Comparing ML-Specific and General Python Code Smells Across Project Characteristics
Pith reviewed 2026-06-28 13:46 UTC · model grok-4.3
The pith
ML code smells are 41-94 times less frequent than general Python smells in open-source ML projects.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
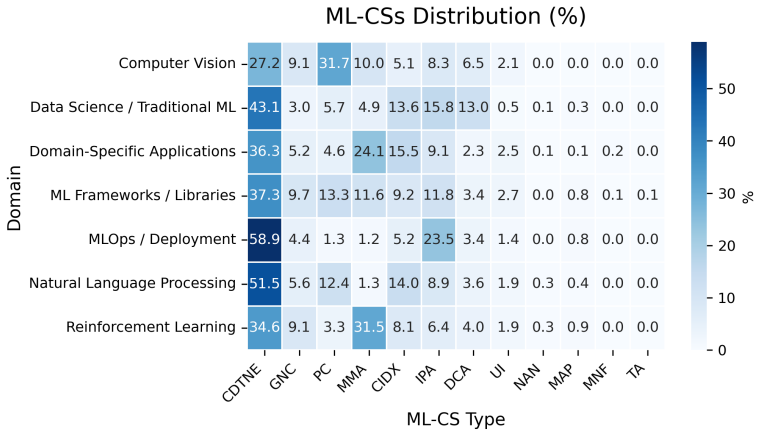
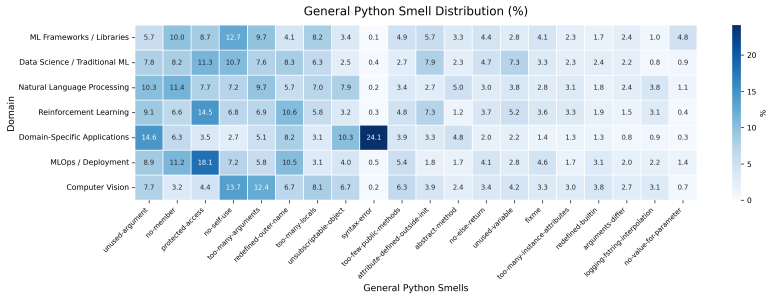
ML-specific code smells detected by CodeSmile occur 41-94 times less frequently than general Python smells detected by Pylint. Commit frequency and domain are significantly associated with ML-specific smell occurrence, but project size, team size, age, and CI/CD adoption are not. General Python smells are not associated with any of the six project features, and the domains most impacted by each smell type differ.
What carries the argument
Empirical comparison of ML-specific smells (CodeSmile) versus general Python smells (Pylint) related to project size, age, contributors, commit frequency, CI/CD adoption, and domain in 279 open-source ML repositories.
If this is right
- Domains such as MLOps, Reinforcement Learning, and Computer Vision require distinct quality checks for ML-specific issues like configuration, tensor manipulation, and GPU workflows.
- Standard CI/CD pipelines often miss domain-specific ML correctness problems, so specialized quality gates are needed.
- General Python smell reduction strategies can ignore project context, but ML smell strategies must account for commit frequency and domain.
- ML code quality depends on specialized practices rather than the general project metrics traditionally linked to technical debt.
Where Pith is reading between the lines
- ML teams may apply stricter discipline to ML-specific code than to surrounding general code.
- Detection tools for ML smells would benefit from tighter integration with domain-specific validators beyond standard automation.
- The independence of general smells from all project traits suggests systemic language-level issues that persist across contexts.
Load-bearing premise
The tools CodeSmile and Pylint correctly detect and classify the relevant code smells without substantial measurement error, and the 279 projects represent typical ML development practices.
What would settle it
A representative sample of ML projects in which ML-specific smell density equals or exceeds general Python smell density, or in which project size shows a significant correlation with ML smell frequency.
Figures

read the original abstract
Machine learning systems consist of general-purpose code as well as machine-learning-specific code. While ML-specific code smells have been identified, their connection to project characteristics and their interaction with overall code quality are not well understood. Without this knowledge, quality assurance strategies remain one-size-fits-all, failing to account for the contextual factors that drive technical debt in ML systems. We present empirical evidence by examining how six project features (size, age, contributors, commit frequency, CI/CD adoption, and domain) relate to both ML-specific and general Python code quality in 279 open-source ML projects on GitHub. Using CodeSmile for ML code smells and Pylint for general Python smells, our results show: (1) ML code smells are 41-94 times less frequent than general Python smells; (2) commit frequency and domain are significantly associated with ML-specific quality, while project size, team size, age, and CI/CD adoption are not, challenging traditional views on technical debt; (3) general Python smells are not linked to any project characteristic, indicating systemic coding issues that are independent of project context; (4) domains that suffer most from ML-specific smells are not necessarily the same domains that suffer most from general Python smells, necessitating tailored quality strategies for each smell type. MLOps often involves configuration issues, Reinforcement Learning faces challenges with tensor manipulation, and Computer Vision encounters problems with GPU workflows. Overall, ML code quality depends on domain-specific practices and specialized CI/CD quality gates, as standard automation often overlooks domain-specific correctness problems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript reports an empirical analysis of code smells in 279 open-source ML projects on GitHub. Using CodeSmile to detect ML-specific smells and Pylint for general Python smells, it finds ML-specific smells are 41-94 times less frequent than general ones. Commit frequency and domain are significantly associated with ML-specific quality, while project size, team size, age, and CI/CD adoption are not. General Python smells show no associations with any project characteristics. Different domains are affected differently by the two types of smells, suggesting the need for tailored quality assurance strategies.
Significance. If the detection tools accurately capture the smells without substantial bias, the results provide valuable evidence that ML code quality is driven by different factors than general code quality, challenging traditional technical debt models that treat all code uniformly. The large sample size and use of established tools like Pylint are strengths. The findings have practical implications for MLOps practices, highlighting domain-specific issues like tensor manipulation in RL and GPU workflows in CV.
major comments (2)
- [Abstract and Methods (code smell detection)] Abstract and Methods (code smell detection): The headline result that ML code smells are 41-94 times less frequent, and the associations with commit frequency and domain, depend on CodeSmile providing a faithful measure of ML smell prevalence. No validation of CodeSmile's accuracy (e.g., precision/recall against manual review or comparison in ML-specific contexts like tensor operations) is described. If CodeSmile under-detects ML smells relative to Pylint's detection of general smells, the frequency ratio and null results for other factors become difficult to interpret.
- [Results (statistical analysis)] Results (statistical analysis): The abstract mentions significant associations but provides no details on the statistical methods, correction for multiple testing, effect sizes, or handling of potential confounds such as correlations between project characteristics. This information is necessary to assess the robustness of the claims about which factors are or are not associated.
minor comments (2)
- [Abstract] The abstract could briefly note the statistical approach used to determine 'significantly associated' to improve clarity for readers.
- [Discussion] Consider adding a limitations section explicitly addressing potential measurement error in the smell detection tools.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on tool validation and statistical transparency. We address each major comment below, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: Abstract and Methods (code smell detection): The headline result that ML code smells are 41-94 times less frequent, and the associations with commit frequency and domain, depend on CodeSmile providing a faithful measure of ML smell prevalence. No validation of CodeSmile's accuracy (e.g., precision/recall against manual review or comparison in ML-specific contexts like tensor operations) is described. If CodeSmile under-detects ML smells relative to Pylint's detection of general smells, the frequency ratio and null results for other factors become difficult to interpret.
Authors: We agree that the manuscript does not include an independent validation of CodeSmile within this study. CodeSmile was chosen as the established detector from its originating publication, which reports performance metrics on ML code. To improve interpretability of the 41-94x frequency ratio, we will revise the Methods section to cite those prior metrics, explicitly discuss the assumption of comparable detection fidelity with Pylint, and add a dedicated paragraph in Threats to Validity acknowledging the absence of fresh ML-specific precision/recall evaluation as a limitation. This directly mitigates concerns about systematic under-detection biasing the headline results and the null findings for other project characteristics. revision: yes
-
Referee: Results (statistical analysis): The abstract mentions significant associations but provides no details on the statistical methods, correction for multiple testing, effect sizes, or handling of potential confounds such as correlations between project characteristics. This information is necessary to assess the robustness of the claims about which factors are or are not associated.
Authors: The full manuscript contains a Statistical Analysis subsection in Methods that specifies negative binomial regression for the count-based smell data, Bonferroni correction for the six project characteristics tested, incidence rate ratios as effect sizes, and multicollinearity checks via VIF (all <5, indicating no problematic confounds). The Results section reports these alongside the significance findings. We will revise the abstract to include a one-sentence summary of the modeling approach and add explicit cross-references from Results to the Methods details. This makes the robustness information immediately accessible without altering the existing analysis. revision: partial
Circularity Check
No significant circularity; purely observational empirical study.
full rationale
The paper performs direct measurement of code smells via external static-analysis tools (CodeSmile for ML-specific smells, Pylint for general Python smells) across 279 GitHub projects, followed by statistical association tests against six project characteristics. No equations, normalizations, fitted parameters, or predictions are present that could reduce to self-referential definitions or fitted inputs called predictions. No self-citation chains or uniqueness theorems are invoked as load-bearing premises. All reported results (frequency ratios, domain associations, null results for size/team/age/CI-CD) are outputs of the measurement and correlation pipeline rather than inputs redefined as findings. The study is therefore self-contained against external benchmarks with no circular steps.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Open-source GitHub ML projects form a representative sample for drawing conclusions about ML code quality
- domain assumption CodeSmile and Pylint outputs constitute valid and comparable measures of ML-specific and general code smells
Reference graph
Works this paper leans on
-
[1]
Software engineering for machine learning: A case study,
S. Amershi et al., “Software engineering for machine learning: A case study,” in Proceedings of the 41st IEEE/ACM International Conference on Software Engineering: Software Engineering in Practice, 2019, pp. 291–300. doi: 10.1109/ICSE-SEIP.2019.00042
-
[2]
J. D. Gonzalez, T. Zimmermann, and N. Nagappan, “The state of the ML-universe: 10 years of artificial intelligence & machine learning soft- ware development on GitHub,” in Proceedings of the 17th International Conference on Mining Software Repositories, 2020, pp. 431–442. doi: 10.1145/3379597.3387473
-
[3]
Software engineering for AI-based sys- tems: A survey,
S. Mart ´ınez-Fern´andez et al., “Software engineering for AI-based sys- tems: A survey,” ACM Trans. Softw. Eng. Methodol., vol. 31, no. 2, p. 37e:1-37e:59, 2022, doi: 10.1145/3487043
-
[4]
Robots and AI: Illusions and Social Dilemmas
V . Lenarduzzi, F. Lomio, S. Moreschini, D. Taibi, and D. A. Tamburri, “Software quality for AI: Where we are now?,” in Software Quality: Future Perspectives on Software Engineering Quality, D. Winkler, S. Biffl, D. Mendez, M. Wimmer, and J. Bergsmann, Eds., Cham: Springer International Publishing, 2021, pp. 43–53. doi: 10.1007/978-3-030- 65854-0 4
-
[5]
Hidden technical debt in machine learning systems,
D. Sculley et al., “Hidden technical debt in machine learning systems,” in Advances in Neural Information Processing Systems, 2015, pp. 2503–2511
2015
-
[6]
Fowler, Refactoring: Improving the design of existing code
M. Fowler, Refactoring: Improving the design of existing code. Addison- Wesley Professional, 2018
2018
-
[7]
Code smells and refactoring: A tertiary systematic review of challenges and observations,
G. Lacerda, F. Petrillo, M. Pimenta, and Y . G. Gu ´eh´eneuc, “Code smells and refactoring: A tertiary systematic review of challenges and observations,” Journal of Systems and Software, vol. 167, p. 110610, 2020, doi: 10.1016/j.jss.2020.110610
-
[8]
B. van Oort, L. Cruz, M. Aniche, and A. van Deursen, “The Prevalence of Code Smells in Machine Learning projects,” in Proceedings of the 1st IEEE/ACM Workshop on AI Engineering - Software Engineering for AI, 2021, pp. 1–8. doi: 10.1109/W AIN52551.2021.00011
work page doi:10.1109/w 2021
-
[9]
F. Palomba, G. Bavota, M. Di Penta, F. Fasano, R. Oliveto, and A. De Lucia, “On the diffuseness and the impact on maintainability of code smells: A large scale empirical investigation,” in Proceedings of the 40th International Conference on Software Engineering, 2018, p. 482. doi: 10.1145/3180155.3182532
-
[10]
An exploratory study of the impact of antipatterns on class change- and fault-proneness,
F. Khomh, M. D. Penta, Y .-G. Gu ´eh´eneuc, and G. Antoniol, “An exploratory study of the impact of antipatterns on class change- and fault-proneness,” Empir Software Eng, vol. 17, no. 3, pp. 243–275, 2012, doi: 10.1007/s10664-011-9171-y
-
[11]
Code smells for machine learning applications,
H. Zhang, L. Cruz, and A. van Deursen, “Code smells for machine learning applications,” in Proceedings of the 1st International Conference on AI Engineering: Software Engineering for AI, 2022, pp. 217–228. doi: 10.1145/3522664.3528620
-
[12]
When code smells meet ML: On the lifecycle of ML-specific code smells in ML-enabled systems,
G. Recupito, G. Giordano, F. Ferrucci, D. Di Nucci, and F. Palomba, “When code smells meet ML: On the lifecycle of ML-specific code smells in ML-enabled systems,” Empir Software Eng, vol. 30, no. 5, p. 139, 2025, doi: 10.1007/s10664-025-10676-4
-
[13]
Investigating the Resolution of Vulnerable Dependencies with Dependabot Security Updates,
R. Widyasari et al., “NICHE: A curated dataset of engineered machine learning projects in Python,” in Proceedings of 20th IEEE/ACM Inter- national Conference on Mining Software Repositories, 2023, pp. 62–66. doi: 10.1109/MSR59073.2023.00022
-
[14]
A. J. Simmons, S. Barnett, J. Rivera-Villicana, A. Bajaj, and R. Vasa, “A large-scale comparative analysis of Coding Standard conformance in Open-Source Data Science projects,” in Proceedings of the 14th ACM/IEEE International Symposium on Empirical Software Engineer- ing and Measurement, 2020, pp. 1–11. doi: 10.1145/3382494.3410680
-
[15]
Under- standing developer practices and code smells diffusion in AI-enabled software: A preliminary study,
G. Giordano, G. Annunziata, A. De Lucia, and F. Palomba, “Under- standing developer practices and code smells diffusion in AI-enabled software: A preliminary study,” in IWSM-Mensura, 2023
2023
-
[16]
G. Giordano, A. Della Porta, F. Ferrucci, and F. Palomba, “An evidence- based study on the relationship of software engineering practices on code smells in Python ML projects,” in Software Engineering and Advanced Applications, D. Taibi and D. Smite, Eds., Cham: Springer Nature, 2026, pp. 105–120. doi: 10.1007/978-3-032-04207-1 8
-
[17]
An empirical study of refactorings and technical debt in machine learning systems,
Y . Tang, R. Khatchadourian, M. Bagherzadeh, R. Singh, A. Stewart, and A. Raja, “An empirical study of refactorings and technical debt in machine learning systems,” in Proceedings of the 43rd IEEE/ACM International Conference on Software Engineering, 2021, pp. 238–250. doi: 10.1109/ICSE43902.2021.00033
-
[18]
Prevalence of code smells in reinforcement learning projects,
N. Cardozo, I. Dusparic, and C. Cabrera, “Prevalence of code smells in reinforcement learning projects,” 2023, arXiv: arXiv:2303.10236
arXiv 2023
-
[19]
Automatic identifica- tion of machine learning-specific code smells,
P. Hamfelt, R. Britto, L. Rocha, and C. Almendra, “Automatic identifica- tion of machine learning-specific code smells,” 2025, arXiv: 2508.02541
arXiv 2025
-
[20]
AI-specific code smells: From specification to detection,
B. Mahmoudi, N. Moha, Q. Sti ´evenart, and F. Avellaneda, “AI-specific code smells: From specification to detection,” 2025, arXiv: 2509.20491
Pith/arXiv arXiv 2025
-
[21]
Is it all lost? A study of inactive open source projects,
J. Khondhu, A. Capiluppi, and K.-J. Stol, “Is it all lost? A study of inactive open source projects,” in Open Source Software: Quality Verification, E. Petrinja, G. Succi, N. El Ioini, and A. Sillitti, Eds., Springer, 2013, pp. 61–79. doi: 10.1007/978-3-642-38928-3 5
-
[22]
J. Coelho, M. T. Valente, L. Milen, and L. L. Silva, “Is this GitHub project maintained? Measuring the level of maintenance activity of open- source projects,” Information and Software Technology, vol. 122, p. 106274, 2020, doi: 10.1016/j.infsof.2020.106274
-
[23]
Understanding the factors that impact the popularity of GitHub repositories,
H. Borges, A. Hora, and M. T. Valente, “Understanding the factors that impact the popularity of GitHub repositories,” in Proceedings of the IEEE International Conference on Software Maintenance and Evolution, 2016, pp. 334–344. doi: 10.1109/ICSME.2016.31
-
[24]
Is popularity a measure of quality? An analysis of Maven components,
H. Sajnani, V . Saini, J. Ossher, and C. V . Lopes, “Is popularity a measure of quality? An analysis of Maven components,” in Proceedings of the IEEE International Conference on Software Maintenance and Evolution, 2014, pp. 231–240. doi: 10.1109/ICSME.2014.45
-
[25]
The promises and perils of mining GitHub,
E. Kalliamvakou, G. Gousios, K. Blincoe, L. Singer, D. M. German, and D. Damian, “The promises and perils of mining GitHub,” in Proceedings of the 11th Working Conference on Mining Software Repositories, 2014, pp. 92–101. doi: 10.1145/2597073.2597074
-
[26]
A novel approach for estimating truck factors,
G. Avelino, L. Passos, A. Hora, and M. T. Valente, “A novel approach for estimating truck factors,” in Proceedings of the 24th IEEE Inter- national Conference on Program Comprehension, 2016, pp. 1–10. doi: 10.1109/ICPC.2016.7503718
-
[27]
W. Zou, W. Zhang, X. Xia, R. Holmes, and Z. Chen, “Branch use in practice: A large-scale empirical study of 2,923 projects on GitHub,” in Proceedings of the 19th IEEE International Conference on Software Quality, Reliability and Security, 2019, pp. 306–317. doi: 10.1109/QRS.2019.00047
-
[28]
Us- age, costs, and benefits of continuous integration in open-source projects,
M. Hilton, T. Tunnell, K. Huang, D. Marinov, and D. Dig, “Us- age, costs, and benefits of continuous integration in open-source projects,” in Proceedings of the 31st IEEE/ACM International Con- ference on Automated Software Engineering, 2016, pp. 426–437. doi: 10.1145/2970276.2970358
-
[29]
Quality and productivity outcomes relating to continuous integration in GitHub,
B. Vasilescu, Y . Yu, H. Wang, P. Devanbu, and V . Filkov, “Quality and productivity outcomes relating to continuous integration in GitHub,” in Proceedings of the 10th Joint Meeting on Foundations of Software Engineering, 2015, pp. 805–816. doi: 10.1145/2786805.2786850
-
[30]
Automatically categorising GitHub repositories by application domain,
F. Zanartu et al., “Automatically categorising GitHub repositories by application domain,” 2022, arXiv: 2208.00269
arXiv 2022
-
[31]
HiGitClass: Keyword-driven hierarchical classi- fication of GitHub repositories,
Y . Zhang et al., “HiGitClass: Keyword-driven hierarchical classi- fication of GitHub repositories,” in Proceedings of the IEEE In- ternational Conference on Data Mining, 2019, pp. 876–885. doi: 10.1109/ICDM.2019.00098
-
[32]
An empirical study of code smells in transformer-based code generation techniques,
M. L. Siddiq, S. H. Majumder, M. R. Mim, S. Jajodia, and J. C. S. Santos, “An empirical study of code smells in transformer-based code generation techniques,” in Proceedings of the 22nd IEEE International Working Conference on Source Code Analysis and Manipulation, 2022, pp. 71–82. doi: 10.1109/SCAM55253.2022.00014
-
[33]
Robust statistical methods for empirical software engineering,
B. Kitchenham et al., “Robust statistical methods for empirical software engineering,” Empir Software Eng, vol. 22, no. 2, pp. 579–630, 2017, doi: 10.1007/s10664-016-9437-5
-
[34]
A systematic mapping study on technical debt and its management,
Z. Li, P. Avgeriou, and P. Liang, “A systematic mapping study on technical debt and its management,” Journal of Systems and Software, vol. 101, pp. 193–220, 2015, doi: 10.1016/j.jss.2014.12.027
-
[35]
The ML test score: A rubric for ML production readiness and technical debt reduction,
E. Breck, S. Cai, E. Nielsen, M. Salib, and D. Sculley, “The ML test score: A rubric for ML production readiness and technical debt reduction,” in Proceedings of the IEEE International Conference on Big Data, 2017, pp. 1123–1132. doi: 10.1109/BigData.2017.8258038
-
[36]
Machine learning testing: Survey, landscapes and horizons,
J. M. Zhang, M. Harman, L. Ma, and Y . Liu, “Machine learning testing: Survey, landscapes and horizons,” IEEE Transactions on Software Engi- neering, vol. 48, no. 1, pp. 1–36, 2022, doi: 10.1109/TSE.2019.2962027
-
[37]
Machine learning operations (MLOps): Overview, definition, and architecture,
D. Kreuzberger, N. K ¨uhl, and S. Hirschl, “Machine learning operations (MLOps): Overview, definition, and architecture,” IEEE Access, vol. 11, pp. 31866–31879, 2023, doi: 10.1109/ACCESS.2023.3262138
-
[38]
In: Proceedings of the 2020 CHI Conference on Human Factors in Computing Systems
S. Chattopadhyay, I. Prasad, A. Z. Henley, A. Sarma, and T. Barik, “What’s wrong with computational notebooks? Pain points, needs, and design opportunities,” in Proceedings of the CHI Conference on Human Factors in Computing Systems, 2020, pp. 1–12. doi: 10.1145/3313831.3376729
-
[39]
Exploration and explanation in computational notebooks,
A. Rule, A. Tabard, and J. D. Hollan, “Exploration and explanation in computational notebooks,” in Proceedings of the CHI Conference on Human Factors in Computing Systems, 2018, pp. 1–12. doi: 10.1145/3173574.3173606
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.