HDRFace: Rethinking Face Restoration with High-Dimensional Representation
Pith reviewed 2026-06-30 21:45 UTC · model grok-4.3
The pith
High-dimensional features extracted from both low-quality inputs and intermediate restorations improve diffusion-based face restoration without changing the generative model.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
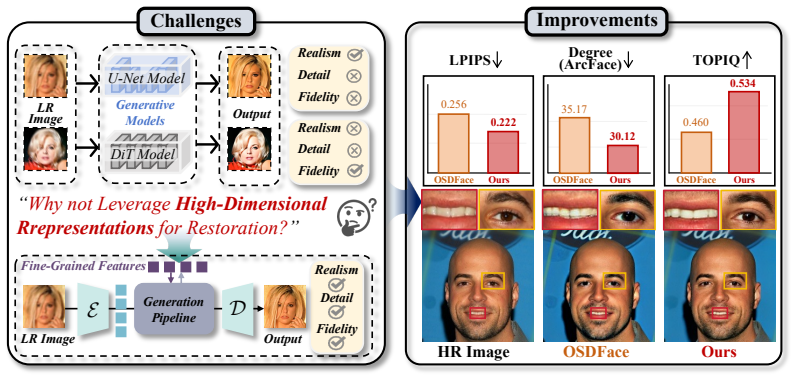
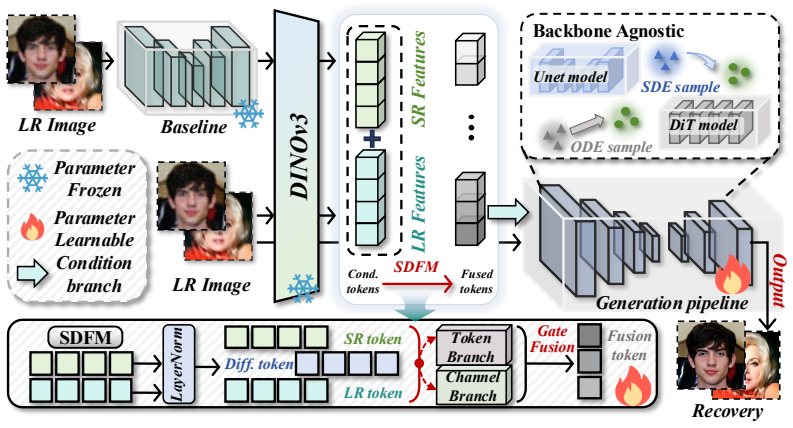
HDRFace first produces a structurally reliable intermediate restoration with an off-the-shelf restorer, then uses a pretrained high-dimensional feature encoder to extract fine-grained facial representations from both the low-quality input and the intermediate result, and injects these representations as additional conditions into the conditional flow of a diffusion model via SDFM, a Structure-Detail aware adaptive Fusion Mechanism that emphasizes global constraints during structure modeling and strengthens representation guidance during detail synthesis, producing consistent performance improvements on SD V2.1-base and Qwen-Image.
What carries the argument
SDFM, the Structure-Detail aware adaptive Fusion Mechanism that adapts emphasis between global structural constraints and representation guidance depending on the synthesis stage.
If this is right
- The same high-dimensional conditioning pipeline produces measurable gains on both SD V2.1-base and Qwen-Image without any modification to their generative backbones.
- SDFM allows the model to maintain structural consistency early in generation while increasing reliance on the extracted facial representations during detail synthesis.
- The framework remains modular because the feature encoder and fusion step operate outside the core diffusion process.
- Heavy degradations become more tractable once semantically rich priors from both the input and an intermediate result are available to the conditional flow.
Where Pith is reading between the lines
- The method may transfer to non-face restoration tasks if suitable domain-specific high-dimensional encoders exist.
- Replacing the off-the-shelf intermediate restorer with a lighter or learned module could reduce overall latency while preserving the reported gains.
- Systematic ablations on encoder choice would clarify which layers or pretraining objectives contribute most to identity recovery.
Load-bearing premise
The pretrained high-dimensional feature encoder extracts identity-critical details from the low-quality input and intermediate result that can be effectively fused by SDFM to guide generation under heavy degradations.
What would settle it
A controlled experiment on standard face restoration benchmarks that adds the high-dimensional features to the same diffusion backbone and measures no gain or a drop in identity similarity scores and perceptual quality compared with conditioning only on the low-quality input.
Figures






read the original abstract
Face restoration under complex degradations still remains an ill-posed inverse problem due to severe information loss. Although diffusion models benefit from strong generative priors, most methods still condition only on low-quality inputs, making it difficult to recover identity-critical details under heavy degradations. In this work, we propose HDRFace, a High-Dimensional Representation conditioned Face restoration framework that injects semantically rich priors into the conditional flow without modifying the generative backbone. Our pipeline first obtains a structurally reliable intermediate restoration with an off-the-shelf restorer, then uses a pretrained high-dimensional feature encoder to extract fine-grained facial representations from both the low-quality input and the intermediate result, and injects them as additional conditions for generation. We further introduce SDFM, a Structure-Detail aware adaptive Fusion Mechanism that emphasizes global constraints during structure modeling and strengthens representation guidance during detail synthesis, balancing structural consistency and detail fidelity. To validate the generalization ability of our method, we implement the proposed framework on two generative models, SD V2.1-base and Qwen-Image, and consistently observe stable and coherent performance gains across different architectures.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes HDRFace, a face restoration framework that obtains an intermediate restoration with an off-the-shelf restorer, extracts fine-grained facial representations from both the low-quality input and intermediate result using a pretrained high-dimensional feature encoder, and injects them via a new Structure-Detail aware adaptive Fusion Mechanism (SDFM) as additional conditions into unmodified generative backbones (SD V2.1-base and Qwen-Image), claiming improved recovery of identity-critical details under heavy degradations.
Significance. If the empirical claims hold, the modular conditioning strategy could provide a practical way to enhance existing diffusion models for face restoration without retraining the generative backbone, with potential generalization across architectures. The absence of any quantitative results, ablations, or comparisons in the manuscript prevents evaluation of whether the approach delivers meaningful gains over standard conditioning.
major comments (2)
- [Abstract] Abstract: the central claim of 'consistently observe stable and coherent performance gains across different architectures' is unsupported by any tables, figures, metrics, error bars, or baseline comparisons, rendering the contribution unevaluable from the provided text.
- [Method] Method description: the pipeline assumes the pretrained high-dimensional feature encoder reliably extracts identity-critical signals from heavily degraded LQ inputs (and intermediates) that SDFM can then usefully fuse; no analysis, training details, or experiments address encoder behavior under comparable degradation levels, leaving this extraction step as an unverified precondition for the reported gains.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We acknowledge that the current manuscript text lacks the quantitative results, ablations, and analyses needed to support the claims, and we will revise accordingly to make the contribution evaluable.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of 'consistently observe stable and coherent performance gains across different architectures' is unsupported by any tables, figures, metrics, error bars, or baseline comparisons, rendering the contribution unevaluable from the provided text.
Authors: We agree that the abstract claim requires supporting evidence from the manuscript. The revised version will add tables with quantitative metrics, figures, baseline comparisons, and error bars demonstrating the gains on SD V2.1-base and Qwen-Image. revision: yes
-
Referee: [Method] Method description: the pipeline assumes the pretrained high-dimensional feature encoder reliably extracts identity-critical signals from heavily degraded LQ inputs (and intermediates) that SDFM can then usefully fuse; no analysis, training details, or experiments address encoder behavior under comparable degradation levels, leaving this extraction step as an unverified precondition for the reported gains.
Authors: We accept this observation. The revision will incorporate analysis of the encoder under degradation, including relevant training details and experiments to verify its extraction of identity-critical signals from LQ inputs. revision: yes
Circularity Check
No circularity; derivation is self-contained
full rationale
The paper presents a pipeline that applies an off-the-shelf restorer, a pretrained high-dimensional feature encoder, and a newly introduced SDFM fusion module to condition existing generative backbones (SD V2.1-base, Qwen-Image). No equations, fitted parameters, or predictions are shown that reduce by construction to the method's own inputs or outputs. The central claim is an empirical performance gain from the added conditioning path; this is externally falsifiable on standard benchmarks and does not rely on self-citation chains, uniqueness theorems, or renaming of known results. The reader's provided circularity score of 2.0 is consistent with this assessment.
Axiom & Free-Parameter Ledger
invented entities (1)
-
SDFM
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Denoising diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
2020
-
[2]
High- resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High- resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022
2022
-
[3]
Dynfacerestore: Balancing fidelity and quality in diffusion-guided blind face restoration with dynamic blur-level mapping and guidance
Huu-Phu Do, Yu-Wei Chen, Yi-Cheng Liao, Chi-Wei Hsiao, Han-Yang Wang, Wei-Chen Chiu, and Ching-Chun Huang. Dynfacerestore: Balancing fidelity and quality in diffusion-guided blind face restoration with dynamic blur-level mapping and guidance. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 10432–10441, 2025
2025
-
[4]
Pgdiff: Guiding diffusion models for versatile face restoration via partial guidance.Advances in Neural Information Processing Systems, 36:32194–32214, 2023
Peiqing Yang, Shangchen Zhou, Qingyi Tao, and Chen Change Loy. Pgdiff: Guiding diffusion models for versatile face restoration via partial guidance.Advances in Neural Information Processing Systems, 36:32194–32214, 2023
2023
-
[5]
Diffbir: Toward blind image restoration with generative diffusion prior
Xinqi Lin, Jingwen He, Ziyan Chen, Zhaoyang Lyu, Bo Dai, Fanghua Yu, Yu Qiao, Wanli Ouyang, and Chao Dong. Diffbir: Toward blind image restoration with generative diffusion prior. InEuropean conference on computer vision, pages 430–448. Springer, 2024
2024
-
[6]
Osdface: One-step diffusion model for face restoration
Jingkai Wang, Jue Gong, Lin Zhang, Zheng Chen, Xing Liu, Hong Gu, Yutong Liu, Yulun Zhang, and Xiaokang Yang. Osdface: One-step diffusion model for face restoration. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 12626–12636, 2025
2025
-
[7]
Difface: Blind face restoration with diffused error contraction.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024
Zongsheng Yue and Chen Change Loy. Difface: Blind face restoration with diffused error contraction.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024
2024
-
[8]
Authface: Towards authentic blind face restoration with face-oriented generative diffusion prior
Guoqiang Liang, Qingnan Fan, Bingtao Fu, Jinwei Chen, Hong Gu, and Lin Wang. Authface: Towards authentic blind face restoration with face-oriented generative diffusion prior. In Proceedings of the 33rd ACM International Conference on Multimedia, pages 9842–9851, 2025
2025
-
[9]
Fsrnet: End-to-end learning face super-resolution with facial priors
Yu Chen, Ying Tai, Xiaoming Liu, Chunhua Shen, and Jian Yang. Fsrnet: End-to-end learning face super-resolution with facial priors. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 2492–2501, 2018
2018
-
[10]
Deep semantic face deblurring
Ziyi Shen, Wei-Sheng Lai, Tingfa Xu, Jan Kautz, and Ming-Hsuan Yang. Deep semantic face deblurring. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 8260–8269, 2018
2018
-
[11]
Super-resolving very low- resolution face images with supplementary attributes
Xin Yu, Basura Fernando, Richard Hartley, and Fatih Porikli. Super-resolving very low- resolution face images with supplementary attributes. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 908–917, 2018
2018
-
[12]
Progressive semantic-aware style transformation for blind face restoration
Chaofeng Chen, Xiaoming Li, Lingbo Yang, Xianhui Lin, Lei Zhang, and Kwan-Yee K Wong. Progressive semantic-aware style transformation for blind face restoration. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11896–11905, 2021
2021
-
[13]
Blind face restoration via deep multi-scale component dictionaries
Xiaoming Li, Chaofeng Chen, Shangchen Zhou, Xianhui Lin, Wangmeng Zuo, and Lei Zhang. Blind face restoration via deep multi-scale component dictionaries. InEuropean conference on computer vision, pages 399–415. Springer, 2020
2020
-
[14]
DeCo: Frequency-Decoupled Pixel Diffusion for End-to-End Image Generation
Zehong Ma, Longhui Wei, Shuai Wang, Shiliang Zhang, and Qi Tian. Deco: Frequency- decoupled pixel diffusion for end-to-end image generation.arXiv preprint arXiv:2511.19365, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[15]
Diffusion Transformers with Representation Autoencoders
Boyang Zheng, Nanye Ma, Shengbang Tong, and Saining Xie. Diffusion transformers with representation autoencoders.arXiv preprint arXiv:2510.11690, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
Back to Basics: Let Denoising Generative Models Denoise
Tianhong Li and Kaiming He. Back to basics: Let denoising generative models denoise.arXiv preprint arXiv:2511.13720, 2025. 10
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
Multi-task image restoration guided by robust dino features.arXiv preprint arXiv:2312.01677, 2023
Xin Lin, Jingtong Yue, Kelvin CK Chan, Lu Qi, Chao Ren, Jinshan Pan, and Ming-Hsuan Yang. Multi-task image restoration guided by robust dino features.arXiv preprint arXiv:2312.01677, 2023
-
[18]
Devendra K Jangid, Ripon K Saha, Dilshan Godaliyadda, Jing Li, Seok-Jun Lee, and Hamid R Sheikh. F2idiff: Real-world image super-resolution using feature to image diffusion foundation model.arXiv preprint arXiv:2512.24473, 2025
-
[19]
Oriane Siméoni, Huy V V o, Maximilian Seitzer, Federico Baldassarre, Maxime Oquab, Cijo Jose, Vasil Khalidov, Marc Szafraniec, Seungeun Yi, Michaël Ramamonjisoa, et al. Dinov3. arXiv preprint arXiv:2508.10104, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[20]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021
2021
-
[21]
Yushun Fang, Yuxiang Chen, Shibo Yin, Qiang Hu, Jiangchao Yao, Ya Zhang, Xiaoyun Zhang, and Yanfeng Wang. One-step diffusion transformer for controllable real-world image super- resolution.arXiv preprint arXiv:2511.17138, 2025
-
[22]
A style-based generator architecture for generative adversarial networks
Tero Karras, Samuli Laine, and Timo Aila. A style-based generator architecture for generative adversarial networks. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 4401–4410, 2019
2019
-
[23]
Vqfr: Blind face restoration with vector-quantized dictionary and parallel decoder
Yuchao Gu, Xintao Wang, Liangbin Xie, Chao Dong, Gen Li, Ying Shan, and Ming-Ming Cheng. Vqfr: Blind face restoration with vector-quantized dictionary and parallel decoder. In European Conference on Computer Vision, pages 126–143. Springer, 2022
2022
-
[24]
Progressive Growing of GANs for Improved Quality, Stability, and Variation
Tero Karras, Timo Aila, Samuli Laine, and Jaakko Lehtinen. Progressive growing of gans for improved quality, stability, and variation.arXiv preprint arXiv:1710.10196, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[25]
Labeled faces in the wild: A database forstudying face recognition in unconstrained environments
Gary B Huang, Marwan Mattar, Tamara Berg, and Eric Learned-Miller. Labeled faces in the wild: A database forstudying face recognition in unconstrained environments. InWorkshop on faces in’Real-Life’Images: detection, alignment, and recognition, 2008
2008
-
[26]
Towards real-world blind face restoration with generative facial prior
Xintao Wang, Yu Li, Honglun Zhang, and Ying Shan. Towards real-world blind face restoration with generative facial prior. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9168–9178, 2021
2021
-
[27]
The unrea- sonable effectiveness of deep features as a perceptual metric
Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang. The unrea- sonable effectiveness of deep features as a perceptual metric. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 586–595, 2018
2018
-
[28]
Image quality assessment: Unifying structure and texture similarity.IEEE transactions on pattern analysis and machine intelligence, 44(5):2567–2581, 2020
Keyan Ding, Kede Ma, Shiqi Wang, and Eero P Simoncelli. Image quality assessment: Unifying structure and texture similarity.IEEE transactions on pattern analysis and machine intelligence, 44(5):2567–2581, 2020
2020
-
[29]
Topiq: A top-down approach from semantics to distortions for image quality assessment.IEEE Transactions on Image Processing, 33:2404–2418, 2024
Chaofeng Chen, Jiadi Mo, Jingwen Hou, Haoning Wu, Liang Liao, Wenxiu Sun, Qiong Yan, and Weisi Lin. Topiq: A top-down approach from semantics to distortions for image quality assessment.IEEE Transactions on Image Processing, 33:2404–2418, 2024
2024
-
[30]
Exploring clip for assessing the look and feel of images
Jianyi Wang, Kelvin CK Chan, and Chen Change Loy. Exploring clip for assessing the look and feel of images. InProceedings of the AAAI conference on artificial intelligence, volume 37, pages 2555–2563, 2023
2023
-
[31]
Musiq: Multi-scale image quality transformer
Junjie Ke, Qifei Wang, Yilin Wang, Peyman Milanfar, and Feng Yang. Musiq: Multi-scale image quality transformer. InProceedings of the IEEE/CVF international conference on computer vision, pages 5148–5157, 2021
2021
-
[32]
Q-Align: Teaching LMMs for Visual Scoring via Discrete Text-Defined Levels
Haoning Wu, Zicheng Zhang, Weixia Zhang, Chaofeng Chen, Liang Liao, Chunyi Li, Yixuan Gao, Annan Wang, Erli Zhang, Wenxiu Sun, et al. Q-align: Teaching lmms for visual scoring via discrete text-defined levels.arXiv preprint arXiv:2312.17090, 2023. 11
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[33]
Blind image quality as- sessment via vision-language correspondence: A multitask learning perspective
Weixia Zhang, Guangtao Zhai, Ying Wei, Xiaokang Yang, and Kede Ma. Blind image quality as- sessment via vision-language correspondence: A multitask learning perspective. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 14071–14081, 2023
2023
-
[34]
Arcface: Additive angular margin loss for deep face recognition
Jiankang Deng, Jia Guo, Niannan Xue, and Stefanos Zafeiriou. Arcface: Additive angular margin loss for deep face recognition. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 4690–4699, 2019
2019
-
[35]
Gans trained by a two time-scale update rule converge to a local nash equilibrium.Advances in neural information processing systems, 30, 2017
Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. Gans trained by a two time-scale update rule converge to a local nash equilibrium.Advances in neural information processing systems, 30, 2017
2017
-
[36]
Lora: Low-rank adaptation of large language models.Iclr, 1(2):3, 2022
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Liang Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models.Iclr, 1(2):3, 2022
2022
-
[37]
Restoreformer++: Towards real-world blind face restoration from undegraded key-value pairs.IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(12):15462–15476, 2023
Zhouxia Wang, Jiawei Zhang, Tianshui Chen, Wenping Wang, and Ping Luo. Restoreformer++: Towards real-world blind face restoration from undegraded key-value pairs.IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(12):15462–15476, 2023
2023
-
[38]
Towards robust blind face restoration with codebook lookup transformer.Advances in Neural Information Processing Systems, 35:30599–30611, 2022
Shangchen Zhou, Kelvin Chan, Chongyi Li, and Chen Change Loy. Towards robust blind face restoration with codebook lookup transformer.Advances in Neural Information Processing Systems, 35:30599–30611, 2022
2022
-
[39]
Dual associated encoder for face restoration
Yu Ju Tsai, Yu Lun Liu, Lu Qi, Kelvin CK Chan, and Ming Hsuan Yang. Dual associated encoder for face restoration. In12th International Conference on Learning Representations, ICLR 2024, 2024
2024
-
[40]
Seesr: Towards semantics-aware real-world image super-resolution
Rongyuan Wu, Tao Yang, Lingchen Sun, Zhengqiang Zhang, Shuai Li, and Lei Zhang. Seesr: Towards semantics-aware real-world image super-resolution. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 25456–25467, 2024
2024
-
[41]
One-step effective diffusion network for real-world image super-resolution.Advances in Neural Information Processing Systems, 37:92529–92553, 2024
Rongyuan Wu, Lingchen Sun, Zhiyuan Ma, and Lei Zhang. One-step effective diffusion network for real-world image super-resolution.Advances in Neural Information Processing Systems, 37:92529–92553, 2024
2024
-
[42]
Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow
Xingchao Liu, Chengyue Gong, and Qiang Liu. Flow straight and fast: Learning to generate and transfer data with rectified flow.arXiv preprint arXiv:2209.03003, 2022. 12 A Appendix A.1 Backbone Architectures and High-Dimensional Representation Injection This section clarifies how the proposed high-dimensional representation condition is injected into the t...
work page internal anchor Pith review Pith/arXiv arXiv 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.