ProPlay: Procedural World Models for Self-Evolving LLM Agents
Pith reviewed 2026-06-27 07:50 UTC · model grok-4.3
The pith
A procedural world model lets LLM agents rehearse and refine task procedures from experience
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
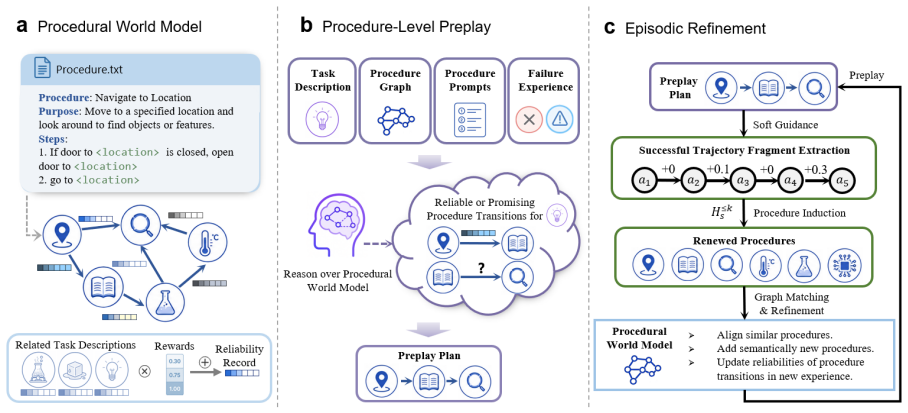
ProPlay abstracts successful trajectories into procedures and organizes them in a procedure graph that captures causal transitions among task stages. Each transition is associated with a reliability record embedding to estimate its task-specific contribution from past outcomes. Before each episode, ProPlay simulates future procedural trajectories over known graph structures as structured soft guidance; after execution, it refines the graph using environment feedback.
What carries the argument
Procedure graph with reliability record embeddings that supports procedure-level preplay simulation and post-execution refinement
Load-bearing premise
Successful trajectories can be reliably abstracted into procedures whose causal transitions, when stored with reliability record embeddings, provide useful structured soft guidance that improves performance after refinement from environment feedback
What would settle it
Running the benchmarks with the reliability record embeddings removed or the preplay simulation disabled, and finding no consistent improvement over baselines
Figures



read the original abstract
Self-evolving agents are expected to improve through interaction without external supervision, but this remains difficult in partially observable environments where agents must explore actively, learn from limited feedback, and decide when to trust prior experience. Existing LLM-agent methods often rely on memory or planning modules, yet they rarely close the loop between them to continually refine an internal understanding of environment dynamics. We introduce ProPlay, a procedural world model that supports procedure-level preplay, where agents can rehearse future procedural paths using the learned world knowledge. Rather than representing experience as isolated rules or low-level action constraints, ProPlay abstracts successful trajectories into procedures and organizes them in a procedure graph that captures causal transitions among task stages. Each transition is associated with a reliability record embedding to estimate its task-specific contribution from past outcomes. Before each episode, ProPlay simulates future procedural trajectories over known graph structures as structured soft guidance; after execution, it refines the graph using environment feedback. Experiments on public benchmarks show that ProPlay consistently improves environment understanding and self-evolution capability over strong baselines. Our code has been released in https://github.com/antman9914/proplay.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ProPlay, a procedural world model for self-evolving LLM agents in partially observable environments. Successful trajectories are abstracted into procedures organized in a procedure graph that captures causal transitions among task stages; each transition carries a reliability record embedding estimated from past outcomes. Before each episode the model performs procedure-level preplay over the graph to supply structured soft guidance; after execution the graph is refined from environment feedback. Experiments on public benchmarks are reported to show consistent gains in environment understanding and self-evolution over strong baselines, and code is released.
Significance. If the reported gains hold under scrutiny, the work supplies a concrete mechanism for closing the loop between memory and planning in LLM agents via reusable procedural abstractions and preplay. The public code release is a clear strength that permits direct verification of whether the abstraction, transition storage, and preplay steps produce the claimed improvements.
major comments (2)
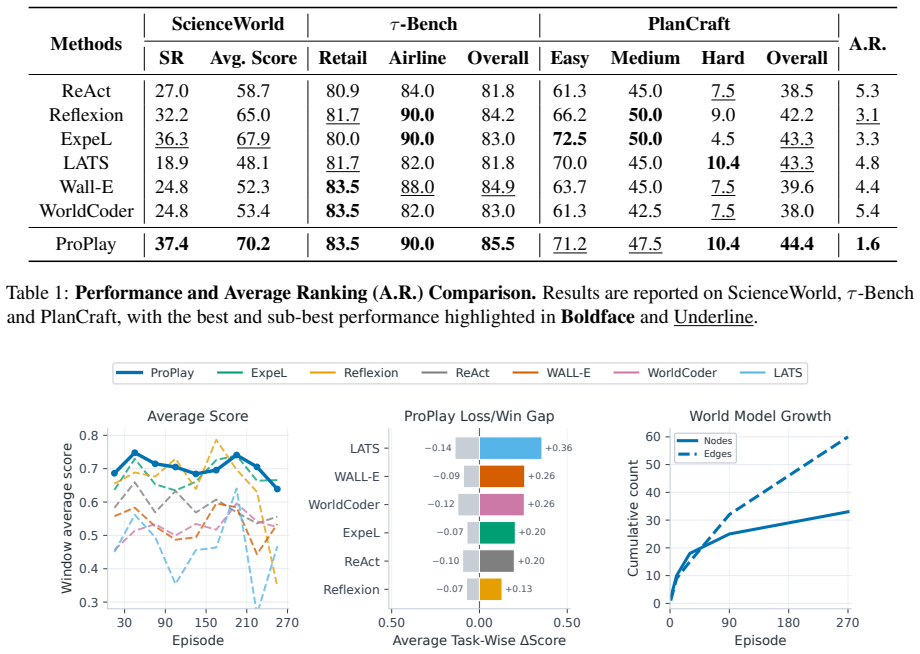
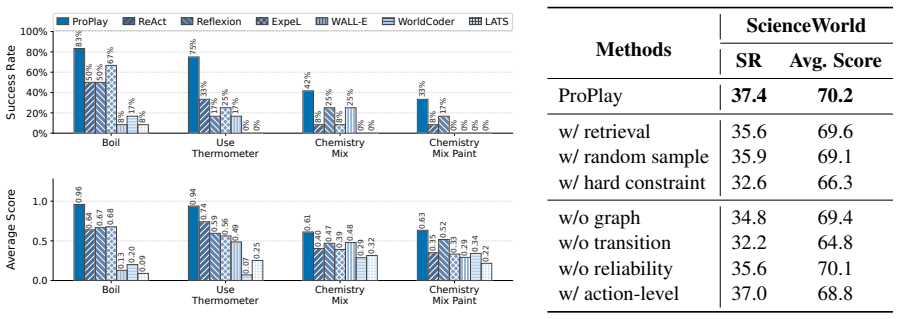
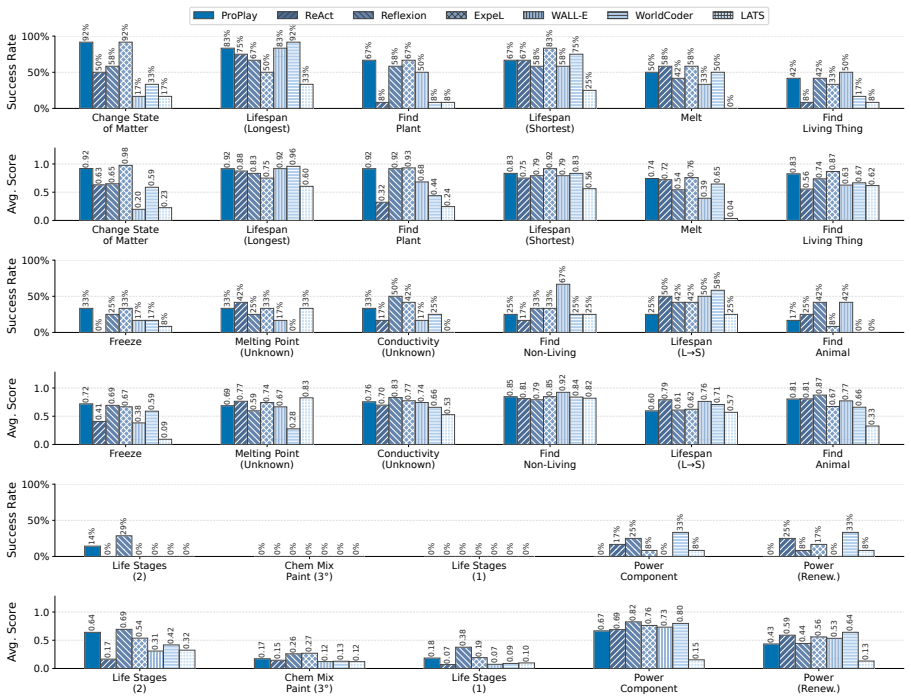
- [Abstract] Abstract and Methods (implied): the central experimental claim of consistent improvement rests on unspecified implementation details for procedure-graph construction, transition reliability estimation, and preplay simulation; no error bars, ablation tables, or statistical tests are referenced, making it impossible to assess whether the gains are robust or attributable to the proposed components.
- [Abstract] Abstract: the reliability record embedding is described as estimated from past outcomes; without the precise update rule or loss it is unclear whether the preplay guidance signal is independent of quantities already fitted from the same trajectories, raising a potential circularity concern that must be resolved before the self-evolution claim can be evaluated.
minor comments (1)
- [Abstract] The GitHub link is given but no commit hash or release tag is supplied, which would aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below by pointing to the relevant sections of the full manuscript and clarifying the design choices.
read point-by-point responses
-
Referee: [Abstract] Abstract and Methods (implied): the central experimental claim of consistent improvement rests on unspecified implementation details for procedure-graph construction, transition reliability estimation, and preplay simulation; no error bars, ablation tables, or statistical tests are referenced, making it impossible to assess whether the gains are robust or attributable to the proposed components.
Authors: The abstract is intentionally concise, but the full manuscript provides the requested details: procedure-graph construction (how trajectories are abstracted into procedures and organized by causal task-stage transitions) is specified in Section 3.1; transition reliability estimation (embedding computation from past outcomes) appears in Section 3.2; and preplay simulation (procedure-level rehearsal over the graph) is described in Section 3.3. The experimental section (Section 4) includes ablation tables (Table 2) isolating each component, error bars on all reported metrics (Figures 3–5), and statistical significance tests (p-values in Table 1). The public code release further permits direct inspection of the implementation. We therefore believe the robustness and attribution claims are already supported in the manuscript. revision: no
-
Referee: [Abstract] Abstract: the reliability record embedding is described as estimated from past outcomes; without the precise update rule or loss it is unclear whether the preplay guidance signal is independent of quantities already fitted from the same trajectories, raising a potential circularity concern that must be resolved before the self-evolution claim can be evaluated.
Authors: The reliability embeddings are updated only after episode execution using the new environment feedback; preplay for any given episode is performed with embeddings computed exclusively from all prior episodes. This temporal separation ensures the guidance signal is independent of the current trajectory’s outcomes. The precise update rule (a non-parametric, weighted average of historical success rates with the latest binary outcome) is given in Equation (5); no learned loss is applied to the embeddings. We can insert an explicit paragraph restating this sequencing and the equation if the current presentation leaves any ambiguity. revision: partial
Circularity Check
No significant circularity; empirical method with released code
full rationale
The manuscript presents ProPlay as an empirical agent architecture that abstracts trajectories into a procedure graph with reliability embeddings derived from observed outcomes, then uses the graph for preplay guidance before refining it with new feedback. No equations or closed-form derivations are provided. The central claims rest on benchmark experiments rather than any mathematical reduction of predictions to fitted inputs. The reliability embedding is described as estimated from past outcomes and updated via environment feedback, which is standard incremental learning rather than a self-definitional or fitted-input-called-prediction loop. No self-citation load-bearing steps, uniqueness theorems, or ansatz smuggling are present. Code release supplies an external verification path, confirming the method is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
invented entities (2)
-
procedure graph
no independent evidence
-
reliability record embedding
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Memory os of ai agent. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 25972–25981. Ziming Li, Jiatan Huang, Xiaoguang Guo, Guilin Wang, and Chuxu Zhang. 2026a. Same signal, opposite meaning: Direction-informed adaptive learning for llm agents.arXiv preprint arXiv:2605.06908. Ziming Li, Xiaoming Wu, Zehong W...
Pith/arXiv arXiv 2025
-
[2]
Charles Packer, Sarah Wooders, Kevin Lin, Vivian Fang, Shishir G Patil, Ion Stoica, and Joseph E Gonzalez
The role of hippocampal replay in memory and planning.Current Biology, 28(1):R37–R50. Charles Packer, Sarah Wooders, Kevin Lin, Vivian Fang, Shishir G Patil, Ion Stoica, and Joseph E Gonzalez
-
[3]
arXiv preprint arXiv:2310.08560
Memgpt: Towards llms as operating systems. arXiv preprint arXiv:2310.08560. Giovanni Pezzulo, Thomas Parr, Paul Cisek, Andy Clark, and Karl Friston. 2024. Generating meaning: active inference and the scope and limits of passive ai.Trends in Cognitive Sciences, 28(2):97–112. Pranav Putta, Edmund Mills, Naman Garg, Sumeet Motwani, Chelsea Finn, Divyansh Gar...
Pith/arXiv arXiv 2024
-
[4]
Agentgym: Evaluating and training large lan- guage model-based agents across diverse environ- ments. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Vol- ume 1: Long Papers), pages 27914–27961. Wujiang Xu, Zujie Liang, Kai Mei, Hang Gao, Juntao Tan, and Yongfeng Zhang. 2026. A-mem: Agentic memory for llm agents.A...
Pith/arXiv arXiv 2026
-
[5]
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao
Tree of thoughts: Deliberate problem solving with large language models.Advances in neural information processing systems, 36:11809–11822. Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. 2022. React: Synergizing reasoning and acting in language models.arXiv preprint arXiv:2210.03629. Zhongwei Yu, Jingqing Ruan, ...
Pith/arXiv arXiv 2022
-
[6]
ADD a new procedure if episodes demonstrate a task pattern not covered by any existing entry
-
[7]
ADD steps to an existing procedure if episodes reveal steps consistently missing from the general template
-
[8]
REWRITE an existing procedure only if it contains steps that are outright incorrect
-
[9]
<object>, <container>, <location>) — never hard-code values from individual episodes
Use abstract placeholders (e.g. <object>, <container>, <location>) — never hard-code values from individual episodes
-
[10]
Output: Section 1 — the complete updated procedure library
Do not add conditional branches that apply only to a single episode. Output: Section 1 — the complete updated procedure library. Section 2 — an execution trace for the LATEST episode only: the ordered sequence of procedure names that best describes what the agent actually did. Wrap in <trace> tags, one name per line. User Message: ## Existing Procedures {...
-
[11]
Select only the procedures relevant to this task — not every available procedure needs to be used
-
[12]
The procedure graph is evidence, not a prescription
Use your own reasoning to determine the order and combination of steps. The procedure graph is evidence, not a prescription
-
[13]
Higher scores are a useful signal, but not instructions — a low-reliability edge may still be the right choice, and a high-reliability edge may not apply to this task
Reliability scores reflect how often a transition contributed to past successful episodes. Higher scores are a useful signal, but not instructions — a low-reliability edge may still be the right choice, and a high-reliability edge may not apply to this task
-
[14]
You may include steps not present in the known procedures if the task requires them
-
[15]
Prioritize experiences from tasks similar to the current goal
If a Past Episode Experiences section is shown, study each failure entry to identify the root cause, and design your plan to reason around it. Prioritize experiences from tasks similar to the current goal. Output format: - Output the plan inside <plan> tags - Top-level entries are numbered, each beginning with the exact procedure name. Under each entry, l...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.