LEAP: Trajectory-Level Evaluation of LLMs in Iterative Scientific Design
Pith reviewed 2026-05-19 15:45 UTC · model grok-4.3
pith:TB66XJQX Add to your LaTeX paper
What is a Pith Number?\usepackage{pith}
\pithnumber{TB66XJQX}
Prints a linked pith:TB66XJQX badge after your title and writes the identifier into PDF metadata. Compiles on arXiv with no extra files. Learn more
The pith
Trajectory scoring changes which LLMs rank best at iterative scientific design and shows they fall short of Bayesian optimization.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
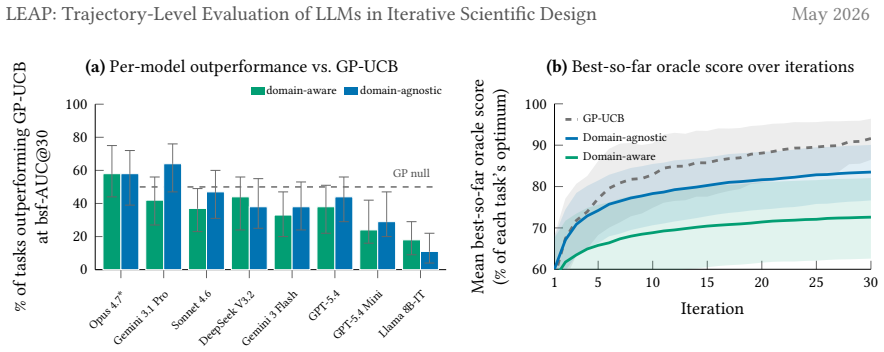
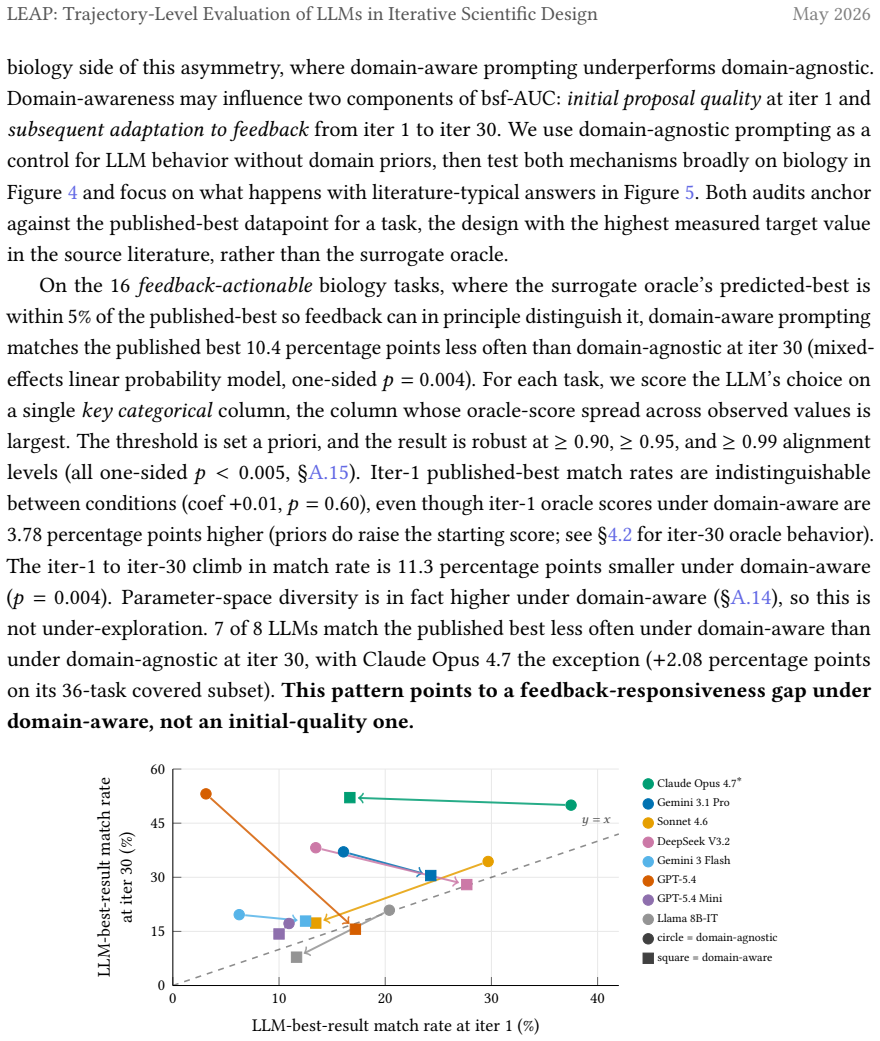
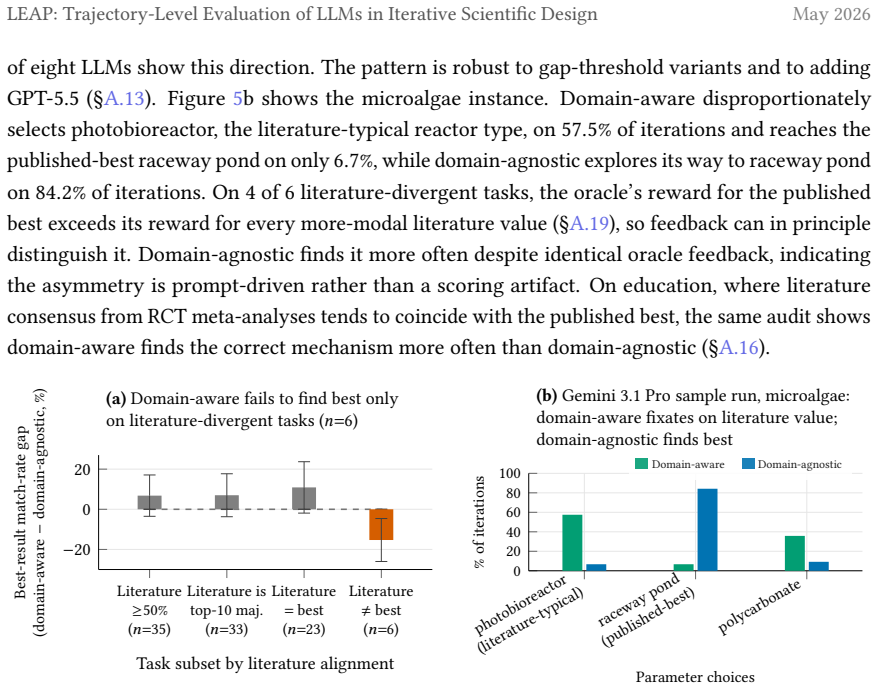
Evaluating LLMs on the entire learning trajectory via best-so-far AUC rather than end-of-horizon snapshots alters model rankings on 53 percent of tasks, exposes efficiency differences missed by outcome-only scoring, and shows that eight contemporary LLMs do not surpass a classical Bayesian-optimization reference; on 16 biology tasks the oracle reward aligns with published-best designs, domain-agnostic prompting matches those designs roughly 10 points more often than domain-aware prompting at iteration 30, with the gap clearest on the six tasks where literature-typical and published-best configurations differ.
What carries the argument
LEAPBench framework that scores best-so-far AUC trajectories, anchors comparisons to a Bayesian-optimization baseline, and audits against published literature optima.
If this is right
- Model selection for autonomous laboratories would shift when trajectory efficiency rather than final outcome is the criterion.
- Offline reinforcement learning that uses the best-so-far AUC as a reward signal improves results on 14 of 21 held-out tasks.
- Domain-agnostic prompting becomes the default choice on tasks where published optima diverge from typical literature values.
- Cost and time savings in real iterative design can be quantified directly from the area under the performance curve.
- The same trajectory metric supplies a training objective that does not require new human labels.
Where Pith is reading between the lines
- Real-world laboratory budgets could be allocated more accurately by forecasting cumulative experiment cost from the early part of the AUC curve.
- Trajectory metrics might transfer to other sequential decision domains such as chemical reaction optimization or materials synthesis loops.
- The gap between domain-aware and domain-agnostic prompting suggests that broad priors in LLMs sometimes conflict with narrow published optima.
- Future benchmarks could combine the LEAPBench trajectory score with physical constraints such as reagent availability to test practical deployability.
Load-bearing premise
That agreement with published-best configurations supplies a reliable external standard for judging whether domain-aware or domain-agnostic prompting is preferable.
What would settle it
A controlled lab experiment in which LLMs guided by trajectory scoring versus Bayesian optimization are run head-to-head on the same 55 tasks and the number of iterations required to reach a fixed performance threshold is measured.
Figures














read the original abstract
LLMs are increasingly deployed in autonomous laboratories, under the assumption that their domain priors and reasoning over iterative feedback let them converge on good designs in fewer iterations than feedback-only baselines. Current iterative scientific design benchmarks, however, score only outcome snapshots at fixed horizons. This leaves the learning trajectory unmeasured, even though the trajectory is what captures learning efficiency, where each iteration saved is a real saving in cost and time. Motivated by this, we examine three evaluation choices that change the conclusions one draws about LLM learning efficiency in iterative scientific design: what to measure, what baseline to compare against, and what to ground against. We introduce LEAPBench, Learning Efficiency in Adaptive Processes, a 55-task framework that pairs a best-so-far area under the curve (AUC) trajectory metric with a classical Bayesian-optimization reference and an audit grounded in published literature. Applied to eight contemporary LLMs, switching from final-outcome to trajectory scoring changes the best-model decision on 53% of tasks at matched horizons, and exposes efficiency gains overlooked by outcome-based scoring. LLMs do not outperform a classical Bayesian baseline. On 16 biology tasks where the oracle's reward signal is aligned with configurations from the published-best design, domain-aware prompting leads to LLM choices that match the published-best's approximately 10 percentage points less often than domain-agnostic prompting at iteration 30. The pattern is sharpest on 6 tasks where the literature-typical and published-best configurations diverge, and domain-agnostic prompting matches the published-best more often on all 6. The trajectory metric also doubles as a tractable training target. Offline reinforcement learning with the metric as a reward improves performance on 14 of 21 held-out tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces LEAPBench, a 55-task framework for trajectory-level evaluation of LLMs in iterative scientific design. It pairs a best-so-far AUC metric with a Bayesian optimization baseline and literature-grounded audit. Key empirical claims are that trajectory scoring changes the best-model decision on 53% of tasks versus final-outcome scoring, LLMs do not outperform the Bayesian baseline, and on a filtered subset of 16 biology tasks (where oracle reward aligns with published-best configurations), domain-agnostic prompting matches the published-best ~10pp more often than domain-aware prompting at iteration 30, with the pattern sharpest on 6 tasks where literature-typical and published-best diverge.
Significance. If the central empirical comparisons hold, the work usefully demonstrates that evaluation protocol choices (trajectory vs. outcome, baseline, grounding) materially affect conclusions about LLM efficiency in scientific design loops. The introduction of a reproducible benchmark, the AUC metric as a potential training target for offline RL, and the explicit audit against published literature are constructive contributions that could improve future benchmarking in this area.
major comments (3)
- [§4.2] §4.2 (biology tasks subset): the selection of the 16 tasks is conditioned on oracle reward alignment with published-best configurations. This criterion risks circularity because the same alignment may correlate with task properties that favor domain-agnostic prompting; the reported ~10pp advantage and the sharper pattern on the 6-task divergence subset therefore may not generalize to the full unfiltered biology set or to alternative ground truths such as literature-typical optima. Full-set results or a sensitivity table should be added.
- [§3.1] §3.1 and Table 2: the claim that trajectory scoring changes the best-model decision on 53% of tasks lacks reported error bars, statistical significance tests, or sensitivity to horizon matching; without these it is unclear whether the 53% figure is robust or driven by a small number of tasks with high variance.
- [§3.3] §3.3 (Bayesian baseline): the statement that LLMs do not outperform the classical Bayesian-optimization reference requires explicit description of the BO implementation details (acquisition function, kernel, hyperparameter handling) to confirm the comparison is not confounded by unequal tuning effort or oracle access.
minor comments (2)
- [Abstract] Abstract and §2: the phrase 'approximately 10 percentage points' should be replaced by the exact observed difference together with the number of tasks and any interval estimate.
- [Figure 3] Figure 3 (trajectory plots): add shaded confidence bands and a legend that distinguishes all eight LLMs plus the BO baseline for direct visual comparison.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major point below and indicate the revisions planned for the next version of the manuscript.
read point-by-point responses
-
Referee: [§4.2] §4.2 (biology tasks subset): the selection of the 16 tasks is conditioned on oracle reward alignment with published-best configurations. This criterion risks circularity because the same alignment may correlate with task properties that favor domain-agnostic prompting; the reported ~10pp advantage and the sharper pattern on the 6-task divergence subset therefore may not generalize to the full unfiltered biology set or to alternative ground truths such as literature-typical optima. Full-set results or a sensitivity table should be added.
Authors: We acknowledge the risk of selection effects when defining the 16-task subset on the basis of oracle alignment with published-best configurations. To address generalizability concerns, we will add results for the full unfiltered set of biology tasks and include a sensitivity table that reports performance under alternative grounding criteria (including literature-typical optima). These additions will allow readers to evaluate whether the observed patterns hold beyond the filtered subset. revision: yes
-
Referee: [§3.1] §3.1 and Table 2: the claim that trajectory scoring changes the best-model decision on 53% of tasks lacks reported error bars, statistical significance tests, or sensitivity to horizon matching; without these it is unclear whether the 53% figure is robust or driven by a small number of tasks with high variance.
Authors: We agree that additional statistical characterization would strengthen the claim. In the revision we will report error bars computed over multiple independent runs, include statistical significance tests for the proportion of tasks on which the best-model ranking changes, and add a sensitivity analysis across different evaluation horizons to demonstrate robustness of the 53% figure. revision: yes
-
Referee: [§3.3] §3.3 (Bayesian baseline): the statement that LLMs do not outperform the classical Bayesian-optimization reference requires explicit description of the BO implementation details (acquisition function, kernel, hyperparameter handling) to confirm the comparison is not confounded by unequal tuning effort or oracle access.
Authors: We will expand Section 3.3 to provide complete implementation details for the Bayesian optimization baseline, including the acquisition function, kernel, and hyperparameter handling procedure. This expanded description will make explicit that the comparison uses standard, reproducible settings and is not confounded by differences in tuning effort or oracle access. revision: yes
Circularity Check
No circularity: claims rest on external empirical benchmarks
full rationale
The paper's key results—changes in model rankings under trajectory AUC versus final-outcome scoring, comparisons to a classical Bayesian optimization baseline, and prompting differences on a literature-aligned biology subset—are obtained through direct empirical measurement against external references (published-best configurations and BO). No derivation step reduces a claimed prediction or uniqueness result to a fitted parameter, self-citation chain, or definitional tautology by construction. The task-selection criterion is a methodological filter justified by the audit goal rather than an internal equation that forces the outcome.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The 55 tasks and oracle alignments with published literature provide representative and reliable ground truth for iterative scientific design.
- domain assumption Bayesian optimization constitutes an appropriate and fair classical reference baseline.
invented entities (1)
-
LEAPBench framework and best-so-far AUC trajectory metric
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We introduce LEAPBench... best-so-far area under the curve (AUC) trajectory metric with a classical Bayesian-optimization reference
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
On 16 biology tasks where the oracle’s reward signal is aligned with configurations from the published-best design
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Parth Asawa, Chris Glaze, Gabe Orlanski, Ramya Ramakrishnan, Benji Xu, Asim Biswal, Vincent Sunn Chen, Frederic Sala, Matei Zaharia, and Joseph E. Gonzalez. Con- tinual learning bench. https://continual-learning-bench.com/news/ 12 Pareto.ai LEAP: Trajectory-Level Evaluation of LLMs in Iterative Scientific Design May 2026 cl-bench-1-0/ ,
work page 2026
-
[2]
doi: 10.1038/s41586-023-06792-0. Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. InAdvances in Neural Information Processing Systems (NeurIPS),
-
[3]
On the Measure of Intelligence
François Chollet. On the measure of intelligence.arXiv preprint arXiv:1911.01547,
work page internal anchor Pith review Pith/arXiv arXiv 1911
-
[4]
Juraj Gottweis, Wei-Hung Weng, Alexander Daryin, Tao Tu, Anil Palepu, Petar Sirkovic, et al. Towards an AI co-scientist.https://arxiv.org/abs/2502.18864,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Ideabench: Benchmarking large language models for research idea generation
Sikun Guo, Amir Hassan Shariatmadari, Guangzhi Xiong, Albert Huang, Eric Xie, Stefan Bekiranov, and Aidong Zhang. Ideabench: Benchmarking large language models for research idea generation. 13 Pareto.ai LEAP: Trajectory-Level Evaluation of LLMs in Iterative Scientific Design May 2026 InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery a...
work page 2026
-
[6]
BurstGPT: A real-world workload dataset to optimize LLM serving systems,
doi: 10.1145/3711896.3737419. Muyu He, Adit Jain, Anand Kumar, Vincent Tu, Soumyadeep Bakshi, Sachin Patro, and Nazneen Rajani. YC-Bench: Benchmarking AI agents for long-term planning and consistent execution. https://arxiv.org/abs/2604.01212,
-
[7]
LAB-Bench: Measuring Capabilities of Language Models for Biology Research
Jon M. Laurent, Joseph D. Janizek, Michael Ruzo, Michaela M. Hinks, Michael J. Hammerling, Sid- dharth Narayanan, Manvitha Ponnapati, Andrew D. White, and Samuel G. Rodriques. LAB-Bench: Measuring capabilities of language models for biology research.arXiv preprint arXiv:2407.10362,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
ResearchBench: Benchmarking LLMs in Scientific Discovery via Inspiration-Based Task Decomposition
Yujie Liu, Zonglin Yang, Tong Xie, Jinjie Ni, Ben Gao, Yuqiang Li, Shixiang Tang, Wanli Ouyang, Erik Cambria, and Dongzhan Zhou. Researchbench: Benchmarking LLMs in scientific discovery via inspiration-based task decomposition.arXiv preprint arXiv:2503.21248,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
14 Pareto.ai LEAP: Trajectory-Level Evaluation of LLMs in Iterative Scientific Design May 2026 Adrian Mirza, Nawaf Alampara, Sreekanth Kunchapu, Martiño Ríos-García, Benedict Emoekabu, Aswanth Krishnan, Tanya Wilhelmi, Macjonathan Okereke, Juliane Eberhardt, Amir Mohammad Elahi, et al. A framework for evaluating the chemical knowledge and reasoning abilit...
work page 2026
-
[10]
doi: 10.1038/ s41557-025-01815-x. Ludovico Mitchener, Jon M. Laurent, Alex Andonian, Benjamin Tenmann, Siddharth Narayanan, Geemi P. Wellawatte, Andrew White, Lorenzo Sani, and Samuel G. Rodriques. BixBench: A comprehensive benchmark for LLM-based agents in computational biology.arXiv preprint arXiv:2503.00096,
-
[11]
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll L
doi: 10.5334/jopd.139. Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul F. Christiano, Jan Leike, and Ryan Lowe. Training language models to follow inst...
-
[12]
15 Pareto.ai LEAP: Trajectory-Level Evaluation of LLMs in Iterative Scientific Design May 2026 Melanie Sclar, Yejin Choi, Yulia Tsvetkov, and Alane Suhr. Quantifying language models’ sensitivity to spurious features in prompt design, or: How i learned to start worrying about prompt formatting. InInternational Conference on Learning Representations (ICLR),
work page 2026
-
[13]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y. K. Li, Y. Wu, and Daya Guo. DeepSeekMath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
doi: 10.64898/2026. 02.05.703998. URLhttps://www.biorxiv.org/content/10.64898/2026.02. 05.703998v1. Niranjan Srinivas, Andreas Krause, Sham M. Kakade, and Matthias W. Seeger. Gaussian process optimization in the bandit setting: No regret and experimental design. InProceedings of the 27th International Conference on Machine Learning (ICML), pages 1015–1022,
-
[15]
Solving math word problems with process- and outcome-based feedback
URL https://arxiv.org/abs/2211.14275. Pre- sented at the MATH-AI Workshop at NeurIPS 2022 (no formal proceedings). David van Dijk and Ivan Vrkic. Scidesignbench: Benchmarking and improving language models for scientific inverse design.arXiv preprint arXiv:2603.12724,
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[16]
Loomba, Shichang Zhang, Yizhou Sun, and Wei Wang
16 Pareto.ai LEAP: Trajectory-Level Evaluation of LLMs in Iterative Scientific Design May 2026 Xiaoxuan Wang, Ziniu Hu, Pan Lu, Yanqiao Zhu, Jieyu Zhang, Satyen Subramaniam, Arjun R. Loomba, Shichang Zhang, Yizhou Sun, and Wei Wang. SciBench: Evaluating college-level scien- tific problem-solving abilities of large language models. InProceedings of the 41s...
work page 2026
-
[17]
Zhaofeng Wu, Linlu Qiu, Alexis Ross, Ekin Akyürek, Boyuan Chen, Bailin Wang, Najoung Kim, Jacob Andreas, and Yoon Kim. Reasoning or reciting? exploring the capabilities and limitations of language models through counterfactual tasks. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics (NAACL),
work page 2024
-
[18]
doi: 10.1186/s13068-018-1068-1. Chujie Zheng, Zhenru Zhang, Beichen Zhang, Runji Lin, Keming Lu, Bowen Yu, Dayiheng Liu, Jingren Zhou, and Junyang Lin. ProcessBench: Identifying process errors in mathematical reasoning. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (ACL),
-
[19]
17 Pareto.ai LEAP: Trajectory-Level Evaluation of LLMs in Iterative Scientific Design May 2026 A Benchmark details A.1 Metric-disagreement effect sizes and number of improving steps (NIS, supporting) Effect-size breakdown of the 26 outcome-vs-bsf-AUC@30 disagreements.Half are close swaps (rank-1 vs. rank-2, 50%). The rest are deeper (rank-3 in 31%, rank-4...
work page 2026
-
[20]
The bsf-AUC winner is faster on 9 of 14 tasks, tied on 2, slower on 3 (paired Wilcoxon𝑝=0.014). Three-way metric agreement.For each of the 55 tasks (pooled biology + education panel for direct comparison across metrics), we identify the best model under three metrics: outcome (final score), bsf-AUC (learning efficiency), and NIS (improving steps). Across ...
work page 2026
-
[21]
You are optimizing CRISPR HDR efficiency
Per-model ΔNIS by R 2 stratum. ΔNIS = (domain-aware NIS) − (domain-agnostic NIS). Negative Δmeans domain-aware prompting reduces improving steps. ModelΔNIS (Variable)𝑝ΔNIS (Clean)𝑝 Claude Opus 4.7−1.44 0.24−1.22 2×10 −3 Gemini 3.1 Pro+1.61 0.88−0.97 2×10 −7 Gemini 3 Flash−0.15 0.84−1.07 2×10 −21 Claude Sonnet 4.6+1.74 2×10 −3 −0.41 3×10 −3 GPT-5.4+0.64 0....
-
[22]
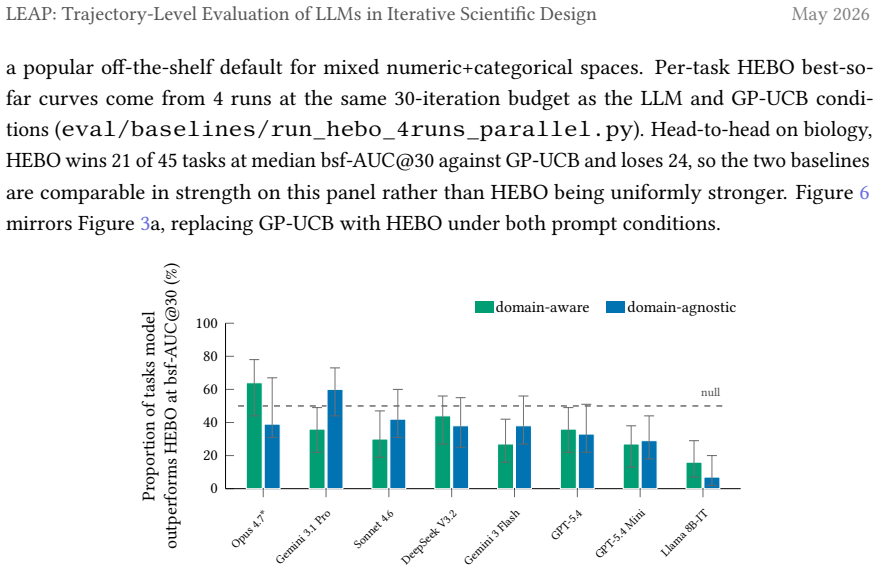
Per-model bsf-AUC@30 outperformance vs. HEBO on biology, both prompt conditions. Each model’s two bars give the fraction of biology tasks where its median bsf-AUC@30 outperforms HEBO’s, under domain-aware (teal) and domain-agnostic (cobalt). Dashed line marks the 50% null. Error bars are 2-level bootstrap 95% CIs (4-run-matched HEBO). Pass rates against H...
work page 2026
-
[23]
Biology domain-aware win rate under leave-one-model-out exclusion.Domain-aware win rate on biology recomputed eight times, excluding one model each time. Task-clustered 95% CIs shown. Excluded model domain-aware win rate Task-clustered 95% CI Clustered𝑝 Claude Opus 4.7 40.7% [31.4, 50.8] 0.070 Claude Sonnet 4.6 42.9% [33.7, 52.5] 0.147 GPT-5.4 41.4% [31.8...
work page 2026
-
[24]
Error bars are task-clustered bootstrap 95% CIs (𝐵=2000)
Disagreement rate between bsf-AUC@ 𝑘 and bsf-Outcome@𝑘 across horizons (biology, 45 tasks).Bars show the fraction of biology tasks where the argmax-of-median bsf-AUC@𝑘winner is not in the tied-best set under bsf-Outcome@𝑘 (canonical tie-aware-strict rule). Error bars are task-clustered bootstrap 95% CIs (𝐵=2000). 5 10 15 20 25 30 1 2 3 4 5 6 7 8 Horizon𝑘(...
work page 2000
-
[25]
Per-model rank on biology bsf-AUC@ 𝑘 vs. GP-UCB, across horizons.Each model is ranked by the fraction of 45 biology tasks where its median bsf-AUC@𝑘 outperforms GP-UCB. Lines connect the same model across 𝑘∈ { 5, 10, 15, 20, 25, 30}. The three highlighted models have non-trivial rank movement. 28 Pareto.ai LEAP: Trajectory-Level Evaluation of LLMs in Iter...
work page 2026
-
[26]
Error bars are task-clustered bootstrap 95% CIs (𝐵= 2000)
Bars use the same tie-aware-strict rule. Error bars are task-clustered bootstrap 95% CIs (𝐵= 2000). The smaller panel widens CIs, but flip rates remain non-trivial at every horizon. A.11 Best-model confusion matrix: bsf-AUC@30 vs. bsf-Outcome@30 Figure 10 shows the per-model breakdown of the 24 biology disagreement tasks. Most concentrate on tasks where C...
work page 2000
-
[27]
Best-model confusion matrix over 55 tasks.Diagonal (gray) = agreement (29 tasks). Off- diagonal (green, shade ∝ count) = 26 tasks where bsf-AUC@30 and bsf-Outcome@30 pick different best models. andottmar_perceptual_cues as biology-non-divergent and education representatives, and 5 biology tasks where the closest-running LLM came within 3% of GP-UCB AUC, c...
work page 2026
-
[28]
Exploration is not the missing ingredient.Domain-aware diversity is higher on ∼80% of (task, model) combinations, yet domain-agnostic runs achieve better scores on high-R2 tasks. A.15 Robustness of Figure 4: alignment, match definition, and inferential tests This appendix gives the full robustness battery for the oracle-aligned match-rate finding in §4.3....
work page 2026
-
[29]
The per-model sign test on diffs (averaging across tasks) is 5of8negative ( 𝑝= 0.36) for iter-30 and5of8( 𝑝= 0.36) for the climb at the primary threshold; the 32 Pareto.ai LEAP: Trajectory-Level Evaluation of LLMs in Iterative Scientific Design May 2026 cross-model summary is therefore weaker than the cell-level tests, consistent with the bootstrap findin...
work page 2026
-
[30]
domain-aware’s prior matches the RCT-confirmed mechanism
Mean Δ=+ 0.089. Per-task paired Wilcoxon two-sided𝑝=0.31(one-sided𝑝=0.16); the per-task test is underpowered at𝑛=9. 33 Pareto.ai LEAP: Trajectory-Level Evaluation of LLMs in Iterative Scientific Design May 2026 Iteration-level pooled rate.Pooled across all 19,825 (task, model, condition, run, iter) educa- tion iterations, domain-aware proposes the correct...
work page 2026
-
[31]
The cross-subject reversal (§4.3) is therefore not two different mechanisms, but the same prior-application mechanism evaluated against two different alignment regimes. A.17 Threshold sensitivity of the audit’s main result The audit selects 6 literature-divergent biology tasks using two gap criteria connected by an OR: (R)top-1 vs. runner-up gap ≥ 10%of t...
work page 2026
-
[32]
literature-typical and best-result diverge by a meaningful margin
Cross-subject view of the prior-application mechanism.(a)Education head-start decays. Per-iteration % of education iterations where the trajectory’s proposal matches the RCT-confirmed correct mechanism (9 tasks). Domain-aware enters above and the gap closes by iter ∼22 as oracle feedback teaches domain-agnostic the same mechanism.(b)Biology domain-awarene...
work page 2026
-
[33]
domain-agnostic minus domain-aware
91.72 A.20 Literature-stickiness persists across model sizes despite training-data access The literature-divergent tasks (§4.3) require finding designs better than what the literature suggests is typical. We test whether the literature-divergent failure could be a knowledge gap rather than a prior-overrides-feedback issue by checking whether the source pa...
work page 2018
-
[34]
Domain-agnostic remains≥ domain-aware on 4 of 5 tasks under both search-OFF and search-ON; the lone reversal isadcp_target_phagocytosis, where Opus’s domain-aware proposes the published-best antibody isotype (IgG1) on most iterations even without search and search inflates that further (70.0%→ 87.5%). On the four other tasks the domain-aware match rate st...
work page 2026
-
[35]
Tasks marked † overlap with the literature-divergent set; deviations from Table 4 on those rows reflect run-to-run sampling variability of Opus rather than a protocol change. Task D-aware off D-agnostic off D-aware on D-agnostic on (agn−aware) off (agn−aware) on adcp_target_phagocytosis 70.0% 30.8% 87.5% 71.7%−39.2−15.8 mab_developability_aggregation 0.0%...
work page 2026
-
[36]
alongside the outperformance view as a robustness check against near-zero denominators. Because GP-UCB shares the oracle and parameter space with both LLM conditions, any artifact in the oracle (e.g., inflated scores near literature-typical designs) is inherited by the GP baseline, not removed by normalization. See §5 for how this lets us rule out simple ...
work page 2026
-
[37]
Per-iteration median GP-normalized bsf-AUC across domain and condition.Top row: domain-aware. Bottom row: domain-agnostic. Left column: biology (45 tasks). Right column: education (10 tasks). Zero is GP parity. Negative means LLM below GP. Shaded bands are bootstrap 95% CIs on the median. UCB runs per task, matching the LLM 4-run protocol). As a consisten...
work page 2026
-
[38]
GP-UCB on biology under thedomain-agnosticcondition
Per-model outperformance vs. GP-UCB on biology under thedomain-agnosticcondition. Mirror of Figure 3b, which shows the domain-aware condition. Dashed line marks the 50% null. Error bars are 2-level bootstrap 95% CIs (4-run-matched GP). No model’s CI is strictly above the 50% null. Domain- agnostic differs from domain-aware in mixed directions across model...
work page 2026
-
[39]
Per-iteration pass rate vs. GP-UCB under the domain-agnostic condition.(a)Biology (45 tasks).(b)Education (10 tasks). Dashed line marks the 50% null; shaded band shows Wilson 95% CI for the highlighted model (Opus 4.7). Compare to Figure 3b (domain-aware bar version) and §A.12. Table 6.Modal-categorical rank distribution conditional on missing the best-re...
work page 2026
-
[40]
and carries anon-commercial use restriction; theLEAPBenchdata deposit therefore uses the CC BY-NC 4.0 license uniformly to satisfy that constraint. Oracle models are derived predictors trained on these data, released alongside the benchmark for reproducibility. •assistments_experiments : Prihar et al. (2022),Exploring Common Trends in Online Educational E...
-
[41]
(rank 16,𝛼=32, dropout 0.05, applied to 𝑞, 𝑘, 𝑣, 𝑜 projections). Offline GRPO with KL penalty 𝛽=0.1, group size 8, learning rate 5 × 10−6, 2 epochs over the fixed trajectory pool. The training curriculum pre-computes advantages from the fixed pool rather than rolling out new trajectories per step, which stabilizes training and makes it cheap enough to run...
work page 2026
-
[42]
Per-task GP-normalized Δbsf-AUC across 21 held-out tasks.Biology held-out and education cross-domain (never in training) both show directionally consistent improvement. Transfer to other trajectory metrics.Training used bsf-AUC-aligned reward, so bsf-AUC improvement is close to in-distribution. To check whether gains transfer to structurally different tra...
work page 2026
-
[43]
Baseline vs. GRPO on CHO antibody expression, first 5 iterations.One representative run per condition.(a)Per-iteration mAb titer.(b)Strategy per iteration; bold rows mark GRPO’s three successive glucose-feeding refinements. Illustrative example, not a quantitative mechanism claim. • Antibody expression (CHO cells).Baseline tries 5 disconnected strategies ...
work page 2026
-
[44]
System-to-condition assignment was randomized per pair; biology experts were blinded. Pair Baseline identity GRPO preferred CHO Antibody Stability A=Baseline, B=GRPO 3/3 Baculovirus Titer A=GRPO, B=Baseline 3/3 E. coli GFP Yield A=Baseline, B=GRPO 1/3 ADCP Phagocytosis A=GRPO, B=Baseline 3/3 Perceptual Cues A=Baseline, B=GRPO 2/2 Total 12/14 (86%) Part A ...
work page 2026
-
[45]
Fleiss’𝜅= 0.33across the three raters (fair agreement, supporting evidence, not confirmatory)
Expert 2 vs 3 = 2 of 4 (Expert 3 disagreed with both on Trajectories 2 and 4). Fleiss’𝜅= 0.33across the three raters (fair agreement, supporting evidence, not confirmatory). Reproducible via expert_review/analyze.py. On Part A quality ratings, the responsive vs. anchored separation is consistent across experts (Experts 1 and 2: responsive≥anchored on ever...
work page 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.