The Art of Interrogation: Consistency Amplifies Factuality in Spatial Reasoning
Pith reviewed 2026-06-27 09:44 UTC · model grok-4.3
The pith
Pre-trained models reach near-supervised spatial reasoning accuracy by enforcing consistency under geometric transformations without labels.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that formalizing consistency verifiers as reward functions for geometric and semantic coherence under transformations, combined with an optimal transport-based RL strategy called OT-GRPO, allows self-supervised training to improve spatial reasoning in large reasoning models to levels approaching those achieved by supervised fine-tuning on ground-truth data, while preserving similar generalization.
What carries the argument
Consistency verifiers that reward logical coherence under 2D and 3D geometric constraints, implemented through the OT-GRPO reinforcement learning variant.
If this is right
- Label-free consistency training approaches the accuracy of models trained with ground-truth supervision.
- The method achieves comparable generalization across diverse tasks and data domains.
- Training targets the internal reasoning process directly without external annotations.
- Both image transformations such as flipping and textual transformations such as object swaps serve as effective consistency signals.
Where Pith is reading between the lines
- The work suggests that apparent deficits in model spatial abilities may often be alignment problems rather than missing knowledge.
- Similar consistency-based alignment could apply to other reasoning areas where transformations yield verifiable logical constraints.
- Adopting this approach might reduce dependence on external synthetic data generators for spatial tasks.
Load-bearing premise
Spatial reasoning capabilities are already present in pre-trained large reasoning models and can be aligned through logical coherence under geometric constraints.
What would settle it
If models trained with consistency verifiers show no accuracy gain over base models or fall measurably short of supervised baselines on held-out spatial reasoning tasks, the central claim would be falsified.
Figures

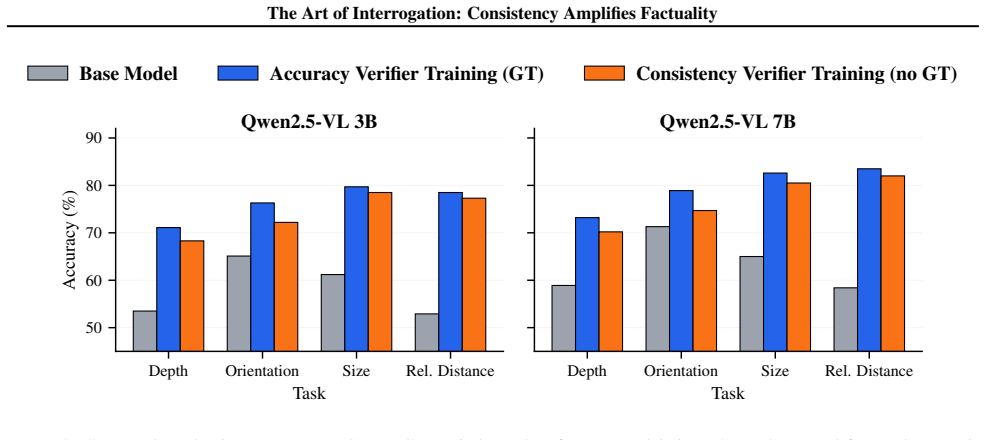


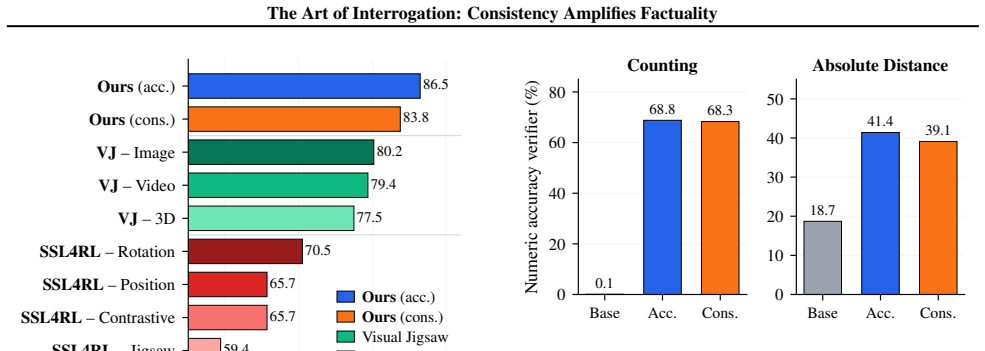














read the original abstract
Current Large Reasoning Models (LRMs) exhibit remarkable general capabilities but significantly underperform in spatial reasoning tasks. Existing approaches treat this gap as a knowledge deficit, relying on supervised fine-tuning (SFT) to ingest labeled spatial data from external vision sources or synthetic engines. In contrast, we argue that for many tasks, spatial reasoning capabilities are already present in pre-trained LRMs but require alignment through logical coherence under geometric 2D and 3D constraints. In this work, we propose a self-supervised reinforcement learning (RL) framework that targets the internal reasoning process without requiring ground-truth annotations. By formalizing the notion of consistency verifiers -- reward functions that check for geometric and semantic consistency under transformations -- we demonstrate that models can improve their spatial reasoning abilities. We use both image transformations, like flipping, and textual transformations, like swapping the order of objects in the question, and propose a new optimal transport-based RL strategy, OT-GRPO, which is a minimal-matching variant of group relative policy optimization tailored to pairwise verifiers. We show that this label-free consistency training approaches the accuracy of models trained with ground-truth supervision and achieves similar generalization across diverse tasks and data domains.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript argues that spatial reasoning capabilities are already latent in pre-trained Large Reasoning Models (LRMs) and can be aligned via a self-supervised RL framework. It introduces consistency verifiers (checking geometric/semantic coherence under transformations such as image flips and object swaps) and proposes OT-GRPO, a minimal-matching optimal-transport variant of group relative policy optimization. The central empirical claim is that this label-free approach approaches the accuracy of ground-truth supervised training while achieving comparable generalization across tasks and domains.
Significance. If the results and mechanism hold, the work would be significant for demonstrating a scalable, annotation-free route to improving spatial reasoning in LRMs and for formalizing consistency-based rewards in RL. The self-supervised design and OT-GRPO formulation are technical strengths that could generalize beyond the spatial setting. The paper receives credit for avoiding parameter fitting to the target metric and for focusing on internal reasoning coherence rather than external labels.
major comments (1)
- [Introduction and §4 (Experiments)] Introduction and §4 (Experiments): The load-bearing claim that 'spatial reasoning capabilities are already present in pre-trained LRMs but require alignment' is not distinguished from the alternative that the consistency verifiers simply supply an indirect reward signal that teaches new behavior. No independent probe (zero-shot performance on geometric subtasks, representation analysis, or pre-training consistency checks) is reported to test this. If models produce mutually consistent yet systematically incorrect answers under the chosen transformations, the training loop would reinforce errors rather than factuality, undermining the 'alignment of latent capability' interpretation.
minor comments (2)
- The abstract states performance claims without quantitative results, error bars, or experimental details; these must appear in the main text with clear baselines and statistical reporting to allow verification of the 'approaches supervised accuracy' statement.
- [§3 (Method)] §3 (Method): Provide the precise mathematical definition of the consistency verifiers and the OT-GRPO objective (including how the optimal transport matching is computed) so that the 'minimal-matching' property can be reproduced.
Simulated Author's Rebuttal
We thank the referee for this substantive comment on the central interpretive claim. We address the concern directly below and indicate where revisions will be made to strengthen the distinction between latent alignment and indirect teaching.
read point-by-point responses
-
Referee: [Introduction and §4 (Experiments)] Introduction and §4 (Experiments): The load-bearing claim that 'spatial reasoning capabilities are already present in pre-trained LRMs but require alignment' is not distinguished from the alternative that the consistency verifiers simply supply an indirect reward signal that teaches new behavior. No independent probe (zero-shot performance on geometric subtasks, representation analysis, or pre-training consistency checks) is reported to test this. If models produce mutually consistent yet systematically incorrect answers under the chosen transformations, the training loop would reinforce errors rather than factuality, undermining the 'alignment of latent capability' interpretation.
Authors: We agree that the manuscript does not report independent probes (zero-shot geometric subtasks, representation analysis, or pre-training consistency statistics) that would directly test the latent-capability hypothesis versus the alternative of the verifiers supplying a new reward signal. The current evidence is indirect: the label-free OT-GRPO procedure reaches accuracy levels statistically indistinguishable from ground-truth supervised training on held-out tasks and domains. If the verifiers were systematically reinforcing consistent-but-incorrect answers, we would not expect this convergence to supervised performance; the fact that it occurs suggests the consistency signal is selecting for factuality rather than arbitrary consistent errors. Nevertheless, we acknowledge this remains an inference rather than a direct test. We will revise the Introduction and add a dedicated paragraph in §4 (and the Discussion) that (a) explicitly states the alternative interpretation, (b) notes the absence of the suggested probes as a limitation, and (c) argues that the cross-task and cross-domain generalization results are more consistent with alignment than with de-novo learning. No new experiments will be added at this stage. revision: partial
Circularity Check
No significant circularity detected; derivation is self-contained.
full rationale
The paper presents a self-supervised RL framework that applies external geometric and textual transformations (image flips, object swaps) as consistency verifiers to improve spatial reasoning in pre-trained LRMs, with OT-GRPO as the optimization strategy. The claimed improvement is demonstrated empirically by comparing label-free training outcomes to ground-truth supervised baselines across tasks and domains, without any equation or step that reduces the reported accuracy gains to a fitted input, self-defined metric, or self-citation chain. The central premise that latent capabilities exist and require alignment is treated as a hypothesis tested via the method rather than presupposed by construction. No self-definitional, fitted-prediction, or uniqueness-imported patterns appear in the abstract or described approach.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption spatial reasoning capabilities are already present in pre-trained LRMs but require alignment through logical coherence under geometric 2D and 3D constraints
invented entities (2)
-
consistency verifiers
no independent evidence
-
OT-GRPO
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Be consistent! enhancing robust visual reasoning in LVLMs with consistency constraints
Anonymous. Be consistent! enhancing robust visual reasoning in LVLMs with consistency constraints. ICLR 2026 Conference Submission 6260, 2025. URL https://openreview.net/forum?id=REPLACE_WITH_ID
2026
-
[2]
Cycle consistency as reward: Learning image-text alignment without human preferences
Bahng, H., Chan, C., Durand, F., and Isola, P. Cycle consistency as reward: Learning image-text alignment without human preferences. 2025
2025
-
[3]
Tres observaciones sobre el \'a lgebra lineal
Birkhoff, G. Tres observaciones sobre el \'a lgebra lineal. Universidad Nacional de Tucum \'a n Revista Serie A , 5: 0 147--151, 1946
1946
-
[4]
Omni3D : A large benchmark and model for 3D object detection in the wild
Brazil, G., Straub, J., Ravi, N., Johnson, J., and Gkioxari, G. Omni3D : A large benchmark and model for 3D object detection in the wild. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp.\ 13154--13164, 2023
2023
-
[5]
Spatialbot: Precise spatial understanding with vision language models
Cai, W., Ponomarenko, Y., Yuan, J., Li, X., Yang, W., Dong, H., and Zhao, B. Spatialbot: Precise spatial understanding with vision language models. In 2025 IEEE International Conference on Robotics and Automation (ICRA), pp.\ 9490--9498. IEEE, 2025 a
2025
-
[6]
Holistic evaluation of multimodal llms on spatial intelligence
Cai, Z., Wang, Y., Sun, Q., Wang, R., Gu, C., Yin, W., Lin, Z., Yang, Z., Wei, C., Shi, X., Deng, K., Han, X., Chen, Z., Li, J., Fan, X., Deng, H., Lu, L., Li, B., Liu, Z., Wang, Q., Lin, D., and Yang, L. Holistic evaluation of multimodal llms on spatial intelligence. arXiv preprint arXiv:2508.13142, 2025 b
arXiv 2025
-
[7]
Spatialvlm: Endowing vision-language models with spatial reasoning capabilities
Chen, B., Xu, Z., Kirmani, S., Ichter, B., Driess, D., Florence, P., Sadigh, D., Guibas, L., and Xia, F. Spatialvlm: Endowing vision-language models with spatial reasoning capabilities. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp.\ 14455--14465, 2024 a
2024
-
[8]
Chen, J. et al. Sprite: Scaling spatial reasoning in mllms through programmatic data synthesis. arXiv preprint arXiv:2512.16237, 2024 b
arXiv 2024
-
[9]
Chen, W. et al. Space-10: A comprehensive benchmark for multimodal large language models in compositional spatial intelligence. arXiv preprint arXiv:2506.07966, 2025 a
arXiv 2025
-
[10]
On the mechanism of reasoning pattern selection in reinforcement learning for language models
Chen, X., Li, T., and Zou, D. On the mechanism of reasoning pattern selection in reinforcement learning for language models. arXiv preprint arXiv:2506.04695, 2025 b
arXiv 2025
-
[11]
Spatialrgpt: Grounded spatial reasoning in vision-language models
Cheng, A.-C., Yin, H., Fu, Y., Guo, Q., Yang, R., Kautz, J., Wang, X., and Molchanov, P. Spatialrgpt: Grounded spatial reasoning in vision-language models. In Advances in Neural Information Processing Systems, volume 37, 2024
2024
-
[12]
Cast: Cross-modal alignment similarity test for vision language models
Dagan, G., Loginova, O., and Batra, A. Cast: Cross-modal alignment similarity test for vision language models. In Proceedings of the 31st International Conference on Computational Linguistics, pp.\ 1387--1402, 2025
2025
-
[13]
Danskin, J. M. The Theory of Max-Min and its Application to Weapons Allocation Problems. Springer, Berlin, 1966
1966
-
[14]
Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning, 2025
DeepSeek-AI. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning, 2025. URL https://arxiv.org/abs/2501.12948
Pith/arXiv arXiv 2025
-
[15]
Z., Boisbunon, A., Chambon, S., Chapel, L., Corenflos, A., Fatras, K., Fournier, N., Gautheron, L., Gayraud, N
Flamary, R., Courty, N., Gramfort, A., Alaya, M. Z., Boisbunon, A., Chambon, S., Chapel, L., Corenflos, A., Fatras, K., Fournier, N., Gautheron, L., Gayraud, N. T., Janati, H., Rakotomamonjy, A., Redko, I., Rolet, A., Schutz, A., Seguy, V., Sutherland, D. J., Tavenard, R., Tong, A., and Vayer, T. POT : P ython O ptimal T ransport. Journal of Machine Learn...
2021
-
[16]
Are we ready for autonomous driving? T he KITTI vision benchmark suite
Geiger, A., Lenz, P., and Urtasun, R. Are we ready for autonomous driving? T he KITTI vision benchmark suite. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp.\ 3354--3361, 2012
2012
-
[17]
Guo, D., Yang, D., Zhang, H., Song, J., Wang, P., Zhu, Q., Xu, R., Zhang, R., Ma, S., Bi, X., Zhang, X., Yu, X., Wu, Y., Wu, Z. F., Gou, Z., Shao, Z., Li, Z., Gao, Z., Liu, A., Xue, B., Wang, B., Wu, B., Feng, B., Lu, C., Zhao, C., Deng, C., Ruan, C., Dai, D., Chen, D., Ji, D., Li, E., Lin, F., Dai, F., Luo, F., Hao, G., Chen, G., Li, G., Zhang, H., Xu, H...
-
[18]
Guo, X., Zhou, R., Wang, Y., Zhang, Q., Zhang, C., Jegelka, S., Wang, X., Chai, J., Yin, G., Lin, W., and Wang, Y. SSL4RL : Revisiting self-supervised learning as intrinsic reward for visual-language reasoning, 2025 b . URL https://arxiv.org/abs/2510.16416
Pith/arXiv arXiv 2025
-
[19]
J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., and Chen, W
Hu, E. J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., and Chen, W. Lora: Low-rank adaptation of large language models, 2021. URL https://arxiv.org/abs/2106.09685
Pith/arXiv arXiv 2021
-
[20]
Marble: A hard benchmark for multimodal spatial reasoning and planning
Jiang, Y., Chai, Y., Brbi \'c , M., and Moor, M. Marble: A hard benchmark for multimodal spatial reasoning and planning. arXiv preprint arXiv:2506.22992, 2025
arXiv 2025
-
[21]
Spatial R easoner: Towards explicit and generalizable 3d spatial reasoning, 2025
Ma, W., Chou, Y.-C., Liu, Q., Wang, X., de Melo, C., Xie, J., and Yuille, A. Spatial R easoner: Towards explicit and generalizable 3d spatial reasoning, 2025. URL https://arxiv.org/abs/2504.20024
arXiv 2025
-
[22]
and Cuturi, M
Peyr \'e , G. and Cuturi, M. Computational optimal transport: With applications to data science. Foundations and Trends in Machine Learning, 11 0 (5-6): 0 355--607, 2019
2019
-
[23]
Optimal Transport for Applied Mathematicians: Calculus of Variations, PDEs, and Modeling
Santambrogio, F. Optimal Transport for Applied Mathematicians: Calculus of Variations, PDEs, and Modeling. Birkh \"a user, Cham, 2015
2015
-
[24]
P., and Xiao, J
Song, S., Lichtenberg, S. P., and Xiao, J. SUN RGB-D : A RGB-D scene understanding benchmark suite. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp.\ 567--576, 2015
2015
-
[25]
Stogiannidis, I., McDonagh, S., and Tsaftaris, S. A. Mind the gap: Benchmarking spatial reasoning in vision-language models. arXiv preprint arXiv:2503.19707, 2025
arXiv 2025
-
[26]
Winoground: Probing vision and language models for visio-linguistic compositionality
Thrush, T., Jiang, R., Bartolo, M., Singh, A., Williams, A., Kiela, D., and Ross, C. Winoground: Probing vision and language models for visio-linguistic compositionality. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp.\ 5238--5248, 2022
2022
-
[27]
Equivariant similarity for vision-language foundation models
Wang, T., Lin, K., Li, L., Lin, C.-C., Yang, Z., Zhang, H., Liu, Z., and Wang, L. Equivariant similarity for vision-language foundation models. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pp.\ 11998--12008, 2023
2023
-
[28]
Wang, X., Jabri, A., and Efros, A. A. Learning correspondence from the cycle-consistency of time. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp.\ 2566--2576, 2019
2019
-
[29]
Self-consistency improves chain of thought reasoning in language models
Wang, X., Wei, J., Schuurmans, D., Le, Q., Chi, E., Narang, S., Chowdhery, A., and Zhou, D. Self-consistency improves chain of thought reasoning in language models. arXiv preprint arXiv:2203.11171, 2022
Pith/arXiv arXiv 2022
-
[30]
Chain-of-thought prompting elicits reasoning in large language models, 2023
Wei, J., Wang, X., Schuurmans, D., Bosma, M., Ichter, B., Xia, F., Chi, E., Le, Q., and Zhou, D. Chain-of-thought prompting elicits reasoning in large language models, 2023. URL https://arxiv.org/abs/2201.11903
Pith/arXiv arXiv 2023
-
[31]
Visual jigsaw post-training improves mllms, 2025
Wu, P., Zhang, Y., Diao, H., Li, B., Lu, L., and Liu, Z. Visual jigsaw post-training improves mllms, 2025. URL https://arxiv.org/abs/2509.25190
arXiv 2025
-
[32]
How far are VLM s from visual spatial intelligence? A benchmark-driven perspective
Yu, S., Chen, Y., Ju, H., Jia, L., Zhang, F., Huang, S., Wu, Y., Cui, R., Ran, B., Zhang, Z., et al. How far are VLM s from visual spatial intelligence? A benchmark-driven perspective. arXiv preprint arXiv:2509.18905, 2025
arXiv 2025
-
[33]
Yue, Y., Chen, Z., Lu, R., Zhao, A., Wang, Z., Song, S., and Huang, G. Does reinforcement learning really incentivize reasoning capacity in llms beyond the base model? arXiv preprint arXiv:2504.13837, 2025
Pith/arXiv arXiv 2025
-
[34]
Unveiling the tapestry of consistency in large vision-language models
Zhang, Y., Xiao, F., Huang, T., Fan, C.-K., Dong, H., Li, J., Wang, J., Cheng, K., Zhang, S., and Guo, H. Unveiling the tapestry of consistency in large vision-language models. Advances in Neural Information Processing Systems, 37: 0 118632--118653, 2024
2024
-
[35]
Co-rewarding: Stable self-supervised rl for eliciting reasoning in large language models
Zhang, Z., Zhu, J., Ge, X., Zhao, Z., Zhou, Z., Li, X., Feng, X., Yao, J., and Han, B. Co-rewarding: Stable self-supervised rl for eliciting reasoning in large language models. arXiv preprint arXiv:2508.00410, 2025
arXiv 2025
-
[36]
Learning to reason without external rewards, 2025
Zhao, X., Kang, Z., Feng, A., Levine, S., and Song, D. Learning to reason without external rewards, 2025. URL https://arxiv.org/abs/2505.19590
Pith/arXiv arXiv 2025
-
[37]
Zhou, T., Krahenbuhl, P., Aubry, M., Huang, Q., and Efros, A. A. Learning dense correspondence via 3d-guided cycle consistency. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp.\ 117--126, 2016
2016
-
[38]
Zhu, J.-Y., Park, T., Isola, P., and Efros, A. A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE international conference on computer vision, pp.\ 2223--2232, 2017
2017
-
[39]
Ttrl: Test-time reinforcement learning, 2025
Zuo, Y., Zhang, K., Sheng, L., Qu, S., Cui, G., Zhu, X., Li, H., Zhang, Y., Long, X., Hua, E., Qi, B., Sun, Y., Ma, Z., Yuan, L., Ding, N., and Zhou, B. Ttrl: Test-time reinforcement learning, 2025. URL https://arxiv.org/abs/2504.16084
Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.