Object-Centric Residual RL for Zero-Shot Sim-to-Real VLA Enhancement
Pith reviewed 2026-06-26 21:04 UTC · model grok-4.3
The pith
An object-centric residual RL policy trained in simulation transfers zero-shot to raise real-world VLA success rates from 42% to 76%.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
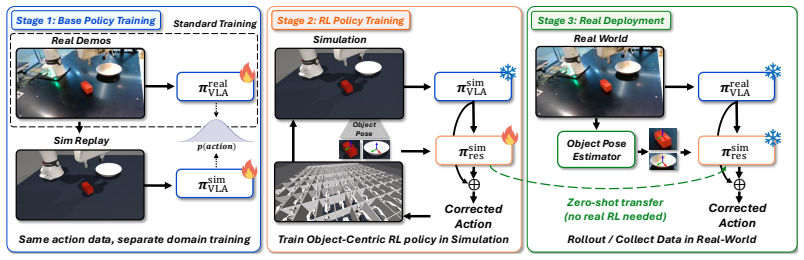
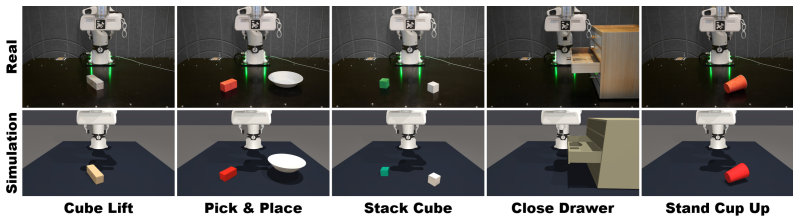
An object-centric residual RL policy trained in simulation on object poses after replaying real teleoperation data to align the sim VLA, with pose noise injection and dropout, transfers zero-shot to the real Franka robot and lifts success from 42% to 76% on five manipulation tasks while enabling self-improvement of the base model from the improved rollouts.
What carries the argument
Object-centric residual RL that refines VLA actions from object-pose observations in a compact space aligned between simulation and reality.
If this is right
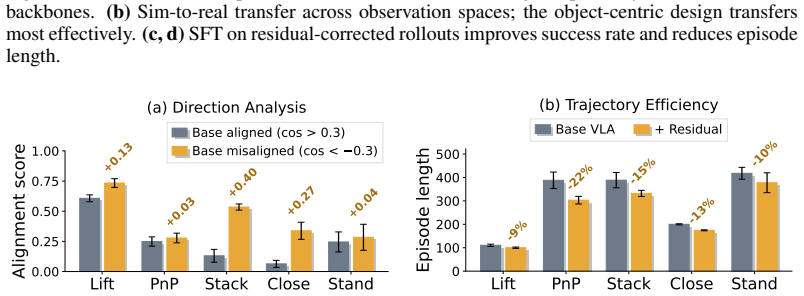
- Success rate on real hardware rises from 42% to 76% across five tasks with zero real-world training.
- Improved rollouts enable retraining the base VLA without collecting new teleoperation data.
- The approach sidesteps both privileged-state distillation and direct visual domain-gap bridging.
Where Pith is reading between the lines
- If reliable object-pose estimation is available, the method could extend to tasks where pure visual feedback lacks the precision needed for contact-rich actions.
- The self-improvement loop suggests repeated cycles of real rollouts feeding back into sim residual training could produce ongoing gains in VLA robustness.
Load-bearing premise
Replaying the same teleoperation demonstrations in simulation produces a sim VLA aligned enough with the real-world VLA that a pose-based residual policy trained with noise will transfer despite other domain differences.
What would settle it
Deploying the residual policy on the real robot and measuring no increase in success rate beyond the base VLA's 42% on the same five tasks.
Figures








read the original abstract
Vision-Language-Action (VLA) models can generalize across diverse manipulation tasks, but their imitation-learning-based policies remain brittle in precise physical interactions due to compounding execution errors; Can a reinforcement learning policy trained purely in simulation improve the robustness of real-world VLAs zero-shot? Residual RL, which learns a corrective policy on top of a frozen VLA, offers a natural framework, but existing approaches face a fundamental sim-to-real dilemma: privileged-state methods require lossy distillation for deployment; image-based methods suffer from the visual domain gap; and real-world RL is costly and unsafe. We propose an object-centric residual RL framework that refines VLA actions using object poses, enabling a compact observation space that transfers consistently between simulation and reality. To align the two domains, we additionally replay the same teleoperation demonstrations in simulation to train a sim counterpart of the real-world VLA. The residual RL policy is trained only in simulation with pose noise injection and dropout, and transfers zero-shot to the real robot. Across five manipulation tasks on a real Franka Research 3 (FR3) robot, our method improves the success rate from 42% to 76% zero-shot, and the improved rollouts can be further reused to retrain the base VLA for self-improvement without additional teleoperation. Project page: https://www.microsoft.com/en-us/research/articles/object-centric-residual-rl/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents an object-centric residual RL framework to enhance Vision-Language-Action (VLA) models for zero-shot sim-to-real transfer in robotic manipulation. By replaying teleoperation demonstrations in simulation to train a matching sim VLA, training a residual corrective policy on object-pose observations with noise injection and dropout, and deploying the residual on the real VLA, the approach claims to raise aggregate success from 42% to 76% across five tasks on a Franka Research 3 robot while enabling self-improvement of the base VLA from the improved rollouts.
Significance. If the sim-to-real VLA alignment holds, the method offers a practical route to robustify imitation-learned VLAs without real-world RL, privileged-state distillation, or image-domain adaptation. The object-centric observation space and the closed-loop self-improvement pathway are concrete strengths that could reduce reliance on teleoperation for iterative improvement.
major comments (2)
- [Abstract] Abstract and methods description: the zero-shot transfer claim rests on the unquantified assumption that the residual errors of the sim VLA (trained by replaying identical teleop trajectories) are sufficiently close to those of the real VLA once object poses are observed; no intermediate metrics (action KL divergence, per-timestep error histograms, or matched-pose success-rate gap between sim and real VLAs) are reported to support this alignment.
- [Experimental evaluation] Experimental evaluation: the reported aggregate improvement (42 % o 76 %) is presented without per-task trial counts, standard deviations, or statistical tests, leaving open the possibility that variability or task-specific confounds drive the result rather than the residual policy itself.
minor comments (1)
- [Abstract] The abstract opens with a rhetorical question; converting it to a declarative statement would align better with conventional abstract style.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and indicate revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract and methods description: the zero-shot transfer claim rests on the unquantified assumption that the residual errors of the sim VLA (trained by replaying identical teleop trajectories) are sufficiently close to those of the real VLA once object poses are observed; no intermediate metrics (action KL divergence, per-timestep error histograms, or matched-pose success-rate gap between sim and real VLAs) are reported to support this alignment.
Authors: We agree that explicit quantification of sim-real VLA alignment would better support the zero-shot claim. Replaying identical teleoperation trajectories in simulation is designed to produce matching error distributions when conditioned on object poses, which serve as the domain-invariant input. However, the original submission did not include the suggested intermediate metrics. In the revised manuscript we will add action KL divergence, per-timestep error histograms, and matched-pose success-rate gaps computed from the trained sim and real VLAs to directly demonstrate alignment. revision: yes
-
Referee: [Experimental evaluation] Experimental evaluation: the reported aggregate improvement (42 % to 76 %) is presented without per-task trial counts, standard deviations, or statistical tests, leaving open the possibility that variability or task-specific confounds drive the result rather than the residual policy itself.
Authors: We acknowledge that aggregate reporting alone leaves room for questions about variability. The original manuscript summarized results for conciseness, but the revised version will expand the experimental section to report per-task success rates, the number of trials conducted per task, standard deviations across repeated evaluations, and statistical significance tests (e.g., paired t-tests) comparing the base VLA against the residual-augmented policy. These additions will confirm consistency across tasks. revision: yes
Circularity Check
No circularity; empirical method validated by real-robot experiments
full rationale
The paper describes an empirical pipeline: replay teleop demos in sim to obtain a sim VLA, train an object-pose residual RL policy in sim with noise/dropout, then deploy the residual zero-shot on the real VLA. No equations, fitted parameters, or self-citations are presented as a derivation that reduces to its own inputs by construction. The reported 42%→76% improvement is an external benchmark measured on physical hardware, not a statistical renaming of training data. The sim-real alignment assumption is an unproven hypothesis whose validity is tested (or not) by the end-to-end outcome rather than being presupposed by definition.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
A. Brohan, N. Brown, J. Carbajal, Y . Chebotar, J. Dabis, C. Finn, et al. RT-1: Robotics transformer for real-world control at scale.arXiv preprint arXiv:2212.06817, 2023
Pith/arXiv arXiv 2023
-
[2]
A. Brohan, N. Brown, J. Carbajal, Y . Chebotar, X. Chen, K. Choromanski, et al. RT-2: Vision-language-action models transfer web knowledge to robotic control.arXiv preprint arXiv:2307.15818, 2023
Pith/arXiv arXiv 2023
-
[3]
Open X-Embodiment: Robotic learning datasets and RT-X models
Open X-Embodiment Collaboration et al. Open X-Embodiment: Robotic learning datasets and RT-X models. InIEEE International Conference on Robotics and Automation (ICRA), 2024
2024
-
[4]
Ghosh, H
Octo Model Team, D. Ghosh, H. Walke, K. Pertsch, et al. Octo: An open-source generalist robot policy. InRobotics: Science and Systems (RSS), 2024
2024
-
[5]
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, et al. OpenVLA: An open-source vision-language-action model. InConference on Robot Learning (CoRL), 2024
2024
-
[6]
K. Black, N. Brown, D. Driess, A. Esmail, M. Equi, C. Finn, et al.π 0: A vision-language- action flow model for general robot control.arXiv preprint arXiv:2410.24164, 2024
Pith/arXiv arXiv 2024
-
[7]
Physical Intelligence, K. Black, N. Brown, et al.π 0.5: a vision-language-action model with open-world generalization.arXiv preprint arXiv:2504.16054, 2025
Pith/arXiv arXiv 2025
-
[8]
NVIDIA, J. Bjorck, F. Casta ˜neda, N. Cherniadev, X. Da, R. Ding, L. Fan, et al. GR00T N1: An open foundation model for generalist humanoid robots.arXiv preprint arXiv:2503.14734, 2025
Pith/arXiv arXiv 2025
-
[9]
S. Ross, G. J. Gordon, and D. Bagnell. A reduction of imitation learning and structured pre- diction to no-regret online learning. InInternational Conference on Artificial Intelligence and Statistics (AISTATS), 2011
2011
-
[10]
T. Z. Zhao, V . Kumar, S. Levine, and C. Finn. Learning fine-grained bimanual manipulation with low-cost hardware. InRobotics: Science and Systems (RSS), 2023
2023
-
[11]
J. Ho, A. Jain, and P. Abbeel. Denoising diffusion probabilistic models. InAdvances in Neural Information Processing Systems (NeurIPS), volume 33, pages 6840–6851, 2020
2020
-
[12]
C. Chi, S. Feng, Y . Du, Z. Xu, E. Cousineau, B. Burchfiel, and S. Song. Diffusion policy: Visuomotor policy learning via action diffusion. InRobotics: Science and Systems (RSS), 2023
2023
-
[13]
Lipman, R
Y . Lipman, R. T. Q. Chen, H. Ben-Hamu, M. Nickel, and M. Le. Flow matching for generative modeling. InInternational Conference on Learning Representations (ICLR), 2023
2023
-
[14]
T. Silver, K. Allen, J. Tenenbaum, and L. Kaelbling. Residual policy learning.arXiv preprint arXiv:1812.06298, 2018
Pith/arXiv arXiv 2018
-
[15]
Johannink, S
T. Johannink, S. Bahl, A. Nair, J. Luo, A. Kumar, M. Loskyll, J. A. Ojea, E. Solowjow, and S. Levine. Residual reinforcement learning for robot control. InIEEE International Conference on Robotics and Automation (ICRA), 2019
2019
-
[16]
Ankile, A
L. Ankile, A. Simeonov, I. Shenfeld, M. Torne, and P. Agrawal. From imitation to refinement – residual rl for precise assembly. InConference on Robot Learning (CoRL), 2024
2024
- [17]
-
[18]
W. Xiao, H. Lin, A. Peng, H. Xue, T. He, Y . Xie, et al. Self-improving vision-language-action models with data generation via residual RL.arXiv preprint arXiv:2511.00091, 2025. 9
arXiv 2025
-
[19]
Dulac-Arnold, N
G. Dulac-Arnold, N. Levine, D. J. Mankowitz, J. Li, C. Paduraru, S. Gowal, and T. Hester. Challenges of real-world reinforcement learning: Definitions, benchmarks and analysis.Ma- chine Learning, 110:2419–2468, 2021
2021
-
[20]
B. Wen, W. Yang, J. Kautz, and S. Birchfield. FoundationPose: Unified 6D pose estimation and tracking of novel objects. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024
2024
-
[21]
N. Ravi, V . Gabeur, Y .-T. Hu, R. Hu, C. Ryali, T. Ma, et al. SAM 2: Segment anything in images and videos.arXiv preprint arXiv:2408.00714, 2024
Pith/arXiv arXiv 2024
-
[22]
Torne, A
M. Torne, A. Simeonov, Z. Li, A. Chan, T. Chen, A. Gupta, and P. Agrawal. Reconciling re- ality through simulation: A real-to-sim-to-real approach for robust manipulation. InRobotics: Science and Systems (RSS), 2024
2024
- [23]
-
[24]
W. Zhao, J. Pe ˜na Queralta, and T. Westerlund. Sim-to-real transfer in deep reinforcement learning for robotics: A survey.arXiv preprint arXiv:2009.13303, 2020
arXiv 2009
-
[25]
Tobin, R
J. Tobin, R. Fong, A. Ray, J. Schneider, W. Zaremba, and P. Abbeel. Domain randomization for transferring deep neural networks from simulation to the real world. InIEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2017
2017
-
[26]
X. B. Peng, M. Andrychowicz, W. Zaremba, and P. Abbeel. Sim-to-real transfer of robotic control with dynamics randomization.arXiv preprint arXiv:1710.06537, 2018
Pith/arXiv arXiv 2018
-
[27]
Handa, A
A. Handa, A. Allshire, V . Makoviychuk, A. Petrenko, R. Singh, J. Liu, et al. DeXtreme: Trans- fer of agile in-hand manipulation from simulation to reality. InIEEE International Conference on Robotics and Automation (ICRA), 2023
2023
-
[28]
Andrychowicz, B
OpenAI, M. Andrychowicz, B. Baker, M. Chociej, R. Jozefowicz, B. McGrew, J. Pachocki, et al. Learning dexterous in-hand manipulation.The International Journal of Robotics Re- search, 39(1):3–20, 2020
2020
-
[29]
Y . J. Ma, W. Liang, H.-J. Wang, S. Wang, Y . Zhu, L. Fan, O. Bastani, and D. Jayaraman. DrEureka: Language model guided sim-to-real transfer. InRobotics: Science and Systems (RSS), 2024
2024
-
[30]
Chebotar, A
Y . Chebotar, A. Handa, V . Makoviychuk, M. Macklin, J. Issac, N. Ratliff, and D. Fox. Closing the sim-to-real loop: Adapting simulation randomization with real world experience. InIEEE International Conference on Robotics and Automation (ICRA), 2019
2019
-
[31]
Ramos, R
F. Ramos, R. Possas, and D. Fox. BayesSim: Adaptive domain randomization via probabilistic inference for robotics simulators. InRobotics: Science and Systems (RSS), 2019
2019
-
[32]
Jiang, C
Y . Jiang, C. Wang, R. Zhang, J. Wu, and L. Fei-Fei. TRANSIC: Sim-to-real policy transfer by learning from online correction. InConference on Robot Learning (CoRL), 2024
2024
-
[33]
G. Hinton, O. Vinyals, and J. Dean. Distilling the knowledge in a neural network.arXiv preprint arXiv:1503.02531, 2015
Pith/arXiv arXiv 2015
-
[34]
Mandlekar, S
A. Mandlekar, S. Nasiriany, B. Wen, I. Akinola, Y . Narang, L. Fan, Y . Zhu, and D. Fox. MimicGen: A data generation system for scalable robot learning using human demonstrations. InConference on Robot Learning (CoRL), 2023
2023
-
[35]
Y . Ze, G. Zhang, K. Zhang, C. Hu, M. Wang, and H. Xu. 3D Diffusion Policy: Generalizable visuomotor policy learning via simple 3D representations. InRobotics: Science and Systems (RSS), 2024. 10
2024
-
[36]
T.-W. Ke, N. Gkanatsios, and K. Fragkiadaki. 3D Diffuser Actor: Policy diffusion with 3D scene representations. InConference on Robot Learning (CoRL), 2024
2024
-
[37]
D. Qu, H. Song, Q. Chen, Y . Yao, X. Ye, Y . Ding, et al. SpatialVLA: Exploring spatial representations for visual-language-action model.arXiv preprint arXiv:2501.15830, 2025
Pith/arXiv arXiv 2025
-
[38]
Fujimoto, H
S. Fujimoto, H. van Hoof, and D. Meger. Addressing function approximation error in actor- critic methods. InInternational Conference on Machine Learning (ICML), 2018
2018
-
[39]
Todorov, T
E. Todorov, T. Erez, and Y . Tassa. MuJoCo: A physics engine for model-based control. In IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2012
2012
-
[40]
Mandlekar, D
A. Mandlekar, D. Xu, J. Wong, S. Nasiriany, C. Wang, R. Kulkarni, L. Fei-Fei, S. Savarese, Y . Zhu, and R. Mart´ın-Mart´ın. What matters in learning from offline human demonstrations for robot manipulation. InConference on Robot Learning (CoRL), 2021
2021
-
[41]
Physical Intelligence et al.π ∗ 0.6: a VLA that learns from experience.arXiv preprint arXiv:2511.14759, 2025. 11 Appendix for: Object-Centric Residual RL for Zero-Shot Sim-to-Real VLA Enhancement A Appendix A.1 Reward Design All tasks use dense, shaped rewards clipped to[0,1]. Each reward is decomposed into staged sub- rewards that are applied progressive...
Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.