Steered Generation via Gradient-Based Optimization on Sparse Query Features
Pith reviewed 2026-05-25 05:29 UTC · model grok-4.3
The pith
Optimizing sparse query features via gradients steers LLM generation to meet planning rules and target cognitive styles.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
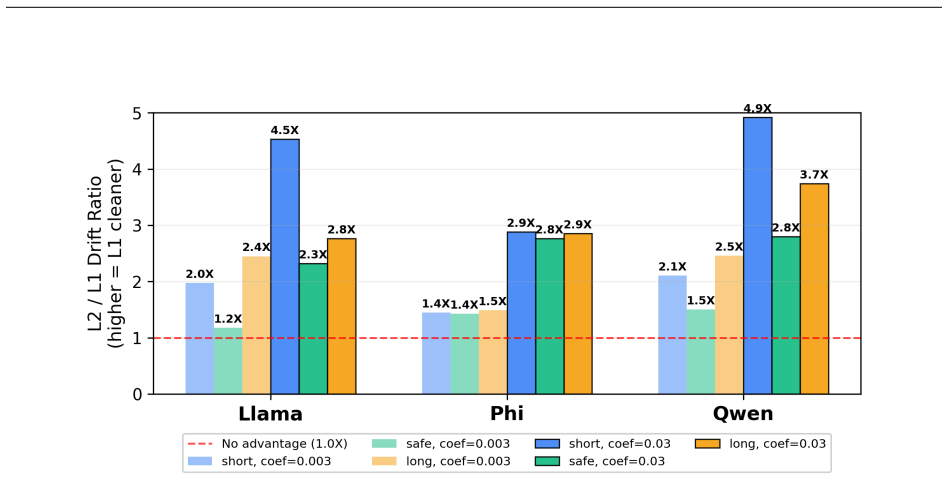
By decomposing attention query activations with sparse autoencoders and performing gradient optimization at inference time to match sparse codes against target class prototypes, the method produces generations that satisfy objective planning constraints in Textualized Gridworld and adjust feedback cognitive complexity in an educational domain, confirming that sparse query representations supply the disentanglement needed for unified control over logical and stylistic behaviors.
What carries the argument
Prototype-Based Sparse Steering, which decomposes query activations via SAEs into sparse features and uses gradient optimization to align them with class prototypes of desired behaviors.
If this is right
- Sparse query optimization satisfies objective rules such as safe versus short paths in controlled planning environments.
- The same framework steers cognitive complexity of feedback to specific levels of Bloom's Taxonomy.
- Query activations provide sharper and more interpretable steerability than interventions on dense model states.
- A single mechanism can enforce both hard logical constraints and stylistic properties without separate pipelines.
Where Pith is reading between the lines
- The method might be tested on tasks that combine planning with stylistic control, such as generating instructions under safety rules and readability targets.
- If the SAE features prove stable across model scales, the approach could be applied to steer outputs in domains like code generation or policy writing.
- One could check whether the gradient steps introduce measurable changes in output diversity or factual accuracy beyond the intended targets.
Load-bearing premise
Decomposing attention query activations with SAEs produces features disentangled enough that gradient optimization during inference can align them to prototypes without side effects or loss of coherence.
What would settle it
If optimized sparse query features produce text that consistently violates the planning constraints or misses the target Bloom's Taxonomy level while remaining fluent, that would show the claimed steerability does not hold.
Figures










read the original abstract
Latent steering exploits internal representations of Large Language Models (LLMs) to guide generation, yet interventions on dense states can entangle distinct semantic features. In this paper, we investigate attention query activations as a high-fidelity site for precise control, hypothesizing that manipulating the attention mechanism itself offers sharper steerability than general state interventions. We introduce Prototype-Based Sparse Steering, a framework that applies Sparse Autoencoders (SAEs) specifically to query activations, to decompose them into interpretable features, then apply gradient-based optimization during inference to align the sparse representation with class prototypes of target behaviors. To validate this architectural insight, we first analyze the mechanism in Textualized Gridworld, a controlled environment for verifiable planning constraints. We demonstrate that optimizing sparse query features enables effective navigation of rigid planning requirements (i.e., safe vs. short paths), confirming the method's ability to satisfy objective rules. We then demonstrate the framework's versatility by training SAEs on a high-dimensional educational domain, where the framework steers the cognitive complexity of feedback (i.e., Bloom's Taxonomy). Our experiments establish that sparse query representations provide the necessary disentanglement for unified, interpretable control over both logical planning and stylistic nuance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Prototype-Based Sparse Steering, a method that applies Sparse Autoencoders (SAEs) to attention query activations in LLMs to decompose them into interpretable sparse features, followed by gradient-based optimization during inference to align these features with class prototypes of target behaviors. It validates the approach first in a Textualized Gridworld environment to demonstrate navigation of rigid planning constraints (safe vs. short paths) and second in an educational domain to steer the cognitive complexity of feedback according to Bloom's Taxonomy, claiming that sparse query representations enable unified, interpretable control over logical and stylistic aspects of generation.
Significance. If the empirical results hold with appropriate controls and baselines, the work could advance latent steering techniques by targeting the attention mechanism for sharper disentanglement than dense state interventions, with potential applications in safety-constrained planning and educational feedback generation. The use of SAEs for feature decomposition and prototype alignment during inference is a notable architectural choice that merits further exploration if supported by reproducible evidence.
major comments (2)
- [Abstract] Abstract: The abstract describes experiments verifying navigation of planning constraints and steering of cognitive complexity but provides no quantitative results, error bars, baselines, or controls. This omission makes it impossible to evaluate whether the data supports the central claim of effective disentangled control.
- [Experiments (Gridworld and educational domain)] The method's reliance on class prototypes (listed as a free parameter) and SAE training on query activations assumes these provide the necessary disentanglement without side effects; however, without reported ablations showing that gradient alignment to one prototype leaves unrelated features unaffected, the evidence for unified control over both planning and stylistic tasks remains incomplete.
minor comments (2)
- [Introduction] The title and abstract use 'Sparse Query Features' but the method description would benefit from explicit notation distinguishing query activations from key/value activations in the attention mechanism.
- [Method] Clarify how the gradient optimization is performed at inference time without degrading generation quality or introducing artifacts, perhaps with an equation for the optimization objective.
Simulated Author's Rebuttal
We thank the referee for these focused comments on the abstract and experimental validation. We address each point below and will revise the manuscript to strengthen the presentation of results and controls.
read point-by-point responses
-
Referee: [Abstract] Abstract: The abstract describes experiments verifying navigation of planning constraints and steering of cognitive complexity but provides no quantitative results, error bars, baselines, or controls. This omission makes it impossible to evaluate whether the data supports the central claim of effective disentangled control.
Authors: We agree that the abstract would be strengthened by including key quantitative indicators. In the revised manuscript we will add concise results such as success rates for constraint satisfaction in Gridworld (with standard deviations) and classification accuracy for Bloom's Taxonomy levels, along with brief baseline comparisons, while remaining within length limits. revision: yes
-
Referee: [Experiments (Gridworld and educational domain)] The method's reliance on class prototypes (listed as a free parameter) and SAE training on query activations assumes these provide the necessary disentanglement without side effects; however, without reported ablations showing that gradient alignment to one prototype leaves unrelated features unaffected, the evidence for unified control over both planning and stylistic tasks remains incomplete.
Authors: The Gridworld results demonstrate that prototype alignment allows independent control over safety and length constraints, which indirectly supports limited interference. Nevertheless, we acknowledge the value of explicit ablation studies on cross-feature effects. We will add a new subsection with controlled ablations that measure activation changes on held-out features when optimizing a single prototype, using both the Gridworld and educational datasets. revision: yes
Circularity Check
No significant circularity identified
full rationale
The abstract and described method introduce Prototype-Based Sparse Steering by decomposing query activations with SAEs and aligning via gradient optimization to class prototypes. No load-bearing step reduces by construction to its own inputs: SAE decomposition and prototype alignment are presented as standard techniques applied to new sites (query activations), with validation on independent gridworld planning and Bloom's Taxonomy steering tasks. No self-definitional equations, fitted inputs renamed as predictions, or self-citation chains appear. The derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- class prototypes
axioms (1)
- domain assumption Sparse autoencoders applied to query activations decompose them into interpretable features that enable disentangled control
Reference graph
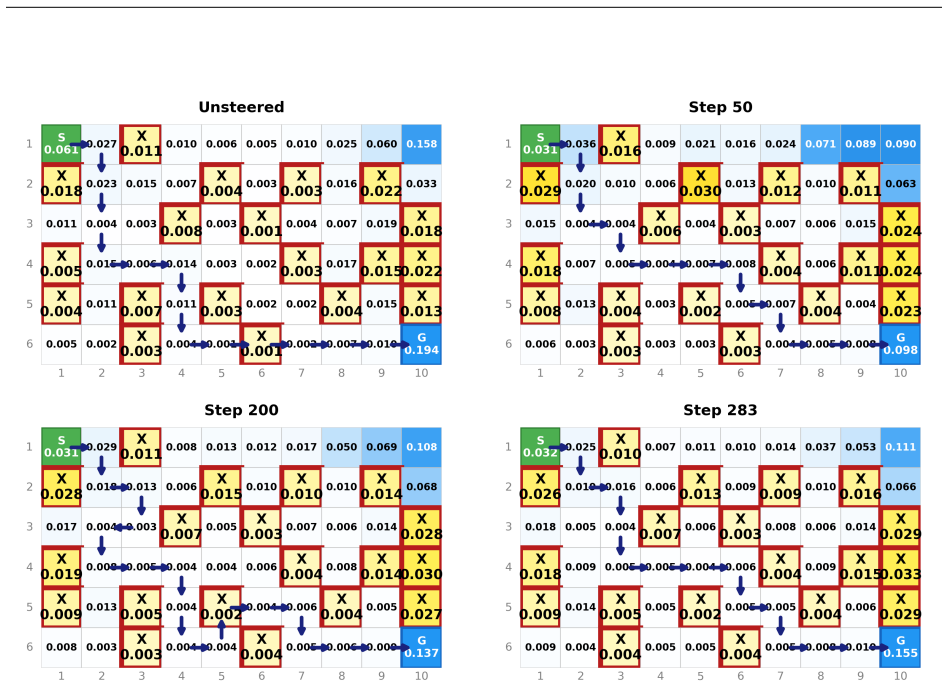
Works this paper leans on
-
[1]
Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone
Marah Abdin, Jyoti Aneja, Hany Awadalla, Ahmed Awadallah, Ammar Ahmad Awan, Nguyen Bach, Amit Bahree, Arash Bakhtiari, Jianmin Bao, Harkirat Behl, et al. Phi-3 technical report: A highly capable language model locally on your phone.arXiv preprint arXiv:2404.14219,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Saes are good for steering–if you select the right features
Dana Arad, Aaron Mueller, and Yonatan Belinkov. Saes are good for steering–if you select the right features. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pp. 10252–10270,
work page 2025
-
[3]
Steering large language model activations in sparse spaces.arXiv preprint arXiv:2503.00177,
Reza Bayat, Ali Rahimi-Kalahroudi, Mohammad Pezeshki, Sarath Chandar, and Pascal Vincent. Steering large language model activations in sparse spaces.arXiv preprint arXiv:2503.00177,
-
[4]
Language models are few-shot learners
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901,
work page 1901
-
[5]
Improving steering vectors by targeting sparse autoencoder features.arXiv preprint arXiv:2411.02193,
Sviatoslav Chalnev, Matthew Siu, and Arthur Conmy. Improving steering vectors by targeting sparse autoencoder features.arXiv preprint arXiv:2411.02193,
-
[6]
CorrSteer: Generation-Time LLM Steering via Correlated Sparse Autoencoder Features
Seonglae Cho, Zekun Wu, and Adriano Koshiyama. Corrsteer: Generation-time llm steering via correlated sparse autoencoder features.arXiv preprint arXiv:2508.12535,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Cheng-Ting Chou, George Liu, Jessica Sun, Cole Blondin, Kevin Zhu, Vasu Sharma, and Sean O’Brien. Causal language control in multilingual transformers via sparse feature steering.arXiv preprint arXiv:2507.13410,
-
[8]
Adaptively sparse transformers.arXiv preprint arXiv:1909.00015,
Gonçalo M Correia, Vlad Niculae, and André FT Martins. Adaptively sparse transformers.arXiv preprint arXiv:1909.00015,
-
[9]
Sparse Autoencoders Find Highly Interpretable Features in Language Models
Hoagy Cunningham, Aidan Ewart, Logan Riggs, Robert Huben, and Lee Sharkey. Sparse autoencoders find highly interpretable features in language models.arXiv preprint arXiv:2309.08600,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Sumanth Dathathri, Andrea Madotto, Janice Lan, Jane Hung, Eric Frank, Piero Molino, J. Yosinski, and Rosanne Liu. Plug and play language models: A simple approach to controlled text generation.ArXiv, September 2019a. Sumanth Dathathri, Andrea Madotto, Janice Lan, Jane Hung, Eric Frank, Piero Molino, Jason Yosinski, and Rosanne Liu. Plug and play language ...
-
[11]
Can Demircan, Tankred Saanum, Akshay Kumar Jagadish, Marcel Binz, and Eric Schulz. Sparse autoencoders reveal temporal difference learning in large language models.ArXiv, abs/2410.01280,
-
[12]
Evaluating feature steering: A case study in mitigating social biases, 2024.URL https://anthropic
Esin Durmus, Alex Tamkin, Jack Clark, Jerry Wei, Jonathan Marcus, Joshua Batson, Kunal Handa, Liane Lovitt, Meg Tong, Miles McCain, et al. Evaluating feature steering: A case study in mitigating social biases, 2024.URL https://anthropic. com/research/evaluating-feature-steering. Nelson Elhage, Neel Nanda, Catherine Olsson, Tom Henighan, Nicholas Joseph, B...
work page 2024
-
[13]
Nelson Elhage, Tristan Hume, Catherine Olsson, Nicholas Schiefer, Tom Henighan, Shauna Kravec, Zac Hatfield-Dodds, Robert Lasenby, Dawn Drain, Carol Chen, et al. Toy models of superposition.arXiv preprint arXiv:2209.10652,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Controllable llm reasoning via sparse autoencoder-based steering.arXiv preprint arXiv:2601.03595,
Yi Fang, Wenjie Wang, Mingfeng Xue, Boyi Deng, Fengli Xu, Dayiheng Liu, and Fuli Feng. Controllable llm reasoning via sparse autoencoder-based steering.arXiv preprint arXiv:2601.03595,
-
[15]
Andrey Galichin, Alexey Dontsov, Polina Druzhinina, Anton Razzhigaev, Oleg Y Rogov, Elena Tutubalina, and Ivan Oseledets. I have covered all the bases here: Interpreting reasoning features in large language models via sparse autoencoders.arXiv preprint arXiv:2503.18878,
-
[16]
Scaling and evaluating sparse autoencoders
Leo Gao, Tom Dupré la Tour, Henk Tillman, Gabriel Goh, Rajan Troll, Alec Radford, Ilya Sutskever, Jan Leike, and Jeffrey Wu. Scaling and evaluating sparse autoencoders.arXiv preprint arXiv:2406.04093,
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Trainable Greedy Decoding for Neural Machine Translation
15 Jiatao Gu, Kyunghyun Cho, and Victor OK Li. Trainable greedy decoding for neural machine translation. arXiv preprint arXiv:1702.02429,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
SAE-SSV: Supervised steering in sparse representation spaces for reliable control of language models
Zirui He, Mingyu Jin, Bo Shen, Ali Payani, Yongfeng Zhang, and Mengnan Du. SAE-SSV: Supervised steering in sparse representation spaces for reliable control of language models. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, November 2025a. Zirui He, Mingyu Jin, Bo Shen, Ali Payani, Yongfeng Zhang, and Mengnan Du....
-
[19]
Editing Models with Task Arithmetic
Gabriel Ilharco, Marco Tulio Ribeiro, Mitchell Wortsman, Suchin Gururangan, Ludwig Schmidt, Hannaneh Hajishirzi, and Ali Farhadi. Editing models with task arithmetic.arXiv preprint arXiv:2212.04089,
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
A unified understanding and evaluation of steering methods.arXiv preprint arXiv:2502.02716,
Shawn Im and Yixuan Li. A unified understanding and evaluation of steering methods.arXiv preprint arXiv:2502.02716,
-
[21]
Shruti Joshi, Andrea Dittadi, Sébastien Lachapelle, and Dhanya Sridhar. Identifiable steering via sparse autoencoding of multi-concept shifts.arXiv preprint arXiv:2502.12179,
-
[22]
Prototype-based dynamic steering for large language models.arXiv preprint arXiv:2510.05498,
Ceyhun Efe Kayan and Li Zhang. Prototype-based dynamic steering for large language models.arXiv preprint arXiv:2510.05498,
-
[23]
Daniel Khashabi, Shane Lyu, Sewon Min, Lianhui Qin, Kyle Richardson, Sean Welleck, Hannaneh Hajishirzi, Tushar Khot, Ashish Sabharwal, Sameer Singh, et al. Prompt waywardness: The curious case of discretized interpretation of continuous prompts.arXiv preprint arXiv:2112.08348,
-
[24]
Zero-bias autoencoders and the benefits of co-adapting features
Kishore Konda, Roland Memisevic, and David Krueger. Zero-bias autoencoders and the benefits of co-adapting features.arXiv preprint arXiv:1402.3337,
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
Interpretable and steerable concept bottleneck sparse autoencoders.arXiv preprint arXiv:2512.10805,
Akshay Kulkarni, Tsui-Wei Weng, Vivek Narayanaswamy, Shusen Liu, Wesam A Sakla, and Kowshik Thopalli. Interpretable and steerable concept bottleneck sparse autoencoders.arXiv preprint arXiv:2512.10805,
-
[26]
Kenneth Li, Oam Patel, Fernanda Viégas, Hanspeter Pfister, and Martin Wattenberg. Inference-time intervention: Eliciting truthful answers from a language model.Advances in Neural Information Processing Systems, 36, 2024a. Tianle Li, Ge Zhang, Quy Duc Do, Xiang Yue, and Wenhu Chen. Long-context llms struggle with long in-context learning.Trans. Mach. Learn...
-
[27]
Lost in the Middle: How Language Models Use Long Contexts
Nelson F Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. Lost in the middle: How language models use long contexts. corr abs/2307.03172 (2023).arXiv preprint arXiv:2307.03172, 10, 2023a. Sheng Liu, Haotian Ye, Lei Xing, and James Zou. In-context vectors: Making in context learning more effective and contr...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[28]
Linguistic regularities in continuous space word repre- sentations
Tomáš Mikolov, Wen-tau Yih, and Geoffrey Zweig. Linguistic regularities in continuous space word repre- sentations. InProceedings of the 2013 conference of the north american chapter of the association for computational linguistics: Human language technologies, pp. 746–751,
work page 2013
-
[29]
Fatemehsadat Mireshghallah, Kartik Goyal, and Taylor Berg-Kirkpatrick. Mix and match: Learning-free controllable text generation using energy language models.arXiv preprint arXiv:2203.13299,
-
[30]
Rajiv Movva, Kenny Peng, Nikhil Garg, Jon M. Kleinberg, and Emma Pierson. Sparse autoencoders for hypothesis generation.ArXiv, abs/2502.04382,
-
[31]
Progress measures for grokking via mechanistic interpretability
Neel Nanda, Lawrence Chan, Tom Lieberum, Jess Smith, and Jacob Steinhardt. Progress measures for grokking via mechanistic interpretability.arXiv preprint arXiv:2301.05217,
work page internal anchor Pith review Pith/arXiv arXiv
-
[32]
Steering language model refusal with sparse autoencoders
Kyle O’Brien, David Majercak, Xavier Fernandes, Richard Edgar, Jingya Chen, Harsha Nori, Dean Carignan, Eric Horvitz, and Forough Poursabzi-Sangde. Steering language model refusal with sparse autoencoders. arXiv preprint arXiv:2411.11296,
-
[33]
The Linear Representation Hypothesis and the Geometry of Large Language Models
Kiho Park, Yo Joong Choe, and Victor Veitch. The linear representation hypothesis and the geometry of large language models.arXiv preprint arXiv:2311.03658,
work page internal anchor Pith review Pith/arXiv arXiv
-
[34]
Fine-tuning Aligned Language Models Compromises Safety, Even When Users Do Not Intend To!
Xiangyu Qi, Yi Zeng, Tinghao Xie, Pin-Yu Chen, Ruoxi Jia, Prateek Mittal, and Peter Henderson. Fine- tuning aligned language models compromises safety, even when users do not intend to!arXiv preprint arXiv:2310.03693,
work page internal anchor Pith review Pith/arXiv arXiv
-
[35]
Improving Dictionary Learning with Gated Sparse Autoencoders
Senthooran Rajamanoharan, Arthur Conmy, Lewis Smith, Tom Lieberum, Vikrant Varma, János Kramár, Rohin Shah, and Neel Nanda. Improving dictionary learning with gated sparse autoencoders.arXiv preprint arXiv:2404.16014, 2024a. Senthooran Rajamanoharan, Tom Lieberum, Nicolas Sonnerat, Arthur Conmy, Vikrant Varma, János Kramár, and Neel Nanda. Jumping ahead: ...
work page internal anchor Pith review Pith/arXiv arXiv
-
[36]
Abel Salinas and Fred Morstatter. The butterfly effect of altering prompts: How small changes and jailbreaks affect large language model performance.arXiv preprint arXiv:2401.03729,
-
[37]
Polysemanticity and capacity in neural networks.arXiv preprint arXiv:2210.01892,
Adam Scherlis, Kshitij Sachan, Adam S Jermyn, Joe Benton, and Buck Shlegeris. Polysemanticity and capacity in neural networks.arXiv preprint arXiv:2210.01892,
-
[38]
Interpretable steering of large language models with feature guided activation additions
Samuel Soo, Wesley Teng, Chandrasekaran Balaganesh, Tan Guoxian, and Ming YAN. Interpretable steering of large language models with feature guided activation additions. InICLR 2025 Workshop on Building Trust in Language Models and Applications,
work page 2025
-
[39]
18 Alessandro Stolfo, Vidhisha Balachandran, Safoora Yousefi, Eric Horvitz, and Besmira Nushi. Improving instruction-following in language models through activation steering.arXiv preprint arXiv:2410.12877,
-
[40]
Extracting latent steering vectors from pretrained language models.arXiv preprint arXiv:2205.05124,
Nishant Subramani, Nivedita Suresh, and Matthew E Peters. Extracting latent steering vectors from pretrained language models.arXiv preprint arXiv:2205.05124,
-
[41]
Massive Activations in Large Language Models
Mingjie Sun, Xinlei Chen, J Zico Kolter, and Zhuang Liu. Massive activations in large language models. arXiv preprint arXiv:2402.17762,
work page internal anchor Pith review Pith/arXiv arXiv
-
[42]
Universal sparse autoencoders: Interpretable cross-model concept alignment.ArXiv, abs/2502.03714,
Harrish Thasarathan, Julian Forsyth, Thomas Fel, Matthew Kowal, and Konstantinos Derpanis. Universal sparse autoencoders: Interpretable cross-model concept alignment.ArXiv, abs/2502.03714,
-
[43]
Analyzing the Structure of Attention in a Transformer Language Model
Jesse Vig and Yonatan Belinkov. Analyzing the structure of attention in a transformer language model.arXiv preprint arXiv:1906.04284,
work page internal anchor Pith review Pith/arXiv arXiv 1906
-
[44]
Anyi Wang, Xuansheng Wu, Dong Shu, Yunpu Ma, and Ninghao Liu. Enhancing llm steering through sparse autoencoder-based vector refinement.arXiv preprint arXiv:2509.23799, 2025a. Weixuan Wang, Jingyuan Yang, and Wei Peng. Semantics-adaptive activation intervention for llms via dynamic steering vectors. InICLR, 2025b. Jason Wei, Xuezhi Wang, Dale Schuurmans, ...
-
[45]
Kaiyue Wen, Huaqing Zhang, Hongzhou Lin, and Jingzhao Zhang. From sparse dependence to sparse attention: Unveiling how chain-of-thought enhances transformer sample efficiency.ArXiv, abs/2410.05459,
-
[46]
Tom White. Sampling generative networks.arXiv preprint arXiv:1609.04468,
work page internal anchor Pith review Pith/arXiv arXiv
-
[47]
Xuansheng Wu, Jiayi Yuan, Wenlin Yao, Xiaoming Zhai, and Ninghao Liu. Interpreting and steering llms with mutual information-based explanations on sparse autoencoders.arXiv preprint arXiv:2502.15576, 2025a. Zhengxuan Wu, Aryaman Arora, Atticus Geiger, Zheng Wang, Jing Huang, Dan Jurafsky, Christopher D Manning, and Christopher Potts. Axbench: Steering llm...
-
[48]
Step-level sparse autoencoder for reasoning process interpretation.arXiv preprint arXiv:2603.03031,
Xuan Yang, Jiayu Liu, Yuhang Lai, Hao Xu, Zhenya Huang, and Ning Miao. Step-level sparse autoencoder for reasoning process interpretation.arXiv preprint arXiv:2603.03031,
-
[49]
Direct preference optimization using sparse feature-level constraints.ArXiv, abs/2411.07618,
Qingyu Yin, Chak Tou Leong, Hongbo Zhang, Minjun Zhu, Hanqi Yan, Qiang Zhang, Yulan He, Wenjie Li, Jun Wang, Yue Zhang, and Linyi Yang. Direct preference optimization using sparse feature-level constraints.ArXiv, abs/2411.07618,
-
[50]
Zeyu Yun, Yubei Chen, Bruno A Olshausen, and Yann LeCun. Transformer visualization via dictionary learning: contextualized embedding as a linear superposition of transformer factors.arXiv preprint arXiv:2103.15949,
-
[51]
Deal: Disentangling transformer head activations for llm steering
Li-Ming Zhan, LIU Bo, Zexin Lu, Yujie Feng, Chengqiang Xie, Jiannong Cao, and Xiao-Ming Wu. Deal: Disentangling transformer head activations for llm steering. InKnowledgeable Foundation Models at ACL 2025,
work page 2025
-
[52]
Zhenyu Zhang, Xiaoxia Wu, Zhongzhu Zhou, Qingyang Wu, Yineng Zhang, Pragaash Ponnusamy, Harikaran Subbaraj, Jue Wang, Shuaiwen Leon Song, and Ben Athiwaratkun. Understanding and steering the cognitive behaviors of reasoning models at test-time.ArXiv, abs/2512.24574, 2025b. Haiyan Zhao, Xuansheng Wu, Fan Yang, Bo Shen, Ninghao Liu, and Mengnan Du. Denoisin...
-
[53]
Association for Computational Linguistics. Yu Zhao, Alessio Devoto, Giwon Hong, Xiaotang Du, Aryo Pradipta Gema, Hongru Wang, Kam-Fai Wong, and Pasquale Minervini. Steering knowledge selection behaviours in llms via sae-based representation engineering.arXiv preprint arXiv:2410.15999,
-
[54]
Apply" level of Bloom’s Taxonomy. The
for ( int num : nums ) { cout << num << " "; } return 0; } W/O SAE (Q generation):. Your code demonstrates solid grasp of fundamental concepts like vector manipulation and the modulo operator for handling rotation. The core structure using three distinct loops shows understanding of array traversal and value swapping mechanisms. SAE:Consider implementing ...
-
[55]
and cognitive style tasks (Figure 13), training SAEs at different layers. Across both domains, sparse query features from middle layers consistently yield the most reliable and effective steering, achieving stronger alignment with target attributes than features from early or late layers . This behavior is consistent with prior findings that middle attent...
work page 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.