Content-Adaptive Rate-Quality Curve Prediction Model in Media Processing System
Pith reviewed 2026-05-23 17:46 UTC · model grok-4.3
The pith
A model predicts full bitrate-quality curves from codec and content features to support flexible transcoding without retraining.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
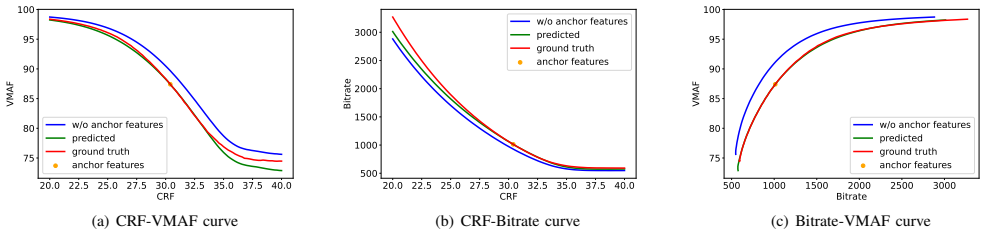
The model predicts both the RF-quality curve and the RF-bitrate curve using codec features, content features, and anchor features. From these, the full bitrate-quality curve is derived, which allows selection of encoding parameters to meet quality targets for different contents. The anchor suspension method improves the accuracy of these predictions.
What carries the argument
The rate-quality curve prediction model that combines codec, content, and anchor features with an anchor suspension method to forecast bitrate-quality relationships.
If this is right
- Transcoding can adjust encoding parameters dynamically based on video content instead of using uniform rate factors.
- Encoding strategies can be modified flexibly without retraining the prediction model.
- Quality control achieves high precision with actual VMAF deviation under 1 from the target.
- Online deployment produces measurable improvements in video views, completions, and app duration time.
Where Pith is reading between the lines
- The approach may extend to other perceptual quality metrics if comparable features are identified.
- It could reduce overall bandwidth consumption in streaming by enabling more precise per-video bitrate allocation.
- Integration with real-time analysis pipelines might support live streaming adaptations beyond on-demand transcoding.
Load-bearing premise
Codec features, content features, and anchor features capture enough information to predict the bitrate-quality curve accurately across arbitrary encoding strategies.
What would settle it
A test set of videos encoded with a new strategy where the actual VMAF differs from the model's target by more than 1 point on average would falsify the accuracy claim.
Figures


read the original abstract
In streaming media services, video transcoding is a common practice to alleviate bandwidth demands. Unfortunately, traditional methods employing a uniform rate factor (RF) across all videos often result in significant inefficiencies. Content-adaptive encoding (CAE) techniques address this by dynamically adjusting encoding parameters based on video content characteristics. However, existing CAE methods are often tightly coupled with specific encoding strategies, leading to inflexibility. In this paper, we propose a model that predicts both RF-quality and RF-bitrate curves, which can be utilized to derive a comprehensive bitrate-quality curve. This approach facilitates flexible adjustments to the encoding strategy without necessitating model retraining. The model leverages codec features, content features, and anchor features to predict the bitrate-quality curve accurately. Additionally, we introduce an anchor suspension method to enhance prediction accuracy. Experiments confirm that the actual quality metric (VMAF) of the compressed video stays within 1 of the target, achieving an accuracy of 99.14%. By incorporating our quality improvement strategy with the rate-quality curve prediction model, we conducted online A/B tests, obtaining both +0.107% improvements in video views and video completions and +0.064% app duration time.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a content-adaptive model that predicts RF-quality and RF-bitrate curves from codec, content, and anchor features (augmented by an anchor suspension technique) to derive full bitrate-quality curves. This is intended to support flexible encoding strategy changes in video transcoding without model retraining. The central empirical claims are that the model keeps actual VMAF within 1 of target at 99.14% accuracy and that incorporating the model yields +0.107% lifts in video views/completions and +0.064% in app duration time in online A/B tests, with deployment on the Xiaohongshu App.
Significance. If the generalizability claim holds, the approach would allow more efficient, strategy-agnostic content-adaptive encoding in large-scale streaming systems, reducing the need for per-strategy model retraining. The reported online A/B improvements and production deployment constitute concrete external validation of practical utility. No machine-checked proofs or parameter-free derivations are present, but the emphasis on curve prediction rather than point estimates is a methodological strength.
major comments (3)
- [Abstract] Abstract: The claim that the model 'facilitates flexible adjustments to the encoding strategy without necessitating model retraining' is load-bearing for the contribution, yet no experiments evaluate performance on encoding strategies (e.g., different presets or codecs) outside the training distribution; the reported 99.14% figure and A/B results are therefore consistent with in-distribution performance only.
- [Abstract] Abstract: The accuracy statement that 'the actual quality metric (VMAF) of the compressed video stays within 1 of the target, achieving an accuracy of 99.14%' is presented without dataset size, content-type distribution, validation split, baseline comparisons, or error analysis, leaving the quantitative support for the central prediction claim only moderately substantiated.
- [Abstract] Abstract: The anchor suspension method is introduced to 'enhance prediction accuracy,' but no ablation quantifying its contribution (or the individual roles of codec/content/anchor features) is described, which is necessary to assess whether the reported accuracy depends on these components or on the fitting procedure itself.
minor comments (1)
- The abstract refers to 'codec features, content features, and anchor features' without providing even high-level definitions or example values; these should be clarified early in the manuscript to allow readers to evaluate feature sufficiency.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract claims. We address each major comment below and commit to revisions that strengthen the substantiation of our results without overstating the current evidence.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that the model 'facilitates flexible adjustments to the encoding strategy without necessitating model retraining' is load-bearing for the contribution, yet no experiments evaluate performance on encoding strategies (e.g., different presets or codecs) outside the training distribution; the reported 99.14% figure and A/B results are therefore consistent with in-distribution performance only.
Authors: The model architecture incorporates codec features explicitly as inputs, which is intended to support generalization across codecs and presets by learning mappings from these features to curve parameters. The production A/B tests reflect real-world usage where encoding configurations can vary. We nevertheless agree that explicit evaluation on held-out strategies would better substantiate the flexibility claim. In the revision we will add experiments testing the model on unseen presets and codecs. revision: yes
-
Referee: [Abstract] Abstract: The accuracy statement that 'the actual quality metric (VMAF) of the compressed video stays within 1 of the target, achieving an accuracy of 99.14%' is presented without dataset size, content-type distribution, validation split, baseline comparisons, or error analysis, leaving the quantitative support for the central prediction claim only moderately substantiated.
Authors: The abstract is a concise summary; the full manuscript (Section 4) reports the dataset size, content distribution, validation protocol, baseline comparisons, and error analysis that underlie the 99.14% figure. We will revise the abstract to include the dataset cardinality and a brief reference to the validation methodology so that the central claim is better supported at the abstract level. revision: yes
-
Referee: [Abstract] Abstract: The anchor suspension method is introduced to 'enhance prediction accuracy,' but no ablation quantifying its contribution (or the individual roles of codec/content/anchor features) is described, which is necessary to assess whether the reported accuracy depends on these components or on the fitting procedure itself.
Authors: We agree that an ablation study is required to isolate the contribution of anchor suspension and the feature groups. We will add a dedicated ablation subsection in the revised manuscript that reports accuracy with and without anchor suspension as well as the incremental value of each feature category. revision: yes
Circularity Check
No significant circularity; model is trained and empirically validated.
full rationale
The paper describes a feature-based ML model for predicting RF-quality and RF-bitrate curves from codec, content, and anchor features, followed by derivation of the bitrate-quality curve and empirical checks (VMAF within 1 at 99.14% accuracy plus online A/B tests). No equations or steps are shown that reduce a claimed prediction to its own fitted inputs by construction, nor any self-citation load-bearing uniqueness theorems or ansatzes smuggled in. The derivation chain is self-contained as a standard supervised prediction task with external validation signals.
Axiom & Free-Parameter Ledger
free parameters (1)
- ML model parameters
axioms (1)
- domain assumption Codec, content, and anchor features suffice to model rate-quality relationships for any encoding strategy
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.