InfiGFusion: Graph-on-Logits Distillation via Efficient Gromov-Wasserstein for Model Fusion
Pith reviewed 2026-05-25 08:39 UTC · model grok-4.3
The pith
Fusing LLMs by distilling co-activation graphs from top-k logits captures cross-token dependencies that independent logit averaging misses.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
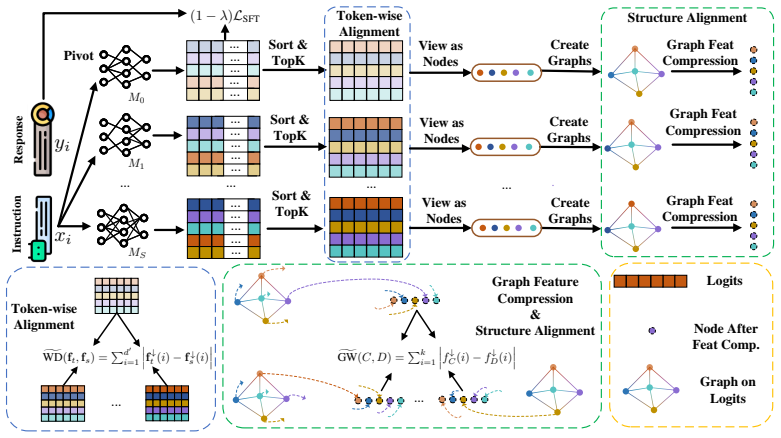
The paper presents Graph-on-Logits Distillation, which builds a co-activation graph whose nodes are vocabulary channels and whose edges measure joint activation strength, then transfers this structure between heterogeneous models via an efficient Gromov-Wasserstein alignment that preserves the relative geometry of the graphs.
What carries the argument
Graph-on-Logits Distillation loss, constructed by aggregating outer products of top-k logits into a global co-activation graph and aligned with a sorting-based O(n log n) approximation to Gromov-Wasserstein distance.
If this is right
- The fused model records +35.6 on Multistep Arithmetic and +37.06 on Causal Judgement relative to supervised fine-tuning.
- GLD improves both quality and stability of fusion across multiple settings and model pairs.
- The closed-form approximation carries provable guarantees while remaining fast enough for practical use.
- The method delivers gains on eleven benchmarks covering reasoning, coding, and mathematics.
Where Pith is reading between the lines
- If the co-activation graphs remain stable across prompt lengths, the same fused weights could serve multiple tasks without per-task re-alignment.
- The graph view might extend naturally to fusing models that differ in tokenizer or vocabulary size by first mapping their logit spaces.
- Replacing the fixed top-k selection with an entropy-dependent threshold could reduce noise when models are uncertain about the next token.
Load-bearing premise
That the global co-activation graph built from outer products of top-k logits encodes the semantic dependencies needed to align models with different generation behaviors.
What would settle it
Run the identical fusion procedure twice on the same pair of models, once with the full GLD loss and once after replacing every edge weight in the co-activation graph with a constant; if the two fused models achieve statistically indistinguishable scores on Multistep Arithmetic and Causal Judgement, the graph structure contributes nothing beyond ordinary logit averaging.
Figures



read the original abstract
Recent advances in large language models (LLMs) have intensified efforts to fuse heterogeneous open-source models into a unified system that inherits their complementary strengths. Existing logit-based fusion methods maintain inference efficiency but treat vocabulary dimensions independently, overlooking semantic dependencies encoded by cross-dimension interactions. These dependencies reflect how token types interact under a model's internal reasoning and are essential for aligning models with diverse generation behaviors. To explicitly model these dependencies, we propose \textbf{InfiGFusion}, the first structure-aware fusion framework with a novel \textit{Graph-on-Logits Distillation} (GLD) loss. Specifically, we retain the top-$k$ logits per output and aggregate their outer products across sequence positions to form a global co-activation graph, where nodes represent vocabulary channels and edges quantify their joint activations. To ensure scalability and efficiency, we design a sorting-based closed-form approximation that reduces the original $O(n^4)$ cost of Gromov-Wasserstein distance to $O(n \log n)$, with provable approximation guarantees. Experiments across multiple fusion settings show that GLD consistently improves fusion quality and stability. InfiGFusion outperforms SOTA models and fusion baselines across 11 benchmarks spanning reasoning, coding, and mathematics. It shows particular strength in complex reasoning tasks, with +35.6 improvement on Multistep Arithmetic and +37.06 on Causal Judgement over SFT, demonstrating superior multi-step and relational inference.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces InfiGFusion, a structure-aware LLM fusion method that constructs global co-activation graphs from outer products of top-k logits across sequence positions and aligns models via a Graph-on-Logits Distillation (GLD) loss based on Gromov-Wasserstein distance. It proposes a sorting-based closed-form approximation claimed to reduce GW computation from O(n^4) to O(n log n) with provable guarantees, and reports consistent improvements over SOTA models and fusion baselines on 11 benchmarks in reasoning, coding, and mathematics, including large gains (+35.6 on Multistep Arithmetic, +37.06 on Causal Judgement) relative to SFT.
Significance. If the empirical gains and approximation guarantees hold under scrutiny, the work would offer a scalable way to incorporate cross-dimension logit dependencies into fusion, addressing a gap in prior logit-based methods that treat dimensions independently. The O(n log n) reduction and explicit graph construction are potentially useful strengths for practical deployment of fused models on complex tasks.
major comments (3)
- [§4.2, Eq. (8)] §4.2 and Eq. (8): the claim that the sorting-based approximation preserves the essential structure of the Gromov-Wasserstein distance for co-activation graphs is not accompanied by a quantitative bound on the approximation error in terms of the fusion objective; without this, it is unclear whether the reported gains on reasoning benchmarks can be attributed to the GLD loss rather than the approximation artifact.
- [Table 2] Table 2, Multistep Arithmetic and Causal Judgement rows: the +35.6 and +37.06 absolute improvements over SFT are presented without standard deviations across runs or statistical significance tests; given that these are the largest reported deltas and central to the claim of superior multi-step reasoning, the lack of variance reporting undermines the strength of the outperformance conclusion.
- [§3.1] §3.1: the construction of the global co-activation graph via aggregation of outer products of top-k logits assumes that these pairwise activations encode the semantic dependencies needed for alignment, but no ablation is shown that isolates the contribution of the graph structure versus simply using the top-k logits without the GW term.
minor comments (3)
- [§3.1] The notation for the co-activation matrix G in §3.1 is introduced without an explicit definition of how sequence-position aggregation is normalized, making it difficult to reproduce the graph construction.
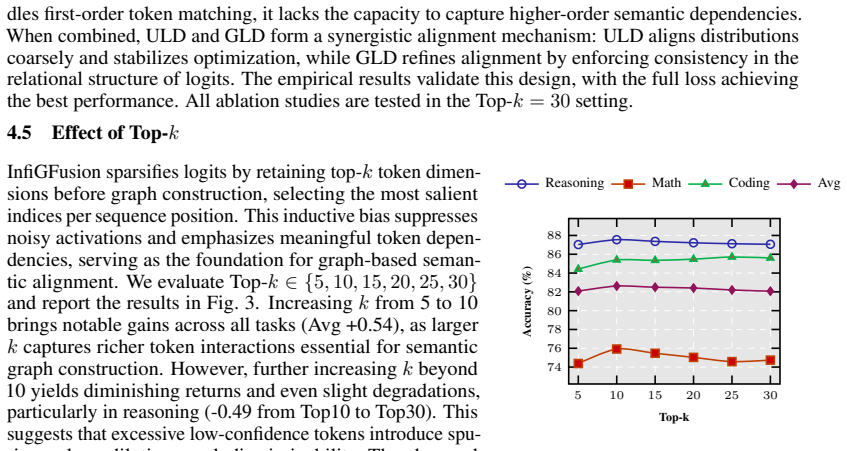
- [Figure 3] Figure 3 caption does not specify the value of k used for the top-k logits or whether results are sensitive to this hyperparameter.
- [Related Work] The related-work section omits recent logit-fusion papers that also operate on vocabulary distributions (e.g., those using optimal transport directly on logits), which would help situate the novelty of the graph-based extension.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript accordingly to strengthen the presentation of the approximation analysis, statistical reporting, and ablations.
read point-by-point responses
-
Referee: [§4.2, Eq. (8)] §4.2 and Eq. (8): the claim that the sorting-based approximation preserves the essential structure of the Gromov-Wasserstein distance for co-activation graphs is not accompanied by a quantitative bound on the approximation error in terms of the fusion objective; without this, it is unclear whether the reported gains on reasoning benchmarks can be attributed to the GLD loss rather than the approximation artifact.
Authors: We acknowledge that the provable guarantees provided for the sorting-based approximation are stated in terms of the GW distance itself rather than a direct quantitative bound on its effect within the fusion objective. In the revision we will add a discussion of error propagation from the approximation into the GLD loss and its potential impact on downstream performance. revision: yes
-
Referee: [Table 2] Table 2, Multistep Arithmetic and Causal Judgement rows: the +35.6 and +37.06 absolute improvements over SFT are presented without standard deviations across runs or statistical significance tests; given that these are the largest reported deltas and central to the claim of superior multi-step reasoning, the lack of variance reporting undermines the strength of the outperformance conclusion.
Authors: We agree that variance reporting and significance testing are needed for these key results. The revised manuscript will include standard deviations computed over multiple runs and paired statistical significance tests for the Multistep Arithmetic and Causal Judgement entries. revision: yes
-
Referee: [§3.1] §3.1: the construction of the global co-activation graph via aggregation of outer products of top-k logits assumes that these pairwise activations encode the semantic dependencies needed for alignment, but no ablation is shown that isolates the contribution of the graph structure versus simply using the top-k logits without the GW term.
Authors: We will add an ablation study that directly compares the full GLD loss against a variant that aggregates top-k logits without the Gromov-Wasserstein term. This will isolate the contribution of the graph structure to the observed gains. revision: yes
Circularity Check
No significant circularity; derivation introduces independent components
full rationale
The abstract and method description define a novel GLD loss via top-k logit outer products forming co-activation graphs, followed by a sorting-based O(n log n) GW approximation with stated guarantees. These steps are constructive definitions of new quantities rather than reductions of outputs to fitted inputs or self-citations. No load-bearing self-citation chains, uniqueness theorems, or renamings of known results appear; performance claims rest on external benchmarks. The derivation chain remains self-contained against the described inputs.
Axiom & Free-Parameter Ledger
free parameters (1)
- top-k
axioms (1)
- domain assumption Cross-dimension interactions in logits reflect semantic dependencies that are essential for aligning models with diverse generation behaviors
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
we design a sorting-based closed-form approximation that reduces the original O(n^4) cost of Gromov-Wasserstein distance to O(n log n), with provable approximation guarantees... |GW(C,D)−gGW(C,D)|≤n^{-1}n^{-2}+m^{-1}m^{-2}
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanembed_add unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Dynamic Graph Construction... adjacency matrix Cb(i,j)=∑t zt(i)·zt(j)
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Proposition 2 (Lipschitz Constants Comparison)... LGW=O(R^3/D)<LWD=O(√D)<LKL=O(e^{RD})
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 4 Pith papers
-
Discovering Physical Directions in Weight Space: Composing Neural PDE Experts
Fine-tuning neural PDE operators to regime endpoints reveals a physical direction in weight space that CCM uses to compose accurate merged models for new or extrapolated regimes from metadata or short prefixes.
-
FeatCal: Feature Calibration for Post-Merging Models
FeatCal reduces feature drift in merged models via layer-wise closed-form calibration on a small dataset, outperforming prior post-merging methods on CLIP and GLUE benchmarks with high sample efficiency.
-
E-PMQ: Expert-Guided Post-Merge Quantization with Merged-Weight Anchoring
E-PMQ improves 4-bit quantization accuracy on merged models by 8-42 points across CLIP and GLUE tasks through expert-guided calibration and merged-weight anchoring.
-
Geometry Conflict: Explaining and Controlling Forgetting in LLM Continual Post-Training
Forgetting in LLM continual post-training is a geometry conflict between task-induced covariance structures and the evolving model state, controlled by gating Wasserstein barycenter merging on measured conflict.
Reference graph
Works this paper leans on
-
[1]
Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Eric Hambro, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. Toolformer: Language models can teach themselves to use tools.Advances in Neural Information Processing Systems, 36:68539– 68551, 2023
work page 2023
-
[2]
Hui Yang, Sifu Yue, and Yunzhong He. Auto-gpt for online decision making: Benchmarks and additional opinions.arXiv preprint arXiv:2306.02224, 2023
-
[3]
Mixture-of-Agents Enhances Large Language Model Capabilities
Junlin Wang, Jue Wang, Ben Athiwaratkun, Ce Zhang, and James Zou. Mixture-of-agents enhances large language model capabilities.arXiv preprint arXiv:2406.04692, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
Length-Controlled AlpacaEval: A Simple Way to Debias Automatic Evaluators
Yann Dubois, Balázs Galambosi, Percy Liang, and Tatsunori B Hashimoto. Length-controlled alpacaeval: A simple way to debias automatic evaluators.arXiv preprint arXiv:2404.04475, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
Llm-blender: Ensembling large language models with pairwise ranking and generative fusion
Dongfu Jiang, Xiang Ren, and Bill Yuchen Lin. Llm-blender: Ensembling large language models with pairwise ranking and generative fusion. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 14165–14178, 2023
work page 2023
-
[6]
Chenhao Fang, Xiaohan Li, Zezhong Fan, Jianpeng Xu, Kaushiki Nag, Evren Korpeoglu, Sushant Kumar, and Kannan Achan. Llm-ensemble: Optimal large language model ensemble method for e-commerce product attribute value extraction. InProceedings of the 47th Interna- tional ACM SIGIR Conference on Research and Development in Information Retrieval, pages 2910–2914, 2024
work page 2024
-
[7]
Sparse upcycling: Training mixture-of-experts from dense checkpoints
Aran Komatsuzaki, Joan Puigcerver, James Lee-Thorp, Carlos Riquelme Ruiz, Basil Mustafa, Joshua Ainslie, Yi Tay, Mostafa Dehghani, and Neil Houlsby. Sparse upcycling: Training mixture-of-experts from dense checkpoints. InThe Eleventh International Conference on Learning Representations
-
[8]
Glam: Efficient scaling of language models with mixture-of-experts
Nan Du, Yanping Huang, Andrew M Dai, Simon Tong, Dmitry Lepikhin, Yuanzhong Xu, Maxim Krikun, Yanqi Zhou, Adams Wei Yu, Orhan Firat, et al. Glam: Efficient scaling of language models with mixture-of-experts. InInternational conference on machine learning, pages 5547–5569. PMLR, 2022
work page 2022
-
[9]
Zixiang Chen, Yihe Deng, Yue Wu, Quanquan Gu, and Yuanzhi Li. Towards understanding the mixture-of-experts layer in deep learning.Advances in neural information processing systems, 35:23049–23062, 2022
work page 2022
-
[10]
Prateek Yadav, Derek Tam, Leshem Choshen, Colin A Raffel, and Mohit Bansal. Ties-merging: Resolving interference when merging models.Advances in Neural Information Processing Systems, 36:7093–7115, 2023
work page 2023
-
[11]
Merging models with fisher-weighted averaging
Michael S Matena and Colin A Raffel. Merging models with fisher-weighted averaging. Advances in Neural Information Processing Systems, 35:17703–17716, 2022
work page 2022
-
[12]
Mitchell Wortsman, Gabriel Ilharco, Samir Ya Gadre, Rebecca Roelofs, Raphael Gontijo-Lopes, Ari S Morcos, Hongseok Namkoong, Ali Farhadi, Yair Carmon, Simon Kornblith, et al. Model soups: averaging weights of multiple fine-tuned models improves accuracy without increasing inference time. InInternational conference on machine learning, pages 23965–23998. P...
work page 2022
-
[13]
Knowl- edge fusion of large language models
Fanqi Wan, Xinting Huang, Deng Cai, Xiaojun Quan, Wei Bi, and Shuming Shi. Knowl- edge fusion of large language models. InThe Twelfth International Conference on Learning Representations
-
[14]
Profuser: Progressive fusion of large language models.arXiv preprint arXiv:2408.04998, 2024
Tianyuan Shi, Fanqi Wan, Canbin Huang, Xiaojun Quan, Chenliang Li, Ming Yan, and Ji Zhang. Profuser: Progressive fusion of large language models.arXiv preprint arXiv:2408.04998, 2024. 11
-
[15]
Zhaoyi Yan, Yiming Zhang, Baoyi He, Yuhao Fu, Qi Zhou, Zhijie Sang, Chunlin Ji, Shengyu Zhang, Fei Wu, and Hongxia Yang. Infifusion: A unified framework for enhanced cross-model reasoning via llm fusion.arXiv preprint arXiv:2501.02795, 2025
-
[16]
A setwise approach for effective and highly efficient zero-shot ranking with large language models
Shengyao Zhuang, Honglei Zhuang, Bevan Koopman, and Guido Zuccon. A setwise approach for effective and highly efficient zero-shot ranking with large language models. InProceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval, pages 38–47, 2024
work page 2024
-
[17]
Chris Lu, Samuel Holt, Claudio Fanconi, Alex Chan, Jakob Foerster, Mihaela van der Schaar, and Robert Lange. Discovering preference optimization algorithms with and for large language models.Advances in Neural Information Processing Systems, 37:86528–86573, 2024
work page 2024
-
[18]
Hongteng Xu, Dixin Luo, and Lawrence Carin. Scalable gromov-wasserstein learning for graph partitioning and matching.Advances in neural information processing systems, 32, 2019
work page 2019
-
[19]
Gromov-wasserstein averaging of kernel and distance matrices
Gabriel Peyré, Marco Cuturi, and Justin Solomon. Gromov-wasserstein averaging of kernel and distance matrices. InInternational conference on machine learning, pages 2664–2672. PMLR, 2016
work page 2016
-
[20]
React: Synergizing reasoning and acting in language models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models. InInternational Conference on Learning Representations (ICLR), 2023
work page 2023
-
[21]
Yongliang Shen, Kaitao Song, Xu Tan, Dongsheng Li, Weiming Lu, and Yueting Zhuang. Hugginggpt: Solving ai tasks with chatgpt and its friends in hugging face.Advances in Neural Information Processing Systems, 36:38154–38180, 2023
work page 2023
-
[22]
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, et al. Judging llm-as-a-judge with mt-bench and chatbot arena.Advances in Neural Information Processing Systems, 36:46595–46623, 2023
work page 2023
-
[23]
Agentbench: Evaluating llms as agents
Xiao Liu, Hao Yu, Hanchen Zhang, Yifan Xu, Xuanyu Lei, Hanyu Lai, Yu Gu, Hangliang Ding, Kaiwen Men, Kejuan Yang, et al. Agentbench: Evaluating llms as agents. InICLR, 2024
work page 2024
-
[24]
Self-consistency improves chain of thought reasoning in language models
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc V Le, Ed H Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. Self-consistency improves chain of thought reasoning in language models. InThe Eleventh International Conference on Learning Representations
-
[25]
Distilling the Knowledge in a Neural Network
Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. Distilling the knowledge in a neural network. arXiv preprint arXiv:1503.02531, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[26]
Tinybert: Distilling bert for natural language understanding
Xiaoqi Jiao, Yichun Yin, Lifeng Shang, Xin Jiang, Xiao Chen, Linlin Li, Fang Wang, and Qun Liu. Tinybert: Distilling bert for natural language understanding. InFindings of the Association for Computational Linguistics: EMNLP 2020, pages 4163–4174, 2020
work page 2020
-
[27]
Gromov–wasserstein distances and the metric approach to object matching
Facundo Mémoli. Gromov–wasserstein distances and the metric approach to object matching. Foundations of computational mathematics, 11:417–487, 2011
work page 2011
-
[28]
Fused gromov-wasserstein distance for structured objects.Algorithms, 13(9):212, 2020
Titouan Vayer, Laetitia Chapel, Rémi Flamary, Romain Tavenard, and Nicolas Courty. Fused gromov-wasserstein distance for structured objects.Algorithms, 13(9):212, 2020
work page 2020
-
[29]
Learning graphons via struc- tured gromov-wasserstein barycenters
Hongteng Xu, Dixin Luo, Lawrence Carin, and Hongyuan Zha. Learning graphons via struc- tured gromov-wasserstein barycenters. InProceedings of the AAAI Conference on Artificial Intelligence, volume 35, pages 10505–10513, 2021
work page 2021
-
[30]
Yuanyi Wang, Haifeng Sun, Chengsen Wang, Mengde Zhu, Jingyu Wang, Wei Tang, Qi Qi, Zirui Zhuang, and Jianxin Liao. Interdependency matters: Graph alignment for multivariate time series anomaly detection.arXiv preprint arXiv:2410.08877, 2024
-
[31]
Yuanyi Wang, Haifeng Sun, Jingyu Wang, Qi Qi, Shaoling Sun, and Jianxin Liao. Gradient flow of energy: A general and efficient approach for entity alignment decoding.arXiv preprint arXiv:2401.12798, 2024. 12
-
[32]
Towards semantic consistency: Dirichlet energy driven robust multi-modal entity alignment
Yuanyi Wang, Haifeng Sun, Jiabo Wang, Jingyu Wang, Wei Tang, Qi Qi, Shaoling Sun, and Jianxin Liao. Towards semantic consistency: Dirichlet energy driven robust multi-modal entity alignment. In2024 IEEE 40th International Conference on Data Engineering (ICDE), pages 3559–3572. IEEE, 2024
work page 2024
-
[33]
Gromov-wasserstein factorization models for graph clustering
Hongtengl Xu. Gromov-wasserstein factorization models for graph clustering. InProceedings of the AAAI conference on artificial intelligence, volume 34, pages 6478–6485, 2020
work page 2020
-
[34]
Nicolas Boizard, Kevin El Haddad, CELINE HUDELOT, and Pierre Colombo. Towards cross- tokenizer distillation: the universal logit distillation loss for llms.Transactions on Machine Learning Research
-
[35]
HuggingFace. Model outputs documentation. https://huggingface.co/docs/ transformers/en/main_classes/output, 2025
work page 2025
-
[36]
Superfiltering: Weak-to-strong data filtering for fast instruction-tuning
Ming Li, Yong Zhang, Shwai He, Zhitao Li, Hongyu Zhao, Jianzong Wang, Ning Cheng, and Tianyi Zhou. Superfiltering: Weak-to-strong data filtering for fast instruction-tuning. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 14255–14273, 2024
work page 2024
-
[37]
Jia Li, Edward Beeching, Lewis Tunstall, Ben Lipkin, Roman Soletskyi, Shengyi Huang, Kashif Rasul, Longhui Yu, Albert Q Jiang, Ziju Shen, et al. Numinamath: The largest public dataset in ai4maths with 860k pairs of competition math problems and solutions.Hugging Face repository, 13:9, 2024
work page 2024
-
[38]
Kodcode: A diverse, challenging, and verifiable synthetic dataset for coding
Zhangchen Xu, Yang Liu, Yueqin Yin, Mingyuan Zhou, and Radha Poovendran. Kodcode: A diverse, challenging, and verifiable synthetic dataset for coding. 2025
work page 2025
-
[39]
An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, et al. Qwen2. 5 technical report.arXiv preprint arXiv:2412.15115, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[40]
Mistral-small-24b-instruct-2501
Mistral AI. Mistral-small-24b-instruct-2501. https://huggingface.co/mistralai/ Mistral-Small-24B-Instruct-2501, 2025
work page 2025
-
[41]
Marah Abdin, Jyoti Aneja, Harkirat Behl, Sébastien Bubeck, Ronen Eldan, Suriya Gunasekar, Michael Harrison, Russell J Hewett, Mojan Javaheripi, Piero Kauffmann, et al. Phi-4 technical report.arXiv preprint arXiv:2412.08905, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[42]
Online knowledge distillation via collaborative learning
Qiushan Guo, Xinjiang Wang, Yichao Wu, Zhipeng Yu, Ding Liang, Xiaolin Hu, and Ping Luo. Online knowledge distillation via collaborative learning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 11020–11029, 2020
work page 2020
-
[43]
Fusechat: Knowl- edge fusion of chat models.arXiv preprint arXiv:2408.07990, 2024
Fanqi Wan, Longguang Zhong, Ziyi Yang, Ruijun Chen, and Xiaojun Quan. Fusechat: Knowl- edge fusion of chat models.arXiv preprint arXiv:2408.07990, 2024
-
[44]
Challenging big-bench tasks and whether chain-of-thought can solve them
Mirac Suzgun, Nathan Scales, Nathanael Schärli, Sebastian Gehrmann, Yi Tay, Hyung Won Chung, Aakanksha Chowdhery, Quoc V Le, Ed H Chi, Denny Zhou, et al. Challenging big-bench tasks and whether chain-of-thought can solve them. InACL (Findings), 2023
work page 2023
-
[45]
Vikas Yadav, Steven Bethard, and Mihai Surdeanu. Quick and (not so) dirty: Unsupervised selection of justification sentences for multi-hop question answering. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 2578–2589, 2019
work page 2019
-
[46]
Measuring massive multitask language understanding
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding. InInternational Conference on Learning Representations
-
[47]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168, 2021. 13
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[48]
Measuring mathematical problem solving with the math dataset
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the math dataset. In Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2)
-
[49]
Theoremqa: A theorem-driven question answering dataset
Wenhu Chen, Ming Yin, Max Ku, Pan Lu, Yixin Wan, Xueguang Ma, Jianyu Xu, Xinyi Wang, and Tony Xia. Theoremqa: A theorem-driven question answering dataset. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, 2023
work page 2023
-
[50]
Program Synthesis with Large Language Models
Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, et al. Program synthesis with large language models.arXiv preprint arXiv:2108.07732, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[51]
Evaluating Large Language Models Trained on Code
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde De Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. Evaluating large language models trained on code.arXiv preprint arXiv:2107.03374, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[52]
Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs
Dheeru Dua, Yizhong Wang, Pradeep Dasigi, Gabriel Stanovsky, Sameer Singh, and Matt Gard- ner. Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. InProceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Paper...
work page 2019
-
[53]
Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi, and Yejin Choi. Hellaswag: Can a machine really finish your sentence? InProceedings of the 57th Annual Meeting of the Association for Computational Linguistics. Association for Computational Linguistics, 2019
work page 2019
-
[54]
Instruction-Following Evaluation for Large Language Models
Jeffrey Zhou, Tianjian Lu, Swaroop Mishra, Siddhartha Brahma, Sujoy Basu, Yi Luan, Denny Zhou, and Le Hou. Instruction-following evaluation for large language models.arXiv preprint arXiv:2311.07911, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[55]
Softsort: A continuous relaxation for the argsort operator
Sebastian Prillo and Julian Eisenschlos. Softsort: A continuous relaxation for the argsort operator. InInternational Conference on Machine Learning, pages 7793–7802. PMLR, 2020
work page 2020
-
[56]
Fast differentiable sorting and ranking
Mathieu Blondel, Olivier Teboul, Quentin Berthet, and Josip Djolonga. Fast differentiable sorting and ranking. InInternational Conference on Machine Learning, pages 950–959. PMLR, 2020
work page 2020
-
[57]
Stability and generalization.Journal of machine learning research, 2(Mar):499–526, 2002
Olivier Bousquet and André Elisseeff. Stability and generalization.Journal of machine learning research, 2(Mar):499–526, 2002
work page 2002
-
[58]
Mher Safaryan, Alexandra Peste, and Dan Alistarh. Knowledge distillation performs partial variance reduction.Advances in Neural Information Processing Systems, 36:75229–75258, 2023
work page 2023
-
[59]
OpenCompass Contributors. Opencompass: A universal evaluation platform for foundation models.https://github.com/open-compass/opencompass, 2023
work page 2023
-
[60]
Jiawei Liu, Chunqiu Steven Xia, Yuyao Wang, and Lingming Zhang. Is your code generated by chatGPT really correct? rigorous evaluation of large language models for code generation. In Thirty-seventh Conference on Neural Information Processing Systems, 2023
work page 2023
-
[61]
Minillm: Knowledge distillation of large language models
Yuxian Gu, Li Dong, Furu Wei, and Minlie Huang. Minillm: Knowledge distillation of large language models. InThe Twelfth International Conference on Learning Representations
-
[62]
Dual-space knowledge distillation for large language models
Songming Zhang, Xue Zhang, Zengkui Sun, Yufeng Chen, and Jinan Xu. Dual-space knowledge distillation for large language models. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 18164–18181, 2024
work page 2024
-
[63]
Self-Instruct: Aligning Language Models with Self-Generated Instructions
Yizhong Wang, Yeganeh Kordi, Swaroop Mishra, Alisa Liu, Noah A Smith, Daniel Khashabi, and Hannaneh Hajishirzi. Self-instruct: Aligning language models with self-generated instruc- tions.arXiv preprint arXiv:2212.10560, 2022. 14
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[64]
Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality.See https://vicuna
Wei-Lin Chiang, Zhuohan Li, Ziqing Lin, Ying Sheng, Zhanghao Wu, Hao Zhang, Lianmin Zheng, Siyuan Zhuang, Yonghao Zhuang, Joseph E Gonzalez, et al. Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality.See https://vicuna. lmsys. org (accessed 14 April 2023), 2(3):6, 2023
work page 2023
-
[65]
Yizhong Wang, Swaroop Mishra, Pegah Alipoormolabashi, Yeganeh Kordi, Amirreza Mirzaei, Anjana Arunkumar, Arjun Ashok, Arut Selvan Dhanasekaran, Atharva Naik, David Stap, et al. Super-naturalinstructions: Generalization via declarative instructions on 1600+ nlp tasks.arXiv preprint arXiv:2204.07705, 2022
-
[66]
Language models are unsupervised multitask learners.OpenAI blog, 1(8):9, 2019
Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, et al. Language models are unsupervised multitask learners.OpenAI blog, 1(8):9, 2019
work page 2019
-
[67]
OPT: Open Pre-trained Transformer Language Models
Susan Zhang, Stephen Roller, Naman Goyal, Mikel Artetxe, Moya Chen, Shuohui Chen, Christopher Dewan, Mona Diab, Xian Li, Xi Victoria Lin, et al. Opt: Open pre-trained transformer language models.arXiv preprint arXiv:2205.01068, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[68]
Niklas Muennighoff, Thomas Wang, Lintang Sutawika, Adam Roberts, Stella Biderman, Teven Le Scao, M Saiful Bari, Sheng Shen, Zheng Xin Yong, Hailey Schoelkopf, et al. Crosslingual generalization through multitask finetuning. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 15991–16111,...
work page 2023
-
[69]
Sorting Stability Error.Denote by ϵsort the error incurred by the potential change in the sorted order when the features are perturbed. Under the assumption that the true features have a positive minimal gap, the sorting operator is stable, or, in practice, one can use a soft sort with known Lipschitz properties. Hence, only small errors are induced in th...
-
[70]
If an algorithm has γ-uniform stability, then its generalization error can be controlled in O(γ)order of magnitude. 2.γ is approximately of the order of L/n, where L is a Lipschitz constant of the loss function andnis the number of samples. C.2 Lipschitz constant of GW loss Lemma 1(GW Lipschitz constant).LetL GW(T,S) =λGW 2(T,S). If∥S∥ 2 ≤R, then ∇SLGW 2 ...
-
[71]
for training. We follow [62] that evaluate on four benchmarks: SelfInst [63], VicunaEval [64], Super Natural Instructions (S-NI) [65], and the Dolly [61]. Models:For distillation, we distill from LLaMA3-8B, Mistral-7B, and Qwen2.5-7B into student models, including GPT2-120M [66], OPT-350M [67], and Bloomz-560M [68]. Training settings:Distillation uses LoR...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.