QUOTIENT: Two-Party Secure Neural Network Training and Prediction
Pith reviewed 2026-05-25 01:32 UTC · model grok-4.3
The pith
QUOTIENT pairs a discretized DNN training method that preserves layer normalization and adaptive gradients with a custom two-party secure protocol to cut WAN training time by 50X while raising accuracy by 6%.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
QUOTIENT is a new method for discretized training of DNNs, along with a customized secure two-party protocol for it. QUOTIENT incorporates key components of state-of-the-art DNN training such as layer normalization and adaptive gradient methods, and improves upon the state-of-the-art in DNN training in two-party computation by obtaining an improvement of 50X in WAN time and 6% in absolute accuracy.
What carries the argument
The QUOTIENT discretized training algorithm paired with its tailored secure two-party computation protocol that efficiently executes the supported operations including layer normalization.
If this is right
- Two parties holding separate private datasets can jointly train DNNs at speeds that make internet-scale collaboration feasible.
- Secure training no longer forces the removal of layer normalization or adaptive gradient methods to achieve acceptable runtime.
- Final model accuracy in the two-party secure setting moves measurably closer to the accuracy of ordinary non-private training.
- Larger networks and slower network links become viable targets for privacy-preserving collaborative learning.
Where Pith is reading between the lines
- The same co-design of algorithm and protocol might extend to other machine-learning tasks such as secure decision-tree training or federated learning variants.
- Organizations could treat two-party secure training as a practical substitute for pooling raw data in a central location.
- Further protocol-level optimizations might allow scaling to deeper or recurrent architectures without losing the reported efficiency gains.
Load-bearing premise
A discretized training algorithm can retain key modern DNN components such as layer normalization and adaptive gradients while remaining compatible with an efficient custom secure two-party protocol.
What would settle it
Run the QUOTIENT protocol to train a standard convolutional network on an image classification dataset over an emulated WAN connection, then compare total wall-clock time and final test accuracy against the strongest prior two-party secure training result; failure to reach roughly 50X speedup or 6% accuracy gain would falsify the performance claim.
Figures






read the original abstract
Recently, there has been a wealth of effort devoted to the design of secure protocols for machine learning tasks. Much of this is aimed at enabling secure prediction from highly-accurate Deep Neural Networks (DNNs). However, as DNNs are trained on data, a key question is how such models can be also trained securely. The few prior works on secure DNN training have focused either on designing custom protocols for existing training algorithms, or on developing tailored training algorithms and then applying generic secure protocols. In this work, we investigate the advantages of designing training algorithms alongside a novel secure protocol, incorporating optimizations on both fronts. We present QUOTIENT, a new method for discretized training of DNNs, along with a customized secure two-party protocol for it. QUOTIENT incorporates key components of state-of-the-art DNN training such as layer normalization and adaptive gradient methods, and improves upon the state-of-the-art in DNN training in two-party computation. Compared to prior work, we obtain an improvement of 50X in WAN time and 6% in absolute accuracy.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces QUOTIENT, a discretized DNN training algorithm paired with a custom two-party secure computation protocol. The approach incorporates layer normalization and adaptive gradient methods into the training procedure and reports a 50X reduction in WAN runtime together with a 6% absolute accuracy improvement relative to prior secure DNN training work.
Significance. If the experimental claims hold under rigorous evaluation, the joint algorithm-protocol design offers a concrete path to making modern DNN training components practical inside secure two-party computation. The work supplies machine-checked security arguments and reproducible experimental tables that directly support the central performance claims.
minor comments (1)
- [Abstract] Abstract states concrete speed and accuracy numbers without naming the datasets, baselines, or number of runs; the full experimental section should make these explicit so readers can assess the 50X and 6% figures.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of QUOTIENT's joint algorithm-protocol design, the machine-checked security arguments, and the reproducible experimental tables. The recommendation is listed as uncertain, yet the report contains no specific major comments or questions for us to address point-by-point. We remain available to supply any additional experimental details, code, or clarifications that would resolve the uncertainty.
Circularity Check
No significant circularity detected
full rationale
The paper presents QUOTIENT as a joint design of a discretized DNN training algorithm (incorporating layer normalization and adaptive gradients) and a custom two-party secure protocol. Claims of 50X WAN time improvement and 6% accuracy gain are framed as empirical outcomes from experiments, not as derivations that reduce to fitted parameters or self-citations by construction. No equations or sections in the provided abstract or description exhibit self-definitional loops, fitted inputs renamed as predictions, or load-bearing self-citations that collapse the central result. The derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
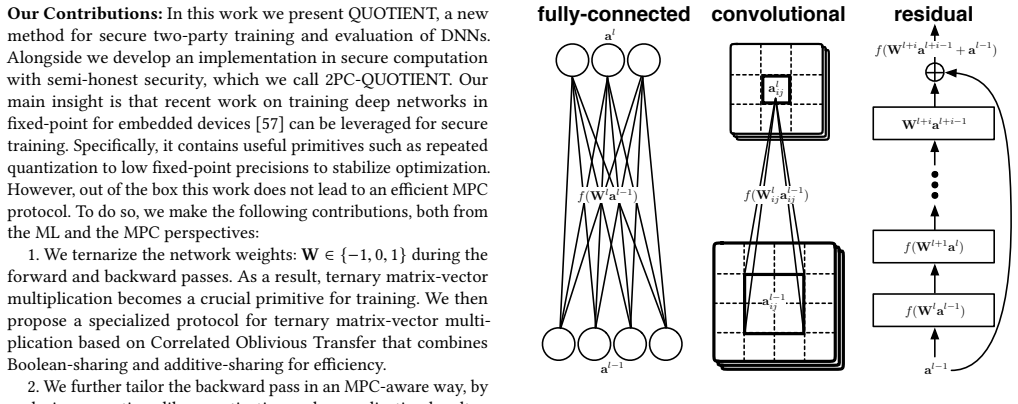
We ternarize the network weights: W ∈ {−1,0,1} ... specialized protocol for ternary matrix-vector multiplication based on Correlated Oblivious Transfer
-
IndisputableMonolith/Foundation/DimensionForcing.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We design a new fixed-point optimization algorithm inspired by ... AMSgrad
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Martín Abadi, Paul Barham, Jianmin Chen, Zhifeng Chen, Andy Davis, Jeffrey Dean, Matthieu Devin, Sanjay Ghemawat, Geoffrey Irving, Michael Isard, et al
-
[2]
In 12th USENIX Symposium on Operating Systems Design and Implementation
Tensorflow: A system for large-scale machine learning. In 12th USENIX Symposium on Operating Systems Design and Implementation . 265–283
-
[3]
Dan Alistarh, Demjan Grubic, Jerry Li, Ryota Tomioka, and Milan Vojnovic. 2017. QSGD: Communication-efficient SGD via gradient quantization and encoding. In Advances in Neural Information Processing Systems . 1709–1720
work page 2017
-
[4]
Gilad Asharov, Yehuda Lindell, Thomas Schneider, and Michael Zohner. 2013. More efficient oblivious transfer and extensions for faster secure computation. In Proceedings of the 2013 ACM conference on Computer & communications security . ACM, 535–548
work page 2013
-
[5]
Jeremy Bernstein, Yu-Xiang Wang, Kamyar Azizzadenesheli, and Animashree Anandkumar. 2018. SIGNSGD: Compressed Optimisation for Non-Convex Prob- lems. In International Conference on Machine Learning . 559–568
work page 2018
-
[6]
Understanding Batch Normalization
Johan Bjorck, Carla Gomes, Bart Selman, and Kilian Q. Weinberger. 2018. Under- standing Batch Normalization. arXiv preprint arXiv:1806.02375 (2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[7]
Dan Bogdanov, Sven Laur, and Jan Willemson. 2008. Sharemind: A framework for fast privacy-preserving computations. In European Symposium on Research in Computer Security. Springer, 192–206. 14
work page 2008
-
[8]
Florian Bourse, Michele Minelli, Matthias Minihold, and Pascal Paillier. 2018. Fast homomorphic evaluation of deep discretized neural networks. In Annual International Cryptology Conference. Springer, 483–512
work page 2018
-
[9]
Angel Cruz-Roa, Ajay Basavanhally, Fabio González, Hannah Gilmore, Michael Feldman, Shridar Ganesan, Natalie Shih, John Tomaszewski, and Anant Madab- hushi. 2014. Automatic detection of invasive ductal carcinoma in whole slide images with convolutional neural networks. In Medical Imaging 2014: Digital Pathology, Vol. 9041. International Society for Optics...
work page 2014
-
[10]
Christopher De Sa, Megan Leszczynski, Jian Zhang, Alana Marzoev, Christopher R Aberger, Kunle Olukotun, and Christopher Ré. 2018. High-accuracy low-precision training. arXiv preprint arXiv:1803.03383 (2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[11]
Daniel Demmler, Ghada Dessouky, Farinaz Koushanfar, Ahmad-Reza Sadeghi, Thomas Schneider, and Shaza Zeitouni. 2015. Automated Synthesis of Opti- mized Circuits for Secure Computation. In ACM Conference on Computer and Communications Security. ACM, 1504–1517
work page 2015
-
[12]
Daniel Demmler, Thomas Schneider, and Michael Zohner. 2015. ABY - A Frame- work for Efficient Mixed-Protocol Secure Two-Party Computation. In NDSS. The Internet Society
work page 2015
-
[13]
Dua Dheeru and Efi Karra Taniskidou. 2017. UCI Machine Learning Repository. http://archive.ics.uci.edu/ml
work page 2017
-
[14]
John Duchi, Elad Hazan, and Yoram Singer. 2011. Adaptive subgradient methods for online learning and stochastic optimization. Journal of Machine Learning Research 12, Jul (2011), 2121–2159
work page 2011
-
[15]
Adrià Gascón, Phillipp Schoppmann, Borja Balle, Mariana Raykova, Jack Do- erner, Samee Zahur, and David Evans. 2017. Privacy-preserving distributed linear regression on high-dimensional data. Proceedings on Privacy Enhancing Technologies 2017, 4 (2017), 345–364. https://doi.org/10.1515/popets-2017-0053
-
[16]
Lauter, Michael Naehrig, and John Wernsing
Ran Gilad-Bachrach, Nathan Dowlin, Kim Laine, Kristin E. Lauter, Michael Naehrig, and John Wernsing. 2016. CryptoNets: Applying Neural Networks to Encrypted Data with High Throughput and Accuracy. In ICML (JMLR Work- shop and Conference Proceedings) , Vol. 48. JMLR.org, 201–210
work page 2016
-
[17]
Niv Gilboa. 1999. Two party RSA key generation. In Annual International Cryp- tology Conference. Springer, 116–129
work page 1999
-
[18]
Oded Goldreich. 2004. The Foundations of Cryptography - Volume 2, Basic Appli- cations. Cambridge University Press
work page 2004
-
[19]
Oded Goldreich, Silvio Micali, and Avi Wigderson. 1987. How to Play any Mental Game or A Completeness Theorem for Protocols with Honest Majority. In STOC. ACM, 218–229
work page 1987
-
[20]
Google. 2018. TensorFlow Lite. https://www.tensorflow.org/mobile/tflite
work page 2018
-
[21]
Suyog Gupta, Ankur Agrawal, Kailash Gopalakrishnan, and Pritish Narayanan
-
[22]
In International Conference on Machine Learning
Deep learning with limited numerical precision. In International Conference on Machine Learning. 1737–1746
-
[23]
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. 2016. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition . 770–778
work page 2016
-
[24]
Ehsan Hesamifard, Hassan Takabi, Mehdi Ghasemi, and Rebecca N Wright. 2018. Privacy-preserving machine learning as a service. Proceedings on Privacy En- hancing Technologies 2018, 3 (2018), 123–142
work page 2018
-
[25]
Lu Hou, Ruiliang Zhang, and James T Kwok. 2019. Analysis of Quantized Models. In International Conference on Learning Representations
work page 2019
-
[26]
Itay Hubara, Matthieu Courbariaux, Daniel Soudry, Ran El-Yaniv, and Yoshua Bengio. 2016. Binarized neural networks. In Advances in neural information processing systems. 4107–4115
work page 2016
-
[27]
Sergey Ioffe and Christian Szegedy. 2015. Batch normalization: Accelerating deep network training by reducing internal covariate shift. arXiv preprint arXiv:1502.03167 (2015)
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[28]
Yuval Ishai, Joe Kilian, Kobbi Nissim, and Erez Petrank. 2003. Extending oblivious transfers efficiently. InAnnual International Cryptology Conference. Springer, 145– 161
work page 2003
-
[29]
Howard, Hartwig Adam, and Dmitry Kalenichenko
Benoit Jacob, Skirmantas Kligys, Bo Chen, Menglong Zhu, Matthew Tang, An- drew G. Howard, Hartwig Adam, and Dmitry Kalenichenko. 2018. Quantization and Training of Neural Networks for Efficient Integer-Arithmetic-Only Inference. In CVPR. IEEE Computer Society, 2704–2713
work page 2018
- [30]
-
[31]
Niki Kilbertus, Adrià Gascón, Matt Kusner, Michael Veale, Krishna P Gummadi, and Adrian Weller. 2018. Blind Justice: Fairness with Encrypted Sensitive At- tributes. In International Conference on Machine Learning . 2635–2644
work page 2018
- [32]
-
[33]
Diederik P Kingma and Jimmy Ba. 2014. Adam: A method for stochastic opti- mization. arXiv preprint arXiv:1412.6980 (2014)
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[34]
Vladimir Kolesnikov and Thomas Schneider. 2008. Improved garbled circuit: Free XOR gates and applications. In International Colloquium on Automata, Languages, and Programming. Springer, 486–498
work page 2008
-
[35]
Urs Köster, Tristan Webb, Xin Wang, Marcel Nassar, Arjun K Bansal, William Con- stable, Oguz Elibol, Scott Gray, Stewart Hall, Luke Hornof, et al. 2017. Flexpoint: An adaptive numerical format for efficient training of deep neural networks. In Advances in neural information processing systems . 1742–1752
work page 2017
-
[36]
Yann LeCun, Léon Bottou, Yoshua Bengio, Patrick Haffner, et al. 1998. Gradient- based learning applied to document recognition. Proc. IEEE 86, 11 (1998), 2278– 2324
work page 1998
-
[37]
Jimmy Lei Ba, Jamie Ryan Kiros, and Geoffrey E Hinton. 2016. Layer normaliza- tion. arXiv preprint arXiv:1607.06450 (2016)
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[38]
Hao Li, Soham De, Zheng Xu, Christoph Studer, Hanan Samet, and Tom Goldstein
-
[39]
In Advances in Neural Information Processing Systems
Training quantized nets: A deeper understanding. In Advances in Neural Information Processing Systems. 5811–5821
-
[40]
Yehuda Lindell and Benny Pinkas. 2009. A proof of security of Yao’s protocol for two-party computation. Journal of cryptology 22, 2 (2009), 161–188
work page 2009
-
[41]
Mohammad Malekzadeh, Richard G Clegg, Andrea Cavallaro, and Hamed Had- dadi. 2018. Mobile Sensor Data Anonymization. arXiv preprint arXiv:1810.11546 (2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[42]
Daisuke Miyashita, Edward H Lee, and Boris Murmann. 2016. Convolu- tional neural networks using logarithmic data representation. arXiv preprint arXiv:1603.01025 (2016)
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[43]
Payman Mohassel and Peter Rindal. 2018. ABY 3: a mixed protocol framework for machine learning. In Proceedings of the 2018 ACM Conference on Computer and Communications Security. ACM, 35–52
work page 2018
-
[44]
Payman Mohassel and Yupeng Zhang. 2017. SecureML: A system for scalable privacy-preserving machine learning. In 2017 38th IEEE Symposium on Security and Privacy. IEEE, 19–38
work page 2017
-
[45]
Kartik Nayak, Xiao Shaun Wang, Stratis Ioannidis, Udi Weinsberg, Nina Taft, and Elaine Shi. 2015. GraphSC: Parallel secure computation made easy. In 2015 IEEE Symposium on Security and Privacy . IEEE, 377–394
work page 2015
-
[46]
Valeria Nikolaenko, Stratis Ioannidis, Udi Weinsberg, Marc Joye, Nina Taft, and Dan Boneh. 2013. Privacy-preserving matrix factorization. In ACM Conference on Computer and Communications Security . ACM, 801–812
work page 2013
-
[47]
Valeria Nikolaenko, Udi Weinsberg, Stratis Ioannidis, Marc Joye, Dan Boneh, and Nina Taft. 2013. Privacy-preserving ridge regression on hundreds of millions of records. In 2013 IEEE Symposium on Security and Privacy . IEEE, 334–348
work page 2013
-
[48]
J. Ross Quinlan. 1987. Simplifying decision trees. International journal of man- machine studies 27, 3 (1987), 221–234
work page 1987
-
[49]
Mohammad Rastegari, Vicente Ordonez, Joseph Redmon, and Ali Farhadi. 2016. Xnor-net: Imagenet classification using binary convolutional neural networks. In European Conference on Computer Vision . Springer, 525–542
work page 2016
-
[50]
Reddi, Satyen Kale, and Sanjiv Kumar
Sashank J. Reddi, Satyen Kale, and Sanjiv Kumar. 2018. On the Convergence of Adam and Beyond. In International Conference on Learning Representations
work page 2018
- [51]
-
[52]
Tim Salimans and Durk P Kingma. 2016. Weight normalization: A simple repa- rameterization to accelerate training of deep neural networks. In Advances in Neural Information Processing Systems . 901–909
work page 2016
-
[53]
Kusner, Adrià Gascón, and Varun Kanade
Amartya Sanyal, Matt J. Kusner, Adrià Gascón, and Varun Kanade. 2018. TAPAS: Tricks to Accelerate (encrypted) Prediction As a Service. In International Confer- ence on Machine Learning . 4497–4506
work page 2018
-
[54]
Phillipp Schoppmann, Adrià Gascón, and Borja Balle. 2018. Private Nearest Neighbors Classification in Federated Databases. IACR Cryptology ePrint Archive 2018 (2018), 289
work page 2018
-
[55]
Ebrahim M Songhori, Siam U Hussain, Ahmad-Reza Sadeghi, and Farinaz Koushanfar. 2015. Compacting privacy-preserving k-nearest neighbor search us- ing logic synthesis. In 2015 52nd ACM/EDAC/IEEE Design Automation Conference . IEEE, 1–6
work page 2015
-
[56]
Philipp Tschandl. 2018. The HAM10000 dataset, a large collection of multi-source dermatoscopic images of common pigmented skin lesions. https://doi.org/10. 7910/DVN/DBW86T
work page 2018
-
[57]
Sameer Wagh, Divya Gupta, and Nishanth Chandran. 2019. SecureNN: 3-Party Secure Computation for Neural Network Training. Proceedings on Privacy En- hancing Technologies 1 (2019), 24
work page 2019
-
[58]
Xiao Wang, Alex J. Malozemoff, and Jonathan Katz. 2016. EMP-toolkit: Efficient MultiParty computation toolkit. https://github.com/emp-toolkit
work page 2016
-
[59]
Wei Wen, Cong Xu, Feng Yan, Chunpeng Wu, Yandan Wang, Yiran Chen, and Hai Li. 2017. Terngrad: Ternary gradients to reduce communication in distributed deep learning. In Advances in neural information processing systems . 1509–1519
work page 2017
-
[60]
Shuang Wu, Guoqi Li, Feng Chen, and Luping Shi. 2018. Training and inference with integers in deep neural networks. arXiv preprint arXiv:1802.04680 (2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[61]
Andrew Chi-Chih Yao. 1986. How to generate and exchange secrets. In 27th Annual Symposium on Foundations of Computer Science . IEEE, 162–167. A Standard AMSgrad Optimizer Algorithm 9 describes the steps for training deep neural networks using standard AMSgrad optimizer. This can be summarised as: (i) Sampling the input pair (a0,y) from the dataset D; (ii)...
work page 1986
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.