
What carries the argument
ICLMEM probing framework using a zero-information multiple-choice context that forces the model to fall back on parametric memory by stripping away all valid contextual patterns.
If this is right
- Memorization signals are strongest on binary and low-cardinality tasks.
- Signals largely disappear once training shifts to realistic multi-task conditions.
- Single-task fine-tuning with fixed samples repeated across many epochs is the setting that produces detectable memorization.
- Appropriate protective measures are needed when sensitive tabular data are involved.
Where Pith is reading between the lines
- Multi-task training may act as a natural regularizer against memorization in tabular foundation models.
- The same zero-information probe could be adapted to test memorization in other in-context learning domains such as text or time series.
- Task cardinality may serve as a simple predictor of memorization risk during fine-tuning.
Load-bearing premise
The zero-information multiple-choice context removes every valid statistical cue, so above-chance performance can only be explained by memorization of training examples.
What would settle it
Running the same fine-tuned model on the zero-information context and observing performance indistinguishable from random chance would show that the detected signals are not due to memorization.
Figures


read the original abstract
Large tabular models (LTMs), i.e., tabular foundation models leveraging in-context learning (ICL), achieve state-of-the-art performance on tabular tasks. While LLMs are known to unintentionally memorize training data, the memorization dynamics of LTMs remain largely unexplored. We investigate the potential for parametric memorization in tabular ICL. We introduce ICLMEM, a probing framework designed to separate context-based predictions from parametric memorization. Our zero-information multiple-choice context strips away valid contextual patterns to force the model to fall back on its parametric memory. Our controlled fine-tuning setup establishes membership ground truth and accounts for common pitfalls, e.g., distribution shift, feature contamination, base-rate fallacy, and the pre-trained base model acts as reference to calibrate for sample difficulty. Our controlled evaluation on a leading real-world-trained LTM detects moderate memorization signals in 8 out of 10 tasks ($\text{AUC}$ up to $0.67$ and TPR at $1\%$ FPR $>0.1$). Notably, memorization signals are strongest for low-cardinality and binary tasks. However, they largely vanish under realistic training conditions. Our findings show LTM memorization signals under specific circumstances (single-task fine-tuning with fixed samples across many epochs and small query size). To protect sensitive data, appropriate measures must be taken, which we discuss.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ICLMEM, a probing framework to isolate parametric memorization from in-context learning in tabular foundation models (LTMs). It constructs a zero-information multiple-choice context that removes valid patterns, uses controlled fine-tuning with membership ground truth, and calibrates against the pre-trained base model. Evaluation on a leading real-world LTM reports moderate memorization signals (AUC up to 0.67, TPR at 1% FPR >0.1) in 8/10 tasks, strongest for low-cardinality/binary tasks, but largely vanishing under realistic training conditions.
Significance. If the zero-information context is confirmed to be information-theoretically null, the work provides the first controlled evidence of parametric memorization risks in tabular ICL under specific fine-tuning regimes (single-task, repeated samples, small query size), with direct implications for privacy in tabular foundation models. The explicit accounting for distribution shift, feature contamination, base-rate fallacy, and use of the base model as reference are methodological strengths.
major comments (2)
- [Methods (zero-information context construction)] Methods section describing the zero-information multiple-choice context: the central attribution of above-chance AUC/TPR to parametric memorization rests on the claim that this context eliminates all residual statistical cues (label distribution, option order). No ablation is reported (e.g., random label permutation within the multiple-choice options or full option randomization) to verify that the constructed context is null with respect to the binary and low-cardinality tasks where signals are strongest; without this, moderate signals (AUC ≤ 0.67) cannot be cleanly separated from prompt leakage.
- [Results (AUC/TPR tables and realistic-conditions ablation)] Results section reporting per-task AUC and TPR values: the claim of signals in 8/10 tasks and their disappearance under realistic conditions requires explicit confirmation that the reported metrics survive multiple-testing correction across tasks and that the 'realistic training conditions' ablation uses the same query size and epoch count as the single-task setup; otherwise the differential conclusion is under-supported.
minor comments (2)
- [Abstract and §1] The abstract and introduction should explicitly name the leading LTM evaluated (or state the anonymization policy) to allow readers to assess generalizability.
- [Figures 2-4] Figure captions for the AUC/TPR plots should include the exact number of queries, epochs, and sample sizes used in each condition.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which highlights important aspects of methodological validation and result reporting. We address each major comment below and will incorporate revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Methods (zero-information context construction)] Methods section describing the zero-information multiple-choice context: the central attribution of above-chance AUC/TPR to parametric memorization rests on the claim that this context eliminates all residual statistical cues (label distribution, option order). No ablation is reported (e.g., random label permutation within the multiple-choice options or full option randomization) to verify that the constructed context is null with respect to the binary and low-cardinality tasks where signals are strongest; without this, moderate signals (AUC ≤ 0.67) cannot be cleanly separated from prompt leakage.
Authors: We agree that an explicit ablation would provide stronger confirmation that the zero-information context is null. The construction removes label distribution via a fixed neutral option and randomizes presentation order by design, with the base-model calibration further controlling for sample difficulty. However, to directly rule out residual cues in low-cardinality tasks, we will add the suggested ablations (random label permutation within options and full option randomization) to the Methods and Results sections of the revision, reporting the resulting AUC/TPR to verify chance-level performance. revision: yes
-
Referee: [Results (AUC/TPR tables and realistic-conditions ablation)] Results section reporting per-task AUC and TPR values: the claim of signals in 8/10 tasks and their disappearance under realistic conditions requires explicit confirmation that the reported metrics survive multiple-testing correction across tasks and that the 'realistic training conditions' ablation uses the same query size and epoch count as the single-task setup; otherwise the differential conclusion is under-supported.
Authors: We will apply multiple-testing correction (Bonferroni) across the 10 tasks and update the tables and text to report adjusted values, confirming which signals remain significant. The realistic-conditions ablation is constructed with identical query size and epoch count to the single-task regime (as specified in the experimental setup); we will add an explicit hyperparameter comparison table and statements in the Results to make this equivalence clear and support the differential conclusion. revision: yes
Circularity Check
Empirical evaluation framework is self-contained with no derivation chain
full rationale
The paper reports measured AUC/TPR values from a controlled probing experiment on an external pre-trained LTM. No equations, predictions, or first-principles results are claimed; the zero-information context is an experimental construction whose validity is asserted via design (not derived from prior results or self-citations). No load-bearing step reduces to a fitted input or self-citation by construction. This is the standard case of an empirical study whose central claim rests on external model behavior and explicit controls rather than internal definitional equivalence.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The pre-trained base model serves as a valid reference to calibrate for sample difficulty without introducing new biases.
- domain assumption Distribution shift, feature contamination, and base-rate fallacy are the primary pitfalls that must be controlled for in this setting.
Reference graph
Works this paper leans on
-
[1]
2006 , organization=
Differential privacy , author=. 2006 , organization=
2006
-
[2]
2006 , organization=
Our data, ourselves: Privacy via distributed noise generation , author=. 2006 , organization=
2006
-
[3]
The algorithmic foundations of differential privacy , author=
-
[4]
2009 , organization=
Computational differential privacy , author=. 2009 , organization=
2009
-
[5]
Mironov, Ilya , series= CSF, year=. R
-
[6]
2016 , organization=
Concentrated differential privacy: Simplifications, extensions, and lower bounds , author=. 2016 , organization=
2016
-
[7]
Privacy integrated queries: an extensible platform for privacy-preserving data analysis , author=
-
[8]
2016 , organization =
Deep learning with differential privacy , author=. 2016 , organization =
2016
-
[9]
arXiv preprint arXiv:2303.00654 , year=
How to DP-fy ML: A Practical Guide to Machine Learning with Differential Privacy , author=. arXiv preprint arXiv:2303.00654 , year=
-
[10]
2013 , organization=
Local privacy and statistical minimax rates , author=. 2013 , organization=
2013
-
[11]
1992 , organization=
Efficient multiparty protocols using circuit randomization , author=. 1992 , organization=
1992
-
[12]
Communications of the ACM , year=
How to share a secret , author=. Communications of the ACM , year=
-
[13]
A pragmatic introduction to secure multi-party computation , author=
-
[14]
Attention is all you need , author=
-
[15]
2018 , URL =
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding , author =. 2018 , URL =
2018
-
[16]
Improving language understanding by generative pre-training , author=
-
[17]
ChatGPT , year =
OpenAI , howpublished =. ChatGPT , year =
-
[18]
Edward J Hu and yelong shen and Phillip Wallis and Zeyuan Allen-Zhu and Yuanzhi Li and Shean Wang and Lu Wang and Weizhu Chen , series = ICLR, year=. Lo
-
[19]
2023 , url =
Practical Tips for Finetuning LLMs Using LoRA , author=. 2023 , url =
2023
-
[20]
LoRA-FA: Efficient and Effective Low Rank Representation Fine-tuning
Lora-fa: Memory-efficient low-rank adaptation for large language models fine-tuning , author=. arXiv preprint arXiv:2308.03303 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
arXiv preprint arXiv:2403.12313 , year=
Improving LoRA in Privacy-preserving Federated Learning , author=. arXiv preprint arXiv:2403.12313 , year=
-
[22]
arXiv preprint arXiv:2312.17493 , year=
Differentially Private Low-Rank Adaptation of Large Language Model Using Federated Learning , author=. arXiv preprint arXiv:2312.17493 , year=
-
[23]
Gaussian Error Linear Units (GELUs)
Gaussian error linear units (gelus) , author=. arXiv preprint arXiv:1606.08415 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
Layer normalization , author=. arXiv preprint arXiv:1607.06450 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
2018 , url =
EU , title =. 2018 , url =
2018
-
[26]
Department of Health & Human Services , title =
U.S. Department of Health & Human Services , title =. 1996 , url =
1996
-
[27]
2018 , url =
California State Legislature , title =. 2018 , url =
2018
-
[28]
2017 , url =
Apple Differential Privacy Team , title =. 2017 , url =
2017
-
[29]
Training Large-Vocabulary Neural Language Model by Private Federated Learning for Resource-Constrained Devices , booktitle =
Mingbin Xu* and Congzheng Song* and Ye Tian and Neha Agrawal and Filip Granqvist and Rogier van Dalen and Xiao Zhang and Arturo Argueta and Shiyi Han and Yaqiao Deng and Leo Liu and Anmol Walia and Alex Jin , year =. Training Large-Vocabulary Neural Language Model by Private Federated Learning for Resource-Constrained Devices , booktitle =
-
[30]
2023 , url =
Hartmann, Florian and Kairouz, Peter , title =. 2023 , url =
2023
-
[31]
2024 , url =
TikTok PrivacyGo Team , title =. 2024 , url =
2024
-
[32]
IEEE Internet of Things Journal , year=
Data poisoning attacks on federated machine learning , author=. IEEE Internet of Things Journal , year=
-
[33]
2020 , organization=
How to backdoor federated learning , author=. 2020 , organization=
2020
-
[34]
2023 , organization=
Learning To Invert: Simple Adaptive Attacks for Gradient Inversion in Federated Learning , author=. 2023 , organization=
2023
-
[35]
Gradient obfuscation gives a false sense of security in federated learning , author=
-
[36]
2020 , organization=
Broadening differential privacy for deep learning against model inversion attacks , author=. 2020 , organization=
2020
-
[37]
2023 , organization=
SoK: Let the privacy games begin! A unified treatment of data inference privacy in machine learning , author=. 2023 , organization=
2023
-
[38]
arXiv preprint arXiv:2206.03317 , year=
Subject membership inference attacks in federated learning , author=. arXiv preprint arXiv:2206.03317 , year=
-
[39]
2023 , organization=
Sok: Model inversion attack landscape: Taxonomy, challenges, and future roadmap , author=. 2023 , organization=
2023
-
[40]
2017 , organization=
Membership inference attacks against machine learning models , author=. 2017 , organization=
2017
-
[41]
2018 , organization=
Privacy risk in machine learning: Analyzing the connection to overfitting , author=. 2018 , organization=
2018
-
[42]
arXiv preprint arXiv:2112.02918 , year=
When the curious abandon honesty: Federated learning is not private , author=. arXiv preprint arXiv:2112.02918 , year=
-
[43]
Extracting training data from large language models , author=
-
[44]
arXiv preprint arXiv:2205.12628 , year=
Are large pre-trained language models leaking your personal information? , author=. arXiv preprint arXiv:2205.12628 , year=
-
[45]
2023 , organization=
Analyzing leakage of personally identifiable information in language models , author=. 2023 , organization=
2023
-
[46]
arXiv preprint arXiv:2304.05197 , year=
Multi-step jailbreaking privacy attacks on chatgpt , author=. arXiv preprint arXiv:2304.05197 , year=
-
[47]
arXiv preprint arXiv:2310.10383 , year=
Privacy in large language models: Attacks, defenses and future directions , author=. arXiv preprint arXiv:2310.10383 , year=
-
[48]
Inan and Andre Manoel , title =
Lukas Wutschitz and Huseyin A. Inan and Andre Manoel , title =. 2022 , month =
2022
-
[49]
Differentially Private Fine-tuning of Language Models , author=
-
[50]
2021 , organization=
Large scale private learning via low-rank reparametrization , author=. 2021 , organization=
2021
-
[51]
arXiv preprint arXiv:2110.05679 , year=
Large language models can be strong differentially private learners , author=. arXiv preprint arXiv:2110.05679 , year=
-
[52]
arXiv preprint arXiv:2401.04343 , year=
Private fine-tuning of large language models with zeroth-order optimization , author=. arXiv preprint arXiv:2401.04343 , year=
-
[53]
Liang Zhang and Kiran Thekumparampil and Sewoong Oh and Niao He , series = NeurIPS, year=
-
[54]
arXiv preprint arXiv:2402.11592 , year=
Revisiting Zeroth-Order Optimization for Memory-Efficient LLM Fine-Tuning: A Benchmark , author=. arXiv preprint arXiv:2402.11592 , year=
-
[55]
Ruan, Wenqiang and Xu, Mingxin and Fang, Wenjing and Wang, Li and Wang, Lei and Han, Weili , title =
-
[56]
arXiv preprint arXiv:2202.02625 , year=
Training differentially private models with secure multiparty computation , author=. arXiv preprint arXiv:2202.02625 , year=
-
[57]
2023 , publisher=
MPCFormer: Fast, performant and private transformer inference with MPC , author=. 2023 , publisher=
2023
-
[58]
2023 , organization=
Privformer: Privacy-preserving transformer with mpc , author=. 2023 , organization=
2023
-
[59]
arXiv preprint arXiv:2401.00793 , year=
Secformer: Towards fast and accurate privacy-preserving inference for large language models , author=. arXiv preprint arXiv:2401.00793 , year=
-
[60]
arXiv preprint arXiv:2307.12533 , year=
Puma: Secure inference of llama-7b in five minutes , author=. arXiv preprint arXiv:2307.12533 , year=
-
[61]
Cryptology ePrint Archive , year=
SIGMA: secure GPT inference with function secret sharing , author=. Cryptology ePrint Archive , year=
-
[62]
Cryptology ePrint Archive , year=
BOLT: Privacy-Preserving, Accurate and Efficient Inference for Transformers , author=. Cryptology ePrint Archive , year=
-
[63]
Iron: Private inference on transformers , author=
-
[64]
Cryptology ePrint Archive , year=
Curl: Private LLMs through Wavelet-Encoded Look-Up Tables , author=. Cryptology ePrint Archive , year=
-
[65]
THE-X: Privacy-Preserving Transformer Inference with Homomorphic Encryption , author=
-
[66]
2020 , doi =
Marcel Keller , title =. 2020 , doi =
2020
-
[67]
Ashkan Yousefpour and Igor Shilov and Alexandre Sablayrolles and Davide Testuggine and Karthik Prasad and Mani Malek and John Nguyen and Sayan Ghosh and Akash Bharadwaj and Jessica Zhao and Graham Cormode and Ilya Mironov , journal=. Opacus:
-
[68]
2021 , organization=
CryptGPU: Fast privacy-preserving machine learning on the GPU , author=. 2021 , organization=
2021
-
[69]
Pytorch: An imperative style, high-performance deep learning library , author=
-
[70]
Crypten: Secure multi-party computation meets machine learning , author=
-
[71]
GLUE: A Multi-Task Benchmark and Analysis Platform for Natural Language Understanding
GLUE: A multi-task benchmark and analysis platform for natural language understanding , author=. arXiv preprint arXiv:1804.07461 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[72]
The skellam mechanism for differentially private federated learning , author=
-
[73]
Poission subsampled r
Zhu, Yuqing and Wang, Yu-Xiang , series = ICML, year=. Poission subsampled r
-
[74]
Ma-bert: Towards matrix arithmetic-only BERTinference by eliminating complex non-linear functions , author=
-
[75]
Mpcvit: Searching for accurate and efficient mpc-friendly vision transformer with heterogeneous attention , author=
-
[76]
Delving deep into rectifiers: Surpassing human-level performance on imagenet classification , author=
-
[77]
Understanding the difficulty of training deep feedforward neural networks , author=
-
[78]
Neural networks: Tricks of the trade , year=
Efficient backprop , author=. Neural networks: Tricks of the trade , year=
-
[79]
Exact solutions to the nonlinear dynamics of learning in deep linear neural networks , author=
-
[80]
DP-AdamBC: Your DP-Adam Is Actually DP-SGD (Unless You Apply Bias Correction) , author=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.