Treatment Response Optimized Clinical Decision Support AI System via Digital Twin Simulation
Pith reviewed 2026-06-27 01:40 UTC · model grok-4.3
The pith
The AI framework using digital twins and reinforcement learning recommends treatments with greater effectiveness and stability than standard baselines in both simulations and real ovarian cancer data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The framework integrates treatment effect estimation, patient digital twin simulation, and reinforcement learning into a continuous learning loop that outperforms standard baselines in recommending treatments, while a rule-based module ensures safety by monitoring vital signs and blocking contraindicated options, with model disagreements routed to clinician review.
What carries the argument
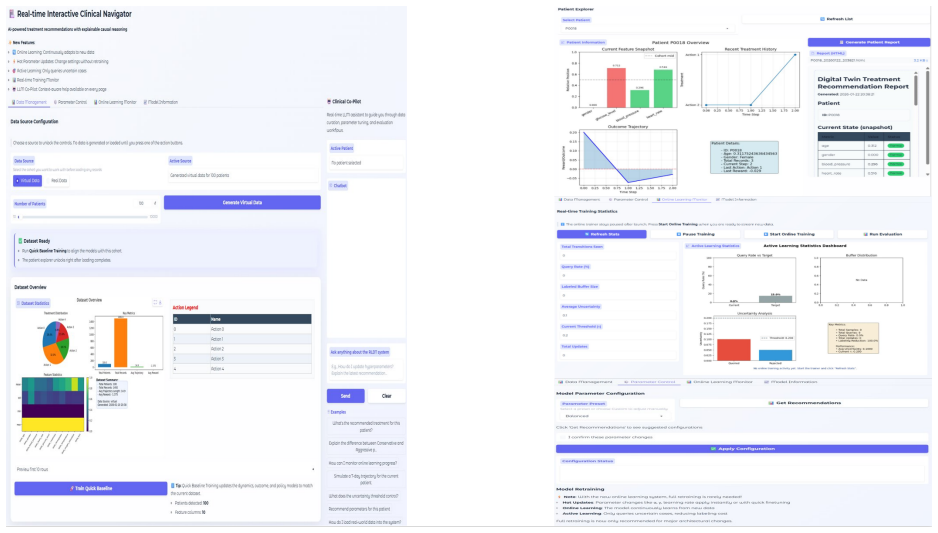
The patient Digital Twin that simulates treatment trajectories, combined with reinforcement learning for decision-making and a rule-based safety module.
Load-bearing premise
The patient digital twin accurately simulates individual treatment trajectories and the rule-based safety module blocks contraindicated treatments without unduly restricting beneficial options.
What would settle it
A prospective clinical study showing that following the AI recommendations produces worse patient survival rates or higher complication rates than standard care would disprove the claimed superiority.
Figures


read the original abstract
Clinical decision support AI systems (CDSASs) must adapt to evolving patient conditions in real-time while adhering to strict safety constraints. We present an online adaptive framework that integrates Treatment Effect (TE) estimation to quantify clinical benefits, a patient Digital Twin (DT) to simulate treatment trajectories, and Reinforcement Learning (RL) for sequential decision-making. The AI system is initially trained on historical medical records and operates in a continuous learning loop. To ensure safety, a rule-based module monitors vital signs and blocks contraindicated treatments. Cases with strong internal model disagreement are flagged for clinician review, simulated in our experiments via a pre-trained outcome model. We validate our framework using both a synthetic clinical simulator and a real-world ovarian cancer dataset from The Cancer Genome Atlas (TCGA). In both simulated and clinical settings, our method demonstrated superior effectiveness and stability in recommending treatments compared to standard computational baselines. Furthermore, the AI system maintains low latency and requires expert consultation for only a minority of cases in our experimental validation, demonstrating its potential as a safe, clinician-supervised tool for personalized medicine that continuously improves through practical use.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents an online adaptive framework for clinical decision support AI that integrates treatment effect estimation, patient digital twin simulation of treatment trajectories, reinforcement learning for sequential decisions, and a rule-based safety module to block contraindicated treatments while flagging disagreements for clinician review. It reports validation on a synthetic clinical simulator and the TCGA ovarian cancer dataset, claiming superior effectiveness and stability over standard computational baselines, low latency, and limited expert consultation needs.
Significance. If the digital twin is shown to accurately model individual trajectories and the experimental comparisons include proper controls and metrics, the framework could advance safe, continuously learning personalized medicine tools. The combination of TE estimation, DT, RL, and safety rules addresses real clinical needs for adaptability and oversight, but the absence of supporting details prevents assessing whether these strengths are realized.
major comments (3)
- [Abstract] Abstract: The central claim of 'superior effectiveness and stability in recommending treatments compared to standard computational baselines' in both simulated and clinical settings provides no quantitative metrics, statistical tests, baseline definitions, or controls, preventing verification of the result.
- [Validation] Validation section (implied by abstract): The patient digital twin is assumed to accurately simulate individual treatment trajectories from TCGA data, but TCGA consists of static genomic snapshots rather than dense longitudinal treatment-response sequences; no construction details, calibration procedure, or held-out prediction error metrics (e.g., on response or survival) are reported.
- [Experiments] Experiments (implied by abstract): Superiority claims depend on the DT fidelity and the rule-based safety module not unduly restricting options, yet no specifics are given on DT implementation, RL algorithm, how baselines are defined, or quantitative evaluation of safety module impact.
minor comments (1)
- [Abstract] Abstract: The phrase 'standard computational baselines' is undefined; explicit identification of the compared methods would aid clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting areas where additional clarity and detail are needed. We will revise the manuscript to address each point, expanding the abstract, adding a dedicated validation subsection on the digital twin, and providing full experimental specifications. These changes will strengthen the paper without altering its core contributions.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim of 'superior effectiveness and stability in recommending treatments compared to standard computational baselines' in both simulated and clinical settings provides no quantitative metrics, statistical tests, baseline definitions, or controls, preventing verification of the result.
Authors: We agree the abstract is insufficiently specific. In revision we will replace the general claim with concrete metrics drawn from the experimental results (e.g., mean cumulative reward, success rate, stability measured by variance across runs), include statistical significance tests against baselines, explicitly name the baselines (standard RL, TE-only, rule-based), and note the evaluation controls used in both the synthetic simulator and TCGA setting. revision: yes
-
Referee: [Validation] Validation section (implied by abstract): The patient digital twin is assumed to accurately simulate individual treatment trajectories from TCGA data, but TCGA consists of static genomic snapshots rather than dense longitudinal treatment-response sequences; no construction details, calibration procedure, or held-out prediction error metrics (e.g., on response or survival) are reported.
Authors: The observation that TCGA supplies static rather than longitudinal records is correct. Our digital twin initializes patient states from TCGA genomic profiles and generates trajectories via the learned treatment-effect model combined with a dynamics simulator; however, the current manuscript omits the precise construction steps. We will add a new subsection detailing (1) how genomic features seed the twin, (2) the calibration procedure that incorporates any available response data and domain knowledge, and (3) held-out prediction error results for both treatment response and survival endpoints to quantify fidelity. revision: yes
-
Referee: [Experiments] Experiments (implied by abstract): Superiority claims depend on the DT fidelity and the rule-based safety module not unduly restricting options, yet no specifics are given on DT implementation, RL algorithm, how baselines are defined, or quantitative evaluation of safety module impact.
Authors: We will expand the Experiments section to supply the missing implementation details: full DT architecture and simulation parameters, the exact RL algorithm (including network architecture, hyperparameters, and training procedure), explicit definitions of every baseline, and quantitative results on the safety module (fraction of treatments blocked, change in performance metrics when the module is ablated). These additions will allow direct assessment of whether the safety constraints unduly limit options. revision: yes
Circularity Check
No derivation chain present; claims are empirical only
full rationale
The paper describes an integrated CDSAS framework combining TE estimation, digital twin simulation, and RL for sequential decisions, with a rule-based safety module, validated experimentally on a synthetic simulator and TCGA ovarian cancer data. No equations, first-principles derivations, or mathematical predictions are supplied in the manuscript. Superiority and stability claims rest solely on reported experimental comparisons rather than any chain that reduces by construction to fitted inputs or self-citations. The work is therefore self-contained against external benchmarks with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
R. S. Sutton, A. G. Bartoet al.,Reinforcement learning: An introduction. MIT press Cambridge, 1998, vol. 1, no. 1
1998
-
[2]
Offline reinforcement learning: Tutorial, review, and perspectives on open problems,
S. Levine, A. Kumar, G. Tucker, and J. Fu, “Offline reinforcement learning: Tutorial, review, and perspectives on open problems,” 2020
2020
-
[3]
Hernan and J
M. Hernan and J. Robins,Causal inference: What if chapman hall/crc, boca raton, 2020
2020
-
[4]
Digital twins in healthcare: Methodological challenges and op- portunities,
C. Meijer, H.-W. Uh, and S. El Bouhaddani, “Digital twins in healthcare: Methodological challenges and op- portunities,”Journal of personalized medicine, vol. 13, no. 10, p. 1522, 2023
2023
-
[5]
Relax: Reinforcement learning agent ex- plainer for arbitrary predictive models,
Z. Chen, F. Silvestri, J. Wang, H. Zhu, H. Ahn, and G. Tolomei, “Relax: Reinforcement learning agent ex- plainer for arbitrary predictive models,” inProceedings of the 31st ACM international conference on information & knowledge management, 2022, pp. 252–261
2022
-
[6]
Off-policy deep reinforcement learning without exploration,
S. Fujimoto, D. Meger, and D. Precup, “Off-policy deep reinforcement learning without exploration,” inInterna- tional conference on machine learning. PMLR, 2019, pp. 2052–2062
2019
-
[7]
Sim- ple and scalable predictive uncertainty estimation using deep ensembles,
B. Lakshminarayanan, A. Pritzel, and C. Blundell, “Sim- ple and scalable predictive uncertainty estimation using deep ensembles,” vol. 30, 2017
2017
-
[8]
Frog: Fair removal on graph,
Z. Chen, J. Cheng, H. Amiri, K. Nag, L. Lin, S. Liu, G. Tolomei, and X. Sun, “Frog: Fair removal on graph,” inProceedings of the 34th ACM International Confer- ence on Information and Knowledge Management, 2025, pp. 415–424
2025
-
[9]
Neuromoe: a transformer-based mixture-of- experts framework for multi-modal neurological disorder classification,
W. H. Raza, A. B. Shah, Y . Wen, Y . Shen, J. D. M. Lemus, M. C. Schiess, T. M. Ellmore, R. Hu, and X. Fu, “Neuromoe: a transformer-based mixture-of- experts framework for multi-modal neurological disorder classification,” in2025 47th Annual International Con- ference of the IEEE Engineering in Medicine and Biology Society (EMBC). IEEE, 2025, pp. 1–7
2025
-
[10]
A primer on reinforcement learning in medicine for clinicians,
P. Jayaraman, J. Desman, M. Sabounchi, G. N. Nadkarni, and A. Sakhuja, “A primer on reinforcement learning in medicine for clinicians,”NPJ Digital Medicine, vol. 7, no. 1, p. 337, 2024
2024
-
[11]
Active learning for convolu- tional neural networks: A core-set approach,
O. Sener and S. Savarese, “Active learning for convolu- tional neural networks: A core-set approach,” 2017
2017
-
[12]
Integrated genomic analyses of ovarian carcinoma,
C. G. A. R. Networket al., “Integrated genomic analyses of ovarian carcinoma,”Nature, vol. 474, no. 7353, p. 609, 2011
2011
-
[13]
A. Thuy and D. F. Benoit, “Reliable uncertainty with cheaper neural network ensembles: a case study in industrial parts classification,”arXiv preprint arXiv:2403.10182, 2024
arXiv 2024
-
[14]
Guidance regarding methods for de-identification of protected health information in accordance with the health insurance portability and accountability act (hipaa) privacy rule,
I. Portability and A. Act, “Guidance regarding methods for de-identification of protected health information in accordance with the health insurance portability and accountability act (hipaa) privacy rule,”Human Health Services: Washington, DC, USA, 2012
2012
-
[15]
Do transformers always win? an empirical study of semantic embeddings for short-text e-commerce reviews,
L. Lai, Z. Cheng, K. Cheng, and X. Qi, “Do transformers always win? an empirical study of semantic embeddings for short-text e-commerce reviews,” in2026 9th Inter- national Symposium on Big Data and Applied Statistics (ISBDAS). IEEE, 2026, pp. 525–529
2026
-
[16]
Openai api documentation,
OpenAI, “Openai api documentation,” https://platform. openai.com/docs/, 2024, accessed: 2025-08-18
2024
-
[17]
Cure: Circuit-aware unlearn- ing for llm-based recommendation,
Z. Chen, J. Cheng, Z. Fan, H. Amiri, Y . Yao, X. Sun, and Y . Zhang, “Cure: Circuit-aware unlearn- ing for llm-based recommendation,”arXiv preprint arXiv:2604.04982, 2026
Pith/arXiv arXiv 2026
-
[18]
Task- specific efficiency analysis: When small language mod- els outperform large language models,
J. Cao, Y . Ma, X. Li, Q. Ren, and X. Chen, “Task- specific efficiency analysis: When small language mod- els outperform large language models,”arXiv preprint arXiv:2603.21389, 2026
arXiv 2026
-
[19]
Human-level control through deep reinforcement learning,
V . Mnih, K. Kavukcuoglu, D. Silver, A. A. Rusu, J. Ve- ness, M. G. Bellemare, A. Graves, M. Riedmiller, A. K. Fidjeland, G. Ostrovskiet al., “Human-level control through deep reinforcement learning,”nature, vol. 518, no. 7540, pp. 529–533, 2015
2015
-
[20]
Deep reinforce- ment learning with double q-learning,
H. Van Hasselt, A. Guez, and D. Silver, “Deep reinforce- ment learning with double q-learning,” inProceedings of the AAAI conference on artificial intelligence, vol. 30, no. 1, 2016
2016
-
[21]
Neural fitted q iteration–first experi- ences with a data efficient neural reinforcement learning method,
M. Riedmiller, “Neural fitted q iteration–first experi- ences with a data efficient neural reinforcement learning method,” inEuropean conference on machine learning. Springer, 2005, pp. 317–328
2005
-
[22]
Conservative q-learning for offline reinforcement learning,
A. Kumar, A. Zhou, G. Tucker, and S. Levine, “Conservative q-learning for offline reinforcement learning,” inNeurIPS, 2020. [On- line]. Available: https://papers.nips.cc/paper/2020/hash/ 0d2b2061826a5df3221116a5085a6052-Abstract.html
2020
-
[23]
Explainability for artificial intel- ligence in healthcare: a multidisciplinary perspective,
J. Amann, A. Blasimme, E. Vayena, D. Frey, V . I. Madai, and P. Consortium, “Explainability for artificial intel- ligence in healthcare: a multidisciplinary perspective,” BMC medical informatics and decision making, vol. 20, no. 1, p. 310, 2020
2020
-
[24]
What clinicians want: contextualizing explain- able machine learning for clinical end use,
S. Tonekaboni, S. Joshi, M. D. McCradden, and A. Gold- enberg, “What clinicians want: contextualizing explain- able machine learning for clinical end use,” inMachine learning for healthcare conference. PMLR, 2019, pp. 359–380
2019
-
[25]
Clinical decision support in the era of artificial intelligence,
E. H. Shortliffe and M. J. Sep ´ulveda, “Clinical decision support in the era of artificial intelligence,”Jama, vol. 320, no. 21, pp. 2199–2200, 2018
2018
-
[26]
Artificial intelli- gence and clinical decision support: clinicians’ perspec- tives on trust, trustworthiness, and liability,
C. Jones, J. Thornton, and J. C. Wyatt, “Artificial intelli- gence and clinical decision support: clinicians’ perspec- tives on trust, trustworthiness, and liability,”Medical law review, vol. 31, no. 4, pp. 501–520, 2023
2023
-
[27]
Role of calibration in uncertainty-based referral for deep learn- ing,
R. Zhang, C. Gatsonis, and J. A. Steingrimsson, “Role of calibration in uncertainty-based referral for deep learn- ing,”Statistical methods in medical research, vol. 32, no. 5, pp. 927–943, 2023
2023
-
[28]
Shared decision making: a model for clinical practice,
G. Elwyn, D. Frosch, R. Thomson, N. Joseph-Williams, A. Lloyd, P. Kinnersley, E. Cording, D. Tomson, C. Dodd, S. Rollnicket al., “Shared decision making: a model for clinical practice,”Journal of general internal medicine, vol. 27, no. 10, pp. 1361–1367, 2012
2012
-
[29]
Automation bias: a systematic review of frequency, effect mediators, and mitigators,
K. Goddard, A. Roudsari, and J. C. Wyatt, “Automation bias: a systematic review of frequency, effect mediators, and mitigators,”Journal of the American Medical Infor- matics Association, vol. 19, no. 1, pp. 121–127, 2012
2012
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.