Nonlinear-Gain Distributed Zeroth-Order Optimization for Networked Black-Box Control
Pith reviewed 2026-06-29 21:07 UTC · model grok-4.3
The pith
A fractional-power powerball map applied locally to gradient estimates yields leading convergence rates for distributed zeroth-order optimization over networks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
ZOOM-PB preserves the known distributed zeroth-order convergence order while changing finite-time behavior through a local nonlinear control gain realized by a fractional-power powerball map on the estimated gradient; the map requires no extra transmitted states.
What carries the argument
The fractional-power powerball map acting as a nonlinear feedback gain on the estimated gradient.
If this is right
- The method attains the leading nonconvex stationarity rate without transmitting additional states beyond the usual local updates.
- Under the Polyak-Lojasiewicz condition the same mechanism produces the leading objective residual rate O(p/(nT)).
- Empirical runs on black-box learning and UAV source seeking exhibit faster convergence precisely in weak-signal regimes.
- The nonlinear gain replaces the need for primal-dual tracking or gradient-refinement steps used in prior distributed zeroth-order schemes.
Where Pith is reading between the lines
- The same local nonlinear gain could be paired with other coordinate-sampling patterns to target different communication topologies.
- Because the map is memoryless and local, it may extend directly to asynchronous or time-varying networks without redesigning the analysis.
- Testing the powerball exponent on problems whose flatness varies with dimension would reveal how the finite-time improvement scales with p.
Load-bearing premise
The stated rates hold only when the objective is smooth, the zeroth-order oracle has bounded variance, and the communication network remains connected.
What would settle it
Measure the stationarity gap after T iterations on a smooth nonconvex test function over an n-agent connected network; the gap should scale as sqrt(p/(nT)) when p, n, and T are varied while keeping other factors fixed.
Figures

read the original abstract
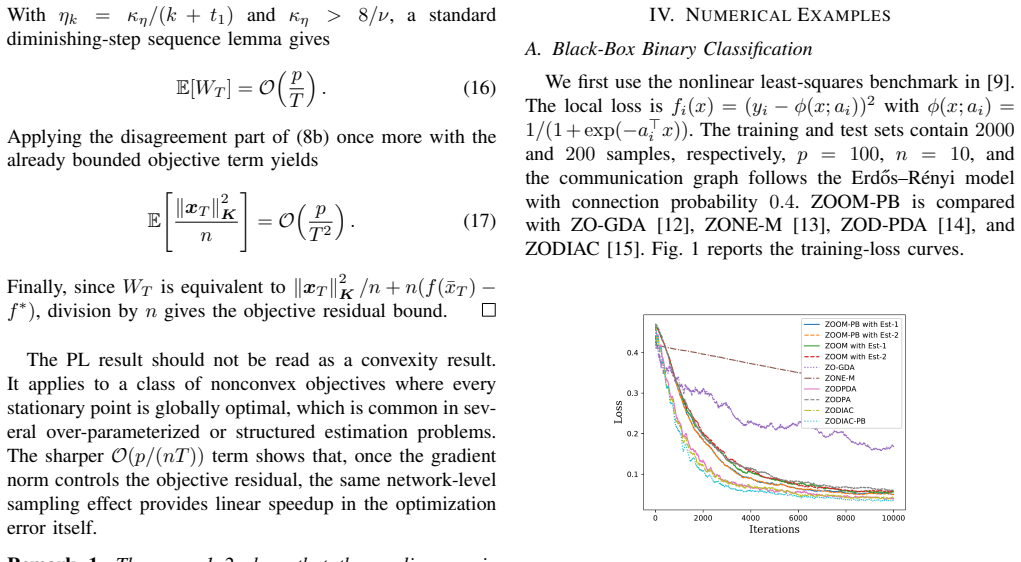
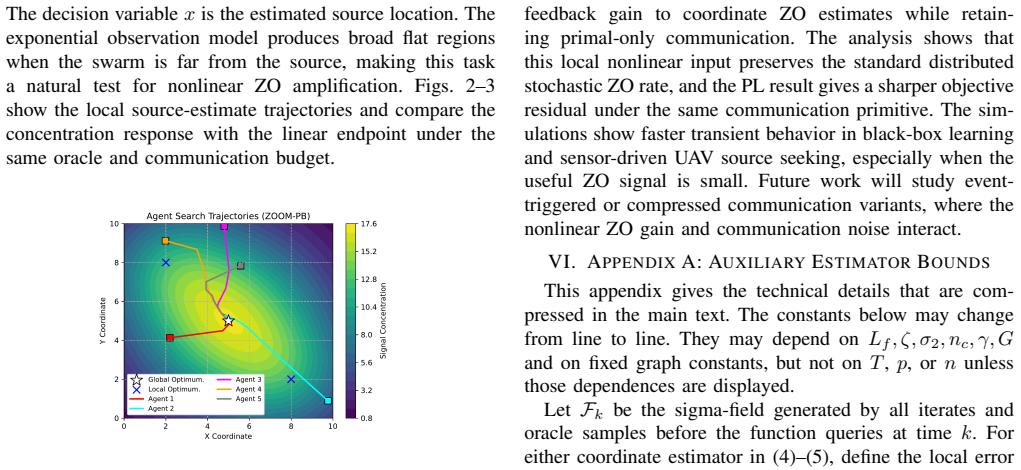
This letter studies distributed stochastic optimization over a peer-to-peer network when agents can query only zeroth-order function values. We propose ZOOM-PB, a coordinate-sampling distributed zeroth-order method equipped with a fractional-power powerball map. Unlike existing distributed zeroth-order methods that mainly refine gradient estimation or introduce primal--dual tracking, the proposed mechanism acts as a nonlinear feedback gain on the estimated gradient: it amplifies weak signals in flat regions and attenuates large stochastic estimates without adding transmitted states. Under standard smoothness, oracle-variance, and network-connectivity assumptions, ZOOM-PB achieves the leading nonconvex stationarity rate $\mathcal{O}(\sqrt{p/(nT)})$, where $p$ is the decision dimension, $n$ is the number of agents, and $T$ is the iteration horizon. Under the Polyak--{\L}ojasiewicz condition, it further attains the leading objective residual rate $\mathcal{O}(p/(nT))$. Thus the method preserves the known distributed ZO order while changing the finite-time behavior through a local nonlinear control gain. Simulations on black-box learning and sensor-driven UAV source seeking show faster empirical convergence in weak-signal regimes.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes ZOOM-PB, a coordinate-sampling distributed zeroth-order optimization method for peer-to-peer networks that applies a fractional-power powerball map as a local nonlinear gain to zeroth-order gradient estimates. The central claim is that, under standard smoothness, bounded oracle variance, and network connectivity assumptions, the algorithm attains the leading nonconvex stationarity rate O(sqrt(p/(nT))) and, under the Polyak-Lojasiewicz condition, the leading objective residual rate O(p/(nT)), while improving finite-time behavior in weak-signal regimes without additional transmitted states or altered assumptions. Simulations on black-box learning and sensor-driven UAV source seeking are included to demonstrate empirical gains.
Significance. If the rates are rigorously established without hidden parameter dependence in the powerball map, the work is significant for showing that a simple local nonlinear feedback can enhance practical convergence in distributed black-box settings while preserving optimal leading-order complexity from the coordinate ZO literature. The explicit preservation of known rates O(sqrt(p/(nT))) and O(p/(nT)) under standard assumptions, together with the focus on networked control applications, strengthens the contribution.
minor comments (2)
- The definition and properties (e.g., Lipschitz constant, range) of the fractional-power powerball map should be stated explicitly in the main text near its first introduction, rather than deferred entirely to an appendix, to allow readers to verify that it introduces no extra factors into the leading rate terms.
- In the simulation section, the choice of the power parameter in the powerball map and its sensitivity should be reported with at least one ablation plot or table entry, as this directly supports the claim of improved finite-time behavior.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of the manuscript, the recognition of its significance in preserving leading rates while improving finite-time behavior via local nonlinear gain, and the recommendation for minor revision. No specific major comments were raised in the report.
Circularity Check
No significant circularity detected in derivation chain
full rationale
The paper presents ZOOM-PB as a coordinate-sampling distributed zeroth-order method with a local fractional-power powerball map acting as nonlinear gain. Convergence rates O(sqrt(p/(nT))) (nonconvex stationarity) and O(p/(nT)) (PL residual) are stated to follow directly from standard smoothness, bounded oracle variance, and network connectivity assumptions, matching known orders for distributed coordinate ZO methods without altering the leading term. No equations or steps in the provided abstract or description reduce a claimed prediction to a fitted input by construction, invoke self-citations as load-bearing uniqueness theorems, or smuggle ansatzes via prior author work. The central claim remains independent of the paper's own fitted quantities or self-referential definitions, qualifying as a normal non-circular theoretical derivation under external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard smoothness, oracle-variance, and network-connectivity assumptions hold.
invented entities (1)
-
fractional-power powerball map
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Cooperative source seeking via networked multi-vehicle systems,
Z. Li, K. You, and S. Song, “Cooperative source seeking via networked multi-vehicle systems,”Automatica, vol. 115, p. 108853, 2020
2020
-
[2]
J. C. Spall,Introduction to stochastic search and optimization: esti- mation, simulation, and control. John Wiley & Sons, 2005, vol. 65
2005
-
[3]
A. R. Conn, K. Scheinberg, and L. N. Vicente,Introduction to Derivative-Free Optimization. MPS-SIAM Series on Optimization. SIAM Philadelphia, 2009
2009
-
[4]
Audet and W
C. Audet and W. Hare,Derivative-Free and Blackbox Optimization. Springer, 2017
2017
-
[5]
Derivative-free optimiza- tion methods,
J. Larson, M. Menickelly, and S. M. Wild, “Derivative-free optimiza- tion methods,”Acta Numerica, vol. 28, pp. 287–404, 2019
2019
-
[6]
Stochastic first-and zeroth-order methods for nonconvex stochastic programming,
S. Ghadimi and G. Lan, “Stochastic first-and zeroth-order methods for nonconvex stochastic programming,”SIAM Journal on Optimization, vol. 23, no. 4, pp. 2341–2368, 2013
2013
-
[7]
A compre- hensive linear speedup analysis for asynchronous stochastic parallel optimization from zeroth-order to first-order,
X. Lian, H. Zhang, C.-J. Hsieh, Y . Huang, and J. Liu, “A compre- hensive linear speedup analysis for asynchronous stochastic parallel optimization from zeroth-order to first-order,” inAdvances in Neural Information Processing Systems, 2016, pp. 3054–3062
2016
-
[8]
Random gradient-free minimization of convex functions,
Y . Nesterov and V . Spokoiny, “Random gradient-free minimization of convex functions,”Foundations of Computational Mathematics, vol. 17, no. 2, pp. 527–566, 2017
2017
-
[9]
Zeroth-order stochastic variance reduction for nonconvex optimiza- tion,
S. Liu, B. Kailkhura, P.-Y . Chen, P. Ting, S. Chang, and L. Amini, “Zeroth-order stochastic variance reduction for nonconvex optimiza- tion,” inAdvances in Neural Information Processing Systems, 2018, pp. 3727–3737
2018
-
[10]
Randomized gradient-free method for multia- gent optimization over time-varying networks,
D. Yuan and D. W. Ho, “Randomized gradient-free method for multia- gent optimization over time-varying networks,”IEEE Transactions on Neural Networks and Learning Systems, vol. 26, no. 6, pp. 1342–1347, 2014
2014
-
[11]
Gradient-free method for distributed multi- agent optimization via push-sum algorithms,
D. Yuan, S. Xu, and J. Lu, “Gradient-free method for distributed multi- agent optimization via push-sum algorithms,”International Journal of Robust and Nonlinear Control, vol. 25, no. 10, pp. 1569–1580, 2015
2015
-
[12]
Distributed zero-order algorithms for nonconvex multiagent optimization,
Y . Tang, J. Zhang, and N. Li, “Distributed zero-order algorithms for nonconvex multiagent optimization,”IEEE Transactions on Control of Network Systems, vol. 8, no. 1, pp. 269–281, 2020
2020
-
[13]
ZONE: Zeroth-order non- convex multiagent optimization over networks,
D. Hajinezhad, M. Hong, and A. Garcia, “ZONE: Zeroth-order non- convex multiagent optimization over networks,”IEEE Transactions on Automatic Control, vol. 64, no. 10, pp. 3995–4010, 2019
2019
-
[14]
Zeroth-order algo- rithms for stochastic distributed nonconvex optimization,
X. Yi, S. Zhang, T. Yang, and K. H. Johansson, “Zeroth-order algo- rithms for stochastic distributed nonconvex optimization,”Automatica, vol. 142, p. 110353, 2022
2022
-
[15]
Con- vergence analysis of nonconvex distributed stochastic zeroth-order coordinate method,
S. Zhang, Y . Dong, D. Xie, L. Yao, C. P. Bailey, and S. Fu, “Con- vergence analysis of nonconvex distributed stochastic zeroth-order coordinate method,” inIEEE Conference on Decision and Control, 2021
2021
-
[16]
Zeroth-order feedback optimization for cooperative multi-agent systems,
Y . Tang, Z. Ren, and N. Li, “Zeroth-order feedback optimization for cooperative multi-agent systems,”Automatica, vol. 148, p. 110741, 2023
2023
-
[17]
On the powerball method: Variants of descent methods for accelerated optimization,
Y . Yuan, M. Li, J. Liu, and C. Tomlin, “On the powerball method: Variants of descent methods for accelerated optimization,”IEEE Control Systems Letters, vol. 3, no. 3, pp. 601–606, 2019
2019
-
[18]
Accelerated zeroth-order algorithm for stochastic distributed non-convex optimization,
S. Zhang and C. P. Bailey, “Accelerated zeroth-order algorithm for stochastic distributed non-convex optimization,” in2022 American Control Conference (ACC). IEEE, 2022, pp. 4274–4279
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.