DailyReport: An Open-ended Benchmark for Evaluating Search Agents on Daily Search Tasks
Pith reviewed 2026-06-27 07:17 UTC · model grok-4.3
The pith
DailyReport benchmark with 150 daily tasks shows current search agents fall short of user expectations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
DailyReport provides 150 open-ended tasks that capture widely discussed and timely real-world user information demands, each decomposed into subtasks and assessed with cascade rubrics across disentangled dimensions to yield highly interpretable scores and a user preference score, with evaluation of 17 agentic systems demonstrating they still fall short of users' expectations.
What carries the argument
Cascade rubrics that decompose each task into subtasks and evaluate performance across disentangled dimensions to enable performance attribution and user-centric aggregation.
Load-bearing premise
The 150 tasks and associated rubrics accurately capture widely discussed and timely real-world user information demands and that the cascade rubric structure yields scores aligned with actual user preferences.
What would settle it
Independent user studies where participants rate the same agent outputs on the 150 tasks and the resulting preference rankings diverge from the benchmark's aggregated user preference scores.
Figures


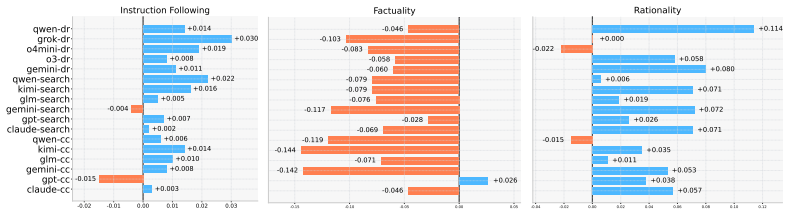
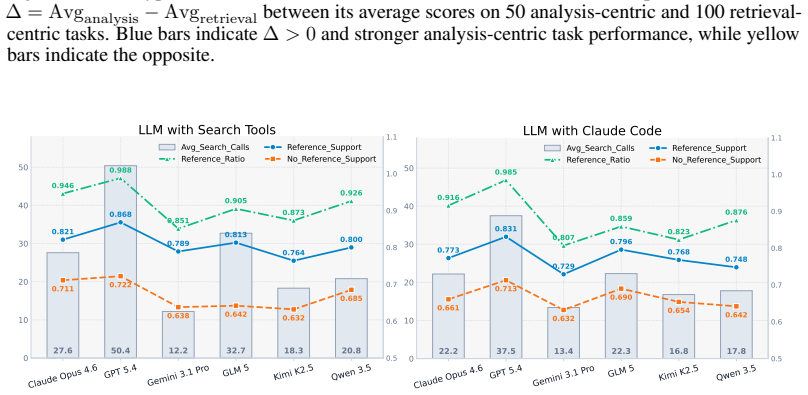
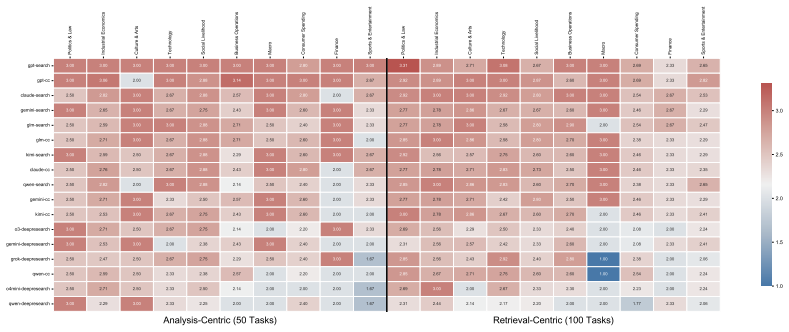
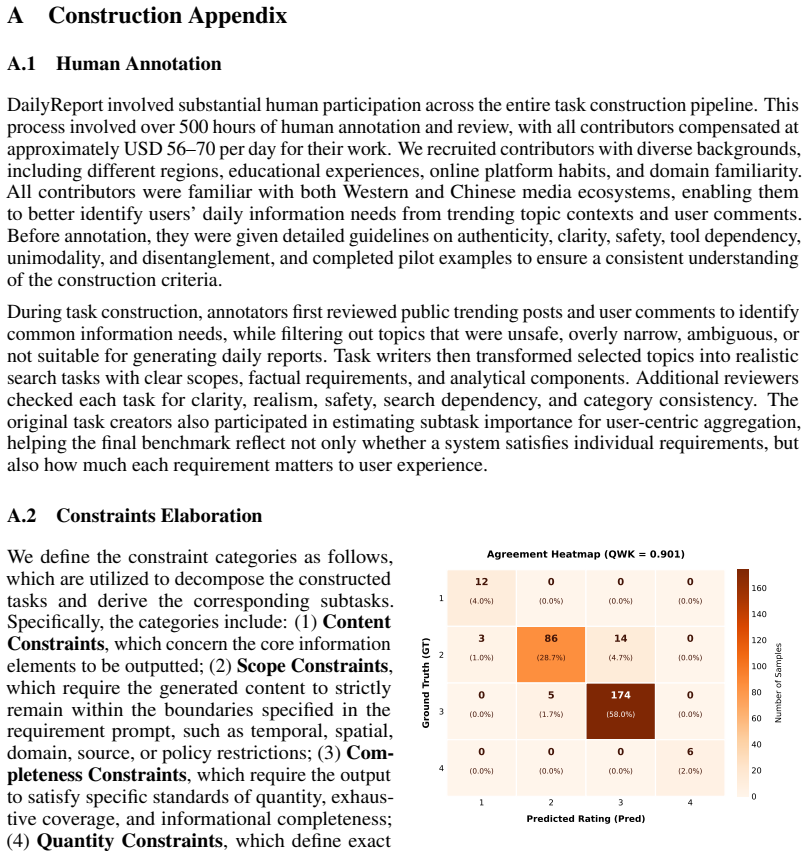
read the original abstract
Search Agents (SAs) typically leverage large language models (LLMs) to support complex information-seeking tasks by autonomously exploring web sources and synthesizing information into comprehensive responses. For SAs evaluation, prior benchmarks mainly focus on specialized tasks that are unlikely to arise in real-world user scenarios. Moreover, their reliance on coarse task-level rubrics often limits evaluation interpretability. To bridge this gap, we introduce DailyReport, an open-ended benchmark to evaluate SA capabilities on daily search tasks. It contains 150 open-ended tasks with 3,546 associated rubrics, capturing widely discussed and timely information demands of real-world users. Each task is decomposed into subtasks and evaluated with cascade rubrics across disentangled dimensions. Through cascade performance attribution and user-centric aggregation, we derive highly interpretable scores for each dimension, along with a user preference score. Our results on 17 agentic systems show that current systems still fall short of users' expectations. To facilitate future research, our dataset and code are made publicly available at https://github.com/AGI-Eval-Official/DailyReport.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces DailyReport, an open-ended benchmark containing 150 daily search tasks and 3,546 cascade rubrics to evaluate search agents (SAs) on real-world information-seeking scenarios. It contrasts with prior specialized-task benchmarks by using task decomposition, disentangled dimension scoring, and user-centric aggregation to produce interpretable per-dimension and overall preference scores. Evaluation of 17 agentic systems leads to the conclusion that current SAs still fall short of user expectations; the dataset and code are released publicly.
Significance. If the tasks and rubrics prove representative and the cascade scoring aligns with user preferences, the benchmark would offer a more realistic and interpretable evaluation framework than existing alternatives, directly supporting progress on practical search-agent capabilities. The public release of tasks, rubrics, and code is a clear strength that enables reproducibility and community follow-up.
major comments (3)
- [§3.1] §3.1 (Task Construction): The claim that the 150 tasks capture 'widely discussed and timely' real-world demands requires explicit sourcing criteria, sampling frame, and filtering steps; without these, it is impossible to evaluate coverage or selection bias, which directly affects the validity of the 'fall short of users' expectations' conclusion.
- [§3.3] §3.3 (Rubric Validation and Aggregation): The assertion that cascade rubrics produce scores 'aligned with actual user preferences' is load-bearing for the main result, yet no human validation study, inter-rater reliability, or correlation between automated scores and direct user preference judgments is reported.
- [§4.2] §4.2 (System Evaluation): The 17 agentic systems are evaluated, but the manuscript does not specify how the systems were selected (e.g., representative sample vs. convenience) or whether any ablation on rubric weighting was performed; this limits the strength of the cross-system shortfall claim.
minor comments (2)
- The abstract states 3,546 rubrics but the main text should include a breakdown by dimension and task type for transparency.
- Figure 2 (or equivalent) illustrating the cascade rubric structure would benefit from a concrete worked example for one task.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and will revise the manuscript accordingly to improve clarity and transparency.
read point-by-point responses
-
Referee: [§3.1] §3.1 (Task Construction): The claim that the 150 tasks capture 'widely discussed and timely' real-world demands requires explicit sourcing criteria, sampling frame, and filtering steps; without these, it is impossible to evaluate coverage or selection bias, which directly affects the validity of the 'fall short of users' expectations' conclusion.
Authors: We agree that explicit documentation of sourcing is required for assessing coverage and bias. The current manuscript states that tasks capture widely discussed demands but does not detail the process. In revision we will expand §3.1 with the sourcing criteria (public forums, news, and search trends), sampling frame, and filtering steps used to select the 150 tasks. revision: yes
-
Referee: [§3.3] §3.3 (Rubric Validation and Aggregation): The assertion that cascade rubrics produce scores 'aligned with actual user preferences' is load-bearing for the main result, yet no human validation study, inter-rater reliability, or correlation between automated scores and direct user preference judgments is reported.
Authors: The cascade design uses task decomposition and user-centric aggregation to promote alignment, but no dedicated human validation study or correlation analysis was performed. We will revise §3.3 to state this limitation explicitly and outline plans for future validation studies. revision: partial
-
Referee: [§4.2] §4.2 (System Evaluation): The 17 agentic systems are evaluated, but the manuscript does not specify how the systems were selected (e.g., representative sample vs. convenience) or whether any ablation on rubric weighting was performed; this limits the strength of the cross-system shortfall claim.
Authors: We will clarify in §4.2 that the 17 systems constitute a diverse convenience sample of publicly available agentic systems (open-source and proprietary). No weighting ablations were conducted; we will add discussion of aggregation robustness and note the absence of ablations. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper constructs a new benchmark (150 tasks, 3546 rubrics) from scratch to evaluate 17 systems empirically. No equations, fitted parameters, or derivations are present; results are direct measurements on the released dataset rather than quantities that reduce to self-citations or internal fits by construction. The central claim (systems fall short) follows from the new evaluation without load-bearing self-referential steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The 150 tasks capture widely discussed and timely information demands of real-world users.
Reference graph
Works this paper leans on
-
[1]
Every factual claim, data point, statistic, name, date, or opinion in your report MUST come from information retrieved via the tools
NEVER use your own parametric knowledge. Every factual claim, data point, statistic, name, date, or opinion in your report MUST come from information retrieved via the tools. If you cannot find information through the tools, say so — do NOT fill in from memory
-
[2]
Use as many search and fetch rounds as needed to produce the most comprehensive, in-depth, and well-verified report possible
Research strategy — fully autonomous, multi-angle verification: You have complete freedom to decide your research strategy. Use as many search and fetch rounds as needed to produce the most comprehensive, in-depth, and well-verified report possible
-
[3]
• The report should be thorough and at least 2000 words
Output format — produce a Markdown research report: • Use clear Markdown headings (##, ###) to organize by topic. • The report should be thorough and at least 2000 words. • Write in the same language as the research question
2000
-
[4]
The three major platforms invested a cumulative 80-100 billion yuan in subsidies [63]
Citations — numbered parenthetical references: • Assign each source a sequential number starting from 1. • In the report body, cite sources usingparenthetical numbers: [1], [2], [3]. For example: “The three major platforms invested a cumulative 80-100 billion yuan in subsidies [63]”. • Each major claim must be backed by at least one citation. • End with a...
-
[5]
Farewell to the cash-burning era! Food delivery platforms simultaneously halt zero-dollar purchases_Financial News http://example.com/article1
-
[6]
That signals the end of the research process
China’s fitness industry report 2025_Reuters https://example.com/article2 When you have gathered sufficient information and are ready, output the final report as your response (without any tool calls). That signals the end of the research process. Instruction Follow Score Prompt
-
[7]
If the question explicitly includes time constraints, please follow the question’s requirements
Role & Goal Background time: The current date is {cur_date}. If the question explicitly includes time constraints, please follow the question’s requirements. You are an expert evaluating the ability of an intelligent agent to handle specified tasks. Your focus is on the agent’s instruction-following capability. Your scoring must be objective and fair
-
[8]
Input Format You will receive the user question (Question), the agent’s processing result (Document), and detailed scoring criteria (Criteria) for this evaluation: • Question(str): <User question> • Document(str): <Agent’s processing result> • Criteria(list): <Scoring criteria>
-
[9]
Workflow Please strictly follow the workflow below to complete the task:
-
[10]
Clearly understand the meaning of each scoring criterion
Carefully read the Question, Document, and Criteria content. Clearly understand the meaning of each scoring criterion. Do not omit or alter any content in the Document
-
[11]
criterion
Iterate through Criteria and score each individual criterion. Do not add, remove, or modify any scoring criteria. Follow the scoring process below: • If the Document content strictly satisfies the "criterion" content, the score for this criterion is 1.0. • If the constraints in the "criterion" include multiple subjects, objects, or methods, and only part ...
-
[12]
Carefully verify your scoring result for each criterion to ensure accuracy
-
[13]
this metric cannot be obtained
Do not judge the accuracy of Document content based on your existing knowledge. You need to judge based on what the Document claims, even if the content may be incorrect. You do not need to verify its accuracy. • If the scoring criteria require explicitly providing a certain metric, and the delivery document explicitly states "this metric cannot be obtain...
-
[14]
When Criteria contains scoring criteria involving time requirements, please judge based on the time information claimed in the Document
Do not judge based on your time system . When Criteria contains scoring criteria involving time requirements, please judge based on the time information claimed in the Document
-
[15]
Strictly score according to the standards in Criteria against the Document
Do not engage in open-ended thinking . Strictly score according to the standards in Criteria against the Document. Do not add, remove, or alter any standards in Criteria
-
[16]
Does the delivery document analyze future development based on existing policies?
Your scoring should be very strict, reflected in the following aspects: (a) All subjects and objects required in the scoring criteria, as well as any actions or conditions related to subjects and objects, must be checked. (b) Scoring cannot rely solely on section titles in the Document. Verify whether the body text actually contains relevant content that ...
-
[17]
Ignore the reference materials section
-
[18]
criterion
Output Format You must output your scoring results in the following format: [ { "criterion": " <Individual scoring criterion, consistent with input >,", "score": <Final score for this criterion >, "explain": " <Thinking process, strictly consistent with the final score >" }, ...and more... ] Please begin your work: Question: {question} Document: {document...
-
[19]
claim information
Role and Objective You are a text information mining expert, skilled at locating and extracting “claim information” from documents
-
[20]
Input Format • Document (str): Input document • Question (str): Accuracy question Important Principle: All extracted content must originate from the Document, and only claim information related to the Question should be extracted
-
[21]
18 • Action: Deeply analyze the Document and Question to identify all information related to the accuracy question
Workflow Step 1: Analysis and Clarification • Objective: Accurately understand the input information. 18 • Action: Deeply analyze the Document and Question to identify all information related to the accuracy question. • Note:
-
[22]
Delivery result
“Delivery result” in the Question refers to the Document
-
[23]
Step 2: Location and Extraction • Objective: Precisely locate and extract the target information
Pay attention to headings of all levels in the Document; some headings may directly correspond to the content of the Question. Step 2: Location and Extraction • Objective: Precisely locate and extract the target information. • Action:
-
[24]
Modifying the original text in any way is strictly prohibited
Locate the target information and fill the original complete content into the “fact” field. Modifying the original text in any way is strictly prohibited
-
[25]
fact” content and store them in the “extract
Integrate the sentences from the “fact” content and store them in the “extract” field as the final extraction result. Sentence integration is allowed, such as clarifying the objects referred to by pronouns, providing textual interpretations of chart content, supplementing missing background context, etc. However, tampering with, adding, or deleting core c...
-
[26]
The extracted information must be a factual claim, i.e., an objective, specific statement whose authenticity can be verified through authoritative sources. Subjective evaluations, basic common sense, symbolic metaphors, suggestions/instructions, hypothetical rea- soning, and other vague statements that cannot be objectively verified must be excluded
-
[27]
Fabricating content that does not exist in the Document is strictly prohibited
The extracted information must explicitly appear in theDocument. Fabricating content that does not exist in the Document is strictly prohibited
-
[28]
Extract all relevant content from the Document to avoid any omissions
-
[29]
no relevant content support
If the target information in the Document appears in the form of “no relevant content support” or “no data”,it must also be extracted
-
[30]
The starring actor of [Movie Name] is [Actor Name]
When extracting, sufficient context and background information must be supple- mented to avoid semantic incompleteness or ambiguity caused by taking things out of context. Relevant context may be distributed in different parts of the Document; please read through carefully and supplement it. – Example: When extracting movie starring information, it should...
-
[31]
If the Question involves quantity requirements, ensure the extracted content meets that quantity
-
[32]
If subject, time, or location information is involved, it must be accurately supple- mented
-
[33]
Step 3: Check and Integration • Objective: Verify whether the complete workflow meets all the notes and output the final result
The “extract” field must not contain any subjective content, including subjective judgments, additional explanations, etc. Step 3: Check and Integration • Objective: Verify whether the complete workflow meets all the notes and output the final result. • Action:
-
[34]
Check item by item whether each field meets the requirements
-
[35]
json_output
Integrate the results into a strict JSON object as the content of “json_output”: [ { "fact": <Original target text in the Document >, "extract": <Integrated target information > }, ... ] 19 Note: Even if there are no extraction results, this question must not be skipped; simply output an empty list in “json_output”
-
[36]
Output Format Please output strictly in the following format: <analysis> Your analysis process </analysis> <json_output> The extracted results </json_output>
-
[37]
• If a section heading directly corresponds to the Question, you must focus on the content of that section to avoid omissions
The Document may be a structured Markdown document; please pay attention to heading level symbols (e.g., “###”). • If a section heading directly corresponds to the Question, you must focus on the content of that section to avoid omissions. • Section headings may contain subject information; necessary subject context should be supplemented during extraction
-
[38]
Be sure to ensure the comprehensiveness of the extraction, double-check repeatedly, and do not omit anything
-
[39]
fact”, “extract
Compared to “fact”, “extract” is strictly prohibited from losing any original text informa- tion
-
[40]
Claim information must guarantee atomicity; each claim should contain only one indepen- dent, verifiable factual point. Specific splitting rules: • Body paragraphs: If a paragraph contains multiple independent factual statements (e.g., data of different subjects, information of different dimensions), it must be split into multiple claims; if multiple sent...
-
[41]
gentle”, “romantic
Subjective evaluations and descriptions (e.g., “gentle”, “romantic”, “more native”, “the soup base is incredibly delicious”)
-
[42]
the sun rises in the east and sets in the west
Basic common sense (e.g., “the sun rises in the east and sets in the west”, “Meituan is a platform with a transaction system”)
-
[43]
Interpretations, symbols, and metaphors (e.g., using A as a metaphor for B)
-
[44]
in order to
Inferences of motives, intentions, and purposes (e.g., “in order to...”, “aimed at...”)
-
[45]
therefore
Analysis, summaries, and causal inferences (e.g., “therefore...”, “this reflects...”)
-
[46]
follow this guide
Suggestions, instructions, and imperatives (e.g., “follow this guide”, “look for Xiang- shan Market”, “don’t buy silverware in the ancient city”)
-
[47]
assuming a 40% penetra- tion rate in tier-1 cities and a uniform 50% savings replacement rate
Simulations, hypotheses, and self-reasoned results (e.g., “assuming a 40% penetra- tion rate in tier-1 cities and a uniform 50% savings replacement rate”, “mathematical modeling of the above scenario is as follows”)
-
[48]
100 times quieter than daytime
Vague statements that cannot be objectively verified(e.g., “100 times quieter than daytime”, “budget travelers can also experience a premium feel”)
-
[49]
the author of paper [1] is Anthony
Descriptions regarding reference links (e.g., “the author of paper [1] is Anthony”)
-
[50]
this report is based on operating data from January 2020 to October 2025
Descriptions related only to the document itself(e.g., “this report is based on operating data from January 2020 to October 2025”) Please begin your work based on the input information: Document: {document} Question: {question} 20 Claims Integrate Prompt
2020
-
[51]
Task Objective Based on the complete document and the extracted claim information, deduplicate and reassign the claims so that each claim belongs to the most matching accuracy question
-
[52]
Each claim comes with a unique “id”
Input Format • Document: {document} • Assertions: {assertions} Assertions is a dictionary structure, where the key is the accuracy question, and the value is the list of claim information already assigned under that question. Each claim comes with a unique “id”
-
[53]
Keep any one of them and delete the rest
Workflow Step 1: Deduplication Identify duplicate claims on a global scale (across questions + within the same question): • Exact Duplicates: If the “extract” of two claims conveys the same fact (even if worded differently), they are considered duplicates. Keep any one of them and delete the rest. • Inclusion Relationship: The core fact of one claim is co...
-
[54]
If duplicates are found, keep it only under the most matching question
Cross-question Uniqueness: Iterate through the claim IDs under all questions to confirm that no ID appears in two or more questions. If duplicates are found, keep it only under the most matching question
-
[55]
If found, delete the redundant one
Semantic Deduplication: Confirm that there are no two claims conveying the same fact (even if worded differently). If found, delete the redundant one
-
[56]
delete” list is indeed a duplicate, rather than just “content-related
Accidental Deletion Check: Confirm that each claim in the “delete” list is indeed a duplicate, rather than just “content-related”
-
[57]
delete": [List of deleted claim IDs],
Output Format Output a strict JSON object: { "delete": [List of deleted claim IDs], "new_claim": {Accuracy question: [List of claim IDs under this question], ...} }
-
[58]
Pay special attention to headings of all levels in the Document to assist in the reassignment of claim information
-
[59]
Omitting any accuracy question is prohibited, and the original order of the accuracy questions must be maintained. 21
-
[60]
Claims that are content-related but have different information must be kept
Deduplication must be conservative: Only delete claims whose “extract” content is truly du- plicated or completely included. Claims that are content-related but have different information must be kept. If unsure whether it is a duplicate, choose to keep it
-
[61]
The output must only use the claim “id” for reference; modifying any accuracy question or the original text of the claims is prohibited
-
[62]
Query Generate Prompt
Core Principle: Categorize claims into specific accuracy questions as much as possible, avoiding piling them up in the fallback category. Query Generate Prompt
-
[63]
Role and Objective You are a web information retrieval expert, skilled at writing query statements for search engine verification based on claim information
-
[64]
fact": <Original claim in the Document >,
Input Format • Question (str): The complete question asked by the user to the AI assistant • Sub-Question (str): The sub-question (scoring rubric) split from the Question • Assertions (list): A list of claim information extracted from the AI assistant’s reply and related to the current Sub-Question, formatted as follows: [ { "fact": <Original claim in the...
-
[65]
• Action : Iterate through each claim in Assertions:
Workflow Step 1: Claim Verification • Objective : Ensure the claim information is complete and prepare for query generation. • Action : Iterate through each claim in Assertions:
-
[66]
extract” omits the core context information of “fact
If “extract” omits the core context information of “fact”, leading to taking things out of context or ambiguity, supplement and correct it
-
[67]
cannot be verified via the internet
Judge whether this claim is an exact duplicate of other claims (i.e., conveys the same core fact) — if it is a duplicate, remove this claim. • Important: Removing claims on the grounds of “cannot be verified via the internet” is strictly prohibited. The input claims have already undergone preliminary screening; this step is only for supplementary correcti...
-
[68]
Identification: Analyze the claim and identify the core information necessary to distinguish its authenticity
-
[69]
Step 3: Generation and Verification • Objective: Generate high-quality query statements
Decomposition: If the claim requires multi-stage, multi-angle verification, further decompose it to facilitate the generation of progressive query statements. Step 3: Generation and Verification • Objective: Generate high-quality query statements. • Action:
-
[70]
id” field is a 0-based index, and the “query
Statement Generation: Iterate through the decomposed claims and generate query statements one by one. Each query statement is an independent dictionary structure, where the “id” field is a 0-based index, and the “query” field is the main body of the 22 query statement (required to be a yes/no question format). If the current query depends on the results o...
-
[71]
Yes”, and the query statement is consistent with the information conveyed by the corresponding claim, keep the query statement. – If “Yes
Authenticity Verification: Perform a final verification on each query statement — Can this query statement be explicitly compared with a recognized objec- tive fact (such as a specific location, institution name, number, geographical location, scientific common sense, etc.) via a search engine to determine its authenticity? – If “Yes”, and the query state...
-
[72]
If multiple progressive queries are needed, please strictly follow the steps above
The query statement must be a yes/no question format to support precise and efficient retrieval. If multiple progressive queries are needed, please strictly follow the steps above
-
[73]
If there is an indirect relationship between the core demand of the Sub-Question and the current claim, please set up progressive query statements through a multi-hop approach
-
[74]
Each query statement must accurately convey the core demand in the Sub-Question; tampering with the intent is strictly prohibited
-
[75]
Be sure to distinguish the affirmative/negative voice of the claim to avoid semantic reversal
-
[76]
Generating the current query statement by referencing other “extract” content is prohibited
The factual content involved in the query statement must strictly appear in the cur- rent “extract”; tampering with, adding, or deleting any modifying words and the factual content itself is strictly prohibited. Generating the current query statement by referencing other “extract” content is prohibited
-
[77]
according to reliable sources
Remove redundant content unrelated to factual information (e.g., “according to reliable sources”, “according to merchant feedback”), but relevant information involving explicit subjects must be retained
-
[78]
Step 4: Check and Integration • Objective: Verify whether the workflow meets all requirements and output the final result
Be sure to pay attention to limiting information such as time and location, as this information is crucial for web retrieval. Step 4: Check and Integration • Objective: Verify whether the workflow meets all requirements and output the final result. • Action:
-
[79]
Check the information completeness of the query statements item by item to ensure no omissions, no tampering, and no fabrication of any content in the claims
-
[80]
Check the generation quality of the query statements to ensure there are no issues such as ambiguity or unclear semantics
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.